
以下均以 InnoDB 引擎为基础进行分析。假设我们现在有 3 行数据,如下:
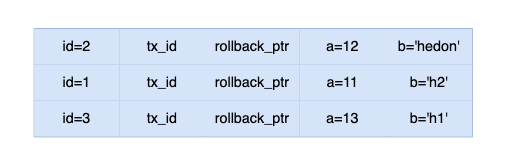
其中:
id是主键索引。a和b都是数据字段。tx_id是隐藏字段,表示事务 id,用于实现 MVCC。rollback_ptr是回指针,用于 undo log。
在将数据存储到文件的时候,我们会将这三行数据进行序列化,然后以二进制流的形式存储到文件中。
现在我们要解决第一个问题:
 如何按照主键(id)排序?
如何按照主键(id)排序?

在 InnoDB 中,会在每一行的前面,加一个 next_record
字段,用于指向比当前数据 id 大的下一条数据,我们假设一行数据占 20
个字节,那么就如下图所示:
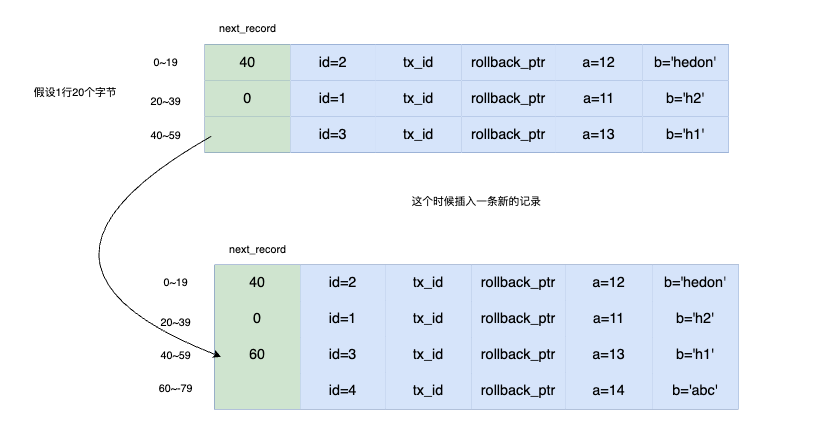
另外,为了便于定位每一行,InnoDB 会在每一行前面再加一个字段
heap_no,它的规则很简单,就是自增,在内部会用于定位一行记录,方便上锁等各种操作。
