funcParse(base *PosBase, src io.Reader, errh ErrorHandler, pragh PragmaHandler, mode Mode) (_ *File, first error) { deferfunc() { if p := recover(); p != nil { if err, ok := p.(Error); ok { first = err return } panic(p) } }()
var p parser p.init(base, src, errh, pragh, mode) p.next() return p.fileOrNil(), p.first }
// 2. 解析包声明 f.GoVersion = p.goVersion p.top = false if !p.got(_Package) { // 包声明必须放在第一位,这跟我们学 Go 语法对应上了 p.syntaxError("package statement must be first") returnnil } f.Pragma = p.takePragma() // 获取编译指令 f.PkgName = p.name() // 获取包名 p.want(_Semi) // _Semi 在之前的 tokens.go 中可以发现是分号(;),是的,包声明后面就是得带分号
// 3. 处理包声明错误 if p.first != nil { returnnil }
// 4. 循环解析顶层声明 // 循环处理文件中的所有声明,包括 import、const、type、var 和 func // 对每种类型的声明,调用其解析函数,如 importDecl、constDecl 进行解析 prev := _Import for p.tok != _EOF { if p.tok == _Import && prev != _Import { p.syntaxError("imports must appear before other declarations") } prev = p.tok
switch p.tok { case _Import: p.next() f.DeclList = p.appendGroup(f.DeclList, p.importDecl)
case _Const: p.next() f.DeclList = p.appendGroup(f.DeclList, p.constDecl)
case _Type: p.next() f.DeclList = p.appendGroup(f.DeclList, p.typeDecl)
case _Var: p.next() f.DeclList = p.appendGroup(f.DeclList, p.varDecl)
case _Func: p.next() if d := p.funcDeclOrNil(); d != nil { f.DeclList = append(f.DeclList, d) }
default: // 5. 处理异常和错误 if p.tok == _Lbrace && len(f.DeclList) > 0 && isEmptyFuncDecl(f.DeclList[len(f.DeclList)-1]) { p.syntaxError("unexpected semicolon or newline before {") } else { p.syntaxError("non-declaration statement outside function body") } p.advance(_Import, _Const, _Type, _Var, _Func) continue }
// Reset p.pragma BEFORE advancing to the next token (consuming ';') // since comments before may set pragmas for the next function decl. p.clearPragma()
if p.tok != _EOF && !p.got(_Semi) { p.syntaxError("after top level declaration") p.advance(_Import, _Const, _Type, _Var, _Func) } }
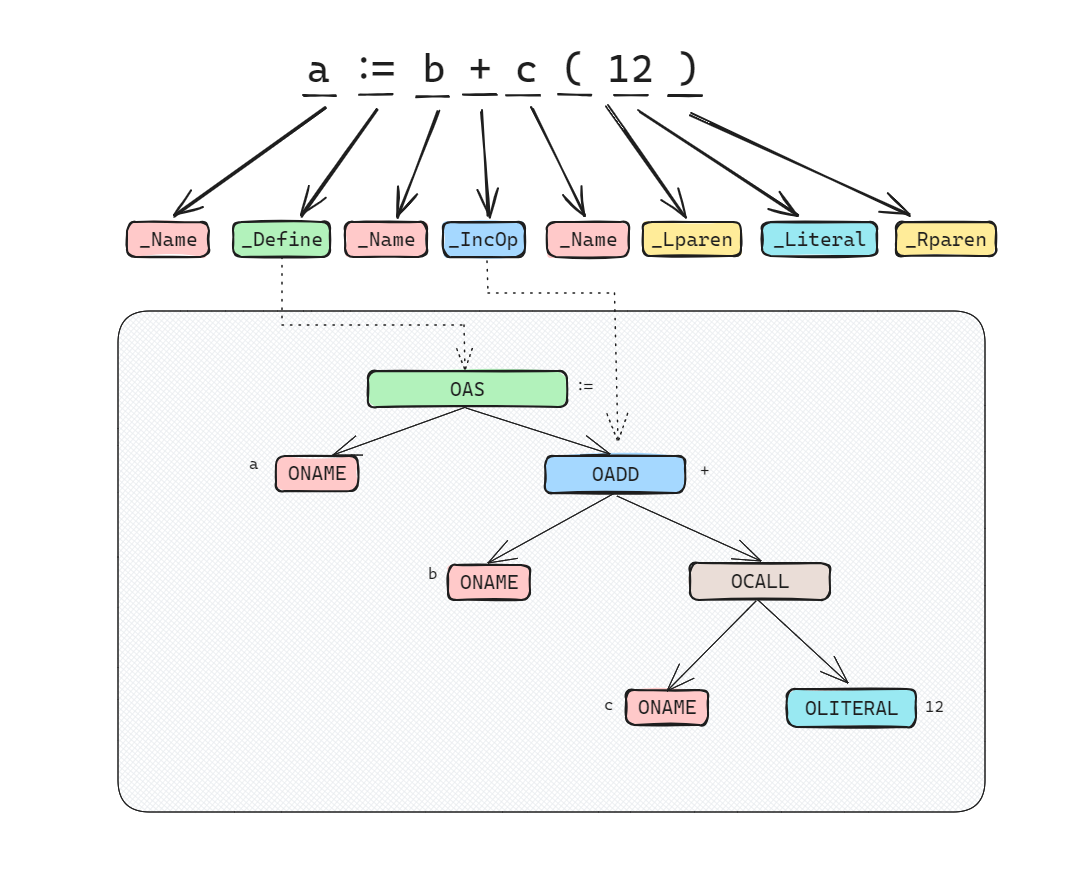
AST 每个节点都包含了当前节点属性的 Op 字段,定义在
ir/node.go 中,以 O 开头。与词法解析阶段中的 token
相同的是,Op 字段也是一个整数。不同的是,每个 Op
字段都包含了语义信息。例如,当一个节点的 Op 操作为 OAS
时,该节点代表的语义为 Left := Right,而当节点的操作为 OAS2
时,代码的语义为 x,y,z = a,b,c。
// names ONAME // var or func name // Unnamed arg or return value: f(int, string) (int, error) { etc } // Also used for a qualified package identifier that hasn't been resolved yet. ONONAME OTYPE // type name OLITERAL // literal ONIL // nil
// expressions OADD // X + Y ... // X = Y or (if Def=true) X := Y // If Def, then Init includes a DCL node for X. OAS // Lhs = Rhs (x, y, z = a, b, c) or (if Def=true) Lhs := Rhs // If Def, then Init includes DCL nodes for Lhs OAS2 ...
