TEXT _rt0_amd64_windows(SB),NOSPLIT|NOFRAME,$-8 JMP _rt0_amd64(SB)
这里我们可以看到它会直接跳到 _rt0_amd64(SB) 这里,在
Goland IDE 中,你可以双击 Shift 键打开搜索,搜索
TEXT _rt0_amd64,就可以发现这个函数位于 asm_amd64.s
文件中,查看该文件:
1 2 3 4 5 6 7 8
// _rt0_amd64 is common startup code for most amd64 systems when using // internal linking. This is the entry point for the program from the // kernel for an ordinary -buildmode=exe program. The stack holds the // number of arguments and the C-style argv. TEXT _rt0_amd64(SB),NOSPLIT,$-8 MOVQ 0(SP), DI // argc LEAQ 8(SP), SI // argv JMP runtime·rt0_go(SB)
翻译一下上面的注释:_rt0_amd64 是大多数
amd64 系统在使用内部链接时的通用启动代码。这是
exe 程序从内核进入程序的入口点。堆栈保存了参数的数量和 C
语言风格的 argv。
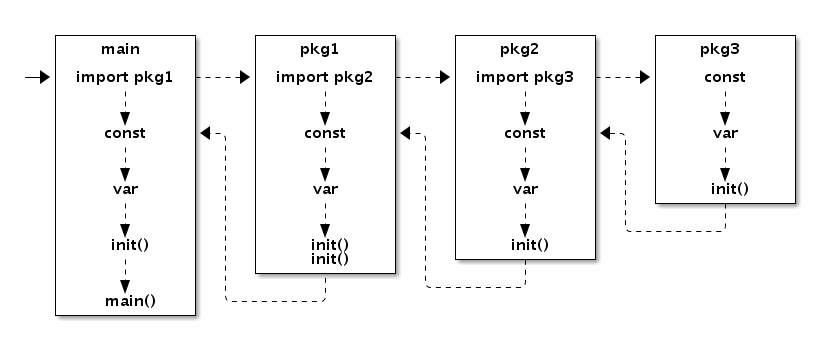
到这里我们就可以非常确定地找到了对应操作系统的 Go
语言程序启动入口了,接下来只需要沿着该入口继续分析即可。
// 针对不同操作系统对 TLS 进行设置 needtls: #ifdef GOOS_plan9 // skip TLS setup on Plan 9 JMP ok #endif #ifdef GOOS_solaris // skip TLS setup on Solaris JMP ok #endif #ifdef GOOS_illumos // skip TLS setup on illumos JMP ok #endif #ifdef GOOS_darwin // skip TLS setup on Darwin JMP ok #endif #ifdef GOOS_openbsd // skip TLS setup on OpenBSD JMP ok #endif
