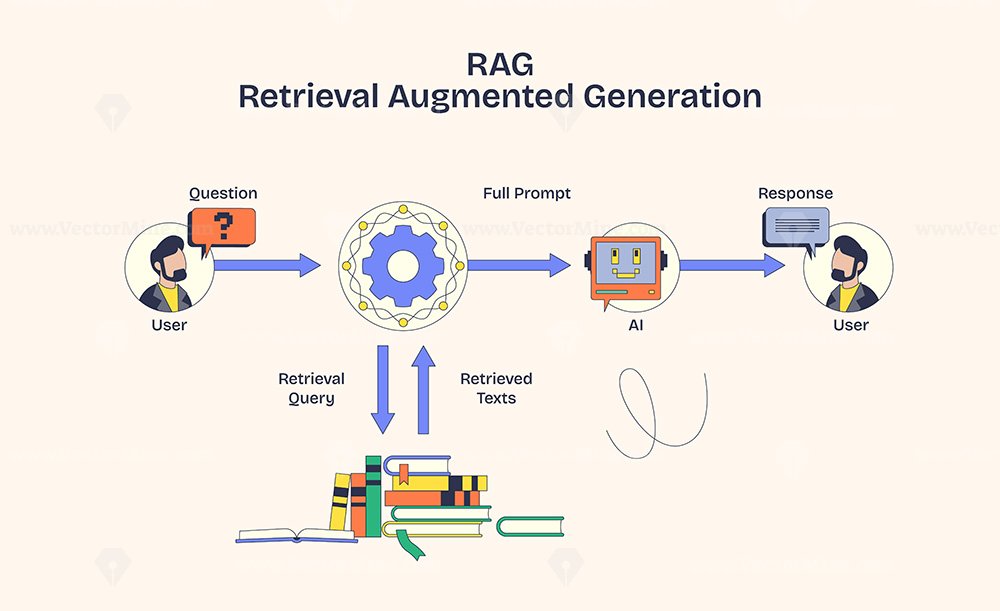
1. 文档加载
langchian Document
page_content: 文档内容metadata: 文档元信息
1 | from langchain.schema import Document |
html
在线网页:from langchaincommunity.document_loaders _import WebBaseLoader
本地文件:from langchaincommunity.document_loaders _import BSHTMLLoader
解析代码:from bs4 import BeautifulSoup
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16from bs4 import BeautifulSoup
# 读取 HTML 文件内容
html_txt = ''
with open("./file_load/test.html", 'r') as f:
for line in f.readlines():
html_txt += line
# 解析 HTML
soup = BeautifulSoup(html_txt, 'lxml')
# 代码块 td class="code"
code_content = soup.find_all('td', class_="code")
for ele in code_content:
print(ele.text)
print("+"*100)这里对代码块解析时的
class需要根据具体网页的元素定义进行更换,不过大体思路都一样(也不局限于代码块)。
加载文件:from langchaincommunity.document_loaders _import PyMuPDFLoader
解析表格:import fitz
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import fitz
doc = fitz.open("./file_load/fixtures/zhidu_travel.pdf")
table_data = []
text_data = []
doc_tables = []
for idx, page in enumerate(doc):
text = page.get_text()
text_data.append(text)
tabs = page.find_tables()
for i, tab in enumerate(tabs):
ds = tab.to_pandas()
table_data.append(ds.to_markdown())
for tab in table_data:
print(tab)
print("="*100)
Unstructured
Unstructured 是由 Unstructured.IO 开发的开源 Python 库,专为处理非结构化数据(如 PDF、Word、HTML、XML 等)设计。在 LangChain 中,它作为文档加载的核心工具,实现以下功能:
- 格式支持广泛:解析 PDF、DOCX、PPTX、HTML、XML、CSV 等格式,甚至支持扫描件中的 OCR 文本提取。
- 元素分区(Partitioning):将文档拆分为结构化元素(标题、段落、表格、列表),保留原始布局和元数据。
- 数据清洗:自动清理文档中的无关符号、页眉页脚,生成纯净文本。
使用 langchain_unstructured 需要安装:
1 | uv add unstructured |
需要额外安装:
1 | uv remove camelot-py # 如果有 camelot 需要先移出,在一些版本上存在冲突 |
使用时导入包:
1 | from langchain_unstructured import UnstructuredLoader |
PPT
需要安装额外依赖:
1 | uv add python-pptx |
使用时导入包:
1 | from langchain_community.document_loaders import UnstructuredPowerPointLoader |
解析 PPT 中的表格及其他特殊类型,可以使用原始的
python-pptx 库:
1 | from pptx import Presentation |
Word
需要安装额外依赖:
1 | uv add docx2txt |
使用时导入包:
1 | from langchain_community.document_loaders import Docx2txtLoader |
解析 Word 中的表格及其他特殊类型,可以使用原始的
python-docx 库:
1 | from docx import Document |
Excel
需要安装额外依赖:
1 | uv add openpyxl |
ragflow.deepdoc
RAGFlow 是一个开源的、基于"深度文档理解"的 RAG 引擎。
RAGFlow 的主要特点:
- 开箱即用: 提供 Web UI
界面,用户可以通过简单的几次点击,无需编写代码,就能完成知识库的建立和问答测试。通过
Docker可以一键部署,非常方便。 - 工作流自动化 (Automated Workflow): RAGFlow 将复杂的 RAG 流程(文档解析、切块、向量化、存储、检索、生成)模板化。用户可以选择不同的模板来适应不同的数据和任务需求,整个过程高度自动化。
- 可视化与可解释性: 在处理文档时,RAGFlow 会生成一个可视化的解析结果图,让用户能清晰地看到文档是如何被理解和切分的,大大增强了系统的透明度和可调试性。
- 企业级特性: 它支持多种文档格式,能够生成可溯源的答案(即答案会附上来源出处),并且兼容多种 LLM 和向量数据库,易于集成到现有企业环境中。
如果说 RAGFlow 是一个高效的问答“工厂”,那么 DeepDoc 就是这个工厂里最核心、最先进的“原材料加工车间”。所有外部文档在进入知识库之前,都必须经过 DeepDoc 的精细处理。
DeepDoc 的全称是 Deep Document Understanding(深度文档理解),它是 RAGFlow 实现高质量检索的基石。它并非简单地提取文本,而是试图像人一样“看”和“理解”文档的版面布局和内在逻辑。
DeepDoc 的工作原理与核心能力:
- 视觉版面分析 (Vision-based Layout Analysis):
- 理论: DeepDoc 首先会利用计算机视觉(CV)模型,像人眼一样扫描整个文档页面。它不是逐行读取字符,而是先识别出页面上的宏观结构,例如:这是标题、那是段落、这是一个表格、这是一张图片、这是一个页眉/页脚。
- 实践: 对于一个两栏布局的
PDF报告,传统的文本提取工具可能会把左边一行的结尾和右边一行的开头错误地拼在一起。而 DeepDoc 的视觉分析能准确识别出两个独立的栏目,并按照正确的阅读顺序(先读完左栏,再读右栏)来处理文本。
- 智能分块 (Intelligent Chunking):
- 理论: 这是 DeepDoc 最具价值的一点。在理解了文档布局之后,它会进行“语义分块”而非“物理分块”。传统的 RAG 会把文档切成固定长度(如 500 个字符)的块,这常常会将一个完整的表格或一段逻辑连贯的话拦腰截断。
- 实践: DeepDoc 会将一个完整的表格识别出来并视为一个独立的“块”(Chunk)。一个标题和它紧随其后的段落也会被智能地划分在一起。这样做的好处是,当用户提问与表格相关的问题时,系统检索到的就是这个包含完整上下文的表格块,而不是表格的某几行碎片。这极大地保证了提供给 LLM 的上下文信息的完整性和逻辑性。
- 高质量光学字符识别 (OCR):
- 理论: 对于扫描的
PDF文件或者文档中嵌入的图片,DeepDoc 内置了高质量的 OCR 引擎。 - 实践: 即便文档是扫描的复印件,它也能尽可能准确地提取出其中的文字内容,并将其融入到上述的版面分析中,确保信息不丢失。
- 理论: 对于扫描的
- 表格解析与转译:
- 理论: 识别出表格只是第一步,更关键的是让 LLM 能“读懂”表格。
- 实践: DeepDoc 能够提取出表格的结构化数据,并将其转换为 LLM 更容易理解的格式,例如 Markdown 格式。一个复杂的表格图片,在经过 DeepDoc 处理后,可能会变成一个 Markdown 文本表格,这样 LLM 就能轻松地理解其行列关系,并回答诸如“请总结一下表格中第三季度销售额最高的产品是哪个?”这类的问题。
笔者在实践过程中,通过精简 ragflow.deepdoc 中的 pdfparser,抽出了一个组件 deepdoc_pdfparser.
