
Go
语言以其简洁的语法和强大的并发支持而闻名。在这些特性中,defer
语句是 Go
语言提供的一项独特功能,它允许我们推迟函数的执行直到包含它的函数即将返回。这个简单而强大的机制不仅可以帮助我们处理资源释放和错误处理,还能让代码更加简洁和安全。本文将深入浅出地介绍
defer
的工作原理,探究其背后的机制,并通过丰富的案例来展示它的实际应用。
笔者本来以为 Go 语言的 defer
其实东西不多,就是类似于“栈”的操作罢了,无非就是用于释放资源、后进先出而已。但是最近在阅读完《深入理解
Go 语言》、《Go 底层原理剖析》和《Go 语言设计与实现》中关于
defer
的篇章。发现其中隐含的道道和坑还是比较有意思的,特此整理这篇文章,希望能对
Go defer 原理感兴趣的读者带来一些帮助。
本文具体会包含以下内容:
defer机制简介:介绍defer关键字的基本概念和它在 Go 语言中的作用。defer的工作原理:深入探讨defer在函数执行结束时如何工作的细节。defer的执行顺序:解释defer语句是如何按照后进先出(LIFO)的顺序执行的。- 参数预计算和值传递:讨论
defer语句中参数是如何被预先计算和传递的。 - 环境变量和闭包:探讨
defer如何与闭包一起工作,以及如何捕获和影响环境变量。 defer与错误处理:说明如何利用defer和recover进行错误处理和异常捕获。defer的实现细节:深入分析defer的不同实现策略,包括堆上分配、栈上分配和开放编码。
版本声明
- Go1.22
思维导图
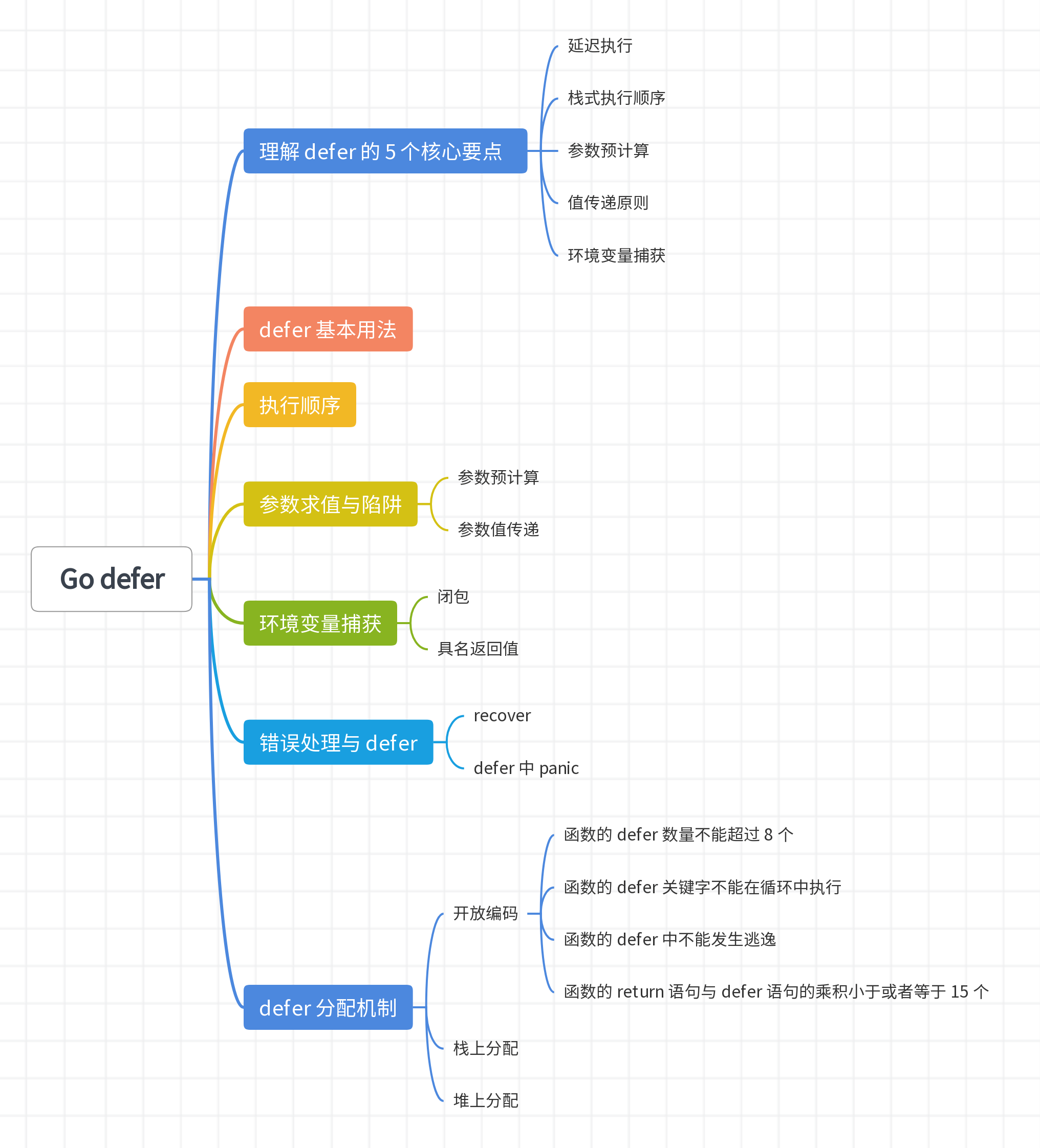
核心要点
对于后面将要分析的各种各样的情况,在分析的时候只要遵循以下几个核心点,基本上就不会跑偏:
- 延迟执行:在函数结束时执行,包括正常返回或遭遇 panic。
- 栈式执行顺序:后定义的
defer先执行(LIFO)。 - 参数预计算:
defer语句定义时即计算并固定参数值。 - 值传递原则:
defer拷贝参数,使用定义时的值。 - 环境变量捕获:在