/** 补充:这是该文件下面对 runtime·mainPC 的声明 // mainPC is a function value for runtime.main, to be passed to newproc. // The reference to runtime.main is made via ABIInternal, since the // actual function (not the ABI0 wrapper) is needed by newproc. DATA runtime·mainPC+0(SB)/8,$runtime·main<ABIInternal>(SB) */
一句话:runtime·rt0_go 是 Go
语言运行时的入口点,它负责设置和初始化运行时环境,然后创建 g0 和 m0
来运行程序的主函数。
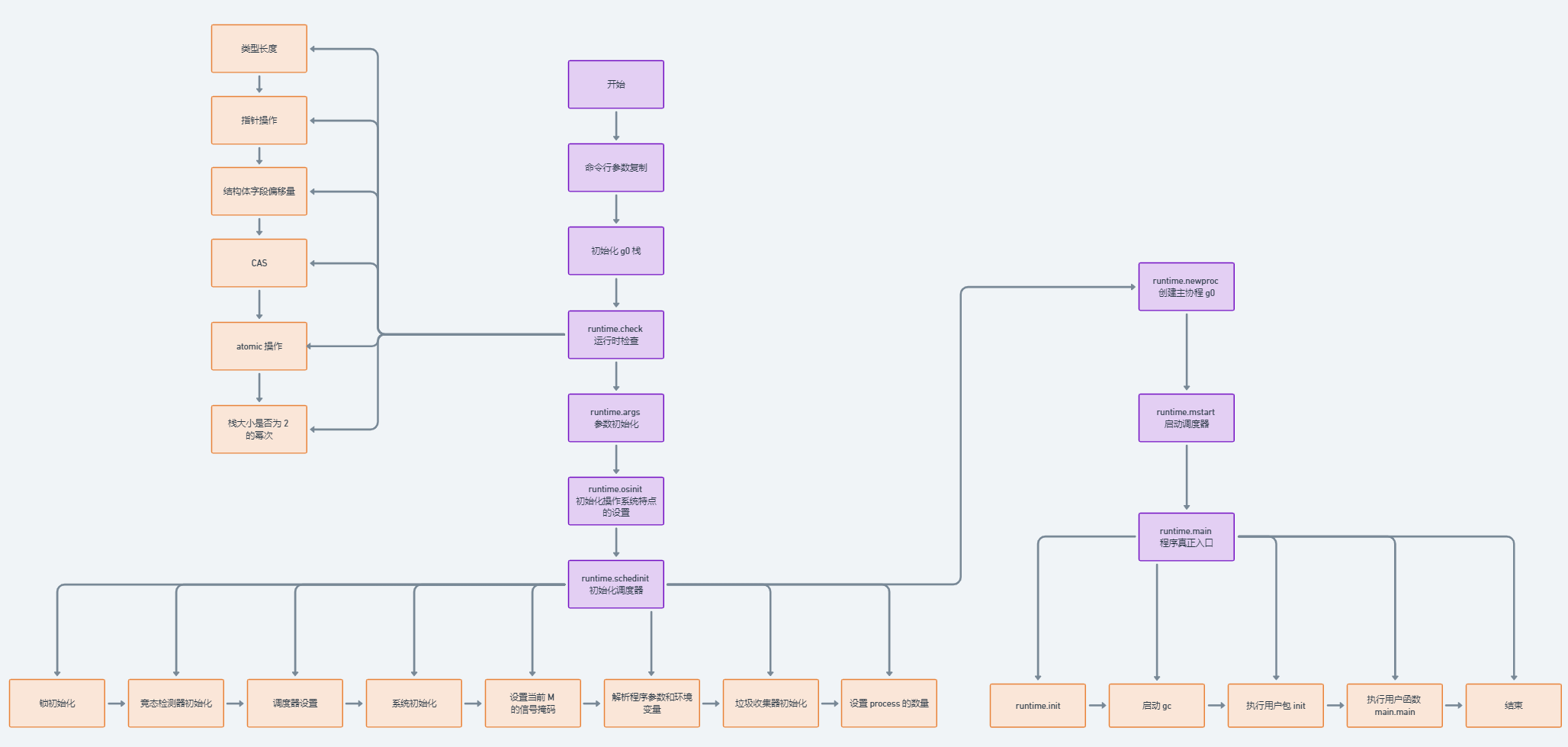
Go 运行时系统初始化流程
了解完 Go 程序的整体启动流程后,我们重点来分析一下其中的
runtime·check、runtime·args、runtime·osinit、runtime·schedinit、runtime·newproc
和 runtime·mstart。
对了,充分理解 Go 启动流程,可能需要你对 Go 的 GMP 模型有一定的了解。
// TODO
runtime·check
在 Goland IDE 上,我们双击 Shift,全局搜索 runtime·check
会发现找不到函数的实现。
Go 语言的运行时系统大部分是用 Go
自己编写的,但是有一部分,特别是与平台相关的部分,是用汇编语言编写的。在汇编语言中,调用
Go 函数的一种方式是使用 CALL
指令和函数的全名,包括包名和函数名。在这种情况下,runtime·check
就是调用 runtime 包下的 check() 函数。
// 调用 SetProcessPriorityBoost 函数,禁用动态优先级提升。 // 在 Windows 中,动态优先级提升是一种机制,可以根据线程的类型和行为自动调整其优先级。 // 但在 Go 的环境中,所有的线程都是等价的,都可能进行 GUI、IO、计算等各种操作, // 所以动态优先级提升可能会带来问题,因此这里选择禁用它。 stdcall2(_SetProcessPriorityBoost, currentProcess, 1) }
runtime·schedinit ★
这个函数就非常重要了,从名字就可以看出来,这是 Go
语言调度器的初始化过程。这个函数位于:runtime/proc.go。
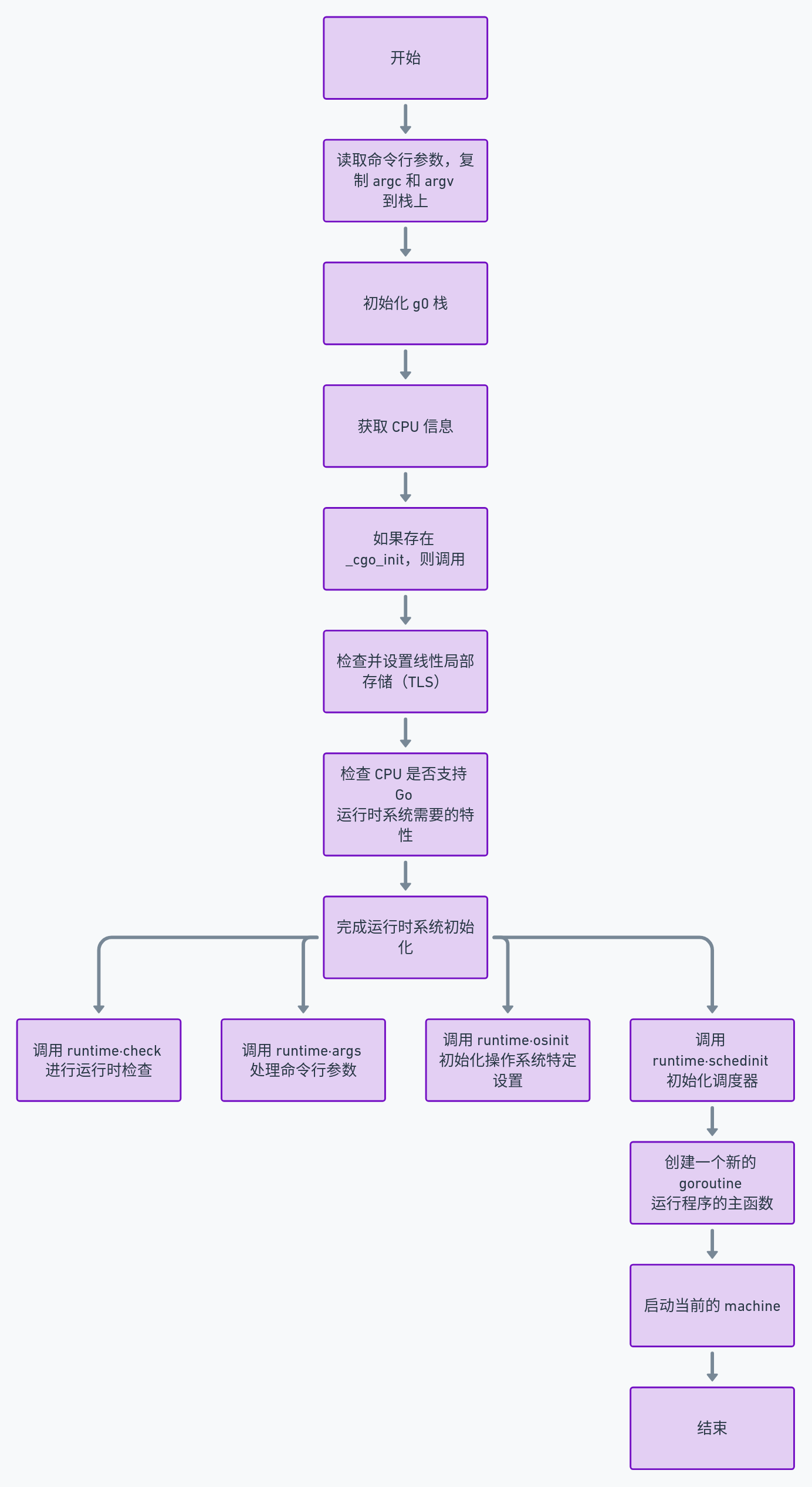
我们可以先来看看 schedinit() 的函数注释,这里也透露了 Go
语言程序的启动流程的核心顺序。
1 2 3 4 5 6 7 8 9