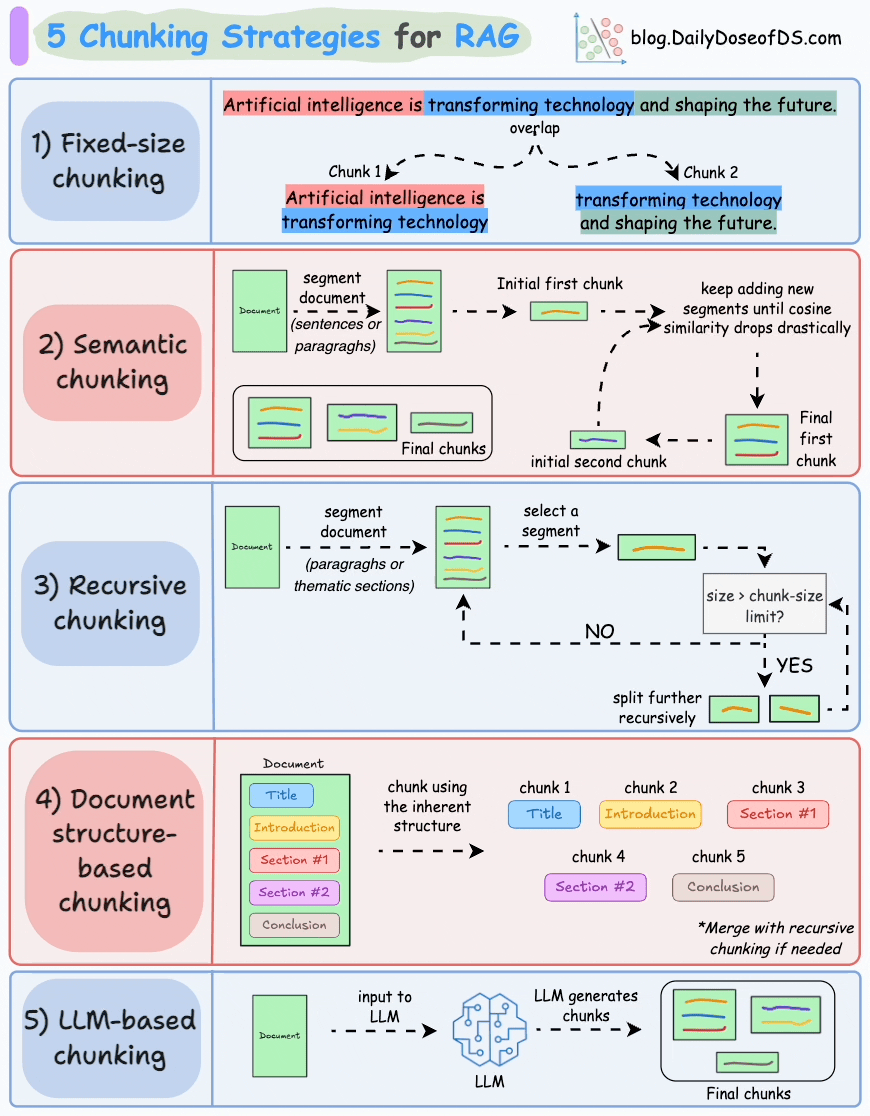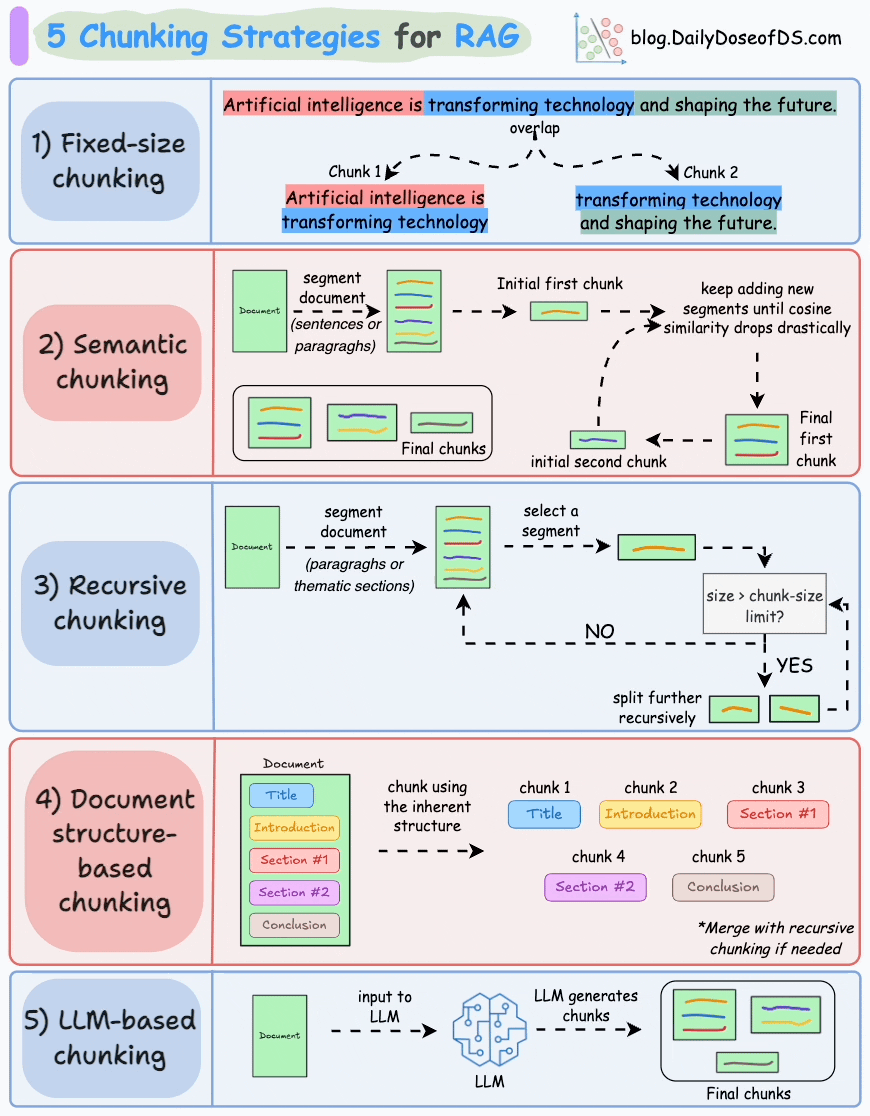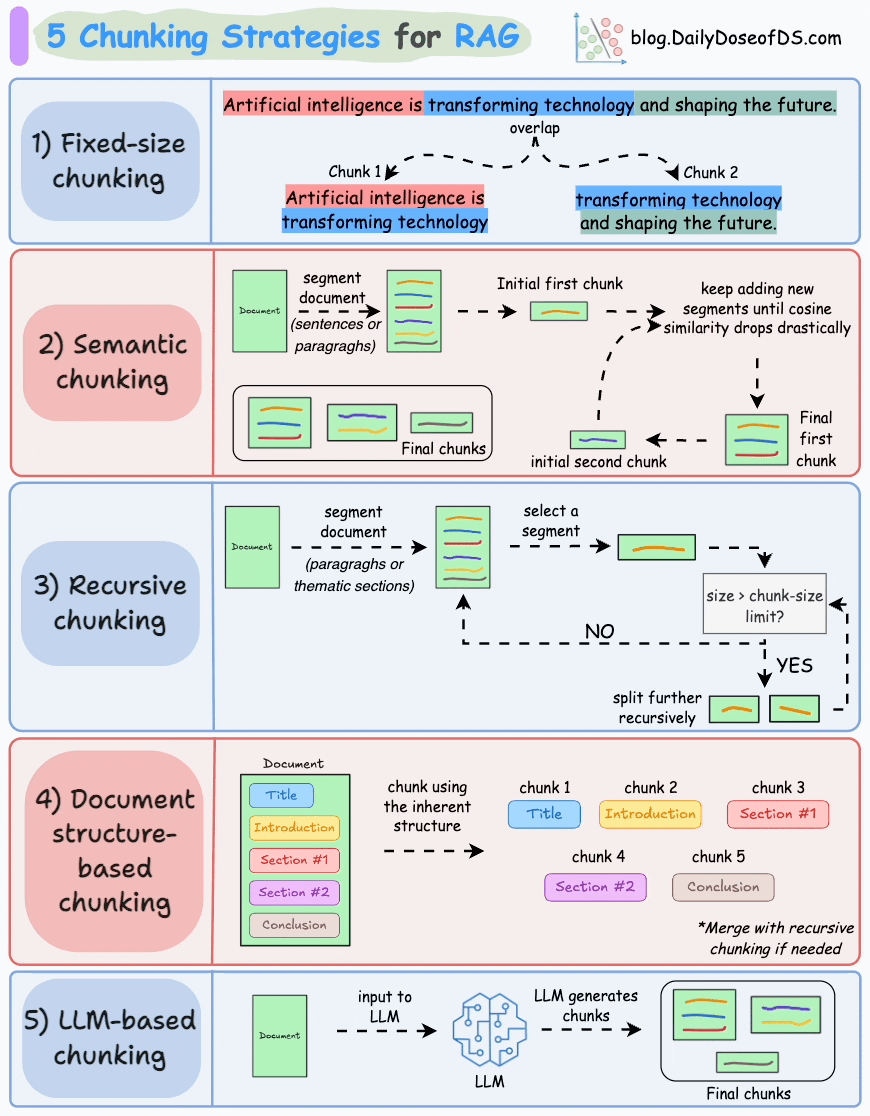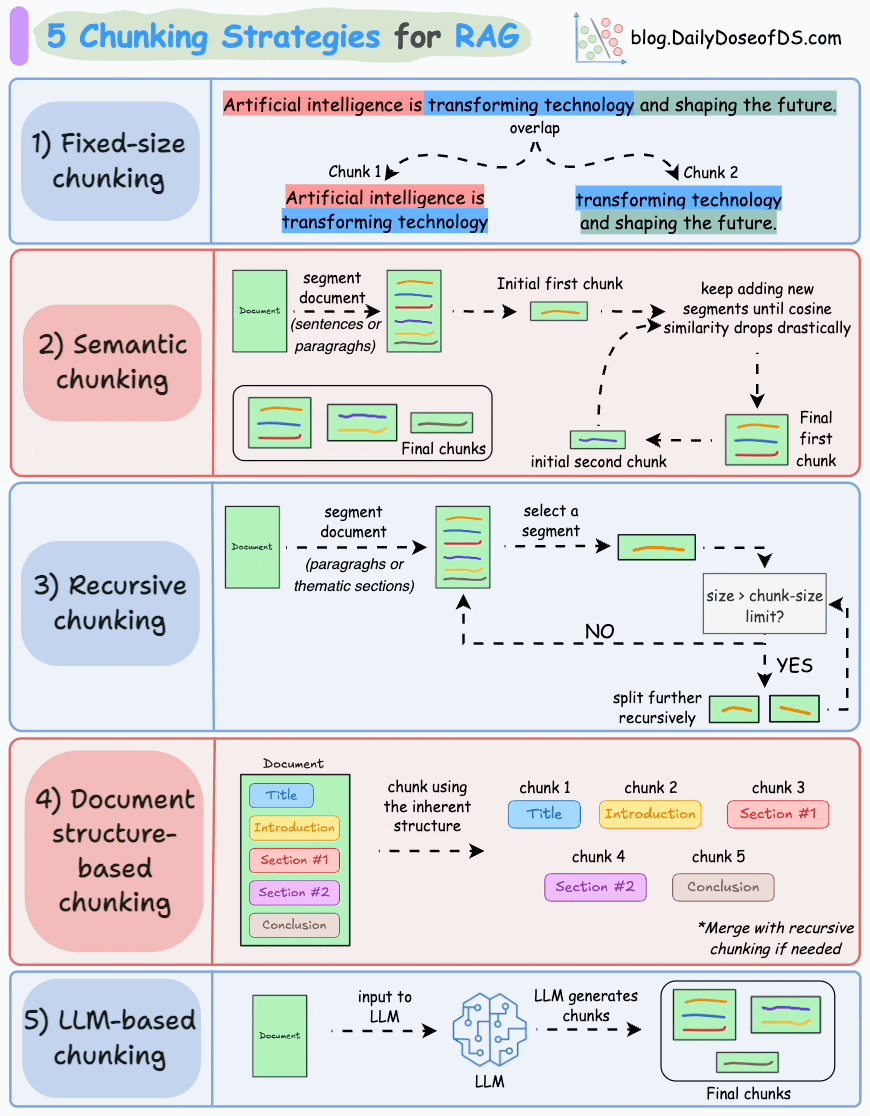
2. 分块策略
- 可视化工具:ChunkViz
3. 向量嵌入
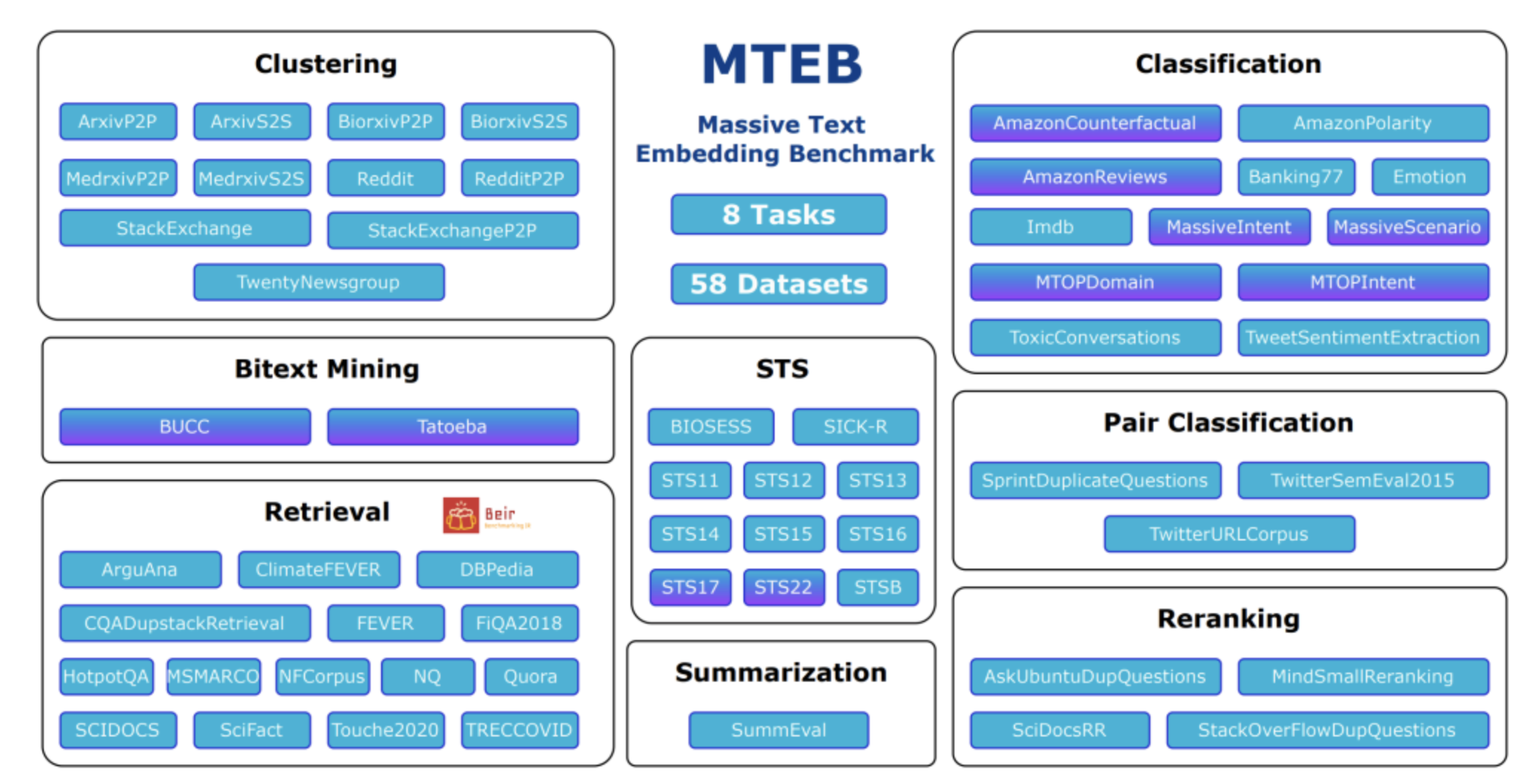
3.1 嵌入模型评测
Hugging Face 的 MTEB (Massive Text Embedding Benchmark) 是一个大规模的文本嵌入模型评测基准。它的核心作用是为各种文本嵌入模型提供一个统一、全面、客观的性能衡量标准。
涵盖了文本嵌入在现实世界中最常见的 8 种应用场景,共计 58 个数据集和 112 种语言。这 8 大任务分别是:
- Bitext Mining (双语文本挖掘): 在不同语言的句子中找出翻译对。
- Classification (分类): 将文本划分到预定义的类别中。
- Clustering (聚类): 将相似的文本分组在一起。
- Pair Classification (句子对分类): 判断两个句子是否具有某种关系 (如释义、矛盾等)。
- Reranking (重排序): 对一个已经排好序的列表 (如搜索结果) 进行重新排序,以提升质量。
- Retrieval (检索): 从一个大规模的文档语料库中找出与查询最相关的文档。这是目前文本嵌入最核心和最热门的应用之一。
- Semantic Textual Similarity (STS, 语义文本相似度): 判断两个句子的语义相似程度,通常给出一个从 0 到 5 的分数。
- Summarization (摘要): 评估生成的摘要与原文的语义相似度。
3.2 稀疏嵌入(Sparse Embedding)
| 特征 | 说明 |
|---|---|
| 维度 | 通常等于完整词表或特征集合的大小,可达 10⁵ – 10⁶;大多数维度为 0,只有少数位置有权重 |
| 构造方式 | 基于词频或词频-逆文档频率(TF-IDF)、BM25 等统计方法,不依赖深度学习 |
| 权重含义 | 每个非零维可直观解释为某个词或特征的重要度,具有高度可解释性 |
| 检索/存储 | 用倒排索引即可实现 O(1) 级精确匹配;在线增量更新代价低 |
| 优势 | 对长文档、术语精确匹配友好 易于调参(停用词、词根化) 资源消耗小、无推理延迟 |
| 劣势 | 维度极高,逐向量暴力计算代价大 只捕获词面共现,无法理解语义或同义词 对拼写/语序变化鲁棒性差 |
TF-IDF(Term Frequency - Inverse Document Frequency,词频-逆文档频率)
一种经典的加权方案,用来衡量 词语 t 对 文档 d 在 语料库 D 中的重要程度。
- 一句话:词在整个语料库中出现得越少,但在本篇文档中出现得越多,那它就越重要。
公式:\(TF-IDF(t,d,D) = TF(t,d) × IDF(t,D)\)
TF(局部权重):
- 计数:
tf = #t 出现次数 - 频率:
tf = #t / |d| - 对数平滑:
tf = 1 + log(#t)
ID(全局权重):\[IDF(t) = log\frac{N-df(t)+0.5}{df(t)+0.5} \]
- N = 语料中文档总数
- df(t) = 含词 t 的文档数
- 加 1 或 0.5 可以避免分母为 0,并抑制长尾噪声。
BM25(Best Matching 25)
可视为 TF-IDF 的扩展版,进一步引入:
- k₁ 控制 TF 饱和:TF 越大,增益递减。
- b 长度归一化:文档越长,单词 TF 权重被抑制。
公式:\[w(t,d)=IDF(t)⋅\frac{TF(k_{1} +1)}{TF+k_{1}·(1-b+b·\frac{文档长度}{平均文档长度} )} \]
| 角色 | 控制对象 | 常见区间 | 极值行为 | 直觉比喻 |
|---|---|---|---|---|
| k₁ (saturation factor) | TF 饱和曲线斜率——同一个词在同一文档中重复出现到第 n 次时,还能再加多少分 | 1.0 – 2.0 | k₁ → 0:完全不计重复词;k₁ → ∞:线性计数,退化为 TF-IDF | 沾一滴酱油 vs. 倒一瓶酱油:味道总有极限,不会永远 1 → 2 → 3 倍变浓 |
| b (length normalizer) | 文档长度惩罚强度——长文能否用“大块头”刷分 | 0.3 – 0.9 | b = 0:不考虑长度(BM15)b = 1:长度全量归一化(BM11) | 打篮球按身高加分:b=0 不管身高;b=1 按身高严格扣分;中间值折中 |
3.3 密集嵌入(Dense Embedding)
| 特征 | 说明 |
|---|---|
| 维度 | 兼顾效率与表达力,常见 128 – 1536;每一维几乎都非零。 |
| 构造方式 | 由深度模型(BERT、Sentence-BERT、OpenAI text-embedding-3-small 等)端对端学习,捕获上下文语义 |
| 权重含义 | 单维难以直观解释,但整体向量在低维空间中编码了丰富的语义相似度 |
| 检索/存储 | 需专门的 ANN(HNSW、Faiss IVF-PQ 等)索引;向量更新需重新编码 |
| 优势 | 具备语义泛化能力,能跨同义词、拼写、语序可跨语言、跨模态(图文)在 RAG/问答场景提升召回率 |
| 劣势 | 训练与推理成本高(GPU/CPU 向量化计算)结果可解释性弱 在线增量写入需再编码、重建索引 |
3.4 ColBERT
ColBERT 是一种让 BERT 用“词级小向量”做快速、精准文本检索的方法 —— 既不像传统 TF-IDF 那样粗糙,也不像跨编码器那样慢。
ColBERT = “把 BERT 的句向量拆成 token 向量,再用 Late Interaction 重新拼起来做检索”的工程化改造版 BERT。