所以现在的存储结构如下图所示:

现在我们来解决解决第二个问题:
如何快速定位到起点(最小)和终点(最大)?
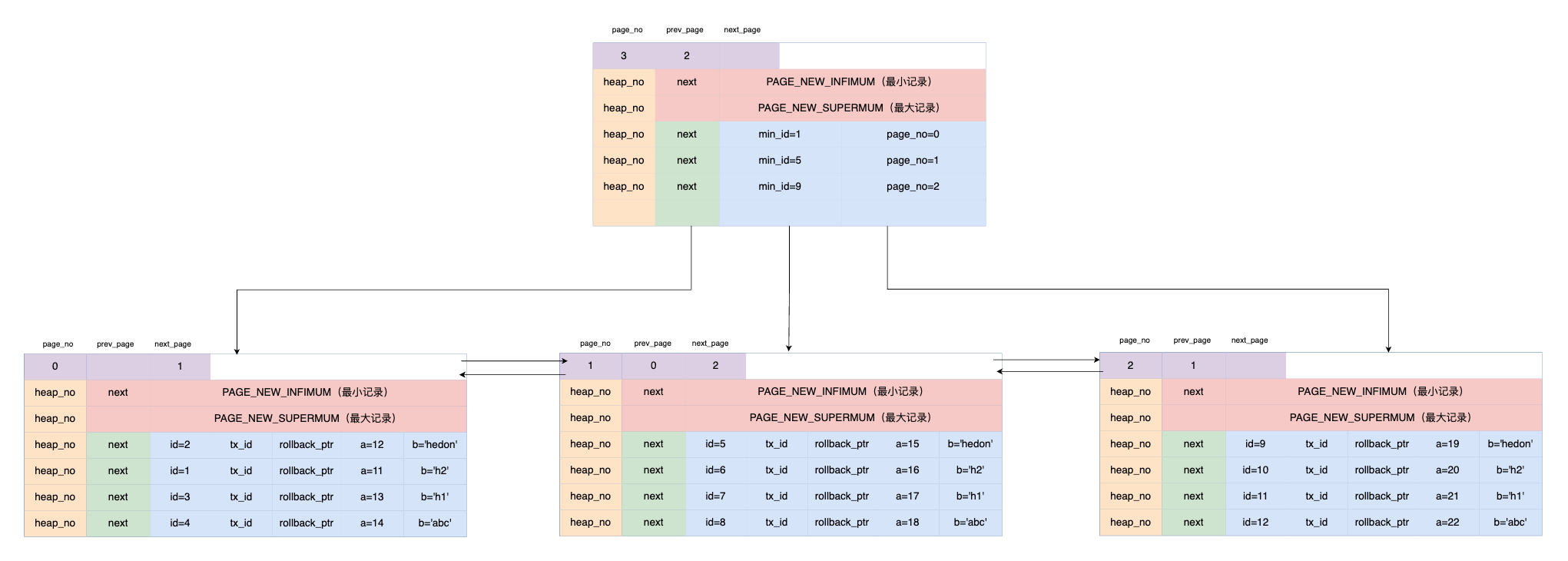
在最前面加 2 条特殊的记录:
PAGE_NEW_INFIMUM:指向最小记录。PAGE_NEW_SUPERMUM:最大记录,最大的一个 id 会指向它。

第三个问题:
每次 select * from t where id = ? 都要进行 I/O 操作吗?
很显然是不行的,效率太低了。这个相信绝大多数读者都知道 ,InnoDB 会以 Page(默认 16KB)为最小单位,一次性将数据从磁盘加载到内存中。为此,需要在最前面再加一条记录,且该记录的前三行分别为:
page_no:页号,自增,InnoDB 最多支持 32 位页号,所以存储上限是 16KB * 232 = 64T。prev_page:指向上一页。next_page:指向下一页。