// The bootstrap sequence is: 启动流程顺序: // // call osinit 1. 调用 osinit // call schedinit 2. 调用 schedinit // make & queue new G 3. 创建一个协程 G // call runtime·mstart 4. 调用 mstart // // The new G calls runtime·main. 5. G 执行 runtime.main funcschedinit() {}
// 进行一系列的系统初始化(内存管理、CPU 设置、栈、算法等) moduledataverify() stackinit() mallocinit() godebug := getGodebugEarly() initPageTrace(godebug) // must run after mallocinit but before anything allocates cpuinit(godebug) // must run before alginit alginit() // maps, hash, fastrand must not be used before this call fastrandinit() // must run before mcommoninit mcommoninit(gp.m, -1) modulesinit() // provides activeModules typelinksinit() // uses maps, activeModules itabsinit() // uses activeModules stkobjinit() // must run before GC starts
// 设置和保存当前 M 的信号掩码 sigsave(&gp.m.sigmask) initSigmask = gp.m.sigmask
// 锁定调度器,处理环境变量 GOMAXPROCS,这是开发者可以设置的允许的最多的 P 的数量。 lock(&sched.lock) sched.lastpoll.Store(nanotime()) procs := ncpu if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 { procs = n } if procresize(procs) != nil { throw("unknown runnable goroutine during bootstrap") } unlock(&sched.lock)
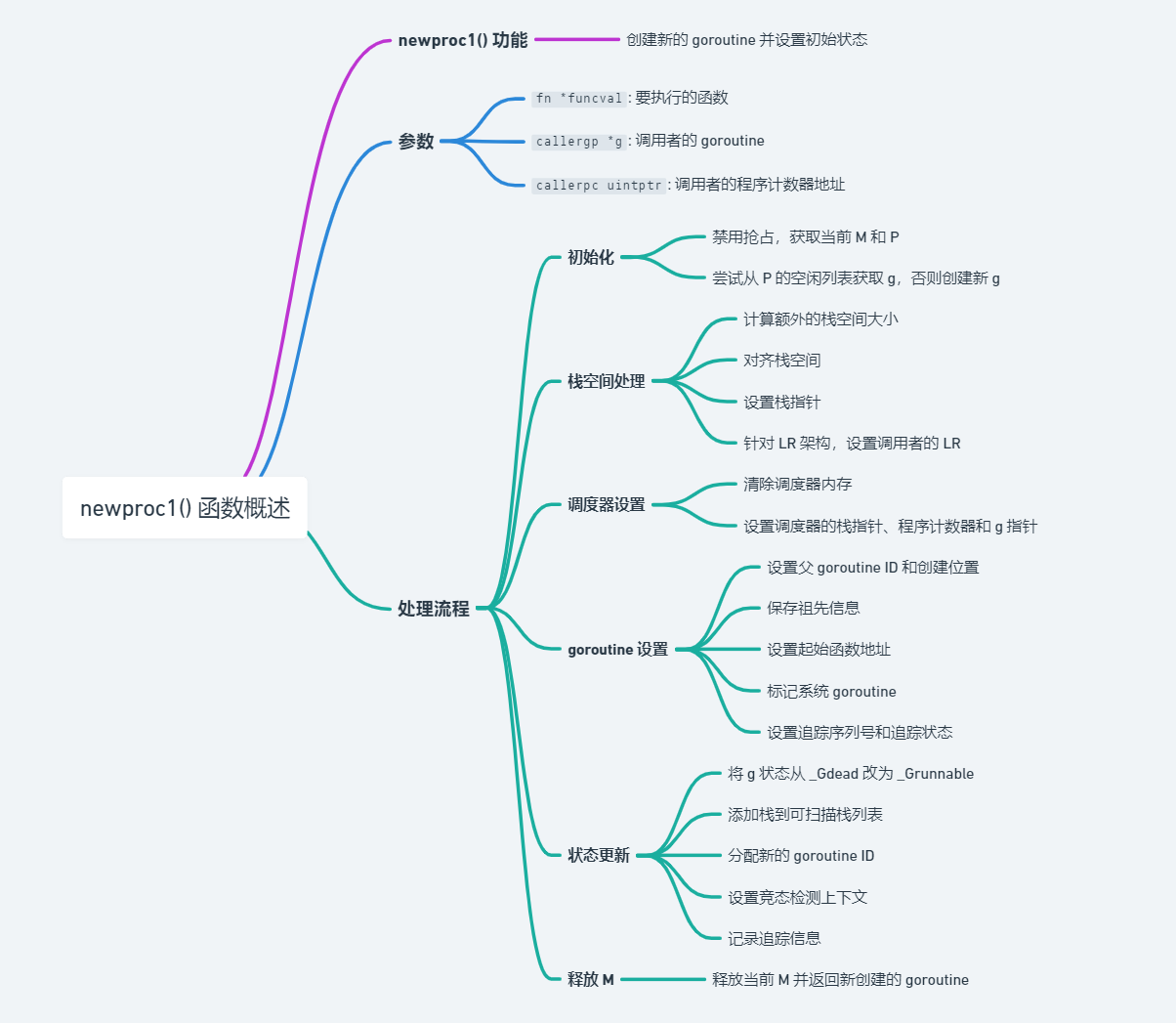
newproc() 的作用如注释所说:创建一个新的
goroutine 来执行 fn,并将它放入等待运行的 g