Late Interaction 就是把查询(Q)和文档(D)先独立编码,等到最后打分时再让它们在 token 级别 做一次“小范围、轻量级”的互动——既不像 Cross-Encoder 那样“一上来就深度交互”,也不像 Bi-Encoder 那样“全程零交互”。
换言之,BERT 提供语言理解底座,ColBERT 在此之上加了面向检索的输出格式与打分逻辑,二者既同宗又分工明确。
1 | 预训练阶段(同一个 BERT 权重) |
3.5 BGE-M3
BGE-M3 是由智源研究院(BAAI)开发的新一代旗舰文本嵌入模型,它开创性地在单一模型内集成了多语言(支持超过 100 种语言)、长文本 (支持 8192 词符)和多功能检索(同时支持稠密、稀疏和多向量检索)的强大能力。
| M | 含义 | 具体能力 | 参考 |
|---|---|---|---|
| Multi-Functionality | 多功能 | 同时产出 稠密向量(dense)、多向量/ColBERT(colbert) 和 稀疏向量(sparse),一套模型即可覆盖混合检索需求。 | huggingface.bge-m3 |
| Multi-Linguality | 多语种 | 覆盖 100+ 语言,是目前公开数据集中多语检索任务的 SOTA。 | arXiv.bge-m3 |
| Multi-Granularity | 多粒度 | 最长输入 8 192 token,既能编码短句也能处理长文档。 | huggingface.bge-m3 |
4. 查询增强技术
4.1 查询构建
4.1.1 Text-to-SQL
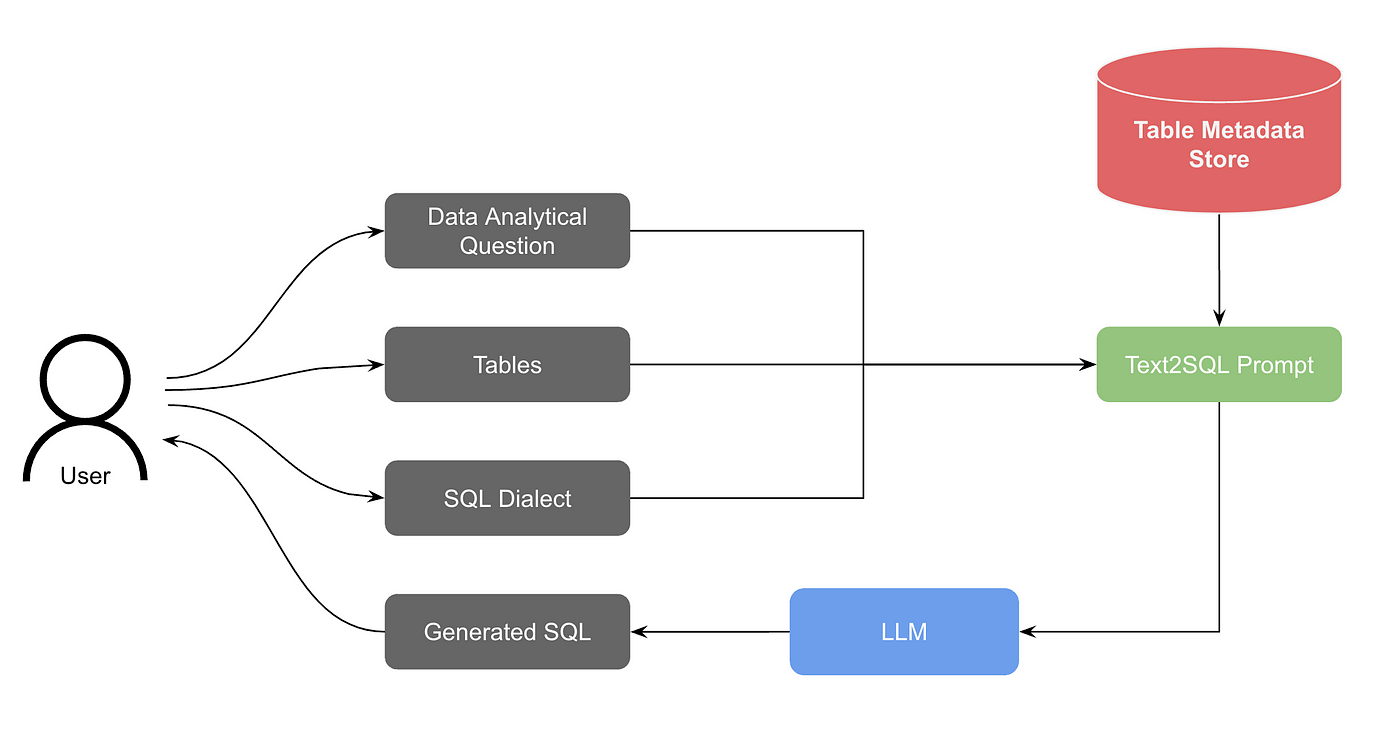
- 构建 DDL 知识库:schema 提取与切片;
- 构建 Q-SQL 知识库:示例对注入;
- 构建 DB 描述知识库:业务描述补充;
- 提供 RAG 检索上下文;
- 调用 LLM 进行 SQL 生成;
- 执行 SQL 并反馈结果;
- 迭代直到正确解决问题。
常用框架:
- vanna
- Chat2DB
- DB-GPT
4.1.2 Text-to-Cypher
跟 Text-to-SQL 一样,只不过是生成图数据库(neo4j)查询语句。
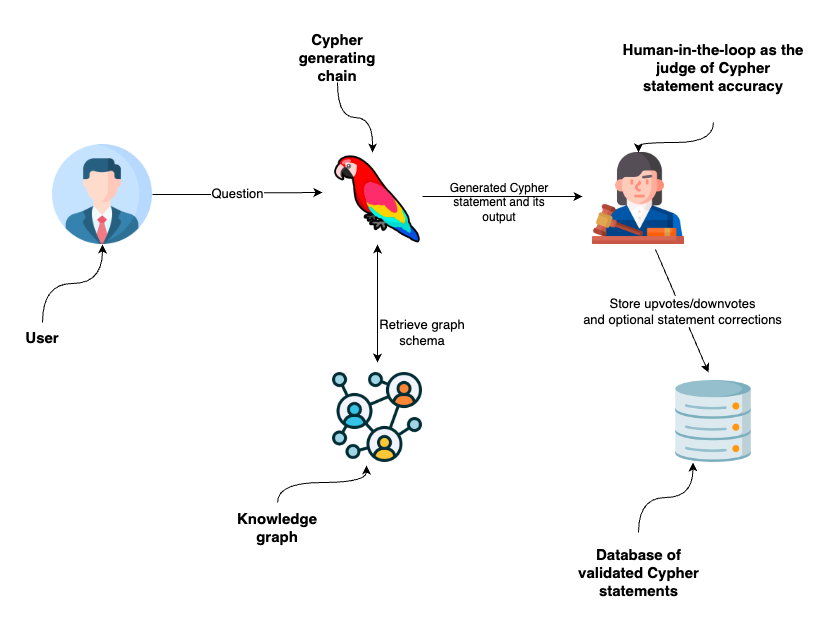
- 构建图元模型(Graph Metamodel)知识库;
- 构建 Q-Cypher 知识库(示例对注入);
- 构建图描述(Graph Description)知识库;
- 提供 RAG 检索上下文;
- 调用 LLM 进行 SQL 生成;
- 执行 SQL 并反馈结果;
- 迭代直到正确解决问题。
4.1.3 从查询中提取元数据构建过滤器
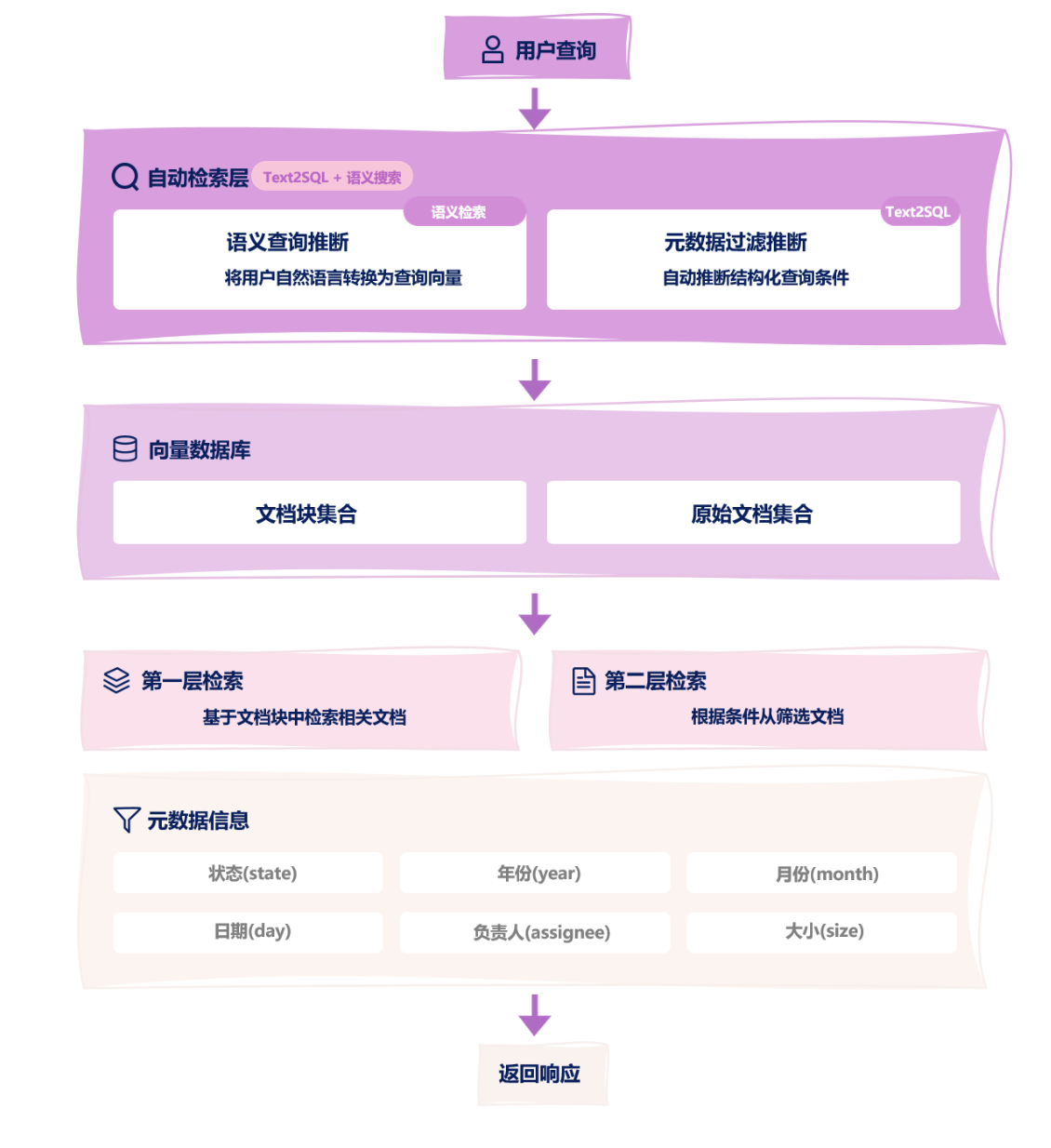
- 将自然语言转为向量查询语句;
- 利用 LLM 推断出元数据过滤条件;
- 在查询检索时,根据过滤条件进行文档过滤;
- 返回过滤后的相似文档;
实战案例:
- https://ragflow.io/blog/implementing-text2sql-with-ragflow
- https://medium.com/neo4j/generating-cypher-queries-with-chatgpt-4-on-any-graph-schema-a57d7082a7e7
4.2 查询翻译
通过对用户查询进行改造和扩展,使其更加清晰、具体,从而提高检索精度。
常用工具:
| 方案 | 链接 | 说明 |
|---|---|---|
| ragbear | GitHub - lexiforest/ragbear | rewrite= 参数多种改写模式 |
| LangChain | Query Transformations | 内置链式改写 |
| LlamaIndex | Query Transform Cookbook ¶ | 多策略组合 |
| Haystack | Advanced RAG: Automated Structured Metadata Enrichment | Haystack | pipeline node |
4.2.1 Query2Doc
Query2Doc 是指将 query 直接交给 LLM 去生成一份相关文档,然后将 query 和生成的文档一起去进行检索。虽然 LLM 生成的文档可能不对,但是提供了更丰富的信息、丰富了问题的语义,有助于提高检索时的精度。
1 | def query2doc(query): |
4.2.2 HyDE
HyDE(Hypothetical Document Embeddings,假设文档向量)让 LLM 根据 query 去生成一系列假设性文档,然后将这些文档跟 query 一起做向量化,取向量均值去进行检索。
1 | def hyde(query, include_query=True): |
4.2.3 子问题查询
当问题比较复杂时,可以利用 LLM 将问题拆解成子问题,每个子问题都生成检索上下文,可以根据合并后总的上下文回答,也可以每个上下文独立回答后汇总。
1 | def sun_question(query): |
4.2.4 查询改写
当问题表达不清、措辞差、缺少关键信息时,使用 LLM 根据用户问题多角度重写问题,增加额外的信息,提高检索质量。
1 | def question_rewrite(query): |
4.2.5 查询抽象
查询抽象(Take a Step Back)是指当问题包含太多的细节,可能导致检索时忽略了关键的信息,降低检索质量。可以将用户的具体问题转化为一个更高层次的抽象问题,一个更广泛的问题,关注于高级概念或原则,从而提高检索质量。
1 | from langchain_core.output_parsers import StrOutputParser |
4.3 查询路由
查询路由(Query Routing)是指根据用户问题的具体意图,自动判断应该将该问题导向最合适的数据源(例如向量知识库、SQL 数据库、图数据库或特定 API)以获取最精准信息的决策过程。