defer中可以跟一个闭包,闭包可以捕获环境变量,当然这包括具名返回值。
特别说明的是,虽然我们通常将 defer
想象为使用栈进行管理,但是实际实现上,defer
并不都是存放在栈上的,我们后面会具体分析到。这种实现细节通常对于编写正确的
Go
代码并不重要,但了解这一点对于深入理解语言内部机制可能是有帮助的。
基本用法
在 Go 语言中,defer
语句通常用于确保一个函数调用在程序执行结束时发生,常见的用例包括文件关闭、锁释放、资源回收等。
1 | func readFile(filename string) error { |
在上面的例子中,defer f.Close() 保证了无论
readFile
函数如何返回(正常返回或发生错误),f.Close()
都会被调用,从而避免了资源泄露。
执行顺序
defer
的执行顺序是先进后出,即“栈”操作。这里借用刘丹冰老师的一张图来演示这个过程:
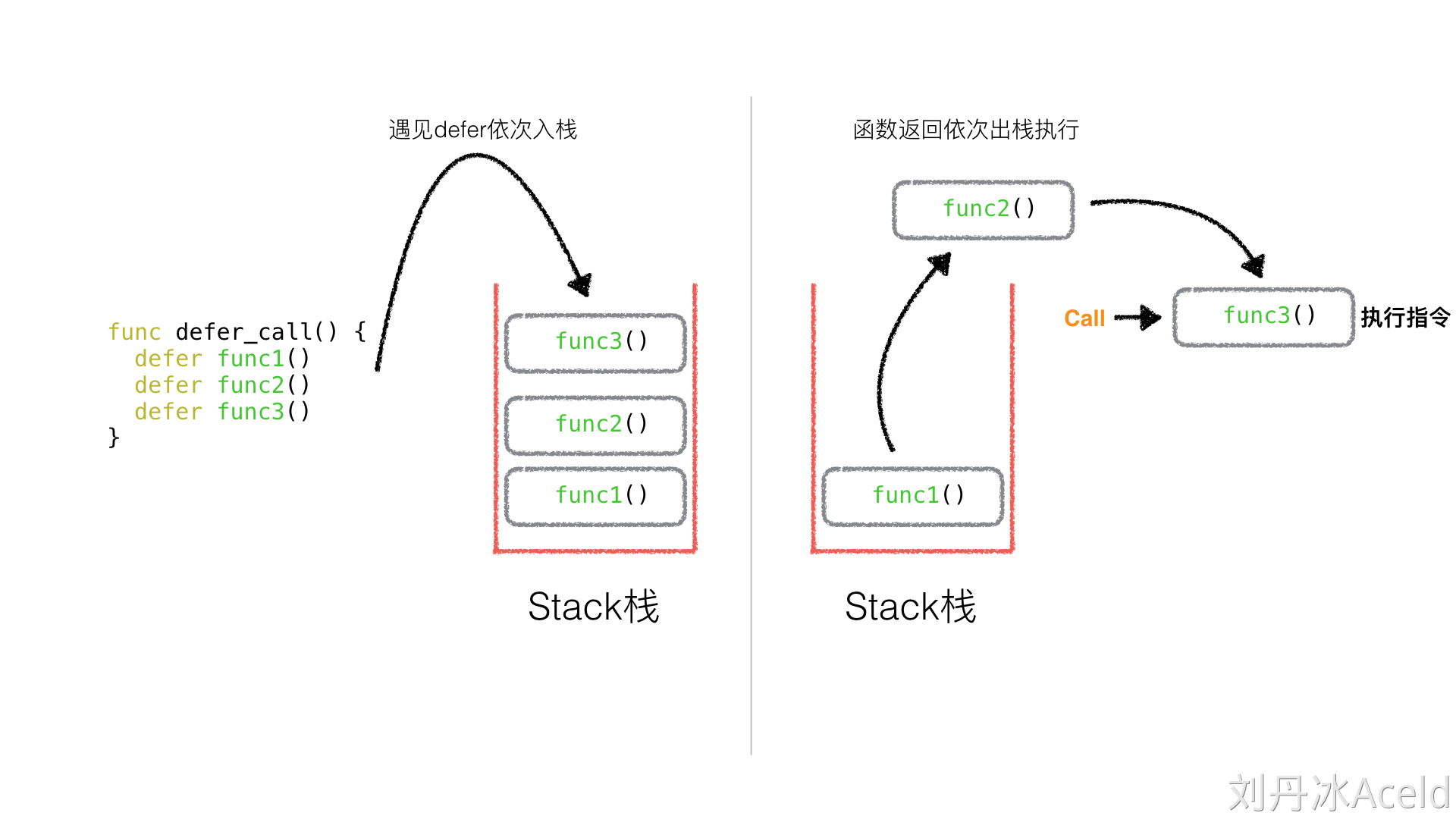
我们可以通过以下代码进行验证:
1 | func func1() { |
输出如下:
1 | func3... |
参数求值与陷阱
关于 defer
参数这一块,是一个比较容易出错的地方。我们先来看一个例子,你可以分析下它的输出会是什么?
1 | func printI(i int) { |
按照我们之前总结的核心点:参数预计算:defer
语句定义时即计算并固定参数值。具体来说,在把 defer
压入“栈”时,会同时压入函数地址和函数形参,也就是会在这个时候就把参数先算好。所以在执行到第
7 行代码的时候,就会把 i*10 算好,然后同
printI 一同压入到延迟执行栈中。
所以最后的结果就是:
1 | main i: 11 |
关于参数值传递,笔者这里再举两个例子进行比较,体会后你应该就理解了。
第一个例子中,defer
后面参数是指针,本质上值传递,但是拷贝的是指针,所以在
defer 中修改的东西,最后会反馈到指针指向的对象,所以对
testUser 的返回值是有影响的。
