
本篇在上一篇的基础上,梳理下笔者的个人见解,感兴趣的读者可参考原文对比阅读:
 揪心疑惑
揪心疑惑

在撰写单元测试的过程中,你是否曾经被以下问题困扰过?
- 为什么要写单元测试?单元测试的目标是什么?
- 单元测试的粒度是怎样的?什么叫单元?a class, a function, or a behavior, or an observable behavior?
- 单测覆盖率真的有用吗?有什么用?又有哪些限制?
- 怎样才能写好单元测试?怎样才能写出性价比最高的单元测试?
- 如何判断一个单元测试的好坏?有没有具体可供参阅的维度?
- 哪些代码需要写单元测试,哪些代码没必要写单元测试?
- 单元测试和集成测试的边界是什么?
- (单元丨集成)测试到底是要测什么东西?
- 单元测试的侧重点是什么?集成测试的侧重点是什么?二者的比例该是怎样的?
- 如何使用 Mock?哪些东西是需要 Mock 的?哪些东西是不应该 Mock 的?需要 Mock 的东西,应该在哪个层次进行 Mock?(你的 repository 层需要 Mock 吗?)
- 为什么你的测试代码很脆弱,总是需要频繁修改,维护起来难度很大?
- 如何减少测试结果的假阳性和假阴性?
四根柱子
对于第 5 个问题,作者提出了 4 个维度:
- Protection against
regressions:防止回归,通过自动化验证代码修改后原有功能不受破坏。
- The amount of code that is executed during the test.
- The complexity of that code.
- The code’s domain significance.
- Resistance to
refactoring:抗重构性,重构业务代码时,测试代码无需过多变动便可通过用例,证明重构无误。
- Tests provide an early warning when you break existing functionality.
- You become confident that your code changes won’t lead to regressions.
- Fast feedback:快速反馈。
- Maintainability:可维护性。
- How hard it is to understand the test.
- How hard it is to run the test.
对于这 4 个问题,你是否又有以下疑问:
- 哪个维度是最重要的?
- 怎样才能写出满足各个维度的测试代码?
- 如果维度之间存在矛盾,如何 trade off?
为什么要写单元测试?
三个最重要的原因:
验证你的程序逻辑正确性。
带来更好的代码设计。
因为单元测试能够让你站在使用者的角度去使用暴露的接口,如果接口不好用,逻辑不好测,测试条件不好构建,大概率说明代码的设计本身是有缺陷的,包括但不限于:抽象不合理、逻辑划分不清晰、与其他模块耦合严重等。
使软件项目更可持续发展。
如果你的需求没有发生变化,那原本能运行通过的单测应该一直都能运行,这有助于避免在团队协作中不小心改坏你不知道的代码,也有助于你执行各种重构措施。
这三个原因的重要性是显而易见的,但笔者个人觉得还有一个更深层次的最重要的原因:
- 你要对你做的事情负责,好的代码一定要先过自己这关。
单元测试的粒度是什么?
这是一个很有争议的话题,单元测试的「单元」到底是什么?
- 一个类?
- 一个函数?
- 还是多个类组成的一个模块?
- 还是多个函数组成的一个大逻辑?
在《Unit Testing》书中,作者指出:「单元」指的是 an observable behavior,即一个外部系统可观测到的行为。
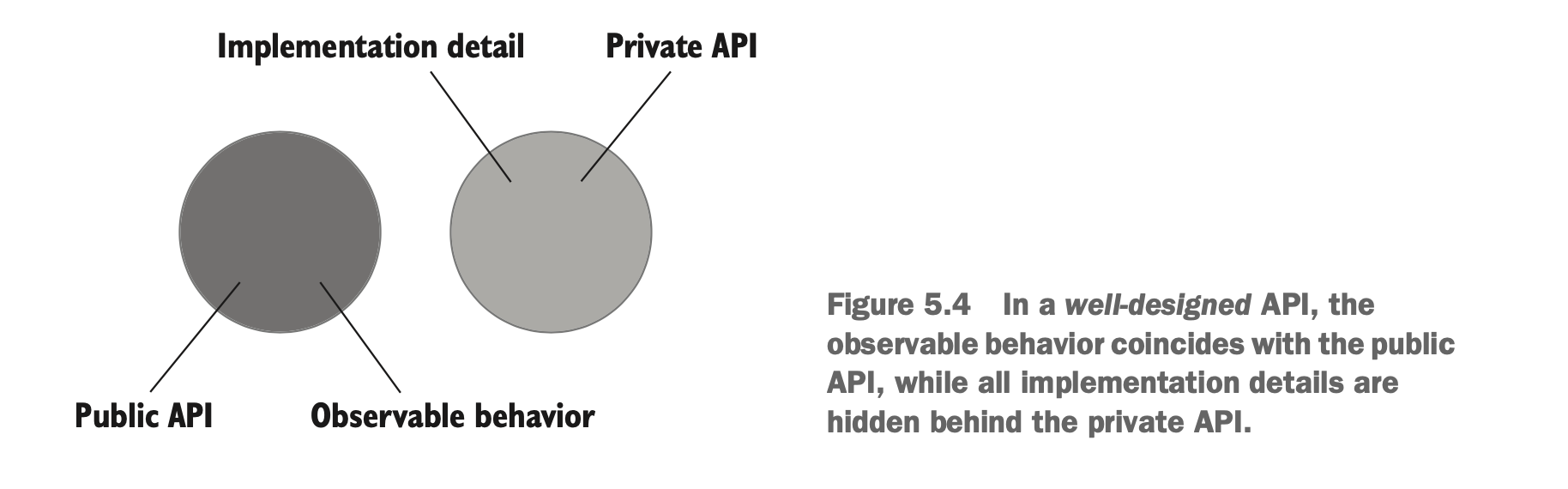
为什么是可观测行为:
- 一个帮助客户端实现目标的操作(operation)。
- 一个帮助客户端实现目标的状态(state)。
换言之,也就是我在撰写单元测试的时候,我就是在使用系统提供的能力,我就是个使用者, 我只要验证你能提供我要的功能,就 OK 了,你背后怎么做,为了这个功能所拆分的类也好,小的辅助函数也好,都不重要,都不属于我要验证的范畴。
所以这更像是黑盒测试(black-box test)。
当然,会有例外,如果你底层有一个特别特别复杂的逻辑,你有必要专门花精力去验证它的逻辑正确性,那是可以针对它撰写专门的白盒测试(white-box test)的。针对这个情况,作者其实也提出了一个观点,对于这个复杂的逻辑,也可以抽成一个单独的模块,由它来提供能力给你当前模块使用。
总结:
- 优先选择黑盒测试。
- 对于涉及复杂算法的逻辑,单独撰写白盒测试。
- 结合覆盖率工具去看哪些代码没被覆盖,然后再站在使用者的角度去思考为什么没被覆盖,是这个分支压根没必要存在,还是还有未考虑到的使用场景。
如何组织单元测试?