| 思路 | 图示 |
|---|---|
| 逻辑路由 | 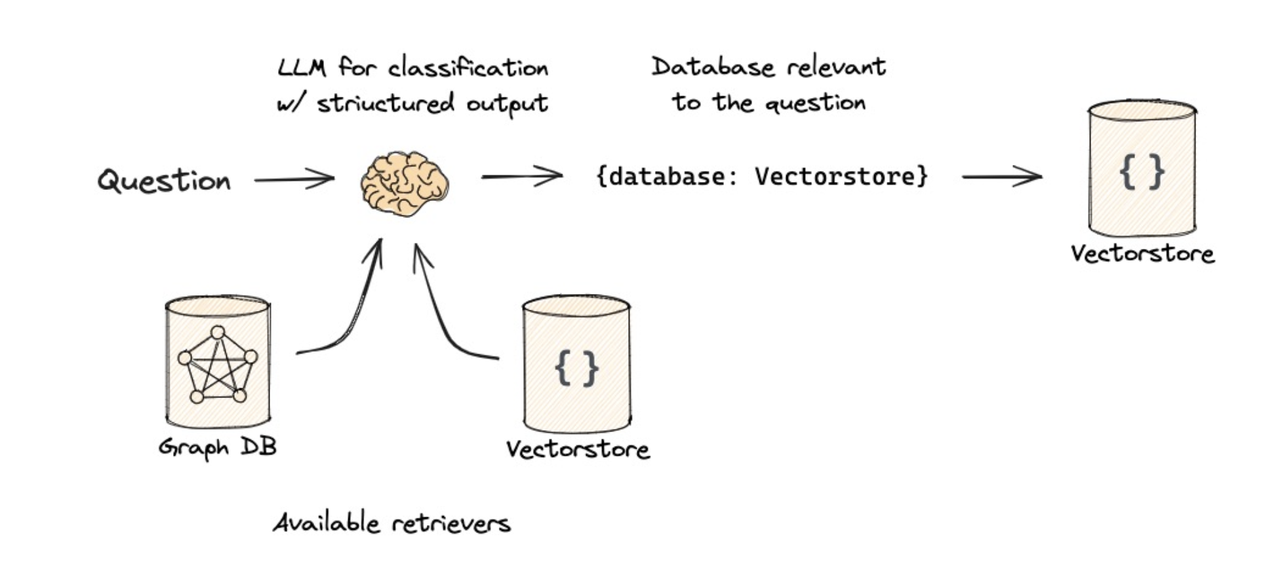 |
| 语义路由 | 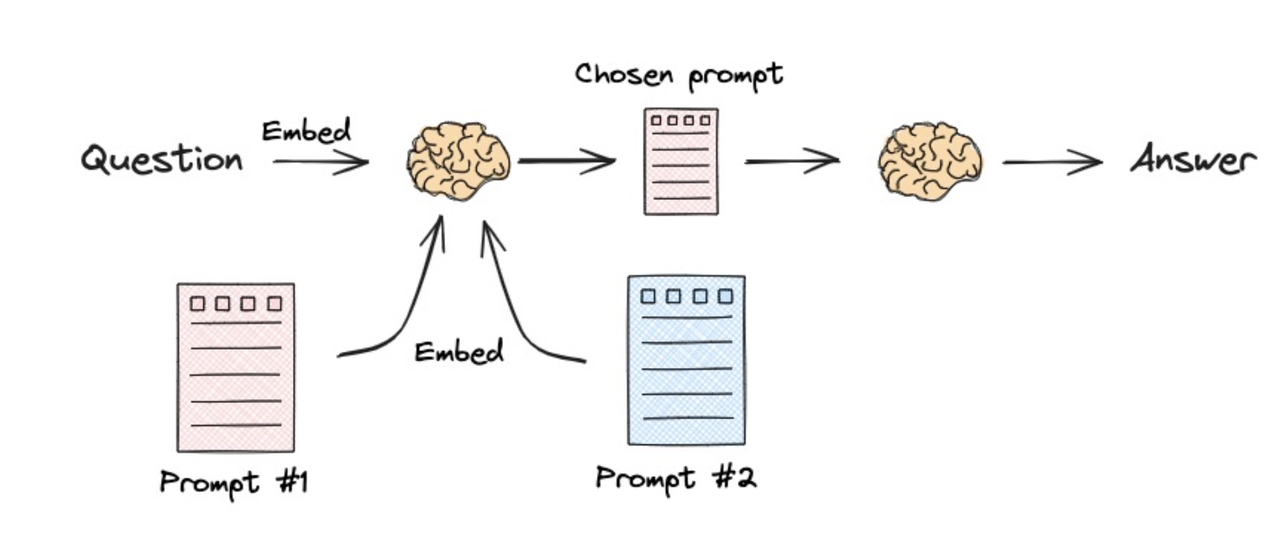 |
5. 索引优化技术
基本思路:
- 父子文档索引
- 分层索引
- 多表示索引
5.1 从小块到大上下文
向量检索的时候,检索到的是一个小文档,但是通过小文档的 metadata,返回给 LLM 的是查询出来的大文档。
节点-句子滑动窗口检索 SentenceWindowNodeParser
.png)
父子文本块检索:ParentDocumentRetriever
.png)
前后串连、自动扩展上下文:PrevNextNodePostprocessor、AutoPrevNextPostprocessor
.png)
5.2 构建有层次的索引
- 构建两个向量数据库(Summary 和 Details),通过 Metadata 进行连接;
- 通过
llamaindex的indexnode和PandasQueryEngine; - 通过查询先检索相关表名,然后做
Text2SQL。
.png)
5.3 构建多表示索引
构建混合索引:EnsembleRetriever
.png)
构建多表示索引:MultiVectorRetriever
.png)
6. 检索后优化技术
6.1 重排 rerank
传统的搜索或推荐系统通常分为两步:
- 召回(Recall): 从海量的候选集中,快速、粗略地筛选出几百或几千个可能相关的项目。此阶段追求速度和查全率,常用技术包括基于关键词的搜索(如 BM25)或向量相似度搜索(ANN)。
- 排序/重排(Ranking/Reranking): 对召回的结果进行更精细、更复杂的计算,以确定最终呈现给用户的顺序。此阶段追求精准度和查准率。我们今天讨论的技术就属于这个范畴。
可以把这个过程比作“海选”和“决赛”。召回是海选,快速淘汰掉明显不相关的选手;重排是决赛,评委(重排模型)对入围选手进行全方位的严格评审,最终给出排名。
6.1.1 RRF 重排
民主投票式的融合
RRF 是一种简单、高效、无需训练的“结果融合”策略。想象一下,你有多个独立的搜索系统(比如一个关键词搜索,一个向量搜索),它们各自对同一批文档给出了自己的排名。RRF 的作用就是将这些不同的排名列表“民主地”融合成一个最终的、可能更优的排名列表。
RRF 的核心思想是:一个文档在多个列表中的排名越靠前,它在最终列表中的排名就应该越靠前。
与简单地将不同系统的得分相加不同,RRF 采用“倒数排名”(Reciprocal Rank)来计算每个文档的最终分数。
.png)
优势:
- 无需训练: 即插即用,非常方便。
- 性能稳健:
在不同召回源质量参差不齐时,表现通常比简单的分数相加(如
sum fusion)更稳定。 - 计算开销极低: 几乎不增加额外的计算负担。
缺点:
- 效果上限不高: 它只利用了“排名”这一个信息,忽略了不同系统给出的原始“分数”中蕴含的置信度信息。
- 依赖召回质量: 如果所有召回源的质量都很差,RRF 也无力回天。
适应场景:
- 混合搜索(Hybrid Search):融合关键词搜索(BM25)和向量搜索的结果。
- 多模态搜索:融合文本、图片等不同模态的搜索结果。
6.1.2 Cross-Encoder 重排
query 和文档的"深度阅读理解"
如果说召回阶段的向量搜索是"看标题识文章",那么 Cross-Encoder 重排就是"把 query 和每篇文档放在一起,逐字逐句地做一篇完整的阅读理解"。
它通过深度学习模型(通常是 Transformer 架构,如 BERT)来判断一个 query 和一个文档之间的相关性到底有多强。
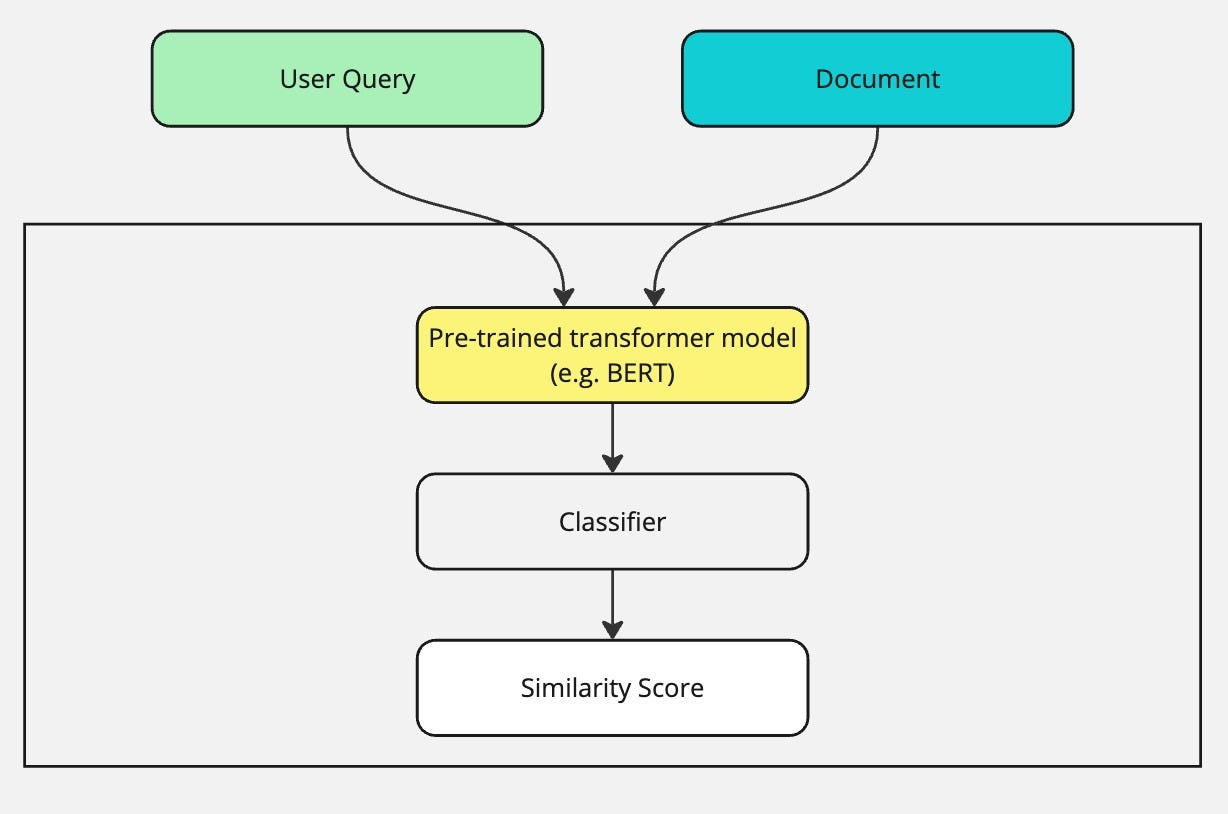
基本流程:
- 输入构建:
将查询(Query)和待排序的文档(Document)用一个特殊的分隔符(如
[SEP])拼接在一起,形成一个单一的输入序列。例如:[CLS] 我的问题是什么?[SEP] 这是候选文档的内容... [SEP] - 模型计算: 将这个拼接后的序列输入到一个预训练好的 Transformer 模型(如 BERT)中。模型内部的自注意力机制(Self-Attention)会让 Query 中的每个词和 Document 中的每个词都进行充分的交互和信息比对。
- 分数输出:
模型在处理完整个序列后,通常会利用起始位置
[CLS]Token 对应的输出向量,接一个简单的线性层,最终输出一个单一的分数(logit),这个分数就代表了 Query 和 Document 之间的相关性得分。 - 排序: 根据所有文档得到的相关性得分,从高到低进行排序,得到最终结果。
优点:
- 效果极佳: 由于对 query 和文档进行了深度的、非对称的交互分析,其精度通常是所有重排方法中最高的。
缺点:
- 计算成本极高: 对于每个
(query, document)对,都需要进行一次完整的、重量级的模型前向传播。如果召回了 500 个文档,就需要进行 500 次 BERT 模型的计算,这在实时性要求高的场景下是巨大的挑战。 - 无法提前索引: 文档的表示不是独立的,必须在查询时与 query 结合才能计算,因此无法像向量搜索那样提前为所有文档建立索引。
适用场景:
- 对精度要求极高,且可以容忍较高延迟的场景,如某些法律或医疗文献的精确查找。
- 作为“黄金标准”来生成高质量的标注数据,用于训练更轻量的召回模型(如 Bi-Encoder)。
6.1.3 ColBERT 重排
Contextualized Late Interaction over BERT。
介于“看标题”和“深度阅读”之间的“划重点式”阅读
ColBERT 试图在 Cross-Encoder 的高精度和 Bi-Encoder (召回阶段常用) 的高效率之间找到一个平衡点。它的核心思想是:不需要逐字逐句地进行完整对比,而是先把 query 和文档各自的"重点"(关键词向量)划出来,然后再计算这些重点之间的匹配程度。