1 | type User struct{ |
第二个例子中,我们传入的就是结构体示例本身了,因为值传递,即拷贝了一份新的
user,所以闭包内的修改对外面是不产生影响的。
1 | type User struct { |
环境变量捕获
将上面的一个例子进行简单修改,会输出什么呢?
1 | func printI(i int) { |
这个时候其实没有参数,所以会直接将下面闭包压入延迟栈中。
1 | func() { |
而闭包是可以捕获环境变量的,所以在 main return
后,defer 可以捕获到 i 的值,为更新后的
i+1,最后再进行 printI(i * 10)。
所以输出结果是:
1 | main i: 11 |
所以说,defer
后面的闭包,是可以捕获环境变量的,如果这个变量是返回值的话,那么理所应当也是可以对其产生作用的,如:
1 | func getI() (i int) { |
这段代码中,getI 的返回值是有名字的
i,getI 执行了
return 20,其实就是将 i 设置为
20,所以在执行到 defer 闭包的时候,捕获到了
i=20,并将其进行了修改。所以最终输出:
1 | 200 |
错误处理与 defer
我们都知道 Go 程序中遇到 panic
就会中断后面的执行流程直接返回,这个时候我们可以在 defer
中结合 recover 来捕获这个
panic,从而保护程序不崩溃。
如:
1 | func panicAndRecover() { |
更进一步,如果我们在 defer 中也有 panic
呢?请思考下列代码:
1 | func panicAndRecover() { |
上述代码中,我们在 panicAndRecover 强行抛出
panic,由于 defer 先进后出,所以我们会先执行第
2 个 defer,其中也发生了 panic,我们在第 1 个
defer 中对 panic 进行
recover,最终的现象是只捕获到了后面抛出的
panic:
1 | panicAndRecover 函数中正常流程 |
这是为什么呢?