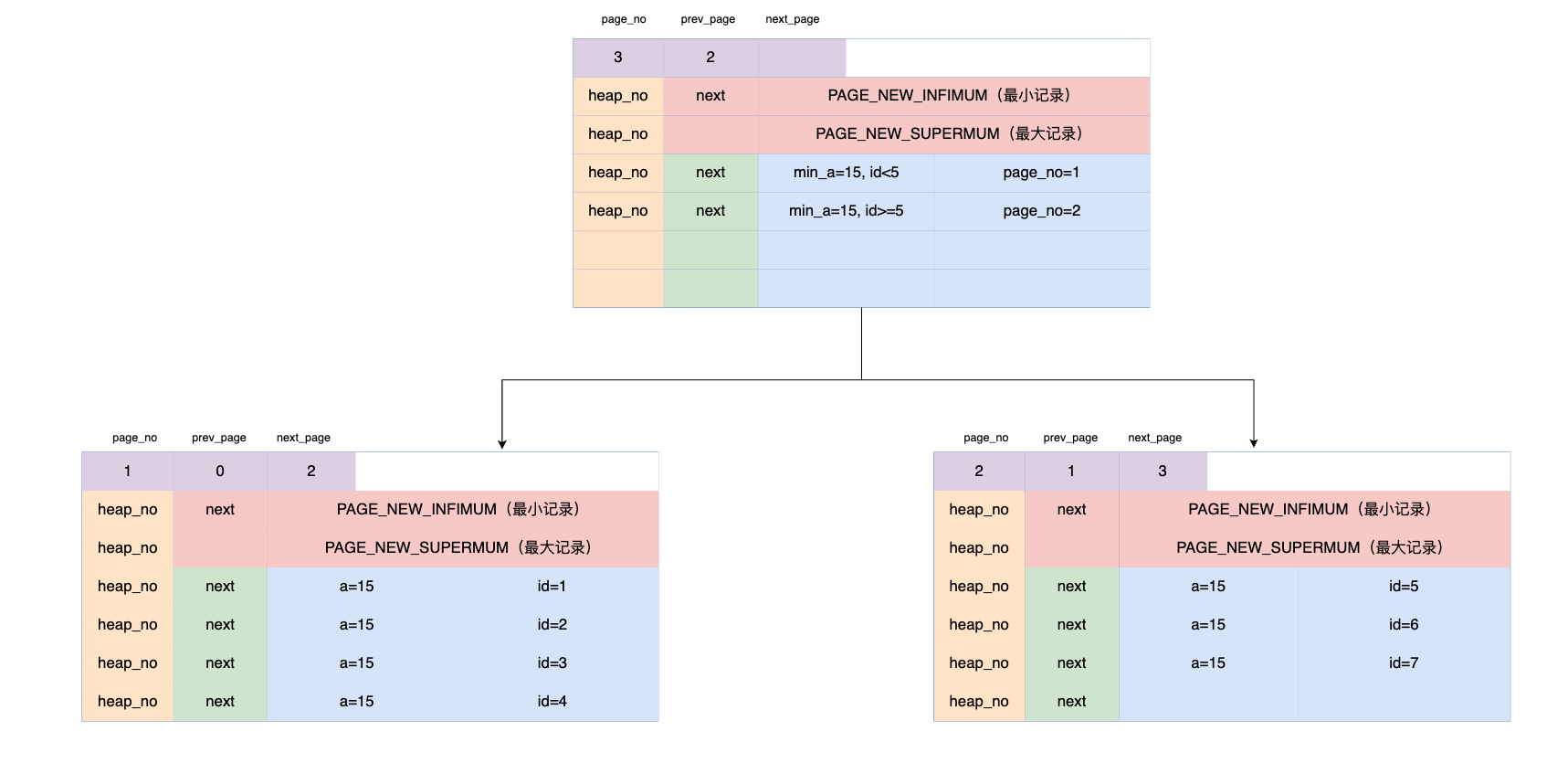
如果一个 Page 放不下呢?
很显然,那就要进行分页,即按照 ID 的顺序进行一分为二,前者取范围
[a, b),后者取范围 [b, c)。

如何快速定位到数据在哪个 Page 上呢?
这个时候,我们需要新创建一个 Page,专门用于管理这些数据 Page 的,这个 Page 我们这里暂且称为索引 Page。
其中核心数据就是 2 个:
min_id:即当前页存储的最小主键 ID。page_no:页号,用于定位到 Page。

这是什么呀?这其实就是 B+ 树!在文件层面的存储,是连续存储的,但是为了便于理解,我们可以在逻辑层面将其绘制成 B+ 树的形态。如下图可以看到这其实就是一颗 B+ 树。
在主键索引树上:
- 叶子节点存储的就是具体某一行的数据(聚簇索引)。
- 非叶子节点存储的是索引。
- 每一层的节点,都是一条有序的双向链表。
如果对非主键索引 a 创建索引呢?