队列中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// Create a new g running fn. // Put it on the queue of g's waiting to run. // The compiler turns a go statement into a call to this. funcnewproc(fn *funcval) { gp := getg() // 获取当前协程 pc := getcallerpc() // 获取当前程序计数器 systemstack(func() { // 在系统栈上执行新 goroutine 的创建 newg := newproc1(fn, gp, pc) // 创建新 goroutine
pp := getg().m.p.ptr() // 获取当前 M 绑定的 P runqput(pp, newg, true) // 将新创建的 goroutine 放入 P 的本地队列中
// Get from gfree list. // If local list is empty, grab a batch from global list. funcgfget(pp *p) *g { retry: // 如果当前 P 的空闲队列为空,并且全局空闲队列中有可用的 goroutine,则进行下列操作。 if pp.gFree.empty() && (!sched.gFree.stack.empty() || !sched.gFree.noStack.empty()) { // 枷锁全局空闲列表 lock(&sched.gFree.lock) // 将最多 32 个空闲的 g 从全局列表中移动到当前 P 的空闲列表 for pp.gFree.n < 32 { // 优先选择有栈的 g gp := sched.gFree.stack.pop() if gp == nil { // 实在没有栈,也可以接受 gp = sched.gFree.noStack.pop() if gp == nil { break } } sched.gFree.n-- pp.gFree.push(gp) pp.gFree.n++ } unlock(&sched.gFree.lock) // 一直尝试,知道 P 有空闲 g,或者全局列表也没有空闲 g 了,就退出 for 循环,进行下面的操作。 goto retry }
// 从 P 的空闲列表中取出一个 g gp := pp.gFree.pop() if gp == nil { returnnil } pp.gFree.n--
// 检查获取到的 g 是否有一个有效的栈,如果栈不符合预期的大小,则释放旧栈 if gp.stack.lo != 0 && gp.stack.hi-gp.stack.lo != uintptr(startingStackSize) { systemstack(func() { stackfree(gp.stack) gp.stack.lo = 0 gp.stack.hi = 0 