在 Go 语言中,panic 函数实际上是创建了一个
panic 对象,并抛出这个对象。
当一个 panic 发生并开始向上传播时,Go 运行时会检查每个
defer。如果 defer 中包含 recover
调用,并且它被执行,那么 recover 会捕获当前的
panic,并且防止它继续向上传播。如果 defer
中再次发生 panic,那么原来的 panic 就不会被
recover 捕获,因为 defer
函数已经退出了。在这种情况下,新的 panic
会导致程序崩溃,因为没有更多的 defer 函数去
recover 这个新的 panic。
这说明了 Go 程序中不允许同时有多个活跃的 panic
存在,这个设计确保了在任何给定的时刻,只有一个 panic
能够被处理。这样做有几个原因:
- 简化错误处理: 如果同时存在多个
panic,就会变得非常复杂去确定如何处理它们,尤其是在它们之间存在依赖关系的时候。一个panic应该表示一个不可恢复的错误,如果有多个这样的错误同时存在,程序的状态可能会变得非常不确定。 - 保持一致性:
panic通常表示程序中出现了严重错误,可能会破坏程序的一致性或安全性。如果允许多个panic同时存在,就很难保证程序状态的一致性,因为不同的panic可能需要回退不同的操作。 - 避免资源泄漏:
defer语句用于确保资源被释放,例如文件和锁。如果在处理一个panic的过程中,又发生了另一个panic,可能会导致defer语句中剩余的清理代码无法执行,从而引起资源泄漏。 - 控制流程清晰:
panic和recover的设计使得错误的控制流程清晰且可预测。一旦一个panic被recover捕获,程序可以选择是否继续执行,或者是通过重新panic来终止程序。这种决策过程在多个panic情况下会变得复杂且难以管理。
因此,在 Go 的设计中,不允许同时存在多个活跃的
panic。一旦发生 panic,它必须被
recover
处理,否则程序将会终止。这确保了错误处理的清晰性和程序的稳定性。
defer 放在哪
defer 实际上不一定是放在栈上的,截止
Go1.22,defer 其实用 3 种分配策略:
- 堆上分配
- 栈上分配
- 开放编码
执行机制
在 ssa.go
文件中,我们可以找到 state.stmt(),这个函数是负责在 Go
程序编译过程中中间代码生成阶段时对不同语句的处理过程,其中对于
ODEFER 即 defer 语句的处理逻辑如下:
1 | // stmt converts the statement n to SSA and adds it to s. |
可以看到,总共有 3 种分配策略:
- open-coded: s.hasOpenDefers == true
- stack-allocated: n.Esc() == ir.EscNever
- heap-allocated: 默认
默认是堆分配,在 Go1.13
以前,也只有堆分配这一种策略,不过该实现的性能较差。Go 语言在 1.13
中引入栈上分配的结构体,减少了 30%
的额外开销,并在 1.14 中引入了基于开放编码的
defer,使得该关键字的额外开销几乎可以忽略不计。
本文中不对具体的分配机制进行分析,这一块会比较复杂,笔者本身也不是很感兴趣,便决定对此不过分深究,感兴趣的读者推荐详细阅读《Go
语言设计与实现》中关于 defer
关键字的分析:https://draveness.me/golang/docs/part2-foundation/ch05-keyword/golang-defer/。
本文只讨论什么情况下会使用什么分配策略。由于堆分配是默认的,我们就不作分析了,具体来看看
s.hasOpenDefers == true 和
n.Esc() == ir.EscNever 什么时候会成立。
栈上分配
我们先来看栈上分配,要满足栈上分配,则需要满足
n.Esc() == ir.EscNever。
1 | const ( |
当 n 的逃逸分析结果是 ir.EscNever,则表明该
defer
语句从不逃逸(不会在函数调用结束后仍然被引用),这种情况下
defer 将被分配到栈上(stack-allocated)。否则,如果
defer 逃逸了,就会被分配到堆上(heap-allocated)。
那 defer 语句什么时候会逃逸呢?