两种结构:
- AAA: Arrange-Act-Assert
- GWT: Given-When-Then
其实都是一个思路:准备前置条件→执行待验证代码→验证逻辑正确性。
几个建议:
- 尽量避免一个单元测试中包含多个 AAA/GWT。
- 避免在单元测试中使用
if等分支语句。 - 命名的时候,尽可能让非程序员也能看懂,即这个命名需要描述一个领域问题。
如何发挥单测的最大价值?
- 单元测试用例必须持续不断反复执行验证。
- 用最小的维护代价提供最大价值的单元测试。
- 识别一个有价值的测试
- 撰写一个有价值的测试
- 验证代码中最重要的部分(领域模型)。
1. 单元测试用例必须持续不断反复执行验证
这里推荐笔者的个人实践:
- 在
pre-commit执行增量单元测试,确保本次修改的代码涉及的单测可正确通过。 - 在
gitlab-ci/github-action流程中执行全量单元测试,全面覆盖,避免本次修改的代码影响到其他模块的正常功能。同时如果是合并到主分支的请求,加入增量覆盖率阈值检测,不满足阈值的,发送飞书消息卡片进行告警通知。
pre-commit 增量单测
.pre-commit-config.yaml 配置如下:
1 | repos: |
run_diff_go_test.sh 脚本如下:
1 | !/bin/bash |
gitlab-ci 全量单测
gitlab-ci.yml 配置如下:
1 | go-unit-test: |
unittest.sh 单测执行脚本如下:
1 | !/bin/bash |
其中 cal_diff_coverage.sh 用于计算增量覆盖率:
1 | !/bin/bash |
2. 用最小的维护代价提供最大价值的单元测试
如何评价一个单元测试价值是否足够大呢?或者,更简单的说法是,如何评价一个单元测试写得好不好?
可以从 4 个角度进行评估:
- protection against regressions
- resistance to refactoring
- fast feedback
- maintainability
更具体地说:
2.1 防止回归
代码修改后,原有功能不受影响。
评价指标:
- 被测试代码执行到的业务代码数量(测试覆盖率)。
- 业务代码的复杂度。
- 业务代码的领域重要性。
2.2 抵抗重构
非功能性重构,测试仍能通过,确保功能一致性。
评价指标:
- 越少的“假阳性”越好。
- 在重构代码时,引入了破坏性变更,测试代码能否快速反馈,即越少的“假阴性”越好。
- 测试代码是否为你重构代码提供了足够的信心。
- 测试代码测试的是业务代码的 observable behavior,而不是其背后的每一个步骤。
2.3 快速反馈
测试代码执行时间越快,则反馈间隔越短,缺陷修复效率和质量就越高。
评价指标:
- 代码执行速度
2.4 可维护性
测试代码的修改成本,可维护的测试代码更有利于适应需求变更。
评价指标:
- 测试代码有多难理解?
- 测试代码的代码行数有多少?
- 测试代码的执行难度有多高?即有多少的外部依赖?
