在分布式追踪系统中,采样策略直接影响着系统的性能和可观测性。OpenTelemetry 作为当前最流行的可观测性框架,其采样机制设计有着深刻的考量。本文将深入探讨 OpenTelemetry 的采样机制,特别是为什么它在 SDK 层面不支持尾采样。
前置采样 vs 尾采样
在讨论 OpenTelemetry 的采样机制前,我们需要理解两种主要的采样策略:
前置采样(Head-based Sampling):
- 在链路开始时就决定是否采样
- 决策一旦做出,整个链路都遵循这个决策
- 不需要缓存完整的链路数据
尾采样(Tail-based Sampling):
- 在链路结束后决定是否保留
- 可以基于完整链路信息(如总耗时、是否有错误)做决策
- 需要临时缓存所有链路数据
OpenTelemetry 的采样实现
通过分析 OpenTelemetry Go SDK 的源码,我们可以清晰地看到它采用的是前置采样策略。关键代码如下:
1 | func (tr *tracer) newSpan(ctx context.Context, name string, config *trace.SpanConfig) trace.Span { |
这段代码揭示了几个关键点:
- 采样决策在 span 创建时就已经做出
- 采样标志通过位操作设置在 TraceFlags 中
- 这个标志会随着 SpanContext 传播到整个分布式系统
采样标志的传播机制
特别值得注意的是设置采样标志的代码:
1 | if isSampled(samplingResult) { |
这段代码使用位操作来设置或清除采样标志:
|操作用于设置采样标志,保留其他标志位不变&^操作用于清除采样标志,同样保留其他标志位不变
这确保了采样决策能够一致地传播到整个分布式链路中。
为什么 OpenTelemetry 不支持尾采样?
最重要的原因是:在 SDK 中找不到尾巴!因为不知道链路什么时候结束!
在分布式系统中,一条链路可能跨越多个服务,所以你在某一个服务中,是不知道链路是否结束的,而
OpenTelemetry 也不是一次性上报一整条链路,而是每个 span
独立上报,最后再拼接到一起。
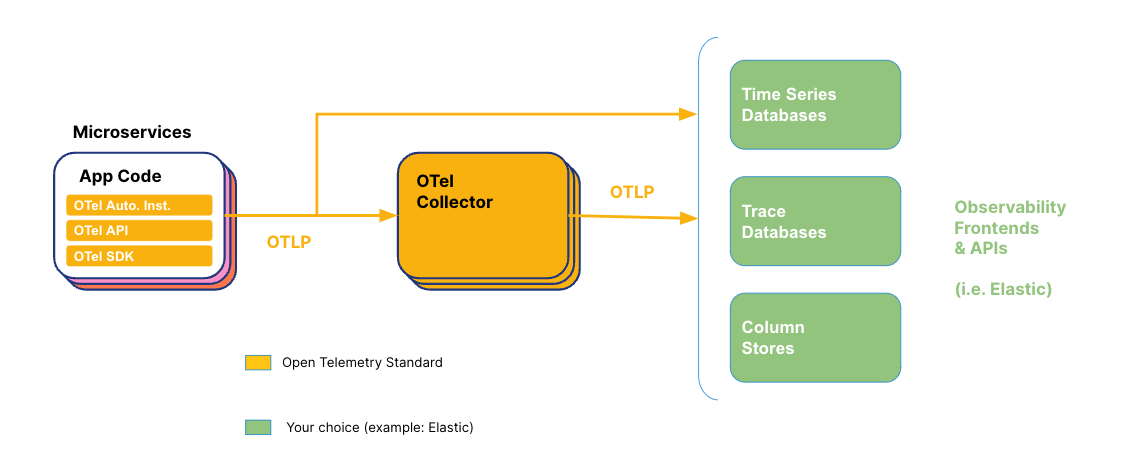
OpenTelemetry 上报原理
独立上报
每个
span在结束时(调用span.End())会被传递给SpanProcessorSpanProcessor决定如何处理这个span(立即导出或批量导出)导出是独立的,不会等待整个
trace完成
批处理机制
默认使用
BatchSpanProcessor,它会收集一定数量的spans或等待一定时间然后批量导出但这个批处理与
trace完整性无关,只是为了效率
Collector 如何实现尾采样
Collector 通过以下方式解决这些问题:
设置等待时间窗口
为每个 trace 设置一个等待期(如 10 秒)
在此期间收集该 trace 的所有 spans
超过等待期后,基于已收集的 spans 做决策
集中式收集
所有服务的 spans 都发送到 Collector
Collector 有更全面的视图来关联 spans
专门的资源分配:Collector 作为独立组件,有专门的资源处理这种复杂逻辑,不会影响应用性能。
如何在 OpenTelemetry 生态中实现尾采样?
虽然 SDK 不直接支持尾采样,但 OpenTelemetry 生态提供了其他方式实现类似功能:
1. 使用 OpenTelemetry Collector
Collector 提供了 Tail Sampling Processor,可以在数据聚合层实现尾采样:
1 | processors: |
2. 结合前置采样和错误捕获
可以实现一个智能的前置采样器,对特定场景(如包含错误属性)强制采样:
1 | type SmartSampler struct { |
3. 使用专门的后端系统
一些专门的可观测性后端系统提供了尾采样功能:
Jaeger 的 Adaptive Sampling
SkyWalking 的 Trace Sampling
Grafana Tempo 的 Trace Sampling
结论
OpenTelemetry SDK 采用前置采样而非尾采样,是基于分布式系统一致性、性能优化和架构分层等多方面考虑的结果。虽然这意味着无法基于完整链路信息做采样决策,但 OpenTelemetry 生态提供了多种方式来弥补这一限制。
在实际应用中,我们可以:
- 在 SDK 层使用智能前置采样策略,确保关键链路被采样
- 在 Collector 层实现尾采样,进一步筛选有价值的链路
- 结合使用多种采样策略,平衡性能和可观测性
通过这种分层设计,OpenTelemetry 既保证了高效的数据收集,又为高级采样策略提供了可能性,满足了不同场景的需求。
 实战案例
实战案例

笔者实现一个 Go 语言的开源项目 goapm,对多个 Go
语言中常用的组件进行了 trace、log 和 metrics 的集成封装,用于快速在 Go
语言项目中实现可观测性,同时还提供了 goapm-example
实战案例,可供参考。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。