// statements OLABEL // Label: ... OEND )
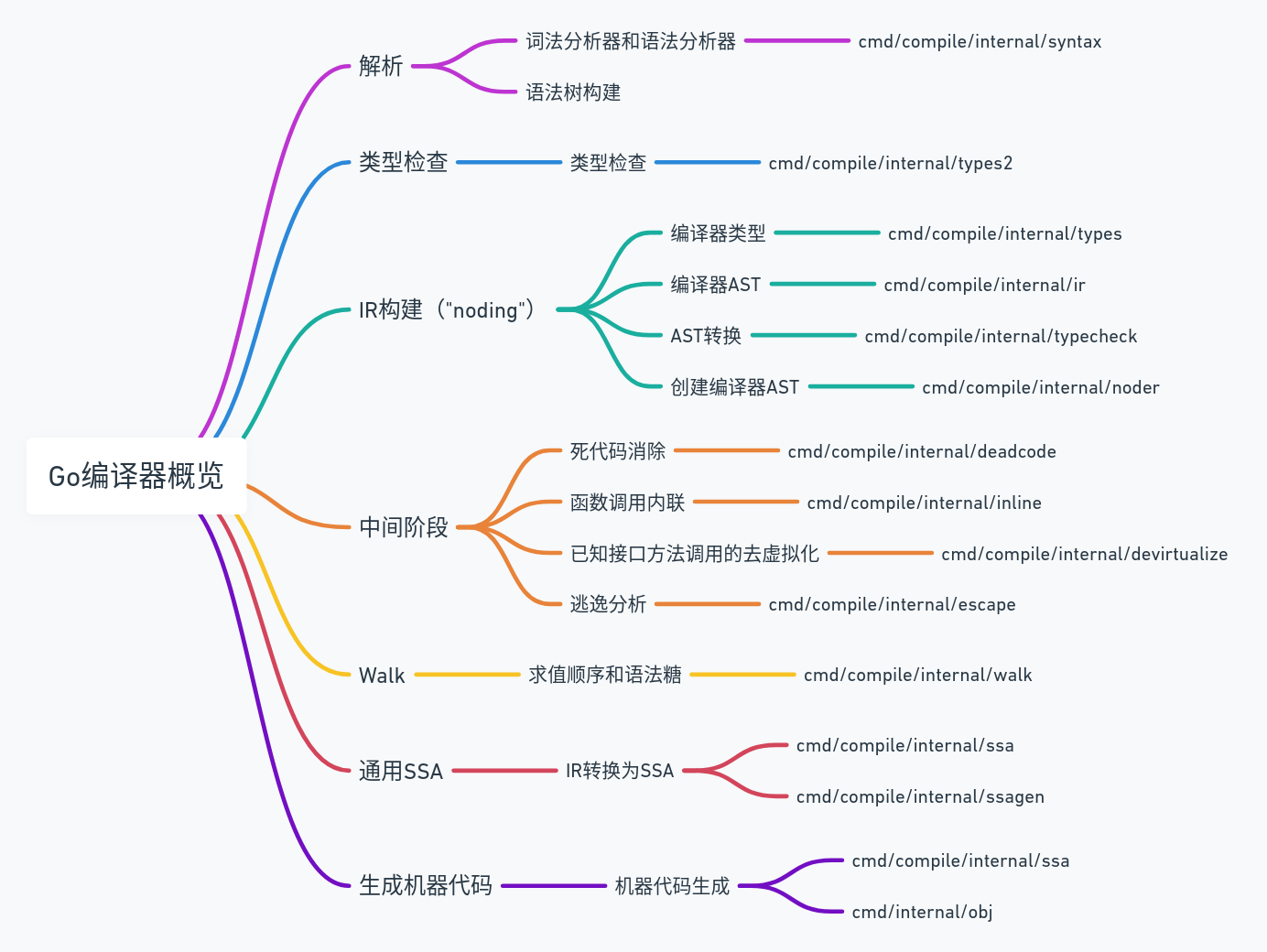
以前面举例的赋值语句 a := b + c(12)
为例,该赋值语句最终会编程如下图所示的抽象语法树,节点之间具有从上到下的层次结构和依赖关系。
// 3. 对每个文件,解析其中指定的 Go 版本 for _, file := range check.files { v, _ := parseGoVersion(file.GoVersion) if v.major > 0 { if v.equal(check.version) { continue } // Go 1.21 introduced the feature of setting the go.mod // go line to an early version of Go and allowing //go:build lines // to “upgrade” the Go version in a given file. // We can do that backwards compatibly. // Go 1.21 also introduced the feature of allowing //go:build lines // to “downgrade” the Go version in a given file. // That can't be done compatibly in general, since before the // build lines were ignored and code got the module's Go version. // To work around this, downgrades are only allowed when the // module's Go version is Go 1.21 or later. // If there is no check.version, then we don't really know what Go version to apply. // Legacy tools may do this, and they historically have accepted everything. // Preserve that behavior by ignoring //go:build constraints entirely in that case. if (v.before(check.version) && check.version.before(version{1, 21})) || check.version.equal(version{0, 0}) { continue } if check.posVers == nil { check.posVers = make(map[*syntax.PosBase]version) } check.posVers[base(file.Pos())] = v } } }
// 1. 标记最后一个标签,其对应的 Op 字段就是 OLABEL var lastLabel = -1 for i, n := range *nn { if n != nil && n.Op() == ir.OLABEL { lastLabel = i } }
// 2. 处理 if 和 switch 语句 for i, n := range *nn { cut := false if n == nil { continue } if n.Op() == ir.OIF { n := n.(*ir.IfStmt) n.Cond = expr(n.Cond) // if 语句根据条件是否为常量来保留和移除分支 if ir.IsConst(n.Cond, constant.Bool) { var body ir.Nodes if ir.BoolVal(n.Cond) { ir.VisitList(n.Else, markHiddenClosureDead) n.Else = ir.Nodes{} body = n.Body } else { ir.VisitList(n.Body, markHiddenClosureDead) n.Body = ir.Nodes{} body = n.Else } // 如果 then 或 else 分支以 panic 或 return 语句结束,那么可以安全地移除该节点之后的所有语句。 // 这是因为 panic 或 return 会导致函数终止,后续的代码永远不会被执行。 // 同时,注释提到要避免移除标签(labels),因为它们可能是 goto 语句的目标, // 而且为了避免 goto 相关的复杂性,没有使用 isterminating 标记。 // might be the target of a goto. See issue 28616. if body := body; len(body) != 0 { switch body[(len(body) - 1)].Op() { case ir.ORETURN, ir.OTAILCALL, ir.OPANIC: if i > lastLabel { cut = true } } } } } // 尝试简化 switch 语句,根据条件值决定哪个分支始终被执行 if n.Op() == ir.OSWITCH { n := n.