2.5 如何权衡
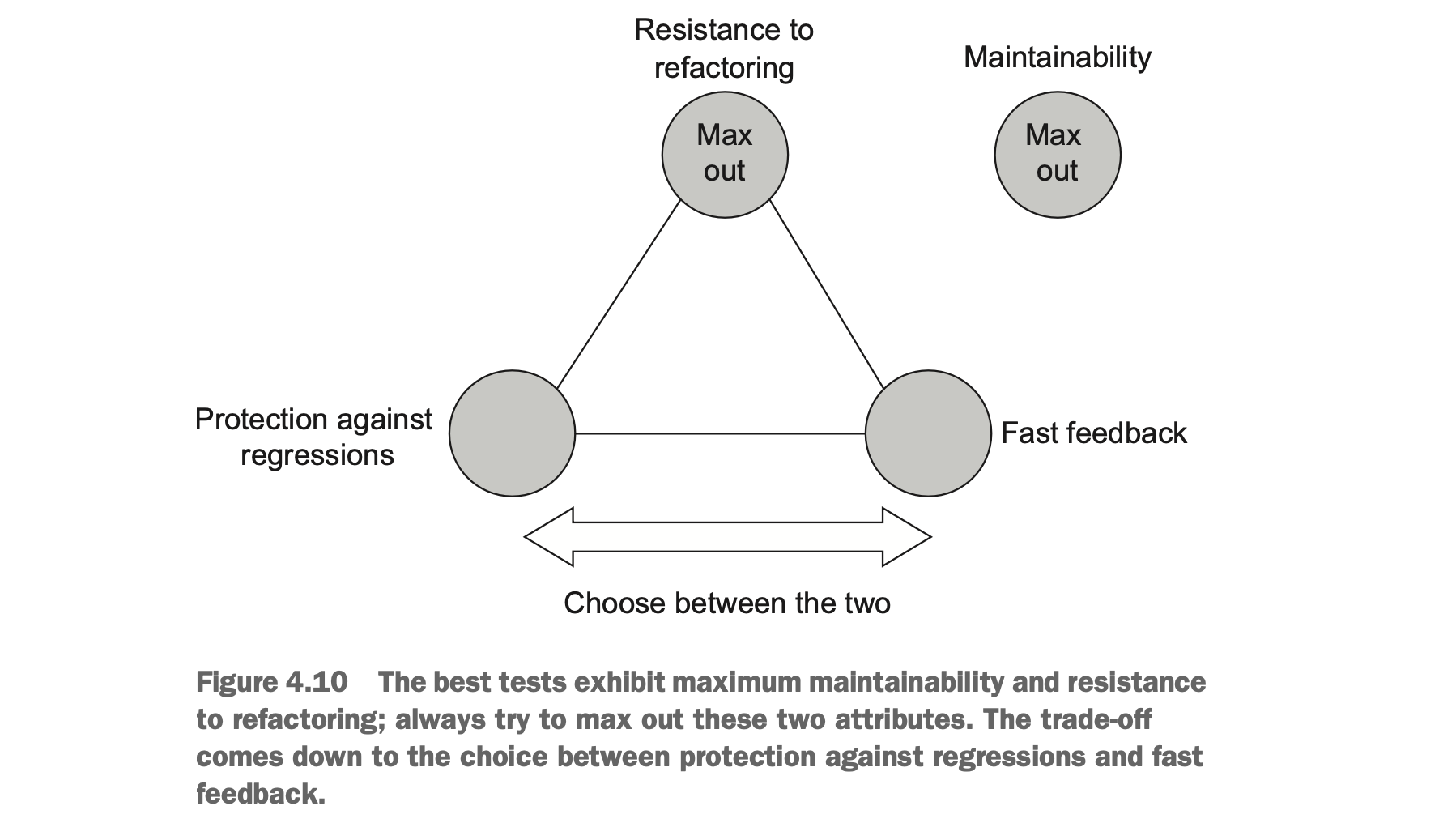
单元测试的价值可以通过上述 4 个指标的乘积来进行估算,但现实是,这 4 者,往往无法兼得。那我们如何做权衡呢?
首先回顾「为什么要写单元测试」,核心目的是为了程序逻辑正确性、使软件项目更可持续发展。所以:
- 可维护性(maintainability)是不可商量的,必须要撰写可维护的测试代码。
- 抵抗重构(resistance to refactoring)是不可商量的,我们的测试代码应尽可能对错误的逻辑进行告警,也应避免对正确的逻辑进行误告警。
所以我们能权衡的其实就是 protection againts regressions 和 fast feedback,二者的矛盾很清晰:
- 如果执行的代码越多,相应的效率就越低。
- 如果执行的代码太少,那验证的逻辑范围就越小。
为了权衡这二者,业界提出了“测试金字塔”的概念。
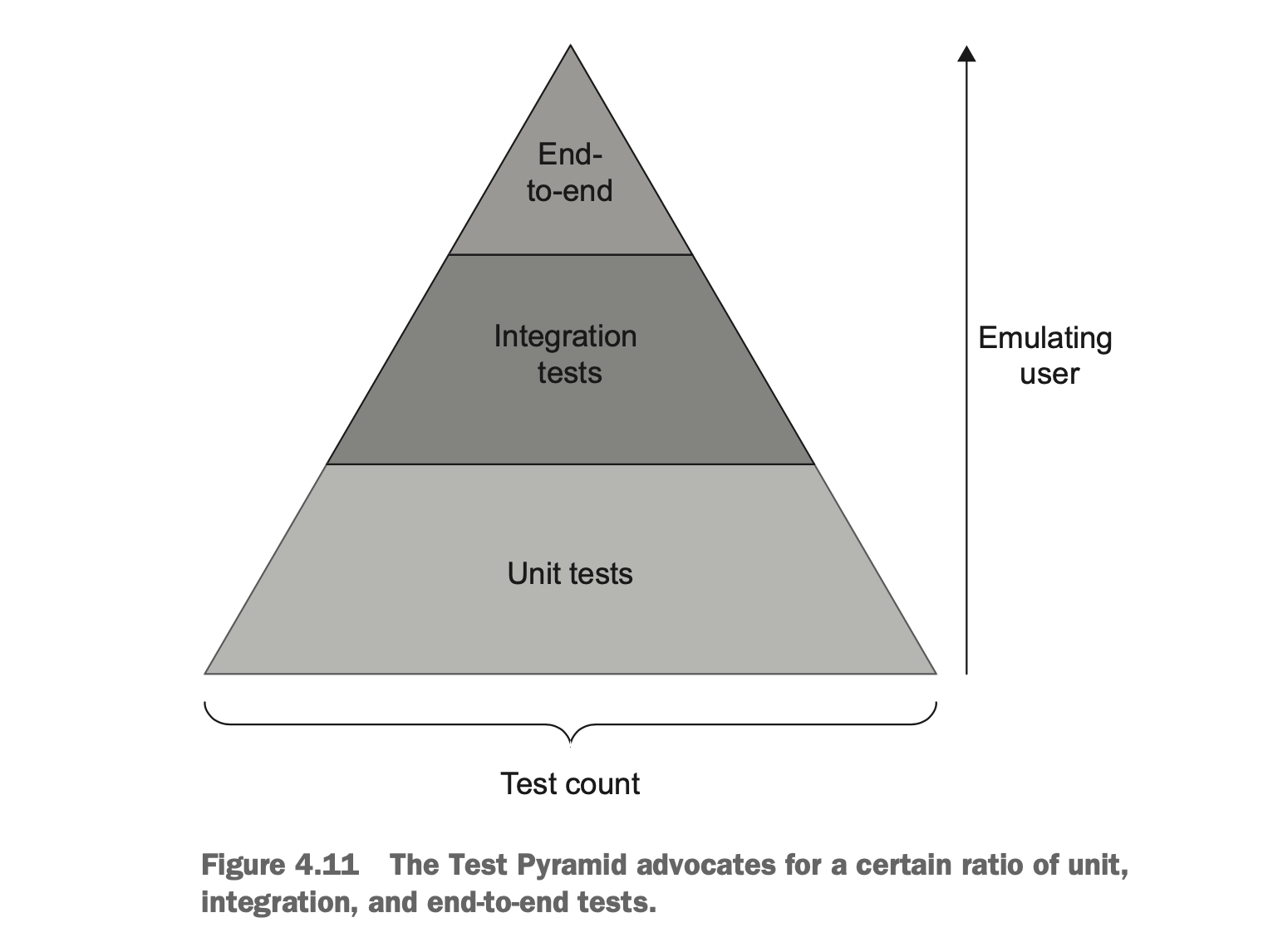
- 单元测试的单位更小,涉及的外部依赖也更少,更加 fast feedback,所以在这个层次我们要撰写更多的测试,去尽可能覆盖更多的单元逻辑。
- 集成测试、端到端测试的逻辑覆盖范围更大,更加 resistance to refactoring,但是往往会依赖更多的组件,执行的效率也更低,所以在这 2 个层次,我们可以只撰写覆盖最重要(乐观)的业务路径的测试代码,在牺牲有限的执行效率的情况下,尝试更大的防止回归效果。