在 Go 中,一个变量的逃逸意味着它的生命周期超出了当前函数的范围。在函数内定义的变量通常分配在栈上,而在堆上分配内存需要更复杂的管理。在一些情况下,编译器可能会选择将变量分配在堆上,这种情况下我们称之为逃逸。
对于 defer 语句,如果它引用了函数外的变量,这个
defer 就会逃逸。例如:
1 | var x = 10 |
在这个例子中,defer 函数内部引用了 x
这个外部变量,因此 defer 语句需要确保 x 在
defer 函数执行时仍然有效。为了满足这个条件,编译器可能会将
x 分配在堆上,而不是栈上。
开放编码
先给结论,在开发过程中,要使用开放编码策略,你只需要关注以下 4 点即可:
- 函数的
defer数量不能超过 8 个; - 函数的
defer关键字不能在循环中执行; - 函数的
defer中不能发生逃逸; - 函数的
return语句与defer语句的乘积小于或者等于 15 个;
Ok,下面是具体的分析过程。
借助 Goland 的能力,将鼠标光标放在 s.hasOpenDefers
上,按住 Command
加点击鼠标,可以看到该属性的使用情况:
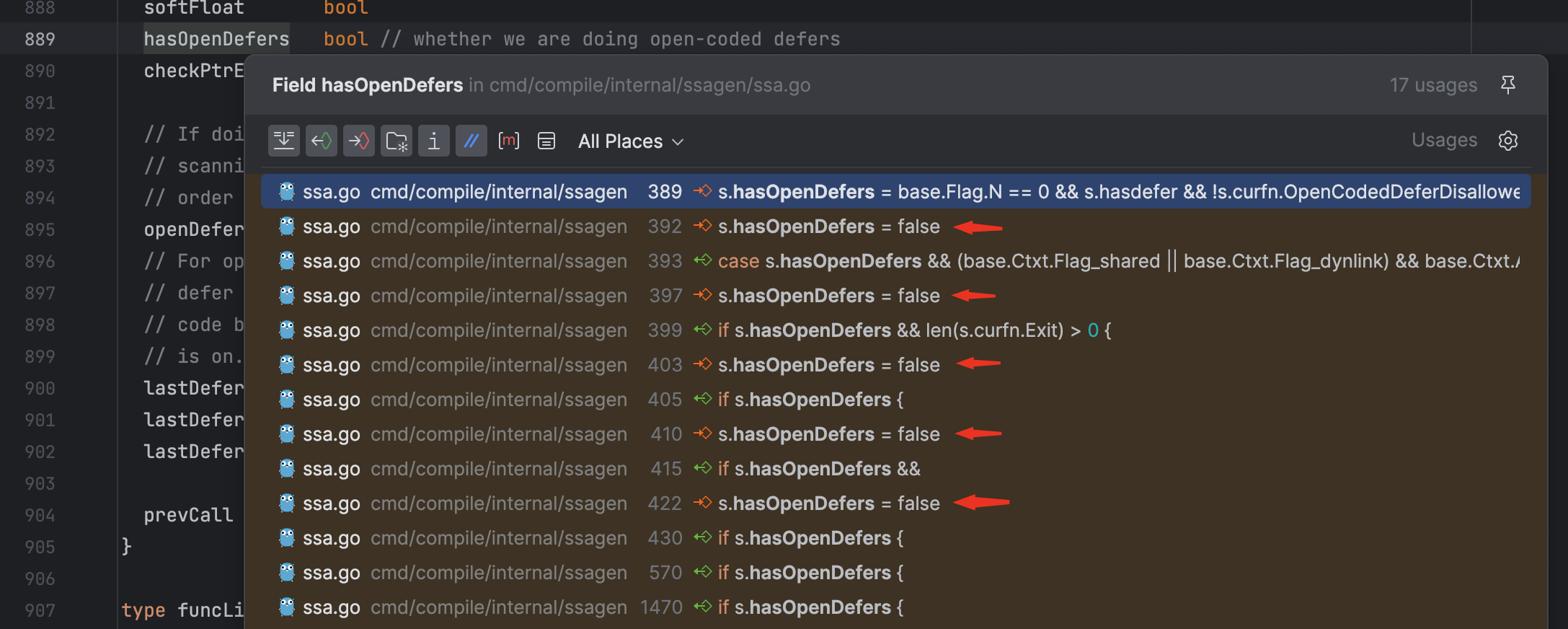
可以看到该属性的判断逻辑都在 ssa.go
文件中的 buildssa()
函数中。去掉一些无关的代码,核心逻辑如下:
1 | // buildssa builds an SSA function for fn. |
可以看到总共有 6 个条件,我已在注释中进行标注,我们来进行逐一分析:
① base.Flag.N == 0 && s.hasdefer && !s.curfn.OpenCodedDeferDisallowed()
如果
base.Flag.N等于 0 且当前函数有延迟调用且没有禁止开放式延迟,那么设置s.hasOpenDefers为true。
在 Go
编译器中,-N标志通常用于禁用优化。在这段代码中,如果base.Flag.N等于
0,意味着没有禁用优化,因此编译器可能会尝试使用更高级的优化技术,比如开放式延迟(open-coded
defers)。
OpenCodedDeferDisallowed()
即禁用开放编码,它的实现如下:
1 | const funcOpenCodedDeferDisallowed // can't do open-coded defers |
按住 Command 后点击 funcOpenCodedDeferDisallowed
可以看到只有 funcOpenCodedDeferDisallowed(b)
可以修改它的值。

我们来看看哪个地方会调用
funcOpenCodedDeferDisallowed(),并将
funcOpenCodedDeferDisallowed 设置为 true:

调用它的地方在 stmt.go