(*ir.SwitchStmt) func() { if n.Tag != nil && n.Tag.Op() == ir.OTYPESW { return// no special type-switch case yet. } var x constant.Value // value we're switching on if n.Tag != nil { if ir.ConstType(n.Tag) == constant.Unknown { return } x = n.Tag.Val() } else { x = constant.MakeBool(true) // switch { ... } => switch true { ... } } var def *ir.CaseClause for _, cas := range n.Cases { iflen(cas.List) == 0 { // default case def = cas continue } for _, c := range cas.List { if ir.ConstType(c) == constant.Unknown { return// can't statically tell if it matches or not - give up. } if constant.Compare(x, token.EQL, c.Val()) { for _, n := range cas.Body { if n.Op() == ir.OFALL { return// fallthrough makes it complicated - abort. } } // This switch entry is the one that always triggers. for _, cas2 := range n.Cases { for _, c2 := range cas2.List { ir.Visit(c2, markHiddenClosureDead) } if cas2 != cas { ir.VisitList(cas2.Body, markHiddenClosureDead) } }
// Rewrite to switch { case true: ... } n.Tag = nil cas.List[0] = ir.NewBool(c.Pos(), true) cas.List = cas.List[:1] n.Cases[0] = cas n.Cases = n.Cases[:1] return } } } if def != nil { for _, n := range def.Body { if n.Op() == ir.OFALL { return// fallthrough makes it complicated - abort. } } for _, cas := range n.Cases { if cas != def { ir.VisitList(cas.List, markHiddenClosureDead) ir.VisitList(cas.Body, markHiddenClosureDead) } } n.Cases[0] = def n.Cases = n.Cases[:1] return }
// TODO: handle case bodies ending with panic/return as we do in the IF case above.
// entire switch is a nop - no case ever triggers for _, cas := range n.Cases { ir.VisitList(cas.List, markHiddenClosureDead) ir.VisitList(cas.Body, markHiddenClosureDead) } n.Cases = n.Cases[:0] }() }
// 3. 对节点的初始化语句递归调用 stmt 函数进行处理 iflen(n.Init()) != 0 { stmts(n.(ir.InitNode).PtrInit()) } // 4. 遍历其他控制结构,递归处理它们的内部语句 switch n.Op() { case ir.OBLOCK: n := n.(*ir.BlockStmt) stmts(&n.List) case ir.OFOR: n := n.(*ir.ForStmt) stmts(&n.Body) case ir.OIF: n := n.(*ir.IfStmt) stmts(&n.Body) stmts(&n.Else) case ir.ORANGE: n := n.(*ir.RangeStmt) stmts(&n.Body) case ir.OSELECT: n := n.(*ir.SelectStmt) for _, cas := range n.Cases { stmts(&cas.Body) } case ir.OSWITCH: n := n.(*ir.SwitchStmt) for _, cas := range n.Cases { stmts(&cas.Body) } }
// 函数名必须有效 if fn.Nname == nil { base.Fatalf("CanInline no nname %+v", fn) }
// 如果不能内联,输出原因 var reason string if base.Flag.LowerM > 1 || logopt.Enabled() { deferfunc() { if reason != "" { if base.Flag.LowerM > 1 { fmt.Printf("%v: cannot inline %v: %s\n", ir.Line(fn), fn.Nname, reason) } if logopt.Enabled() { logopt.LogOpt(fn.Pos(), "cannotInlineFunction", "inline", ir.FuncName(fn), reason) } } }() }