3. 验证代码中最重要的部分
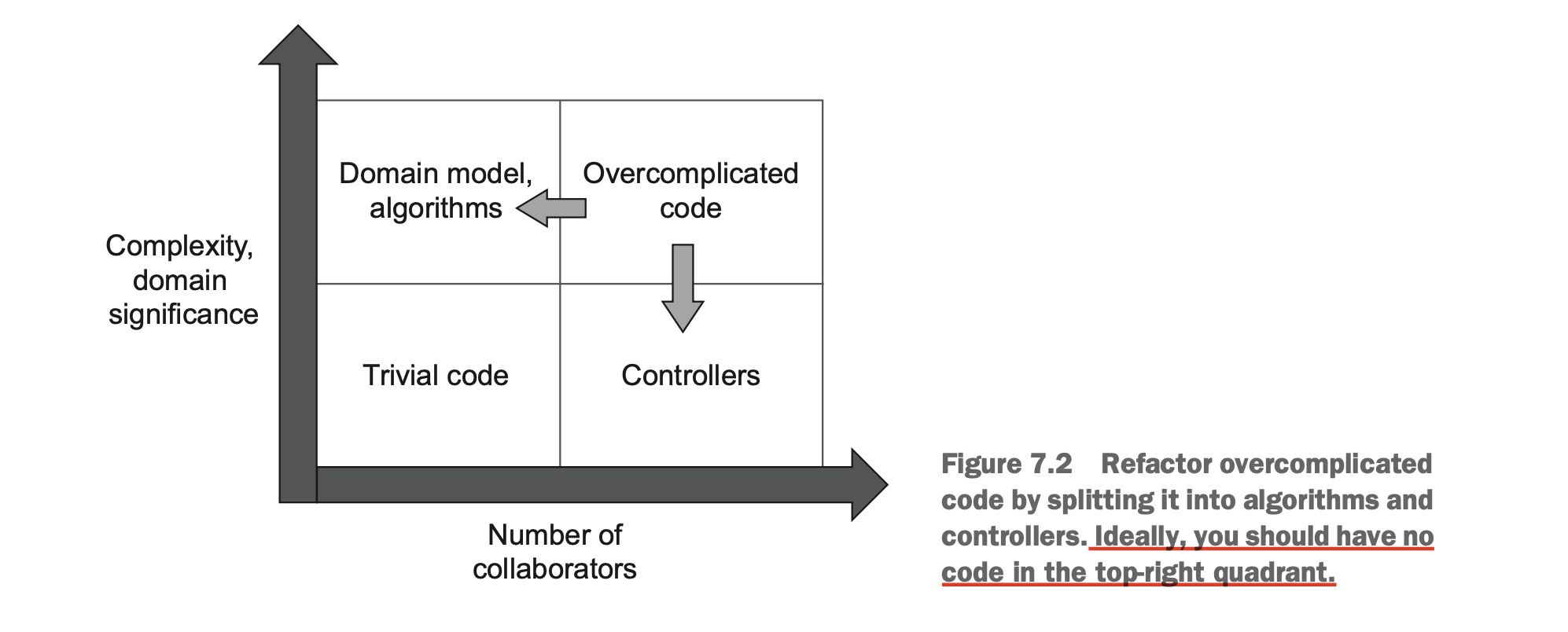
什么是代码中最重要的部分呢?我们可以将代码分成以下 4 个种类:
- 领域模型和算法(Domain Model and Algorithms):领域模型是对业务领域核心概念和逻辑的抽象,算法则是解决特定问题的计算步骤。两者共同构成系统的核心业务逻辑。
- 琐碎代码(Trivial Code):实现简单功能、无复杂逻辑的代码片段,通常为工具方法或数据转换层。
- 控制器(Controllers):协调业务逻辑与外部交互的中间层,常见于 MVC 或分层架构中。
- 过度复杂代码(Overcomplicated Code):既包含核心业务逻辑,又包含控制器逻辑。
作者建议:
- 永远为 Domain Model and Algorithms 撰写全面细致的单元测试。
- 永远不为 Trivial Code 撰写单元测试。
- 为 Controllers 撰写集成测试,而不是单元测试。
- 避免写 Overcomplicated Code,将其拆分成 Domain Model and Algorithms 和 Controllers 。
如何让代码更容易测试?