gp.stackguard0 = 0 }) } // 如果 g 没有有效的栈,或者刚刚被释放了,则分配新栈给 g if gp.stack.lo == 0 { systemstack(func() { gp.stack = stackalloc(startingStackSize) }) gp.stackguard0 = gp.stack.lo + stackGuard } else { if raceenabled { racemalloc(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo) } if msanenabled { msanmalloc(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo) } if asanenabled { asanunpoison(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo) } } return gp }
// MinFrameSize is the size of the system-reserved words at the bottom // of a frame (just above the architectural stack pointer). // It is zero on x86 and PtrSize on most non-x86 (LR-based) systems. // On PowerPC it is larger, to cover three more reserved words: // the compiler word, the link editor word, and the TOC save word. const MinFrameSize = goarch.MinFrameSize
goarch.PtrSize:指针大小。
1 2 3
// PtrSize is the size of a pointer in bytes - unsafe.Sizeof(uintptr(0)) but as an ideal constant. // It is also the size of the machine's native word size (that is, 4 on 32-bit systems, 8 on 64-bit). const PtrSize = 4 << (^uintptr(0) >> 63)
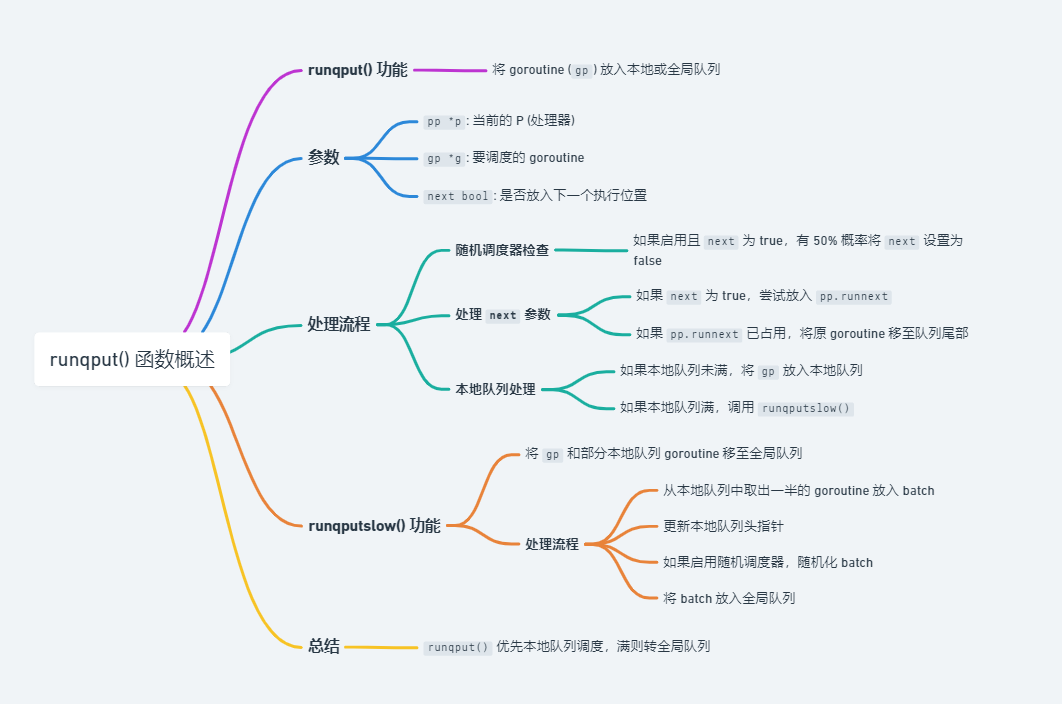