// 检查是否符合不可能内联的情况,如果返回的 reason 不为空,则表示有不可以内联的原因 reason = InlineImpossible(fn) if reason != "" { return } if fn.Typecheck() == 0 { base.Fatalf("CanInline on non-typechecked function %v", fn) }
n := fn.Nname if n.Func.InlinabilityChecked() { return } defer n.Func.SetInlinabilityChecked(true)
cc := int32(inlineExtraCallCost) if base.Flag.LowerL == 4 { cc = 1// this appears to yield better performance than 0. }
// 设置内联预算,后面如果检查函数的复杂度超过预算了,就不内联了 budget := int32(inlineMaxBudget) if profile != nil { if n, ok := profile.WeightedCG.IRNodes[ir.LinkFuncName(fn)]; ok { if _, ok := candHotCalleeMap[n]; ok { budget = int32(inlineHotMaxBudget) if base.Debug.PGODebug > 0 { fmt.Printf("hot-node enabled increased budget=%v for func=%v\n", budget, ir.PkgFuncName(fn)) } } } }
funcInlineImpossible(fn *ir.Func)string { var reason string// reason, if any, that the function can not be inlined. if fn.Nname == nil { reason = "no name" return reason }
// If marked "go:noinline", don't inline. if fn.Pragma&ir.Noinline != 0 { reason = "marked go:noinline" return reason }
// If marked "go:norace" and -race compilation, don't inline. if base.Flag.Race && fn.Pragma&ir.Norace != 0 { reason = "marked go:norace with -race compilation" return reason }
// If marked "go:nocheckptr" and -d checkptr compilation, don't inline. if base.Debug.Checkptr != 0 && fn.Pragma&ir.NoCheckPtr != 0 { reason = "marked go:nocheckptr" return reason }
// If marked "go:cgo_unsafe_args", don't inline, since the function // makes assumptions about its argument frame layout. if fn.Pragma&ir.CgoUnsafeArgs != 0 { reason = "marked go:cgo_unsafe_args" return reason }
// If marked as "go:uintptrkeepalive", don't inline, since the keep // alive information is lost during inlining. // // TODO(prattmic): This is handled on calls during escape analysis, // which is after inlining. Move prior to inlining so the keep-alive is // maintained after inlining. if fn.Pragma&ir.UintptrKeepAlive != 0 { reason = "marked as having a keep-alive uintptr argument" return reason }
// If marked as "go:uintptrescapes", don't inline, since the escape // information is lost during inlining. if fn.Pragma&ir.UintptrEscapes != 0 { reason = "marked as having an escaping uintptr argument" return reason }
// The nowritebarrierrec checker currently works at function // granularity, so inlining yeswritebarrierrec functions can confuse it // (#22342). As a workaround, disallow inlining them for now. if fn.Pragma&ir.Yeswritebarrierrec != 0 { reason = "marked go:yeswritebarrierrec" return reason }