根据不同处理架构的业务代码,可以将测试代码分成以下 3 个种类:
output-based:业务代码只产生输出结果,所以只需要验证输出。state-based:业务代码会修改内部状态或依赖状态,所以需要验证状态变化。communication-based:业务代码会跟协作方进行交互,所以需要验证交互情况。对于这种场景,我们会使用mock工具来进行验证。关于mock这个话题,文章后续会进行详细讨论。
我们按照上述 4 个分析维度,对这 3 种测试代码进行比较:
| protection againts regressions | resistance to refactoring | fast feedback | maintainability | |
|---|---|---|---|---|
| output-based | ⭐️⭐️⭐️ | ⭐️⭐️⭐️ | ⭐️⭐️⭐️ | ⭐️⭐️⭐️ 最好,不需要外部依赖。 |
| state-based | ⭐️⭐️⭐️ | ⭐️⭐️ | ⭐️⭐️⭐️ | ⭐️⭐️ 比较差,需要外部依赖。 |
| communication-based | ⭐️⭐️ 过度使用会导致需要到处 mock,而真正执行的业务代码数量很少。 | ⭐️ 最差,因为验证交互情况,往往会陷入实现细节,很容易在重构过程中出现误警告。 | ⭐️⭐️ 大差不差,但是 mock 工具效率可能会相对低一点点。 | ⭐️ 最差,需要引入大量的 mock 工具和 mock 代码。 |
所以我们应该尽可能写 output-based 测试,减少 communication-based 测试。
可以采取 functional architecture,将代码分成 2
个阶段:
- 根据业务规则做出决定
- 根据决定做出行为

为此,在可能的场景下,我们可以尝试通过 2 个步骤来优化我们的测试代码:
- 使用
mock来替代外部依赖out-of-process dependency。 - 使用
functional architecture来替代mock。
聊一下 Mock
在撰写单元测试的过程中,如果业务逻辑依赖的组件不好实例化的时候,我们常常会借助各种
Mock
工具来实现“模拟”功能,使单测更易撰写,这里有一个更准确的词叫
test doubles(测试替身)。
test double 的种类
从大的方面可以分为 2 种:
- 用于模拟和验证对象间的输出交互(如方法调用次数、参数匹配),则为
mock。 - 用于模拟输入交互,提供预定义的数据,则为
stub。
更进一步可以分为:
mockmock: 由 mock 工具生成。spy: 手工撰写。
stubstub: 可以通过配置在不同的场景下返回不同的数据。dummy: 占位符,仅用于填充参数,不参与实际逻辑。fake: 跟stub几乎一样,唯一的区别是fake经常用于替代尚未开发或复杂的依赖。
需要注意的是:永远不要去验证(assert)跟
stub的交互,没必要!
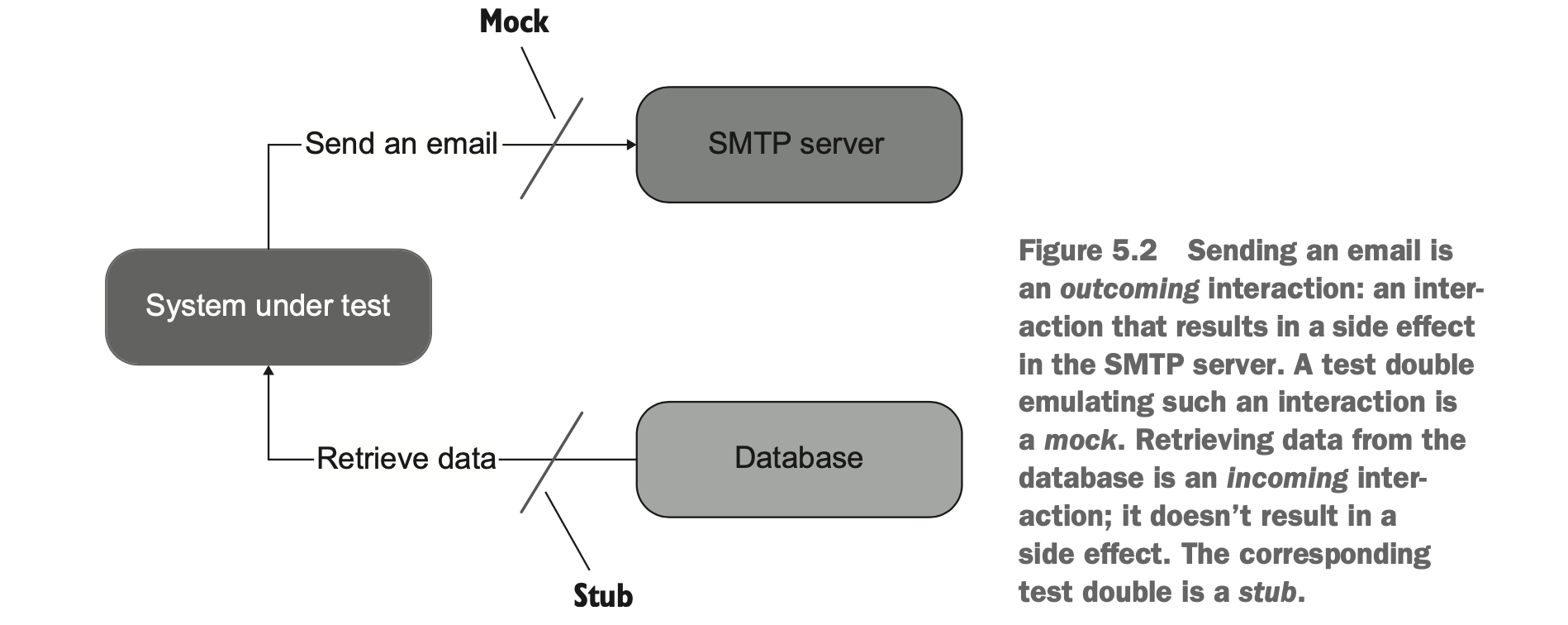
哪些东西需要 Mock?