// runqput 尝试将 g 放入当前的执行队列中 // 如果 next=false,则将 g 放在队列末尾, // 如果 next=true,则将 g 放在 pp.runnext,即下一个要执行的 goroutine。 // 如果本地队列满了,则加入到全局队列。 funcrunqput(pp *p, gp *g, next bool) { // 如果启用了随机调度器 (randomizeScheduler), // 并且调用者指示将 goroutine 放入 runnext 位置 (next 为 true), // 则有 50% 的概率将 next 设置为 false,以随机地将 goroutine 放入队列尾部。 if randomizeScheduler && next && fastrandn(2) == 0 { next = false }
if next { retryNext: // 如果为 next,则尝试将 p 放入 pp.runnext 插槽 oldnext := pp.runnext if !pp.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) { goto retryNext } // 如果这个槽之前没有被占用,则直接返回 if oldnext == 0 { return } // 如果这个槽之前已经被占用了,则剔除旧 goroutine, // 然后进行下面的逻辑,即将其放入常规的运行队列中 gp = oldnext.ptr() }
retry: h := atomic.LoadAcq(&pp.runqhead) // 取出队列头部 t := pp.runqtail // 取出队列尾部 // 如果还没满,则将 gp 放入本地队列中(可能是新 g,也可能是之前在 runnext 的 g if t-h < uint32(len(pp.runq)) { pp.runq[t%uint32(len(pp.runq))].set(gp) atomic.StoreRel(&pp.runqtail, t+1) // store-release, makes the item available for consumption return } // 如果本地队列满了,则尝试将其放入全局队列中 if runqputslow(pp, gp, h, t) { return } goto retry }
其中 runqputslow() 不仅会尝试将 gp
放入全局队列中,还会尝试将本地队列的部分 g
放入全局队列中,因为这个时候本地队列已经满了,放入全局队列中就有机会被其他
P 所调度,减少饥饿。
// Put g and a batch of work from local runnable queue on global queue. // Executed only by the owner P. funcrunqputslow(pp *p, gp *g, h, t uint32)bool {