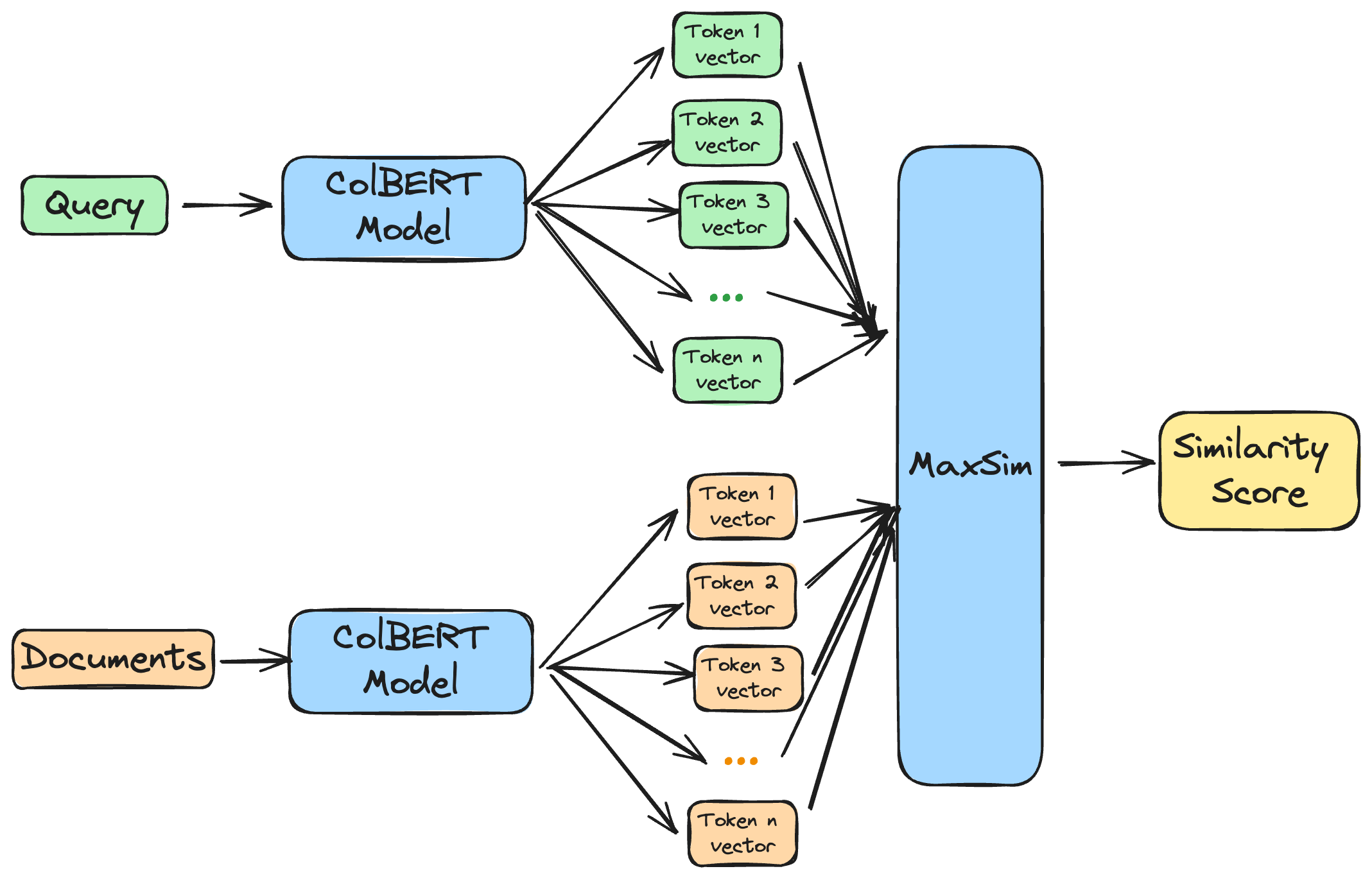
基本流程:
- 独立编码: 首先,使用一个 BERT
类的模型(但稍作修改)分别独立地处理 Query 和
Document。它不再是输出一个单一的
[CLS]向量,而是为 Query 和 Document 中的每一个 Token 都生成一个上下文相关的向量。 - Query 端向量: 对于 Query,我们保留所有 Token 的输出向量。
- Document 端向量: 对于 Document,我们也保留所有 Token 的输出向量。这些向量可以提前计算并存储,这是它比 Cross-Encoder 高效的关键。
- 延迟交互计算:
在查询时,进行“延迟交互”。具体来说,对于 Query
中的每一个 Token 向量,我们都去 Document 的所有 Token
向量中寻找一个最相似的(通过最大内积
MaxSim操作)。 - 分数聚合: 最后,将 Query 中每个 Token 找到的最大相似度分数相加,得到最终的相关性总分。
这个过程好比:
- Query: "best deep learning framework"
- Document: "PyTorch is a popular framework for deep learning..."
ColBERT 会分别计算:
- "best" 和文档中所有词向量的最大相似度。
- "deep" 和文档中所有词向量的最大相似度。
- "learning" 和文档中所有词向量的最大相似度。
- "framework" 和文档中所有词向量的最大相似度。
- 然后把这四个最大相似度值加起来作为总分。
优点:
- 性能优越: 精度远超传统的 Bi-Encoder,并且在很多任务上能逼近 Cross-Encoder。
- 效率较高: 由于文档向量可以预计算和索引,查询时的计算开销远低于 Cross-Encoder,只涉及向量的相似度计算。
缺点:
- 存储开销大: 需要为文档中的每个 Token 都存储一个高维向量,存储成本远高于只存一个文档向量的 Bi-Encoder。
- 实现相对复杂: 其索引和查询逻辑比标准向量搜索更复杂。
适用场景:
- 需要高精度但又对延迟有一定要求的现代搜索引擎,如微软的 Bing 就在使用类似的技术。
- 作为 RAG 系统中的高质量重排器。
6.1.4 Cohere 和 Jina 重排
商业化的"重排即服务"(Reranking-as-a-Service)
Cohere 和 Jina AI 都是提供 AI 模型和服务的公司。它们都将高质量的重排模型封装成了简单易用的 API 服务。本质上,它们提供的重排器很可能就是基于类似 Cross-Encoder 架构的、在海量高质量数据上训练和优化的专有模型。
优点:
- 使用简单: 只需几行代码调用 API 即可,无需关心模型训练、部署和维护。
- 效果保证: 通常能获得非常好的开箱即用效果,因为这些模型经过了大量数据的锤炼。
缺点:
- 成本: 按调用量或 token 数量计费,对于大流量应用可能是一笔不小的开销。
- 数据隐私: 需要将你的 query 和文档数据发送给第三方服务商,对于数据敏感的应用需要仔细评估其隐私政策。
- 灵活性受限: 无法像自建模型那样进行深度定制或调优。
适用场景:
- 快速原型验证(MVP)。
- 中小型企业或开发者,希望以最小的工程代价获得最好的排序质量。
- 大型企业中非核心但又需要高质量排序的业务场景。
6.1.5 RankGPT 和 RankLLM
这是最新的重排范式,直接利用 LLM 强大的语言理解和推理能力来进行排序。它的思路是:不再让模型输出一个简单的相关性分数,而是让 LLM 直接对召回的文档列表进行"思考"和"比较",然后输出一个排序好的列表。
基本思路:
- 构建 Prompt: 将 query 和召回的文档列表(通常是文档的标题和摘要)格式化成一个复杂的 Prompt。这个 Prompt 会明确指示 LLM 作为一个排序专家,对给定的文档列表根据与 query 的相关性进行排序,并按指定的格式输出结果。
- LLM 推理: 将这个 Prompt 发送给 LLM。LLM 会利用其强大的上下文理解能力,分析 query 的深层意图,并比较不同文档之间的细微差别(例如,一个内容更全面,另一个更新颖)。
- 解析输出: LLM 会返回一个文本结果,比如一个重新排序好的文档 ID 列表。程序需要解析这个文本输出来获取最终的排序。
优点:
- 理解复杂意图: LLM 能够理解非常复杂和模糊的 query,并能进行一定程度的推理,这是传统模型难以做到的。
- 零样本/少样本能力强: 无需针对特定任务进行微调,就能在很多场景下取得惊人的效果。
- 可解释性: 有时可以引导 LLM 给出排序的理由,增加了透明度。
缺点:
- 成本和延迟极高: 调用大型 LLM API 的成本和时间开销是目前所有方法中最高的,通常只能用于非实时或小批量任务。
- 上下文长度限制: LLM 的上下文窗口大小有限,一次能处理的文档数量和文档长度都受限。
- 稳定性问题: 输出格式可能不稳定,需要设计鲁棒的解析逻辑。结果也可能有一定的随机性。
适用场景:
- 对召回结果的“最后一公里”进行精加工,例如对前 10 名结果进行最终排序。
- 作为生成高质量排序标注数据的强大工具。
- 对成本不敏感、但对排序质量有极致要求的特定应用。
6.1.6 时效加权重排
这是一种业务逻辑驱动的重排策略,而非特定的模型或算法。其核心思想是:对于某些类型的查询,最新的信息比旧的信息更有价值。
基本思路:
- 时间衰减函数 (Time Decay Function): 设计一个函数,使得文档的分数随着其发布时间的流逝而衰减。最常用的函数是指数衰减或高斯衰减。
- 分桶加权: 将文档按发布时间分到不同的桶里,如"24 小时内"、"一周内"、"一月内"、"更早"。为每个桶设置一个固定的权重或加分项。例如,"24 小时内"的文档分数乘以 1.5,"一周内"的乘以 1.2 等。
优点:
- 实现简单: 逻辑清晰,容易实现和调整。
- 效果显著: 对于新闻、社交媒体、产品更新等时效性强的查询,能极大提升用户体验。
缺点:
- "一刀切"风险: 如果不加区分地对所有查询都增强时效性,可能会伤害那些寻求""永恒"知识的查询(如"什么是牛顿第一定律")。
- 参数难调: 衰减函数的形状、权重 w 等参数需要根据经验和 A/B 测试来仔细调整。
适用场景:
- 新闻搜索: 用户总是想看最新的报道。
- 电商新品: 用户搜索"手机"时,可能更想看到最新款。
- 社交媒体 Feed: 最新的帖子通常排在最前面。
- 需要与查询意图识别结合: 一个优秀的系统应该能识别出哪些 query 是具有时效性意图的,然后动态地应用时效性加权。
6.2 压缩 compression
传统的 RAG 流程是“检索-增强-生成”。系统首先根据用户问题从知识库中检索出若干相关文档片段(Chunks),然后将这些片段作为上下文(Context)连同用户问题一起提交给大语言模型(LLM),由 LLM 生成最终答案。
这里面潜藏着几个挑战:
- 上下文窗口限制 (Context Window Limit):每个 LLM 都有其上下文长度上限(如 GPT-4 是 128k tokens)。如果检索出的文档过多,会超出窗口限制,导致无法处理。
- 成本与延迟 (Cost & Latency):LLM 的 API 调用费用通常与输入的 Token 数量成正比。上下文越长,费用越高,同时模型的推理时间也越长,导致用户等待时间增加。
- “大海捞针”问题 (Lost in the Middle):研究表明,当 LLM 的上下文中包含大量信息时,它对位于上下文中间部分信息的注意力会下降。如果关键信息被大量无关或次要信息包围,LLM 可能无法有效利用它,从而影响生成答案的准确性。
- 噪声干扰 (Noise Interference):检索出的文档片段虽然“相关”,但并非每个字、每句话都对回答当前问题至关重要。这些无关信息就是“噪声”,会干扰 LLM 的判断。
因此,RAG 压缩技术的核心目标,就是在将检索到的信息送入 LLM 之前,对其进行“精炼”——去除无关信息、保留核心内容,从而在降低成本、提升效率的同时,提高最终答案的质量。
6.2.1 上下文压缩检索器
上下文压缩检索器是指 LangChain 提供的
Contextual Compression Retriever。
它不是一个独立的检索器,而是一个"包装器"(Wrapper)。它首先使用一个常规的检索器(如
VectorStoreRetriever)获取一批文档,然后通过一个嵌入的"文档压缩器"(Document
Compressor)对这些文档进行筛选或重写,最后只返回那些真正重要的信息。
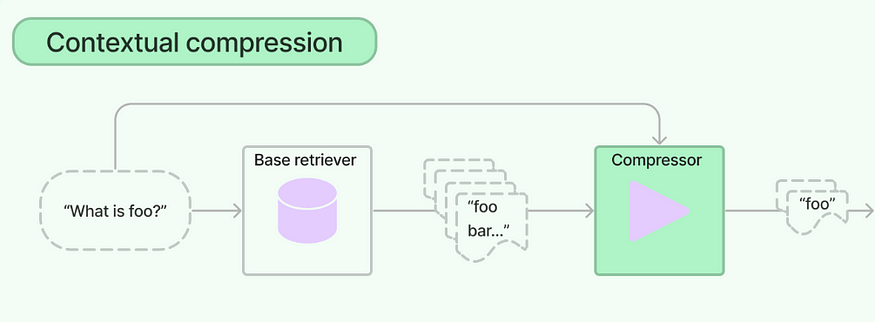
LangChain 提供了两种主流的压缩器:
LLMChainExtractor:这个压缩器内部会运行一个 LLM(通常是一个小模型)。它会遍历每个检索到的文档,并向 LLM 提出一个问题,例如:"请从以下文档中抽取出与'[用户原始问题]'相关的句子。" LLM 会根据指令抽取出关键句子,丢弃无关部分,从而实现压缩。这是一种基于 LLM 的抽取式压缩EmbeddingsFilter:这个压缩器不依赖 LLM。它会计算用户问题和每个检索文档(或文档内更小的句子片段)的嵌入向量(Embedding)之间的相似度。只有当相似度超过预设的阈值(e.g.,similarity_threshold=0.8)时,该文档或句子才会被保留。这是一种基于嵌入相似度的过滤式压缩。
优势:
- 提升信噪比:直接过滤掉与问题无关的整个文档或文档中的无关部分。
- 灵活性高:可以根据需求选择计算成本低但效果略粗糙的
EmbeddingsFilter,或选择成本高但更智能的LLMChainExtractor。 - 模块化:与 LangChain 生态无缝集成,易于实现。
6.2.2 句子嵌入优化器
句子嵌入优化器是指 LlamaIndex 提供的
Sentence Embedding Optimizer。
与 LangChain 的 EmbeddingsFilter 思想非常相似,但它在
LlamaIndex 的生态系统内,并专注于句子级别的精细化过滤。
在检索到相关的文档块(Node)之后,不是将整个文档块都丢给 LLM,而是深入到文档块内部,逐一分析每个句子,只保留与用户问题最相关的句子。
基本原理:
- 初始节点检索:查询引擎首先从索引中检索出 Top-K 个最相关的节点(Nodes,相当于 LangChain 的 Documents)。
- 句子级分析:
SentenceEmbeddingOptimizer(或类似功能的SimilarityPostprocessor)接收这些节点。它会:- 将每个节点分解成单独的句子。
- 为每个句子计算一个嵌入向量。
- 计算每个句子的嵌入向量与用户原始问题嵌入向量之间的相似度得分。
- 阈值过滤:它会根据一个预设的相似度阈值(
similarity_cutoff)来决定保留哪些句子。只有得分高于阈值的句子才会被保留下来,组合成新的、更精简的节点内容。 - 合成响应:最后,只有这些经过精炼的、包含高相关度句子的节点才会被送入响应合成器(Response Synthesizer),由 LLM 生成最终答案。
优势:
- 粒度极细:相比于过滤整个文档,句子级过滤能最大程度地保留一个文档块中的相关信息,同时剔除无关句子,精度更高。
- 减少上下文割裂:有时一个文档块整体相关度可能不高,但其中有一两句关键信息。这种方法可以精准地把这两句"捞"出来,避免整个文档块被丢弃。
6.2.3 LLMLingua
在将包含检索文档的冗长提示词(Prompt)发送给昂贵的大模型(如 GPT-4)之前,先用一个更小、更便宜的语言模型(如 GPT-2 或一个微调过的 Llama)来对这个提示词进行"有损压缩"。这个压缩过程会识别并删除那些对 LLM 理解问题和生成答案不太重要的词语或句子。
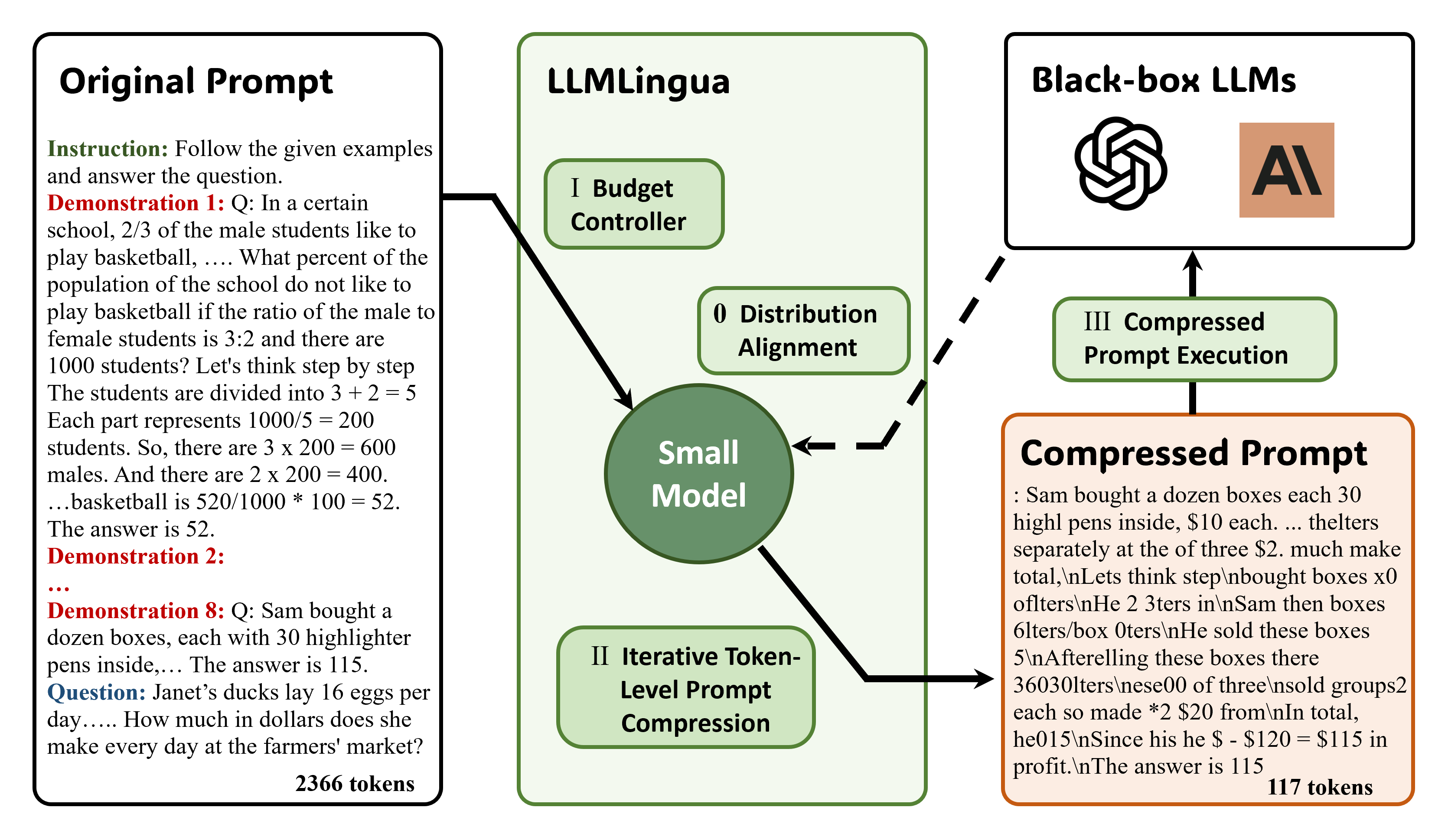