在回答这个问题之前,我们先做下铺垫,聊一下接口的误解、依赖的种类和两种交互的概念。
接口的误解
在谈如何更好地利用 mock 之前,我们先来聊一下接口(interface)的误解。
在业务开发当中,我们经常能看到一些企图进行“优雅”架构设计的代码,上来每一层都定义接口,每一层都使用接口进行交互,反正遇到问题先定义接口再说。
目的有二:
- 抽象外部依赖,进行解耦。
- 可以在不修改既有代码的情况下扩展功能,即所谓的开闭原则(Open-Closed principle)。
但这其实存在一些误区,作者在书中指出:
- 只有一个实现的接口,并不是抽象,也并没有比具体的对象起到太多所谓的解耦作用。
- 上述第 2 点违反了一个更重要的原则 YAGNI(You are not gonna need it),也就是你所谓的功能扩展大概率是不需要的。
- 上述做法的唯一好处是什么:使测试成为可能!因为你不隔离掉外部依赖的话,你的单元测试撰写会非常困难,也无法做到 fast feedback。
抽象是发现出来的,而不是发明出来的!
依赖的种类
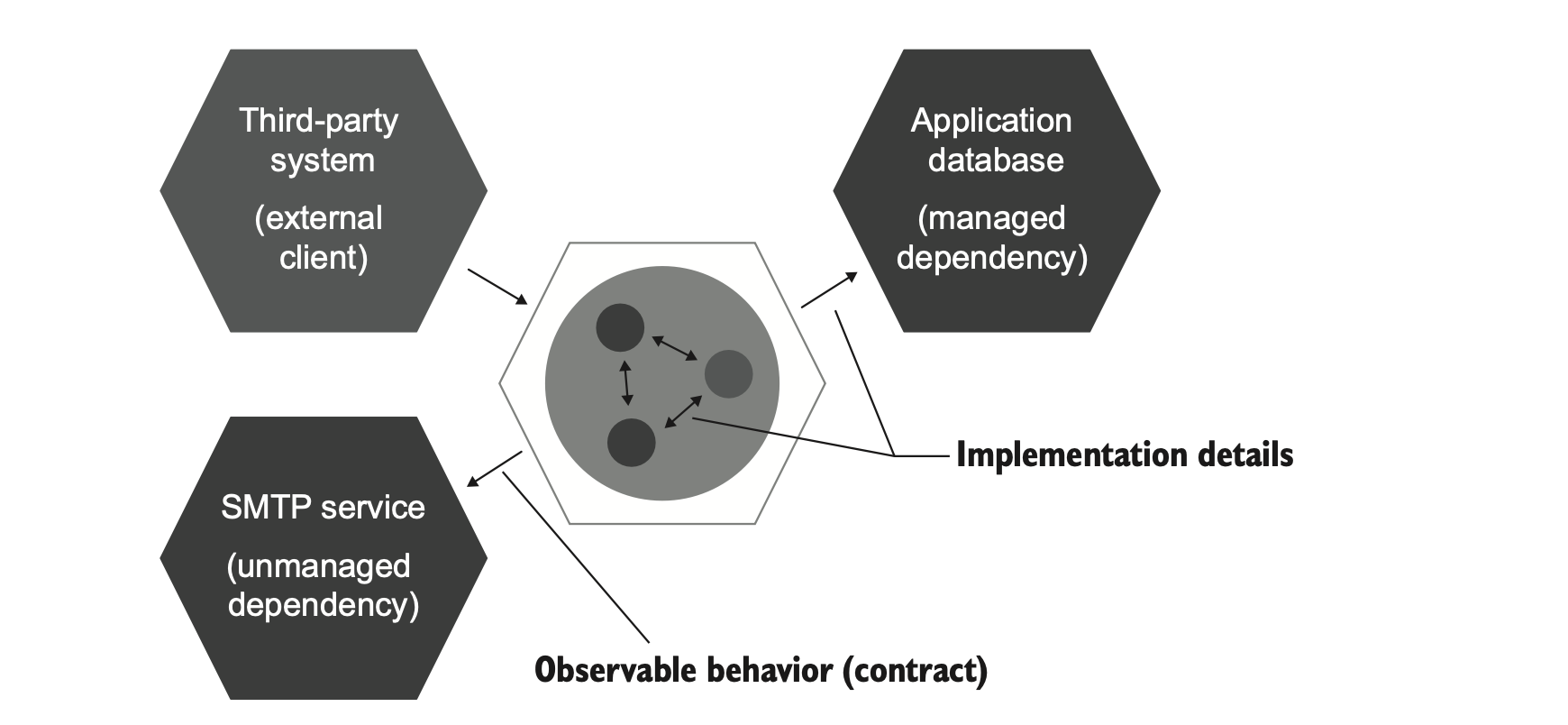
shared dependency: 一个在测试代码中的共享对象。out-of-process dependency: 独立于当前应用程序的另外一个进程对象,如数据库、STMP 服务器等。managed dependency: 仅当前应用程序可访问的依赖(对其他程序、服务是不可见的)。unmanaged dependency: 除了当前应用,其他应用也可见。
private dependency: 一个私有对象。
两种交互
intra-system communication: 应用程序内部的交互。inter-system communication: 应用程序之间的交互。
哪些东西需要 Mock?