n := t - h n = n / 2 // 只有本地队列满才这么操作 if n != uint32(len(pp.runq)/2) { throw("runqputslow: queue is not full") } // 将本地队列一半的 g 复制到 batch 中 for i := uint32(0); i < n; i++ { batch[i] = pp.runq[(h+i)%uint32(len(pp.runq))].ptr() } // CAS 更新本地队列头指针,如果失败,则返回 if !atomic.CasRel(&pp.runqhead, h, h+n) { // cas-release, commits consume returnfalse } // 将当前要调度的 gp 放入 batch 的末尾 batch[n] = gp
// 如果启动了随机调度器,则随机化 batch 数组 if randomizeScheduler { for i := uint32(1); i <= n; i++ { j := fastrandn(i + 1) batch[i], batch[j] = batch[j], batch[i] } }
// 链接 goroutine,以便它们可以作为一个连续的队列被处理 for i := uint32(0); i < n; i++ { batch[i].schedlink.set(batch[i+1]) } var q gQueue q.head.set(batch[0]) q.tail.set(batch[n])
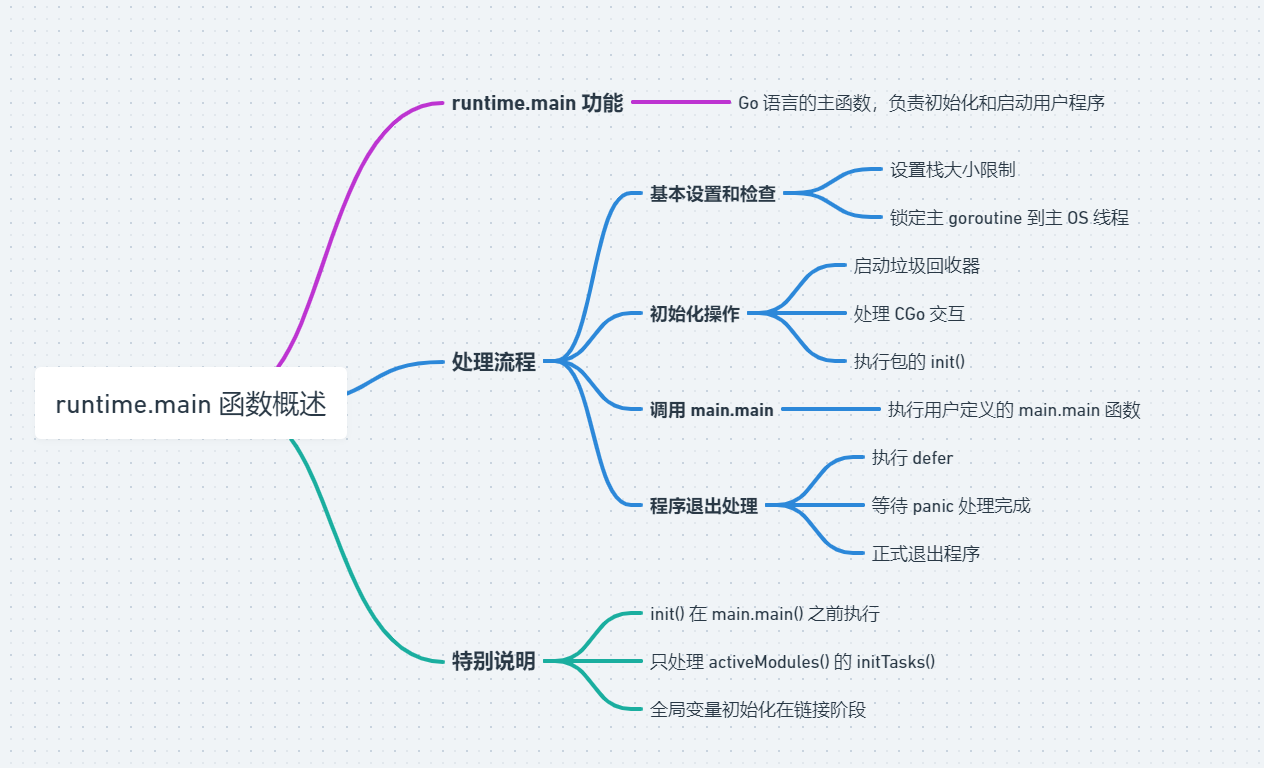
funcmstart0() { gp := getg() osStack := gp.stack.lo == 0 if osStack { // Initialize stack bounds from system stack. // Cgo may have left stack size in stack.hi. // minit may update the stack bounds. size := gp.stack.hi if size == 0 { size = 8192 * sys.StackGuardMultiplier } gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size))) gp.stack.lo = gp.stack.hi - size + 1024 } // Initialize stack guard so that we can start calling regular // Go code. gp.stackguard0 = gp.stack.lo + stackGuard // This is the