基本原理:
- 构建完整提示词:将用户问题和所有检索到的文档拼接成一个完整的、非常长的提示词。
- 小模型介入:LLMLingua 使用一个小模型来分析这个长提示词。它会评估如果从提示词中删除某个词或某段话,对大模型理解原始提示词的“困惑度”会产生多大影响。
- 智能删除:它会优先删除那些对困惑度影响最小的词语和句子,因为这些内容被认为是信息量较低或冗余的。这个过程被设计得非常精巧,旨在保留关键的实体、术语和逻辑关系。
- 生成压缩提示词:经过这个过程,原始的长提示词被压缩成一个更短的版本,其中包含了原始上下文的"精华"。
- 提交大模型:最后,这个压缩后的、短小精悍的提示词被发送给目标大模型进行处理。
6.2.4 RECOMP 压缩
RECOMP (REtrieval-and-COMPression) 是一种面向复杂问题的、多步骤的 RAG 策略,它将压缩思想融入到了一个更宏大的框架中。
当面对一个需要综合多个信息源才能回答的复杂问题时,传统的 RAG 一次性检索出的文档可能包含大量不相关细节。RECOMP 通过"分而治之"和"先抽取再合成"的方式来创建高度浓缩和相关的上下文。
基本原理:
- 问题分解(可选):对于一个非常复杂的问题,可能首先会将其分解为几个更简单的子问题。
- 检索与抽取 (Retrieve and
Extract):针对(每个子)问题,执行以下操作:
- 检索:从知识库中检索相关文档。
- 抽取:这是关键步骤。它不是直接使用这些文档,而是向 LLM 发出指令,要求 LLM 阅读每个文档,并从中抽取出与当前(子)问题直接相关的简明摘要或关键事实点。例如:"请阅读以下关于 A 公司的财报,并抽取出其 2023 年第四季度的收入和利润数字。"
- 压缩与合成 (Compress and Synthesize):
- 将从所有文档中抽取出的摘要或事实点收集起来。
- 再次调用 LLM,将这些零散但高度相关的信息点合成成一段连贯、流畅、无冗余的文本。这段文本就是最终为原始复杂问题量身定制的“完美上下文”。
- 最终生成:将这个合成好的、高度浓缩的上下文连同原始问题一起提交给 LLM,生成最终答案。
优势:
- 极高的信息密度:最终生成的上下文几乎不含任何与问题无关的噪声,每一句话都是为了回答问题而存在的。
- 处理复杂问题的能力强:非常适合需要整合来自不同文档、不同主题信息的“多跳(multi-hop)”问题。
- 可解释性:由于中间步骤生成了摘要和事实点,这个过程比黑盒方法更易于调试和理解。
6.2.5 Prompt Caching 记忆上下文
它是一种性能优化技术,而非内容压缩技术,但常在处理长上下文时被提及。
在 Transformer 模型(所有现代 LLM 的基础)中,当模型处理一个序列时,它会为每个 Token 计算一个键(Key)和值(Value)向量,这个计算过程非常耗时。Prompt Caching(或称 KV Cache)技术的核心就是:将已经处理过的 Prompt 部分的 KV 向量缓存起来,下次请求时如果 Prompt 前缀相同,则直接复用缓存,无需重新计算。
基本原理:
- 首次请求:用户发送一个长 Prompt(例如,一篇需要总结的文章)。模型在处理这个长 Prompt 时,会计算其中每个 Token 的 KV 向量,并将它们存储在 GPU 的内存中(即 KV Cache)。
- 后续交互:现在,用户基于这篇文章提问(例如,“文章的作者是谁?”)。这个新的请求实际上是
[原始长Prompt] + [新问题]。 - 缓存命中:当模型收到这个新请求时,它会发现请求的前半部分(
[原始长Prompt])与上一次完全相同。它会立即从 KV Cache 中加载这部分的 KV 向量,而只需为新的部分([新问题])计算 KV 向量。 - 加速生成:这样一来,模型省去了重复计算长 Prompt 部分的巨大开销,从而极大地加快了对新问题的响应速度。
优势:
- 大幅提升多轮对话或连续查询的性能:对于聊天机器人、文档问答等需要保持长上下文的场景,效果极其显著。
- 降低总计算成本:虽然不减少送入的 Token 数,但通过复用计算结果,降低了处理相同前缀的实际计算成本和时间。
6.3 校正 correction
C-RAG 的核心思想是在检索模块和生成模块之间,引入一个轻量级的“检索评估器” (Retrieval Evaluator),并根据评估结果采取不同的校正措施。这项技术主要在学术论文 arXiv:2401.15884 中被系统性地提出和阐述。
.png)
C-RAG 的精髓在于其动态的、差异化的处理策略。
- 当评估为“不正确”时:C-RAG 会果断地抛弃所有从内部知识库检索到的文档。因为它判断这些文档只会误导 LLM。取而代之,它会重写 (Rewrite) 用户的查询,使其更适合通用搜索引擎,然后触发网络搜索 (Web Search),从更广阔的、实时更新的互联网中获取信息。这极大地扩展了 RAG 系统的知识边界,尤其适用于回答关于近期事件或内部知识库未覆盖领域的问题。
- 当评估为“正确”时:即便文档是相关的,也可能包含大量与问题无关的“噪音”段落。为了让
LLM 更专注于核心信息,C-RAG 采用了一种“分解-再重组”
(Decompose-then-Recompose)*的知识精炼算法。
- 分解 (Decompose):将相关的文档分解成更小的、独立的知识片段 (Knowledge Strips)。
- 重组 (Recompose):再次使用评估器对每个知识片段进行打分,过滤掉无关的片段,只保留最核心、最相关的知识点,然后将这些精华片段“重组”起来,作为最终的上下文。
- 当评估为“模糊”时:C-RAG 会采取一种混合策略。它会同时对内部检索到的模糊文档进行上述的“分解-再重组”精炼,并启动网络搜索获取外部信息。最后,将两方面的信息合并,为 LLM 提供一个更全面、更鲁棒的上下文。
实战案例:LangGraph-CRAG
7. 响应生成
8. 系统性优化
系统性优化指的是从系统层面上,通过优化整个 RAG 流程来达到一个更好的检索效果。
8.1 自我修正与反思型 RAG
- 业界标杆:self-rag