铺垫完接口的误解、依赖的种类和两种交互的概念之后,我们来聊一下哪些东西需要 Mock?
在抉择的时候,需要牢记我们测试粒度和评价指标。
测试粒度:an observable behavior ⭐️⭐️⭐️⭐️⭐️
评价指标:
- 防止回归:protection against regressions
- 抵抗重构:resistance to refactoring
- 快速反馈:fast feedback
- 可维护性:maintainability
集合测试粒度和评价指标,Mock 哪些东西可以用一句话来概括:
Mock 那些外部可观测到的交互,而尽量避免 Mock 内部的实现细节。
更具体来说:
- 仅对
unmanaged dependency应用mock对象。因为我们无法预知其他应用会对这些依赖进行什么操作,所以只能隔离开。 - 对系统最外围的边界进行
mock。只有系统边界,才是可观测行为,内部都是实现细节,对实现细节过多 Mock,意味着破坏了 resistance to refactoring。 - 尽量只在集成测试中使用 mock,避免在单元测试中使用 mock。
- 只 mock 属于你的对象,不去 mock 依赖库中的对象。
- 始终在第三方库之上编写自己的适配器,并对这些适配器进行 mock,而不是 mock底层类型。
- 仅从库中暴露你所需要的功能。
- 使用项目的领域语言(domain language)来完成上述操作。
举个例子:
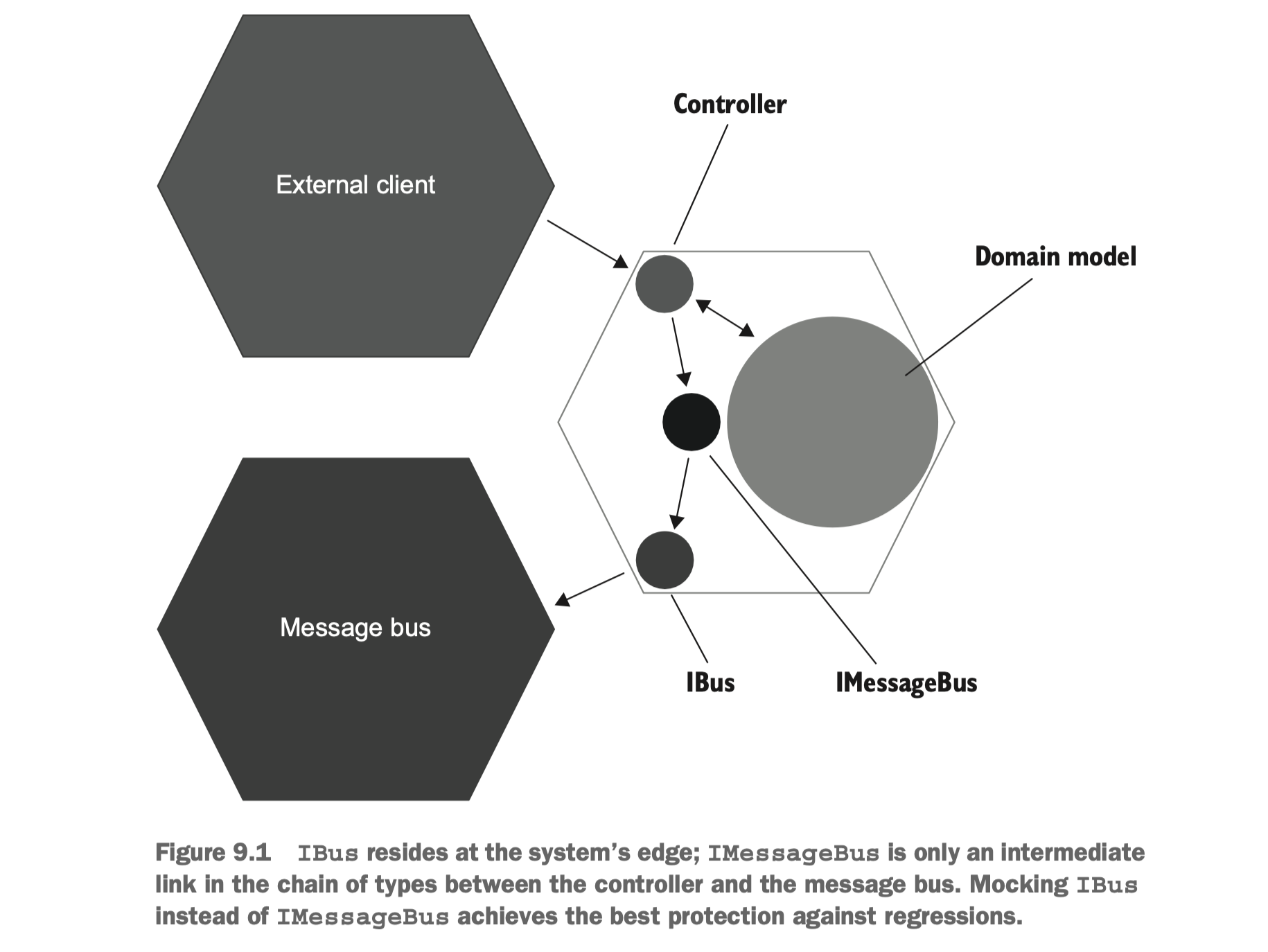
在上图中,右侧是我们的应用程序,它依赖了左下角的
Message bus 这个外部依赖,准确说是
unmanaged dependency。对此,我们为其创建了适配器接口
IBus,在这个通用接口之上,我们又根据具体业务创建了
IMessageBus。
针对这种情况,我们在进行 mock 的时候,只需要 mock IBus
对象,而不是去 mock Message bus 和
IMessageBus。
数据库要不要 Mock?