因为要建索引,所以需要先对 a 进行排序,然后针对 a 建立一颗 b+ 树。而且由于 a 是非主键索引,即辅助索引,所以叶子节点存储的是主键的值,用于回表。
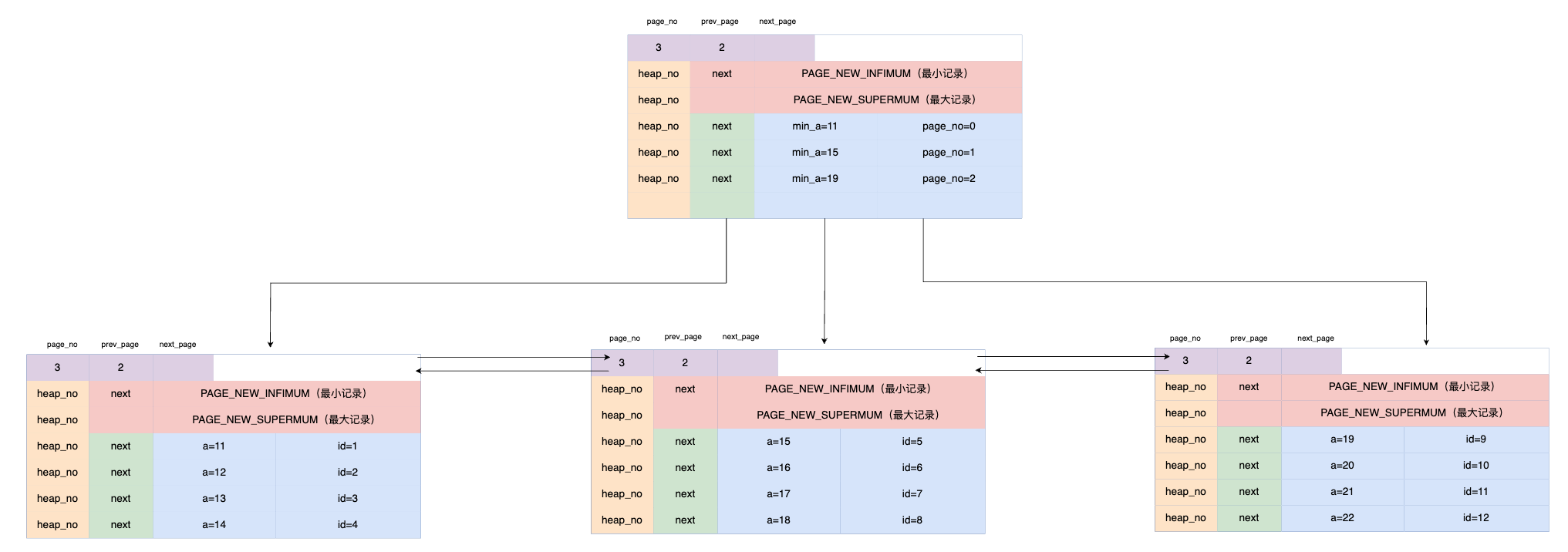
假设 a =15 的数据非常多,一个 page 放不下呢?
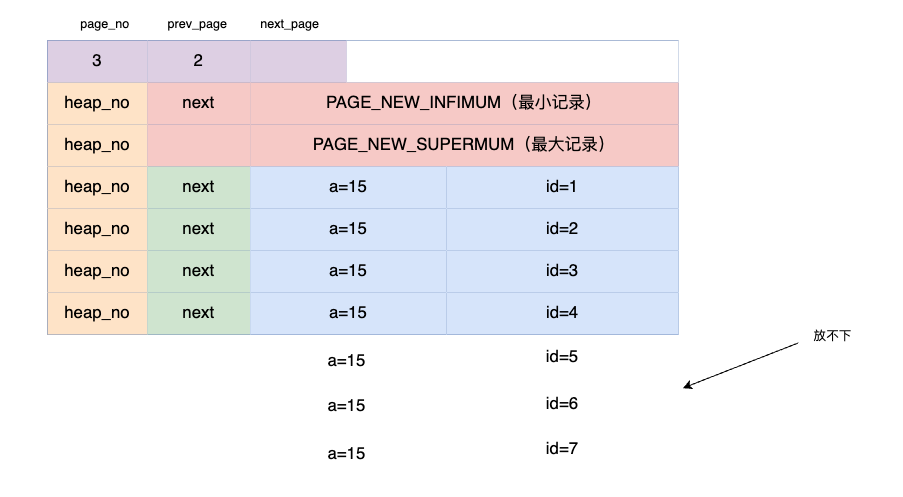
会加入主键 ID 作为二维排序来进行分裂:
估算一下一个三层的 B+ 树可以存储多少条数据?
- 一个 Page 是 16KB
- 假设 1 个 Page 可以存放 1000 个 key
- 假设 1 个 Page 可以存放 200 条记录
基于这种估算:
- 第 1 层:1 个节点是 1 个 Page,存放 1000 个 key,对应 1000 个分叉
- 第 2 层:1000 个节点 1000 个 Page,存放 1000*1000 个 Key,对应 1000*1000 个分叉
- 第 3 层:1000*1000 个 Page,每个 Page 200 条数据,共 1000*1000*200=2 亿条数据 = 16KB*1000*1000=16GB
🐂🐂🐂
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。