// If a local function has no fn.Body (is defined outside of Go), cannot inline it. // Imported functions don't have fn.Body but might have inline body in fn.Inl. iflen(fn.Body) == 0 && !typecheck.HaveInlineBody(fn) { reason = "no function body" return reason }
// If fn is synthetic hash or eq function, cannot inline it. // The function is not generated in Unified IR frontend at this moment. if ir.IsEqOrHashFunc(fn) { reason = "type eq/hash function" return reason }
funcSayHello()string { s := "hello, " + "world" return s }
funcFib(index int)int { if index < 2 { return index } return Fib(index-1) + Fib(index-2) }
funcForSearch()int { var s = []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 0} res := 0 for i := 0; i < len(s); i++ { if s[i] == i { res = i } } return res }
funcmain() { SayHello() Fib(65) ForSearch() }
在编译时我们可以加入 -m=2
标签,来打印函数的内联调试信息。在 main.go 目录下执行:
1
go tool compile -m=2 main.go
输出:
1 2 3 4 5 6 7 8
main.go:3:6: can inline SayHello with cost 7 as: func() string { s := "hello, " + "world"; return s } main.go:8:6: cannot inline Fib: recursive main.go:15:6: can inline ForSearch with cost 45 as: func() int { s := []int{...}; res := 0; for loop; return res } main.go:26:6: cannot inline main: function too complex: cost 116 exceeds budget 80 main.go:27:10: inlining call to SayHello main.go:29:11: inlining call to ForSearch main.go:16:15: []int{...} does not escape main.go:29:11: []int{...} does not escape
/escape/main.go:5:6: can inline main /escape/main.go:6:10: new(int) escapes to hea
也可以执行下面语句输出数据流图构建过程:
1
go build -gcflags="-m -m -l" main.go
如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# command-line-arguments ./main.go:6:10: new(int) escapes to heap: ./main.go:6:10: flow: l = &{storage for new(int)}: ./main.go:6:10: from new(int) (spill) at ./main.go:6:10 ./main.go:6:10: from l := new(int) (assign) at ./main.go:6:4 ./main.go:6:10: flow: m = &l: ./main.go:6:10: from &l (address-of) at ./main.go:8:7 ./main.go:6:10: from m := &l (assign) at ./main.go:8:4 ./main.go:6:10: flow: n = &m: ./main.go:6:10: from &m (address-of) at ./main.go:9:7 ./main.go:6:10: from n := &m (assign) at ./main.go:9:4 ./main.go:6:10: flow: {heap} = **n: ./main.go:6:10: from *n (indirection) at ./main.go:10:7 ./main.go:6:10: from *(*n) (indirection) at ./main.go:10:6 ./main.go:6:10: from o = *(*n) (assign) at ./main.go:10:4 ./main.go:6:10: new(int) escapes to heap
如果我们试一下,把 o 放在 main()
里面呢?