g0, so we can also call go:systemstack // functions, which check stackguard1. gp.stackguard1 = gp.stackguard0 mstart1() // Exit this thread. if mStackIsSystemAllocated() { // Windows, Solaris, illumos, Darwin, AIX and Plan 9 always system-allocate // the stack, but put it in gp.stack before mstart, // so the logic above hasn't set osStack yet. osStack = true } mexit(osStack) }
// 以 -buildmode=(c-archive|c-shared) 方式进行构建程序的话,则不执行 main.main if isarchive || islibrary { // A program compiled with -buildmode=c-archive or c-shared // has a main, but it is not executed. return }
// 执行 main.main() 函数,也就是我们自己写的 main() fn := main_main fn() // 如果我们启动了一个 server 服务,这里就会被阻塞住,直到我们的 main 返回。
// 静态检测输出 if raceenabled { runExitHooks(0) // run hooks now, since racefini does not return racefini() }
// 处理在 main 返回时同时存在的其他 goroutine 的 panic if runningPanicDefers.Load() != 0 { for c := 0; c < 1000; c++ { // 执行 defer if runningPanicDefers.Load() == 0 { break } Gosched() } } // 阻塞 g0 的执行,直到所有的 panic 都处理完毕 if panicking.Load() != 0 { gopark(nil, nil, waitReasonPanicWait, traceBlockForever, 1) }
// 执行 hook 退出函数 runExitHooks(0) // 退出程序,0 表示正常退出 exit(0) // 理论上 exit(0) 应该退出程序的, // 如果还没退出,使用 nil 指针强行赋值,引发崩溃,强行退出程序。 for { var x *int32 *x = 0 } }