文件中的 walkStmt() 函数,具体如下:
1 | // The max number of defers in a function using open-coded defers. We enforce this |
第一点是:当前函数中 defer 个数超过 8
的话,则禁用开放编码。
第二点是当 n.Esc() != ir.EscNever
使,就禁用开放编码。这个要求跟前面分析的“栈上分配”要求是一样的。
这里再补充一点:什么时候 n.Esc() 会被设置为
ir.EscNever 呢?

这里面核心点是第一个,它对应的代码如下:
1 | func (e *escape) goDeferStmt(n *ir.GoDeferStmt) { |
e.loopDepth == 1 时就设置,换言之,defer
不在循环中的时候,才允许开放编码。
总而言之,第 ① 个条件约束了要采用
open-coded 开放编码策略的 3 个条件:
- 函数中
defer个数不能超过 8; defer不能在循环中;defer不能发生逃逸。
② base.Debug.NoOpenDefer != 0
如果
base.Debug.NoOpenDefer不为 0,那么禁用开放式延迟。
1 | NoOpenDefer int `help:"disable open-coded defers" concurrent:"ok"` |
③ (base.Ctxt.Flag_shared || base.Ctxt.Flag_dynlink) && base.Ctxt.Arch.Name == "386"
如果当前架构是
386,并且使用共享库或动态链接,那么不支持开放式延迟,因为存在一些额外的代码(由rewriteToUseGot()添加)可能无法正确追踪。
④ len(s.curfn.Exit)
如果存在任何额外的退出代码(比如可能是竞态检测相关的代码),则跳过开放式延迟。
⑤ !f.Nname.(*ir.Name).OnStack()
如果有任何堆分配的结果参数需要复制回它们的栈槽,也跳过开放式延迟。
⑥ s.curfn.NumReturns*s.curfn.NumDefers > 15
如果函数的返回数乘以延迟调用数大于 15,考虑到每个退出点都要生成延迟调用,并且开放式延迟对于小函数(没有多个返回)的性能提升最为重要,所以在这种情况下也不使用开放式延迟。
堆上分配
当不满足开放编码和栈上分配的时候,默认就是堆上分配(heap-allocated),性能最差,这里不做分析。
以上就是本文关于 Go 语言中 defer 关键字的具体分析,Happy
Coding! Peace~
参考
- 深入理解 Go 语言
- Go 语言底层原理剖析
- Go 语言设计与实现
- ChatGPT4
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