1 2 3 4 5 6 7 8 9
funcmain() { var o *int l := new(int) *l = 42 m := &l n := &m o = **n o = o // 让编译通过 }
执行下面语句:
1
go tool compile -m main.go
输出:
1 2
/escape/main.go:3:6: can inline main /escape/main.go:5:10: new(int) does not escape
func(b *batch) flowClosure(k hole, clo *ir.ClosureExpr) { // 遍历闭包中的所有变量 for _, cv := range clo.Func.ClosureVars { n := cv.Canonical() loc := b.oldLoc(cv) // 如果变量未被捕获,则触发错误 if !loc.captured { base.FatalfAt(cv.Pos(), "closure variable never captured: %v", cv) }
// 根据变量的特性决定是通过值还是引用捕获 // 如果变量未被重新赋值或取址,并且小于等于 128 字节,则通过值捕获 n.SetByval(!loc.addrtaken && !loc.reassigned && n.Type().Size() <= 128) if !n.Byval() { n.SetAddrtaken(true) // 特殊情况处理:字典变量不通过值捕获 if n.Sym().Name == typecheck.LocalDictName { base.FatalfAt(n.Pos(), "dictionary variable not captured by value") } }
// 记录闭包捕获变量的方式(值或引用) if base.Flag.LowerM > 1 { how := "ref" if n.Byval() { how = "value" } base.WarnfAt(n.Pos(), "%v capturing by %s: %v (addr=%v assign=%v width=%d)", n.Curfn, how, n, loc.addrtaken, loc.reassigned, n.Type().Size()) }
// 建立闭包变量的数据流 k := k if !cv.Byval() { k = k.addr(cv, "reference") } b.flow(k.note(cv, "captured by a closure"), loc) } }
举个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
package main
funcmain() { a := 1 b := 2 gofunc() { add(a, b) }() a = 99 }
funcadd(a, b int) { a = a + b }
执行下面语句看看变量的捕获方式:
1
go tool compile -m=2 main.go | grep "capturing"
输出:
1 2
main.go:4:2: main capturing by ref: a (addr=false assign=true width=8) main.go:5:2: main capturing by value: b (addr=false assign=false width=8)
可以看到 a 是通过 ref 地址引用
的方式进行引用的,而 b 是通过 value 值传递
的方式进行引用的。
简单分析一下:上述例子中,闭包引用了 a 和 b
这 2 个闭包外声明的变量,而变量 a
在闭包之前又做了一些其他的操作,而 b 没有,所以对于
a,因为闭包外有操作,所以闭包内的操作可能是有特殊意义的,需要反馈到闭包外,就需要用
ref 地址引用了,而 b
在闭包外并不关心,所以闭包内的操作不会影响到闭包外,故直接使用
value 值传递 即可。
// directClosureCall rewrites a direct call of a function literal into // a normal function call with closure variables passed as arguments. // This avoids allocation of a closure object. // // For illustration, the following call: // // func(a int) { // println(byval) // byref++ // }(42) // // becomes: // // func(byval int, &byref *int, a int) { // println(byval) // (*&byref)++ // }(byval, &byref, 42) funcdirectClosureCall(n *ir.CallExpr) { clo := n.X.(*ir.ClosureExpr) clofn := clo.Func
// 如果闭包足够简单,不进行处理,留给 walkClosure 处理。 if ir.IsTrivialClosure(clo) { return// leave for walkClosure to handle }
// 将闭包中的每个变量转换为函数的参数。对于引用捕获的变量,创建相应的指针参数。 var params []*types.Field var decls []*ir.Name for _, v := range clofn.ClosureVars { if !v.Byval() { // 对于引用捕获的变量,创建相应的指针参数。 addr := ir.NewNameAt(clofn.Pos(), typecheck.Lookup("&"+v.Sym().Name)) addr.Curfn = clofn addr.SetType(types.NewPtr(v.Type())) v.Heapaddr = addr v = addr }
// 如果存在预分配的闭包对象,进行相关处理。 if x := clo.Prealloc; x != nil { if !types.Identical(typ, x.Type()) { panic("closure type does not match order's assigned type") } addr.Prealloc = x clo.Prealloc = nil }