这个话题比较有意思,作者的建议是:
- 如果这个数据库只有你这个应用可以访问,那就不要 mock。
- 如果这个数据库存在可以被其他应用访问的部分,那就只 mock 这一部分,不去 mock 独属于你应用的那部分。
要践行上述标准,需要做到以下前提:
- 将数据库的信息也放在源码控制系统中(git),包括:
- schema
- reference data(项目启动必须要的初始数据)
- migration(数据变更记录)
- 每个开发者有一个单独的数据库(测试环境下)
- 但数据库变更的时候,不要直接修改,而是要写一条对应 sql 去进行修改,同时将这条 sql 也纳入源码控制系统中。
作者不建议 mock 数据库,包括使用内存数据库替代,如
sqlite 替代
MySQL,核心原因是:你无法保证这些数据库能跟线上环境的行为一致,可能会导致一些无效测试用例,即假阴性。
笔者并不完全采纳这个建议,诚然,如果能做到以上前提,是可以考虑践行的。然而,它的要求很高,收益却相对较小,在单元测试环境下,使用内存数据库进行 mock,在保证了 fast feedback 和 maintainability 的情况下,也能够避免绝大多数的逻辑漏洞了,假阴性的情况会非常少,即便有,也可以交给集成测试和端到端测试去解决。
反面案例
- 测试私有方法。
- 暴露私有状态。
- 泄露领域知识到测试中。
- 在业务代码中撰写只用于测试的代码。
- mock 具体的类。
第 3 点比较有意思,比如下面这个例子:
1 | public class CalculatorTests |
什么叫做泄露领域知识呢?
比如你要验证一个加法 Add
对不对,但是在测试代码中,你的期望值也是用加法来获得的,这个“加法”就是领域知识,因为这样测的话,就很有可能会出现“负负得正”的情况。
正确的做法是直接断言你预期的最终结果,以确保逻辑符合预期。
Go 实践案例
本章将分享一些笔者在 Go 项目实战过程中的一些实践案例,希望对读者撰写单元测试能提供一些帮助。
依赖 Redis 的逻辑怎么测
可以使用 miniredis,这是一个使用 Go 语言实现的内存版
Redis。
可以封装一个函数,用于快速启动 miniredis 并返回客户端对象:
1 | func NewMiniRedis() *redis.Client { |
这里可能会出现作者提到的不要使用内存数据库替代真实的数据库,因为你无法保证它们的行为一致。
比如这里是单机的,而生产环境可能是集群的,在 Redis Cluster 中,涉及到 lua 脚本和事务的所有 key,都必须保证在同一个 slot 上,在这种情况下,使用
miniredis是测不出问题的。
依赖 MySQL 的逻辑怎么测
核心挑战:
- 依赖真实 MySQL 则容易因为网络原因而导致测试失败(不可重复性)
- 依赖真实 MySQL 会严重影响单侧执行效率
- 数据预备
- 数据清洗
- 单测之间的数据隔离,互不影响
- 并发安全
为了解决上述问题,提供更优雅的 MySQL 单测解决方案,笔者借助
dolthub/go-mysql-server 和 gorm
的能力,实现了一个 go-mysql-mocker,简称
gmm。
其中:
dolthub/go-mysql-server提供了内存 MySQL 引擎。gorm提供了快速建表和插入数据的能力。
核心功能:
- 内存版数据库,无网络依赖;
- 每个单测可单独启动一个数据库,天然做到数据隔离和清洗;
- 支持 struct、slice、sql stmt、sql file 多种方式进行数据初始化,支持需要前置数据的业务逻辑测试。
随机概率逻辑怎么测
场景:随机抽奖
难点:随机概率的结果是不确定的,直接通过 assert.Equal
是无法写出可稳定重复运行的单测的。
1 | // AssertMapRatioEqual 检查实际计数的比例是否符合预期权重的比例 |
案例:
1 | func TestLottery_randOnce(t *testing.T) { |
HTTP 接口怎么测
挑战:
- 如何快速构建请求体并发送请求?
- 如何快速断言异常情况?
- 如何快速断言成功情况,并解析出期望的返回值?
1. 构造请求
1 | // 快速创建请求体 form 表单格式 |
2. 发送请求
1 | w := httptest.NewRecorder() |
3. 断言异常
1 | // AssertRspErr 断言 http 响应异常,expectedErr 为期望的错误信息 |
4. 断言正确且返回响应值
1 | // FromHTTPResp 从 http 响应中解析出数据 |
这里其实就违反了上一张反面案例中的第 3 点”泄露领域知识到测试中“,因为这里接受响应的时候,还是使用的领域对象结构,所以可能会出现负负得正的情况,比如你的对象字段名就是拼写错误了,但是因为你业务逻辑和断言处都是用的一个结构,所以内部形成了循环,就负负得正了,但是真正到了客户端那,就解析失败了。
不过在这个情况下,笔者认为这个情况下的这种风险是可以接受的,远盖不住其带来的效率提升。
5. 组合起来
1 | func SendHTTPRequest[Rsp any](t *testing.T, server HTTPServer, path string, data any, errMsg ...string) *Rsp { |
6. 案例
1 | func Test_GetCollectReward(t *testing.T) { |
依赖时间的逻辑怎么测
- 尽量不要依赖时间。
- 考虑将时间作为参数,避免
time.Now()。
也可以参考:
并发逻辑怎么测
go test推荐开启-race用于检测并发冲突。
更多可参考:



