
本篇笔者将尝试基于 Gin v1.10.1 来进行一趟 Gin 源码之旅,为了使我们的学习更有方向,在开始之前,我们来思考一个问题:
一个 HTTP 请求从抵达 Gin 到返回响应,其完整的旅程是怎样的?
- 启动服务:
r.Run()究竟做了什么?(提示:它内部调用了 Go 标准库的http.ListenAndServe) - 请求入口: 当一个请求到来,Go 的
http.Server是如何将请求交给 Gin 的核心Engine处理的?(提示:Engine本身就是一个http.Handler) - 上下文创建:
gin.Context是在何时被创建的?它封装了什么? - 路由匹配: Gin 如何根据请求的 URL 快速找到对应的处理函数?
- 中间件执行:
r.Use()添加的中间件是如何形成一个“调用链”的?c.Next()的作用机制是什么? - 业务处理: 你的业务逻辑处理函数(Handler)是如何被调用的?
- 响应返回:
c.JSON()或c.String()这样的函数,最终是如何将数据写入到http.ResponseWriter的? - 资源回收:
gin.Context对象在请求结束后是如何被回收的?(提示:sync.Pool) - 优雅关闭: 服务在关闭过程中,如何保证当前请求被正确完整处理?
从本篇中你可以学到什么
阅读本文,你将不仅仅是学会如何使用 Gin 框架,更是能深入到底层,理解其高效运作背后的原理。这趟旅程将为你揭示一个完整的 HTTP 请求在 Gin 中的生命周期,让你在未来的开发与面试中都更具深度和信心。
具体来说,你将收获以下核心知识点:
- Go Web 服务核心原理
- 理解 Gin 的
r.Run()如何封装并启动标准库的http.Server。 - 掌握 Go
net/http服务如何通过net.Listener的Accept()循环来接收 TCP 连接,并为每个连接开启独立 Goroutine 进行处理的并发模型。
- 理解 Gin 的
- Gin 的高性能设计哲学
- 剖析 Gin 如何通过
sync.Pool对象池技术来复用gin.Context,从而大幅减少内存分配和 GC 压力,这是 Gin 高性能的关键之一。 - 学习 Go
http.Server中优雅关闭(Shutdown)的完整实现,包括:- 如何通过
Context控制超时。 - 如何区分并分别处理监听器(Listener) 和连接(Connection)。
- 高效轮询等待中的指数退避(Exponential Backoff) 与抖动(Jitter) 策略。
- 如何通过
- 剖析 Gin 如何通过
- 精巧的 Radix Tree 路由实现
- 深入理解 Gin 高性能路由的基数树(Radix
Tree)实现原理,包括
methodTrees的整体结构。 - 彻底搞懂路由
node节点的每个字段的精确含义,特别是indices(快速索引)和wildChild(通配符标志)这两个性能优化的法宝。 - 掌握路由的查找(
getValue)过程:包括前缀匹配、静态路由匹配、以及如何通过skippedNodes实现回溯(Backtracking) 机制来保证静态路由的优先级。 - 掌握路由的注册(
addRoute)过程:包括最核心的节点分裂(Split Edge) 逻辑,以及如何通过panic来避免通配符冲突,从而在构建时就保证路由树的逻辑正确性。
- 深入理解 Gin 高性能路由的基数树(Radix
Tree)实现原理,包括
- 中间件的洋葱模型
- 揭秘 Gin 中间件的核心
c.Next()的工作机制,理解HandlersChain和index索引是如何协同工作,实现了优雅的“洋葱模型”调用链。
- 揭秘 Gin 中间件的核心
- 框架的扩展性与接口设计
- 了解 Gin 如何通过
RouterGroup组合的方式,巧妙地为Engine和RouterGroup自身都实现IRouter接口,从而支持灵活的路由分组与嵌套。 - 学习
c.JSON()背后的render.Render接口设计,理解其如何将不同格式(JSON、XML、HTML 等)的响应渲染逻辑解耦。
- 了解 Gin 如何通过
启动服务 r.Run()
1 | func (engine *Engine) Run(addr ...string) (err error) { |
地址解析
其中 resolveAddress 就是解析监听地址,默认为 :8080:
1 | func resolveAddress(addr []string) string { |
启动监听
r.Run() 底层使用的其实还是标准库 http 的
ListenAndServe():
1 | func (s *Server) ListenAndServe() error { |
核心看 s.Serve(ln):
1 | // Serve 方法会针对监听器 l 接收到来的连接建立新的服务协程。 |
- 服务基础 context 的初始化和相关状态处理,作为后面在每个连接上的请求响应的 gin.Context 的基础。
- for 循环监听客户端连接。
- 为每个客户端建立 conn 连接对象。
c.serve(connCtx)服务每一个连接。
请求入口 c.serve(connCtx)
连接握手
重点来看 c.serve(connCtx):
1 | func (c *conn) serve(ctx context.Context) { |
- 如果配置了 TLS,则进行 TLS 加密握手;
- 创建超时控制 context,对于超时连接强制关闭;
- for 循环
c.readRequest(ctx)读取请求数据; - 执行
ServeHTTP(w, req)执行具体的 HTTP 处理业务; - 结束请求,
w.finishRequest()响应数据; - 非长连接则直接返回,释放连接,否则复用当前连接处理后续请求。
读取请求
其中 c.readRequest() 核心逻辑是:
1 | func (c *conn) readRequest(ctx context.Context) (w *response, err error) { |
写回响应
其中 c.finishRequest() 核心逻辑是:
1 | func (w *response) finishRequest() { |
上下文创建 & 回收 sync.Pool
现在我们进入 ServeHTTP(w, req) 执行具体的 HTTP
处理业务,这里会先为每一个请求创建上下文,然后再进行请求处理。
1 | func (sh serverHandler) ServeHTTP(rw ResponseWriter, req *Request) { |
可以看到这里使用了 sync.Pool 对象池来管理
gin.Context
对象,通过复用对象来避免重复创建和销毁带来的额外开销。
路由匹配 sh.ServeHTTP
核心处理逻辑是 engine.handleHTTPRequest(c):
1 | func (engine *Engine) handleHTTPRequest(c *Context) { |
路由树结构 methodTrees
这里我们重点来看一下 Gin 的路由树是怎样的,先看一下数据结构:
1 | // Gin Engine |
如下图所示:
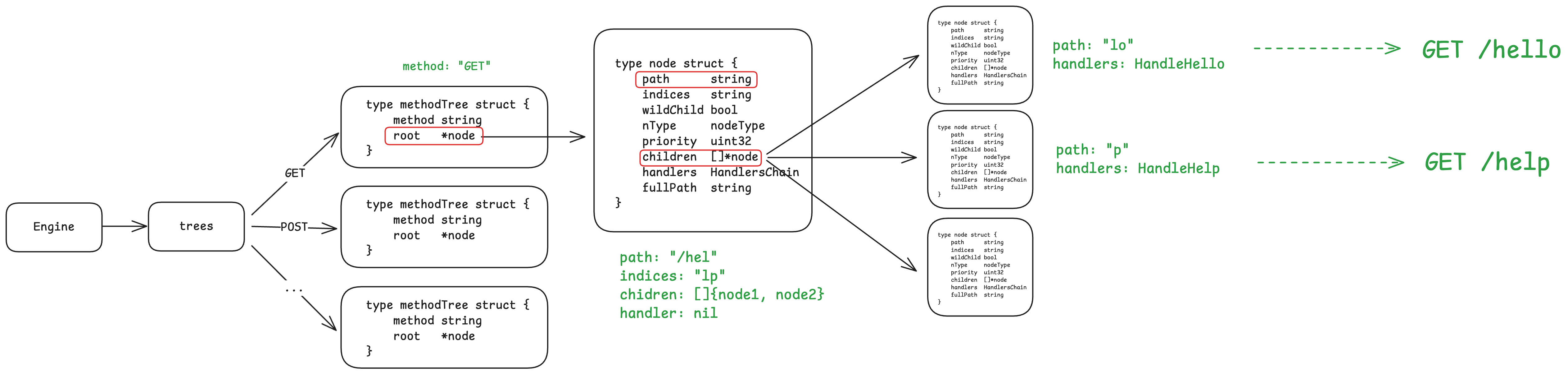
路由树节点 node
这里我们重点解释下 node
结果中的字段含义,这对后续的路由查找分析非常重要:
1 | type node struct { |
1. path string
- 含义:这个字段存储了当前节点所代表的 URL
路径片段 或 公共前缀。它不是完整的 URL
路径,而是树中一个分支的字符串。基数树会尽可能地将多个路由的公共前缀合并到一个
path中以节省空间。 - 举例:假设你注册了两个路由:/user/profile 和 /user/settings。那么可能会有一个父节点的 path 是 /user/,然后它有两个子节点,一个 path 是 profile,另一个是 settings。
2. indices string
含义:这是一个非常巧妙的性能优化字段。它是一个字符串,其中每个字符都是对应
children切片中子节点的path的 第一个字符。它的作用是作为children的一个快速查找索引。当需要寻找下一个节点时,程序只需用请求路径的下一个字符来和indices进行匹配,就能立刻知道应该访问children中的哪个元素,而无需遍历整个children切片。举例:一个父节点 n 的 path 是 /。它有三个子节点,path 分别是 articles、blog 和 contact。
n.children[0].path= "articles"n.children[1].path= "blog"n.children[2].path= "contact"那么,n.indices 的值就会是 "abc"。
当一个请求 /blog/test 到来时,程序匹配完父节点的 / 后,看到下一个字符是 b,它直接在 indices ("abc") 中找到 b 是第二个字符,于是就直接去访问 children[1],非常高效。
3. wildChild bool
- 含义:一个布尔标志位。如果为
true,表示这个节点的子节点中 存在一个通配符节点(即:param或*catchall类型的节点)。 - 作用:这同样是一个性能优化。在路由查找时,如果静态子节点(通过
indices)没有匹配上,程序只需检查wildChild这一个布尔值,就能快速知道是否需要进一步尝试匹配通配符子节点,避免了额外的条件判断。根据约定,通配符子节点永远是children数组的最后一个元素。
4. nType nodeType
- 含义:表示当前节点的类型。
nodeType是一个整数类型,通常有以下几种值:static(静态):节点的path是一个固定的字符串,例如/about。root(根):整棵树的根节点。param(参数):表示一个命名参数,例如:id。路径/users/:id中的:id部分就是一个param类型的节点。catchAll(通配符):表示一个“全匹配”参数,例如*filepath。路径/static/*filepath中的*filepath就是一个catchAll类型的节点。
- 作用:在路由查找时,
getValue函数通过switch n.nType来决定如何处理当前节点和剩余的请求路径。例如,遇到param类型就要提取参数值,遇到catchAll就要捕获所有剩余路径。
5. priority uint32
- 含义:节点的优先级。这个值在 构建路由树 的时候使用,而不是在请求时查找时使用。
- 作用:它的值是根据注册到这个节点的路由数量以及其子孙节点的路由数量计算出来的。当插入新路由可能导致树结构冲突时,
priority可以帮助算法决定如何拆分和重组节点,以保持树的正确性和高效性。简单来说,它代表了一个节点的"权重"或"繁忙程度"。
6. children []*node
- 含义:一个
*node指针的切片,存储了所有直接的子节点。这是构成树状结构的核心字段。 - 规则:这个切片有一个重要规则:如果存在通配符子节点(
:param或*catchall),它 必须并且只能是切片中的最后一个元素。静态子节点(static)则排在前面,它们的顺序与indices字符串中字符的顺序一一对应。
7. handlers HandlersChain
- 含义:
HandlersChain本质上是一个[]HandlerFunc,也就是一个处理函数的切片。 - 作用:这是路由查找的最终目标。当一个请求的 URL
完整匹配到某个节点时,这个节点的
handlers字段就包含了需要被执行的所有函数,这其中可能包括多个中间件(Middleware)和最终处理业务逻辑的那个主函数(Handler)。如果一个节点的handlers为nil,说明它只是一个中间路径节点,不能直接处理请求。
8. fullPath
含义:存储了用户在代码中定义的 完整的、原始的路由注册字符串。
作用:
- 调试与日志:在中间件或日志系统中,你可以通过
c.FullPath()(它读取的就是这个值)获知当前请求匹配到的是哪条原始路由规则,这对于监控和问题排查非常有用。 - 模板渲染或 URL
生成:在某些场景下,你可能需要根据路由名称或模式来生成
URL,
fullPath提供了这个原始模式。
- 调试与日志:在中间件或日志系统中,你可以通过
举例:
你注册了 router.GET("/users/:id/profile", ...).
这会被拆分成多个 node。假设最终匹配到 profile 那个 node:
- 它的
path可能是"profile"。 - 但它的
fullPath会是"/users/:id/profile"。
- 它的
总结
这 8 个字段协同工作,共同构建了一个既节省内存又查找飞快的路由树。
path,children,nType定义了树的 基本结构和逻辑。indices和wildChild是为了 极致性能 而设计的巧妙索引。handlers和fullPath存储了路由的 最终目标和元数据。priority则在幕后默默地保证了这棵树在动态构建过程中的 稳定性和合理性。
路由定位 root.GetValue
接下来我们来看 root.GetValue()
具体是如何定位路由处理器的,这个方法非常长,我们逐一分解。
好的,我们来一起深入解析一下 Gin 框架中这个核心的路由查找函数
(n *node) getValue。
这是一个非常精妙的函数,它的背后是高性能路由技术的典型实现。为了真正理解它,我们需要遵循“由表及里、由浅入深”的原则,从它的目标、使用的数据结构,再到具体的代码执行逻辑,一步步进行剖析。
第 1 步:前缀匹配
1 | prefix := n.path |
这是基数树最基本的操作。代码首先检查当前请求路径 path
是否以当前节点 n 的路径 n.path 为前缀。
- 如果匹配:说明路径的前半部分对了,然后从
path中“砍掉”已经匹配上的前缀,准备在子节点中继续匹配剩余的path。 - 如果不匹配:说明走错路了,需要回溯或直接返回未找到。
第 2 步:在子节点中选择"道路" (静态路由)
1 | idxc := path[0] |
在砍掉前缀后,path
是剩余的待匹配路径。idxc := path[0]
取出剩余路径的第一个字符。然后,代码遍历 n.indices
这个“索引目录”。
n.indices存储了所有子节点的路径的第一个字符。- 如果
idxc在n.indices中找到了匹配项c,就意味着存在一个正确的子节点可以继续走下去。 n = n.children[i]将当前节点n更新为找到的子节点。continue walk跳回到walk循环的开始,在新节点上重复 第 1 步 的前缀匹配。
这个设计非常高效,因为它避免了对 children
切片的完整遍历,而是通过一个字符的比较就快速定位了下一个节点。
第 3 步:处理"岔路口" - 通配符 (Wildcard)
如果静态路由没找到(for
循环结束),程序会检查是否存在通配符子节点。
1 | if !n.wildChild { |
n.wildChild
是一个布尔值,表示当前节点是否有一个通配符子节点(:param 或
*catchall)。按照约定,通配符子节点永远是
children
数组的最后一个元素。如果存在,就直接跳到这个通配符节点继续匹配。
接着,switch n.nType 根据通配符节点的类型进行处理:
case param(例如/users/:id):- 它会从剩余的
path中"截取"出参数值。截取的规则是到下一个/或者路径末尾。 - 例如,如果
path是123/profile,它会截取出123作为参数值。 - 然后将参数的键(如
id)和值(如123)存入params。 - 如果
/后面还有路径(如profile),则继续在当前参数节点的子节点中进行walk。
- 它会从剩余的
case catchAll(例如/static/*filepath):- 这就更简单了,它会把 所有 剩余的
path都作为参数值。 - 例如,如果
path是css/main.css,整个字符串都会被捕获。 catchAll节点一定是路径的终点,找到后直接返回结果。
- 这就更简单了,它会把 所有 剩余的
第 4 步:到达终点与"没路了"的处理
1 | if path == prefix { |
这里说明已经找到了"终点",进行最后的一系列检查。
第一种情况:到达真终点。
1 | // We should have reached the node containing the handle. |
这是最完美的情况!我们找到了一个与请求路径完全匹配的节点,并且这个节点上确实注册了至少一个处理函数,这里我们设置好 fullPath 属性然后就可以直接返回了。
第二种情况:到达假终点。
1 | // If the current path does not equal '/' and the node does not have a registered handle and the most recently matched node has a child node |
我们到达了节点 n,但这个节点的 handlers 是
nil!并且,为了避免对根路径 /
的误判,加了 path != "/" 的条件。
这意味着我们走到了一个"死胡同"或者说一个"假终点"。路径虽然匹配了,但这只是一个中间节点(例如
/users),它本身不能处理请求,真正的终点在它的子节点上(例如
/users/list 或
/users/:id)。但我们的请求路径已经用完了,无法再往下走了。
为什么会发生这种情况? 这通常发生在有路由冲突或歧义时,路由器“贪婪地”选择了一条看似正确但实际上是死胡同的路。
试想一下情况:
- 注册路由 A:
/users/new(静态)- 注册路由 B:
/users/:id(动态)- 用户请求:
GET /users/new路由器在匹配完
/users/后,剩下new。此时它面临一个选择:是匹配静态的new节点,还是匹配动态的:id节点?虽然 Gin 会优先匹配静态节点,但我们可以设想一个场景:如果/users/new这个路由没有注册 handler(开发者忘了写),而/users/:id注册了。当请求
/users/new时,它会先走到new节点。发现handlers是nil,于是就进入了这个回溯逻辑。
第 5 步:智能建议 - TSR (Trailing Slash Redirect)
1 | // We can recommend to redirect to the same URL without a |
tsr 是 Gin 的一个非常人性化的功能。
- 场景 1: 你注册了
/users,但用户请求了/users/。 - 场景 2: 你注册了
/users/,但用户请求了/users。
在这两种情况下,Gin 不会直接返回
404 Not Found。getValue
函数在发现“几乎”匹配(就差一个尾部斜杠)时,会将 value.tsr
设置为 true。上层逻辑接收到这个 true
信号后,就会向客户端返回一个 301 或 307
重定向建议,告诉浏览器应该访问另一个带或不带斜杠的
URL。这提升了用户体验。
第 6 步:回溯 (Backtracking)
这是函数中最复杂,但也最能体现其强大的部分。这里的逻辑跟第 4 步中到达"假终点"大致是相同的。
1 | // the current node needs to roll back to last valid skippedNode |
同样是考虑以下路由:
/users/:id/users/new
我们假设另外一种情况,当一个请求 GET /users/new
到来时:
- 它首先匹配到
/users/前缀。 - 剩下的路径是
new。此时,它既可能匹配静态的new,也可能匹配参数:id。 - 大多数路由器的实现会优先匹配静态路径。但如果
getValue先进入了:id的分支,它会把new当作:id的值。如果:id节点下没有更多子路径,查找就会失败。 - 这时,就需要回溯。
skippedNodes记录了"上一个有其他选择的路口"(例如,那个同时存在静态子节点和通配符子节点的/users/节点)。 - 代码会回退到那个路口,并尝试另一条路(即匹配
new静态路径),最终找到正确的handlers。
这个机制确保了 静态路由的优先级总是高于通配符路由,即使它们的路径结构很相似。
总结
Gin 的 (n *node) getValue
函数是一个基于基数树 (Radix Tree)
的、高度优化的路由查找实现。它的执行过程可以概括为:
- 循路前进:沿着基数树,通过前缀匹配
(
n.path) 和索引查找 (n.indices),快速匹配 URL 的静态部分。 - 灵活应变:当遇到通配符节点 (
:param或*catchall) 时,能正确解析路径参数。 - 终点判断:当路径完全匹配时,检查当前节点是否有
handlers,有则成功返回。 - 智能容错:当精确匹配失败,但存在仅差一个尾部斜杠的路由时,会给出重定向建议 (TSR)。
- 迷途知返:通过
skippedNodes机制实现回溯,确保在有多种可能匹配路径(静态 vs 通配符)时,能够做出正确的选择,保证路由匹配的准确性。
通过这些精巧的设计,Gin 在保证强大功能的同时,实现了极高的路由性能。
我画了个流程图,供你参考:
graph TD
subgraph MainProcess [主流程]
direction TB
A["getValue(path, ...)"]:::startend
%% Stage 1: Traversal Loop
subgraph TraversalPhase ["第一阶段:遍历深入 (WALK 循环)"]
direction TB
W["循环开始
在当前节点 n"]:::process
C1{"路径前缀匹配 且 路径有剩余?"}:::decision
P1["削减已匹配路径"]:::process
C2{"匹配静态子节点?"}:::decision
P2["记录回溯点(skippedNodes)
n = 进入静态子节点"]:::process
C3{"有通配符子节点?"}:::decision
P3["n = 进入通配符子节点"]:::process
C4{"节点类型是 :param?"}:::decision
P4["处理 :param, 截取并保存参数"]:::process
C5{"参数后还有剩余路径?"}:::decision
end
%% Stage 2: Final Adjudication
Junction["
无法继续深入
转到最终裁决
"]:::decision
subgraph FinalAdjudication [第二阶段:最终裁决]
direction TB
C_FINAL_BACKTRACK{"需要回溯?
(当前节点无 handler)"}:::decision
P_FINAL_BACKTRACK["执行回溯
遍历 skippedNodes 查找备用路径
若找到, 则恢复现场"]:::process
C_FINAL_HANDLER{"找到 handler?
(n.handlers != nil)"}:::decision
SUCCESS["成功
返回 value (含 handlers)"]:::startend
P_FINAL_TSR["TSR 检查
检查是否存在 +/- 斜杠的“近亲”路由"]:::process
FINAL_RETURN["返回 value
(可能含 TSR, 或为空)"]:::startend
end
B4_CatchAll["处理 *catchAll
截取所有剩余路径
保存参数, 赋值 handlers
直接成功返回"]:::startend
%% --- Connections (Corrected Syntax) ---
A --> W
W --> C1
%% Traversal Logic
C1 -- "是(Yes)" --> P1
P1 --> C2
C2 -- "是(Yes)" --> P2
P2 -- "进入下一轮" --> W
C2 -- "否(No)" --> C3
C3 -- "是(Yes)" --> P3
P3 --> C4
C4 -- "是(Yes)" --> P4
P4 --> C5
C5 -- "是(Yes)" --> W
C4 -- "否(No), 是 *catchAll" --> B4_CatchAll
%% Exits from Traversal to Adjudication
C1 -- "否(No)" --> Junction
C3 -- "否(No): 无路可走" --> Junction
C5 -- "否(No): 路径耗尽" --> Junction
%% Adjudication Logic
Junction --> C_FINAL_BACKTRACK
C_FINAL_BACKTRACK -- "是(Yes)" --> P_FINAL_BACKTRACK
P_FINAL_BACKTRACK -- "回到循环" --> W
C_FINAL_BACKTRACK -- "否(No): 无需回溯" --> C_FINAL_HANDLER
C_FINAL_HANDLER -- "是(Yes)" --> SUCCESS
C_FINAL_HANDLER -- "否(No)" --> P_FINAL_TSR
P_FINAL_TSR --> FINAL_RETURN
end
%% Styling
classDef startend fill:#9f9,stroke:#333,stroke-width:2px,color:#000
classDef panic fill:#f99,stroke:#333,stroke-width:2px,color:#000
classDef decision fill:#ffc,stroke:#333,stroke-width:2px,color:#000
classDef process fill:#9cf,stroke:#333,stroke-width:2px,color:#000
中间件执行 c.Next
执行机制
经过路由匹配,我们找到了处理当前请求的节点,返回的 value
结构如下:
1 | type nodeValue struct { |
其中处理函数就是 handlers,它是类型的
HandlersChain,其实就是 []HandleFunc:
1 | // HandlersChain defines a HandlerFunc slice. |
在 engine.handleHTTPRequest()
中,找到了处理节点后,执行了下面 4 行代码,其中核心就是
c.Next():
1 | c.handlers = value.handlers |
我们来看一下 c.Next():
1 | type Context struct { |
它的逻辑其实简单,就是通过递增 index 依次执行
HandlersChain。
我们顺带看一下 c.Abort(),真是聪明!将 index 设置为
abortIndex,这样后面的 handler 就执行不到了!
1 | func (c *Context) Abort() { |
接口实现
1 | // IRouter defines all router handle interface includes single and group router. |
注册路由的核心接口是 IRouter,并且为 Engine
和 RouterGroup 实现了 IRouter 接口:
1 | type Engine struct { |
查看源码后我们发现,其实真正实现 IRouter 接口的,只有
RouterGroup!然后在 Engine 中组合
RouterGroup,这样我们既可以直接在 Engine
上(根路径)注册路由,需要注意的是,IRouter
中有一个方法:
1 | Group(string, ...HandlerFunc) *RouterGroup |
这样就巧妙地实现了分组路由和递归分组路由的功能!
我们先来看看 Group() 的实现:
1 | func (group *RouterGroup) Group(relativePath string, handlers ...HandlerFunc) *RouterGroup { |
再来看看注册路由的具体实现,以 GET() 为例:
1 | func (group *RouterGroup) GET(relativePath string, handlers ...HandlerFunc) IRoutes { |
注册逻辑在 engine.addRoute() 中:
1 | func (engine *Engine) addRoute(method, path string, handlers HandlersChain) { |
路由注册
核心逻辑在 root.addRoute()
中,这个函数的目标是在路由树中为给定的 path 和
handlers 找到一个安身之处,必要时会重塑树的结构。
整个函数的核心是一个 walk
循环,它模拟了从树的根节点开始,一步步向下走,直到找到或创造出新路由位置的过程。接下来我们细细拆解这个过程。
初始化与空树处理
1 | fullPath := path |
n.priority++: 每当有一个路由需要经过或终止于当前节点n,这个节点的优先级(权重)就会增加。这反映了该节点在路由树中的"繁忙"程度。- 空树判断: 这是最简单的基础情况。如果当前节点
n的path和children都为空,说明这是一棵空树(或者说我们正处于一个未初始化的根节点)。 - 操作: 直接调用
n.insertChild(path, fullPath, handlers),将整条path作为第一个孩子插入,并把自己的类型设置为root。整个添加过程结束。
如果不是空树,程序就进入 walk
循环,开始真正的"建树之旅"。
1 | i := longestCommonPrefix(path, n.path) |
这是循环体内的第一步,也是最关键的一步。它计算了
要插入的新路径 path 和
当前节点路径 n.path 之间的最长公共前缀
(Longest Common Prefix) 的长度 i。这个 i
的值,决定了接下来所有的操作。
要不,刷个 leetcode 放松一下?🤡🤡🤡 longestCommonPrefix
场景一:节点分裂 (Split Edge)
1 | // Split edge |
- 触发条件:
i < len(n.path)。这意味着公共前缀的长度i小于当前节点n的路径长度。换句话说,新路径和当前节点路径在中间某个位置出现了"分叉"。 - 经典例子: 当前节点
n.path是"/hello",要插入的新路径path是"/help"。- LCP 是
"/hel",长度i为 4。 i < len("/hello")(4 < 6) 条件成立。
- LCP 是
- 操作 (这是最精妙的部分):
- 创建新子节点
child:- 这个
child节点继承了当前节点n"后半段"的路径,即n.path[i:](例子中是"lo")。 - 它也完全继承了
n之前的所有子节点 (n.children)、handlers、wildChild状态等。它的priority会减 1,因为父节点n的priority已经加过了。
- 这个
- 改造当前节点
n:- 当前节点
n被"改造"成一个新的、更短的 父节点/分支节点。 n.path被截断为公共前缀path[:i](例子中是"/hel")。n.handlers被设为nil,因为它现在只是一个中间节点。n.children被重置,现在只包含刚刚创建的那个child节点。n.indices也被更新,只包含指向新child节点的索引字符 (例子中是'l')。
- 当前节点
- 创建新子节点
- 结果: 执行完分裂后,树的结构从
(node path="/hello")变成了(node path="/hel") -> (child path="lo")。此时,我们还没有处理新路径"/help"剩下的部分 ("p")。代码会自然地流转到下面的if i < len(path)逻辑,将"p"作为/hel节点的第二个孩子插入。
场景二:继续向下走或创建新分支
1 | // Make new node a child of this node |
- 触发条件:
i < len(path)。这意味着在匹配完公共前缀后(或者说,完整匹配了当前节点的path后),要插入的新路径path还有剩余部分。 - 例子: 当前节点
n.path是"/users",要插入的新路径是"/users/new"。- LCP 是
"/users",长度i为 6。i == len(n.path)。 i < len("/users/new")(6 < 10) 条件成立。
- LCP 是
具体过程如下:
path = path[i:]: 更新path为剩余未处理的部分 (例子中是"/new")。c := path[0]: 取出剩余路径的第一个字符 (例子中是/)。检查现有子节点:
for i, max := 0, len(n.indices); ...这是最常见的"向下走"逻辑。程序用字符
c去匹配n.indices,如果找到了匹配的静态子节点,就增加那个子节点的priority,然后n = n.children[i],将n更新为那个子节点,continue walk,从新的n开始下一轮循环。插入新子节点:
如果
for循环没找到匹配的子节点,并且c不是通配符 (:或*),程序就会创建一个新的静态子节点,更新n.indices,并将n指向这个新创建的子节点。如果
c是通配符,会进入else if n.wildChild逻辑。这个逻辑主要是用来处理通配符冲突的。例如,你不能在/:id之后再添加/:user。如果存在冲突,程序会panic并给出非常清晰的错误信息。如果没有冲突(例如,在/:id节点下添加子节点/profile),则会继续向下walk。这里检查了 3 个条件:条件 ①
len(path) >= len(n.path) && n.path == path[:len(n.path)]:检查新路径path是否以已存在的通配符路径n.path开头。- 可能兼容:已存在
:id,新来:id/profile。":id/profile"以":id"开头,通过。 - 绝对冲突:已存在
:id,新来:user。":user"并不以":id"开头,检查失败,将直接跳到panic。这正是我们之前讨论的,/:id和/:user无法共存的逻辑实现。
- 可能兼容:已存在
条件 ②
n.nType != catchAll:检查已存在的通配符节点类型不是catchAll(*类型)。catchAll类型的通配符(例如/static/*filepath)是终极的,它会匹配所有后续路径。因此,在它后面再添加任何子节点(例如/static/*filepath/more)都是没有意义的,也是不被允许的。如果已存在的是catchAll,此条件不满足,将panic。条件 ③
(len(n.path) >= len(path) || path[len(n.path)] == '/'):这是一个非常精妙的检查,用于确保通配符的"边界清晰",防止部分重叠的歧义命名。它分为两种允许的情况:len(n.path) >= len(path): 新路径和旧通配符路径完全一样(或更短,但由于条件 A,只能是完全一样)。例如,已存在:id,新来的也是:id(后面可能要加子节点)。path[len(n.path)] == '/': 新路径比旧通配符路径更长,并且紧跟着的第一个字符必须是/。例如,已存在:id,新来的是:id/profile,profile前面必须有/分隔。
如果所有这三个条件都奇迹般地满足了,说明新路径是现有通配符的一个完全合法的"子路径"或"扩展"。程序就会执行
continue walk,继续愉快地向下走,处理路径剩下的部分。
n.insertChild(path, fullPath, handlers): 这是创建新节点的最终调用,并将path、fullPath和handlers赋予这个新的叶子节点。然后return,添加过程结束。
场景三:终点命中,添加 Handlers
1 | // Otherwise add handle to current node |
- 触发条件: 循环走到了一个节点
n,并且i == len(n.path)且i == len(path)。这意味着要插入的路径和当前节点的路径完全一样。 - 含义: 找到了一个已经存在的、路径完全匹配的节点。
- 操作:
- 检查
n.handlers是否已经存在。如果存在,说明重复注册路由,这是不允许的,程序会panic。 - 如果不存在,就将
handlers和fullPath赋予当前节点n。 return,添加过程结束。
- 检查
总结
addRoute 函数通过一个 walk
循环,非常精妙地处理了向基数树中插入新路由的所有可能情况:
- 从计算 LCP 开始,判断新路由与当前节点的关系。
- 如果新路由与现有节点路径部分重叠,则分裂现有节点,创造出一个新的分支节点。
- 如果新路由是现有节点路径的超集,则深入到子节点中,或创建新的子节点。
- 如果新路由与现有节点 路径完全重合,则为其附加处理函数,或因重复注册而报错。
我画了个流程图,供你参考:
graph TD
subgraph MainProcess [主流程]
direction TB
%% Node Definitions
A["addRoute(path, handlers)"]:::startend
A1["n.priority++"]:::process
C0{"树为空?"}:::decision
%% Empty Tree Path
B0["insertChild(path, ...)
n.nType = root
return"]:::startend
%% Main Walk Loop
W["WALK 循环开始"]:::process
W1["i := longestCommonPrefix(path, n.path)"]:::process
C1_SplitEdge{"i < len(n.path)?
(需要分裂节点?)"}:::decision
%% Split Edge Logic
B1["节点分裂 (Split Edge)
1. 创建 child 继承 n 的后半段路径和属性
2. 改造 n 为父节点, path 截为公共前缀
3. n 的 children 重置为 [child]
4. n.handlers = nil"]:::process
%% Continue After Split or No Split
C2_MorePath{"i < len(path)?
(新路径还有剩余?)"}:::decision
%% Path A: No More Path (Exact Match)
C3_HasHandlers{"n.handlers != nil?"}:::decision
P1["panic('路由重复注册')"]:::panic
B2["n.handlers = handlers
n.fullPath = fullPath
return"]:::startend
%% Path B: More Path Left
W2["path = path[i:]
c := path[0]"]:::process
C4{"静态子节点匹配成功?
(for c in n.indices)"}:::decision
B3["n = 匹配的子节点
n.priority++
continue walk"]:::process
%% Wildcard Logic
C5{"c 是通配符 : 或 * ?"}:::decision
C5_1{"n 已有通配符子节点?
(n.wildChild)"}:::decision
C6{"兼容性检查通过?"}:::decision
B4["n = 已存在的通配符子节点
n.priority++"]:::process
B5["continue walk"]:::process
P2["panic('通配符冲突')"]:::panic
%% Insert New Child
B6["创建新子节点
1. 创建 child node
2. 更新 n.indices
3. n.addChild(child)
4. n = child"]:::process
B7["n.insertChild(path, ...)
return"]:::startend
%% Connections
A --> A1 --> C0
C0 -- "是(Yes)" --> B0
C0 -- "否(No)" --> W
W --> W1 --> C1_SplitEdge
C1_SplitEdge -- "是(Yes)" --> B1 --> C2_MorePath
C1_SplitEdge -- "否(No)" --> C2_MorePath
C2_MorePath -- "否(No) - 路径完全匹配" --> C3_HasHandlers
C3_HasHandlers -- "是(Yes)" --> P1
C3_HasHandlers -- "否(No)" --> B2
C2_MorePath -- "是(Yes) - 路径有剩余" --> W2
W2 --> C4
C4 -- "是(Yes)" --> B3 --> W
C4 -- "否(No)" --> C5
C5 -- "是(Yes)" --> C5_1
C5_1 -- "否(No)" --> B6
C5_1 -- "是(Yes)" --> B4 --> C6
C6 -- "是(Yes)" --> B5 --> W
C6 -- "否(No)" --> P2
C5 -- "否(No) - 静态" --> B6
B6 --> B7
end
%% Styling
classDef startend fill:#9f9,stroke:#333,stroke-width:2px,color:#000
classDef panic fill:#f99,stroke:#333,stroke-width:2px,color:#000
classDef decision fill:#ffc,stroke:#333,stroke-width:2px,color:#000
classDef process fill:#9cf,stroke:#333,stroke-width:2px,color:#000
响应返回 ctx.Json
我们的业务逻辑,会在上一步的中间件执行就顺带被执行了。现在我们来看一下请求结果是如何被返还回去的,这里以
ctx.Json() 为例。
1 | // JSON serializes the given struct as JSON into the response body. |
这里的核心是 r.Render,它是一个接口:
1 | // Render interface is to be implemented by JSON, XML, HTML, YAML and so on. |
这里我们看一下 JSON 的实现:
1 | // Render (JSON) writes data with custom ContentType. |
其实逻辑就 2 步:
- 写 content-type: application/json。
- 调用标准库的
http.responseWriter将响应结果写回缓冲区。
在调用链处理完毕后,最后就回到了我们在请求入口
c.serve(connCtx) 中分析到的
finishRequest,然后通过建立好的 TCP 连接传递给客户端。
优雅关闭 httpServer.Shutdown
Gin 框架本身不提供优雅关闭的功能,需要使用标准库的
http.Server 来实现优雅关闭(最好结合 tableflip
实现无缝切换)。
基础实现如下:
1 | // 创建一个通道来接收系统信号 |
我们看一下 Shutdown() 的具体逻辑:
1 | func (s *Server) Shutdown(ctx context.Context) error { |
核心逻辑如下:
将服务置为关闭中的状态,这样在
Accept的时候,就会拒绝新的连接了。执行用户自定义的钩子函数,Gin 框架扩展性的体现。
s.listenerGroup.Wait()等待监听器彻底关闭,这里对应了前面Serve中的这段代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27func (s *Server) Serve(l net.Listener) error {
// ...
if !s.trackListener(&l, true) {
return ErrServerClosed
}
defer s.trackListener(&l, false)
// ...
}
func (s *Server) trackListener(ln *net.Listener, add bool) bool {
s.mu.Lock()
defer s.mu.Unlock()
if s.listeners == nil {
s.listeners = make(map[*net.Listener]struct{})
}
if add {
if s.shuttingDown() {
return false
}
s.listeners[ln] = struct{}{}
s.listenerGroup.Add(1) // <-------- 开启监听
} else {
delete(s.listeners, ln)
s.listenerGroup.Done() // <-------- 结束监听
}
return true
}不断轮询关闭空闲的连接,直到整个服务处于静止状态。这里使用的指数退避和抖动:
1
2
3
4
5
6
7
8
9
10
11const shutdownPollIntervalMax = 500 * time.Millisecond // 最长轮询等待时间为 500ms
pollIntervalBase := time.Millisecond // 从 1ms 开始
nextPollInterval := func() time.Duration {
interval := pollIntervalBase + time.Duration(rand.Intn(int(pollIntervalBase/10))) // 加 10% 随机抖动时间
pollIntervalBase *= 2 // 翻倍
if pollIntervalBase > shutdownPollIntervalMax { // 限制最长轮询等待时间
pollIntervalBase = shutdownPollIntervalMax
}
return interval
}指数退避:轮询的间隔时间
pollIntervalBase从 1 毫秒开始,每次轮询后都翻倍,直到一个最大值 (shutdownPollIntervalMax)。这非常高效:开始时频繁检查,以便服务能快速关闭;如果耗时较长,就降低检查频率,避免空转浪费 CPU。抖动:在基础间隔上增加一个 10% 的随机时间。这在分布式系统中是一个好习惯,可以避免多个服务在同一时刻执行相同操作,造成"惊群效应"。
返回,完成服务的安全关闭。
流程总结
最后我们做一个汇总。一个 HTTP 请求在 Gin 框架中的完整旅程可以总结为以下几个核心阶段:
1. 启动与监听:
- Gin 服务的启动入口是
r.Run(),它首先会解析监听地址,默认使用:8080端口,也可以通过PORT环境变量或直接传参来指定。 - 其底层核心是调用了 Go 标准库的
http.ListenAndServe,进一步通过net.Listen监听 TCP 端口,并最终在Serve方法中进入一个for循环,通过l.Accept()来接收新的客户端连接。 - 每当接收到一个新连接,就会创建一个
conn对象,并为其开启一个独立的 goroutine(go c.serve(connCtx))来处理后续的请求。
2. 请求处理入口:
- 在
c.serve的for循环中,服务器通过c.readRequest(ctx)读取和解析原始的 HTTP 请求数据。 - 最关键的一步是调用
serverHandler{c.server}.ServeHTTP(w, w.req),这将请求的ResponseWriter和Request对象传递给了 Gin 引擎的核心处理逻辑。 - 请求处理完毕后,会调用
w.finishRequest()来写入响应数据、刷新缓冲区并清理资源,为下一次请求复用做准备。
3. 上下文创建与回收:
- Gin 引擎的
ServeHTTP方法是处理所有请求的入口。为了提高性能,Gin 使用sync.Pool对象池来复用gin.Context对象。 - 每次处理新请求时,会从池中
Get()一个Context,重置其内部状态并与当前请求的ResponseWriter和Request绑定。 - 请求处理完毕后,
Context对象会被Put()回对象池,从而避免了频繁创建和销毁对象带来的垃圾回收压力。
4. 路由匹配:
- Gin 的核心路由机制是基于一个
methodTrees结构,它为每种 HTTP 方法(GET、POST 等)维护一棵独立的基数树(Radix Tree)。 - 这棵树由
node节点构成,node结构的path、indices、wildChild、children等字段协同工作,构建了一个既节省内存又查找飞快的路由树。indices字段通过存储子节点首字母作为快速索引,是其高性能的关键之一。 - 路由查找由
root.getValue()方法执行,它通过一系列步骤(前缀匹配、静态路由查找、通配符匹配)来定位处理器。 getValue的设计非常精巧,它利用skippedNodes实现了回溯(Backtracking) 机制,以确保在面对静态路由(/users/new)和动态路由(/users/:id)的选择时,能够优先匹配静态路由,保证了路由的准确性。同时,它还支持 TSR(Trailing Slash Redirect) 建议,提升了用户体验。
5. 中间件与业务逻辑执行:
- 路由匹配成功后,找到的
HandlersChain(一个[]HandlerFunc切片)会被赋值给gin.Context。 c.Next()方法通过一个for循环和递增的index索引,依次调用HandlersChain中的所有处理函数(包括全局中间件、分组中间件和最终的业务 Handler)。c.Abort()方法通过将index设置为一个极大值来巧妙地中断调用链的执行。
6. 响应返回:
- 当业务逻辑中调用
c.JSON()等方法时,实际上是调用了c.Render()。 Render方法会设置 HTTP 状态码,并通过render.Render接口来执行具体的渲染逻辑。例如,render.JSON会使用标准库的json.Marshal将对象序列化,然后通过http.ResponseWriter将数据写入响应体。
7. 优雅关闭:
- Gin 自身不提供优雅关闭,但可以与标准库的
http.Server结合实现。 httpServer.Shutdown()的核心逻辑是:- 首先,通过原子操作
s.inShutdown.Store(true)设置关闭状态,并调用s.closeListenersLocked()关闭监听器,从源头阻止新连接的建立。 - 并发执行通过
onShutdown注册的钩子函数。 - 进入一个轮询循环,不断调用
s.closeIdleConns()来关闭已处理完请求的空闲连接。 - 这个轮询采用了指数退避 (Exponential Backoff) 和抖动 (Jitter) 策略,在保证能快速关闭的同时,避免了在等待期间空转浪费 CPU。
- 整个关闭过程受传入的
context.Context控制,可以实现超时强制关闭,避免无限期等待。
- 首先,通过原子操作
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