- 笔者实践:self-rag.py
此架构模拟了人类“先思考、再审视、后修正”的决策过程。系统首先生成一个初步答案,然后启动一个内部的"批评家"来评估这个答案的质量。如果发现问题(如信息不完整、逻辑不通顺),系统会生成修正指令,并基于新指令进行迭代优化,直到产出高质量的最终答案。
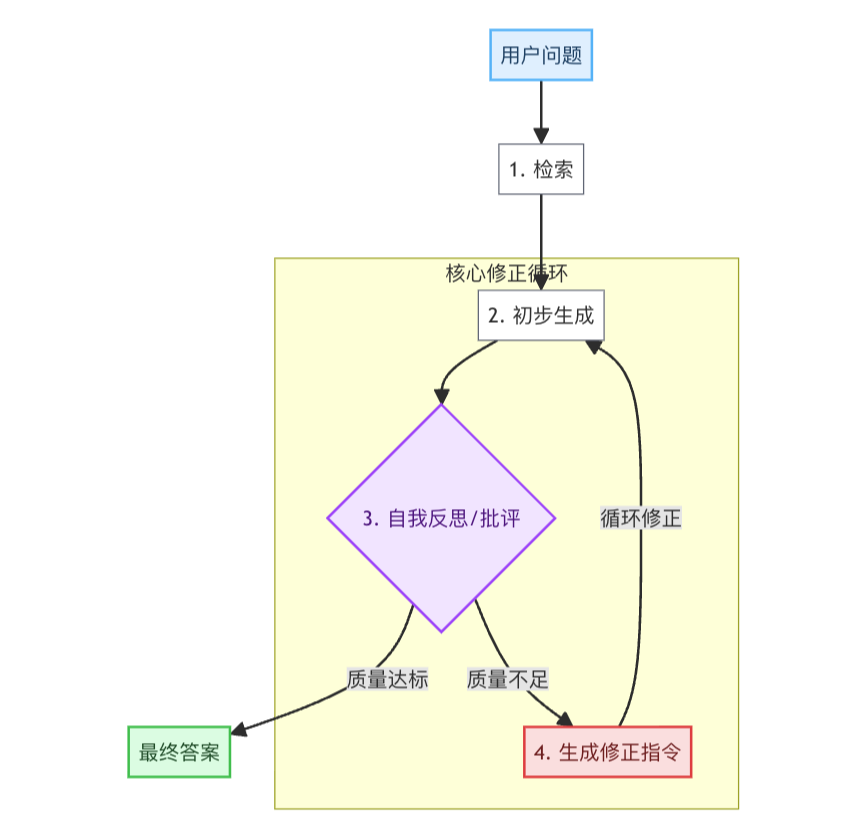
8.2 迭代式检索 RAG
此架构专门应对信息不足的问题。当一次检索无法获取回答复杂问题所需的全部信息时,系统会进入一个迭代循环。它会分析已获取的内容,智能地生成新的、更深入的查询,然后再次进行检索。这个过程不断重复,直到收集到足够全面的上下文,最后再进行综合生成。
.png)
8.3 自适应/智能体 RAG
此架构将 RAG 提升到了一个智能体 (Agent)的高度。系统核心是一个作为大脑的 LLM,它能自主分析用户问题,并决策采取何种行动:是进行知识库检索、上网搜索、调用计算器,还是直接回答。它能制定多步计划并调用不同工具,展现出更高的灵活性和解决复杂问题的能力。
.png)
9. 评估
- 实践案例:eval.ipynb
9.1 三大标准
- Context Relevance:系统检索到的上下文是否紧密围绕用户的问题展开,是否包含了解答问题所需的关键信息。
- Faithfulness:生成的答案与给定的上下文之间的事实一致性。
- Answer Relevance:关注答案是否直接回答了问题,还关注答案是否完整、是否包含冗余信息。

9.2 三大步骤

9.3 Ragas
Ragas 评估指标:
- Faithfulness: 生成的答案与给定的上下文之间的事实一致性。
- Answer relevancy: 关注答案是否直接回答了问题,还关注答案是否完整、是否包含冗余信息。
- Context Precision: 衡量检索上下文的信噪比。
- Context Recall: 判断是否能检索到回答问题所需的全部相关信息。
优点:
优点:
- 轻量易用。
- 指标专业性:专为 RAG 设计四大核心指标:上下文相关性(Context Relevance)、上下文召回率(Context Recall)、答案忠实度(Faithfulness)、答案相关性(Answer Relevance)。
- 无参考标签评估:不依赖参考答案即可完成评估,降低标注成本。
缺点:
- 结果可解释性弱:仅输出分数,不提供得分原因。
- 本地化支持不足:主要优化英文场景,对中文等语言支持有限。
- 功能扩展性弱:不支持自定义指标,灵活性较。
代码示例:
1. 构建数据集
1 | from datasets import Dataset |
2. 定义评估指标
1 | from ragas.metrics import( |
3. 执行评估
1 | from ragas import evaluate |
4. 评估结果
.png)
9.4 TruLens
提供一个交互式的仪表板(Dashboard),用于可视化评估结果、比较不同版本的实验并追踪性能变化。它不仅支持 LangChain 和 LlamaIndex 等主流框架,还支持对完全自定义的 RAG 应用进行封装和评估。
典型流程:
- 定义反馈函数(如
Groundedness,AnswerRelevance,ContextRelevance); - 然后用
TruApp包装 RAG 应用; - 再一个
with上下文管理器中运行查询; run_dashboard启动仪表盘查看结果。
优点:
- 全链路追踪:记录 RAG 全流程(检索、上下文、生成),支持根本原因分析,精准定位故障点(如检索错误或生成偏差)。
- 可视化与集成:内置 Web 仪表盘,实时展示评估结果;深度集成 LangChain 和 LlamaIndex。
- 反馈函数组合:支持自定义反馈函数(如毒性检测、语言匹配),灵活适配业务需求。
缺点:
- 指标覆盖面窄:核心仅三大指标(上下文相关性、答案忠实度、答案相关性),缺乏上下文召回率等关键维度。
- 依赖人工标注:答案正确性等指标需参考答案(Ground Truth),增加标注成本。
- 调试门槛高:全链路追踪需额外配置,对新手不够友好。
代码示例:
1 | from trulens_eval import TruApp, Feedback, OpenAI, Select |
9.5 DeepEval
将自身定位为 LLM 应用的"单元测试"框架,理念非常现代化。提供超过 14 种评估指标,不仅覆盖 RAG,还包括微调等场景。其一大亮点是指标具有自我解释能力,即在给出分数的同时,会提供具体的理由来解释为何得分不高,极大地便利了调试过程。此外,它与流行的测试框架 Pytest 深度集成,可以无缝地融入 CI/CD 流程。
优点:
- 工程化与自动化:原生支持 pytest,可集成 CI/CD 流水线,实现自动化测试与报告生成。
- 指标丰富且可定制:内置 30+ 指标(如忠实度、毒性、偏见检测),支持 DAG 自定义指标(决策树结构)满足复杂逻辑。独创上下文召回率计算(基于关键陈述覆盖比例)。
- 结果可解释性强:提供分数原因及改进建议,支持与 RAGAS 结果联动分析
缺点:
- 部分指标非 RAG 专属:如摘要质量、知识保留等指标更通用,需筛选适用场景。
- 依赖评估模型:默认使用 OpenAI 模型,替换自定义模型需额外开发。
- 配置复杂:DAG 指标需设计节点逻辑(任务节点、裁决节点等),学习曲线陡峭。
示例代码:
1 | import deepeval |
结合单元测试:
1 | import pytest |
输出示例:
1 | --- TestCase 1 --- |
10. Graph RAG
10.1 图数据库
10.1.1 neo4j
neo4j 使用的是语言是 cypher。Cypher
的核心是 MATCH(模式匹配) +
RETURN(结果返回),辅以
CREATE/MERGE(数据操作)、WHERE(过滤)、WITH(管道传递)。
1. 节点与关系语法
- 节点:用圆括号
()表示,可包含变量、标签和属性。():匿名节点(p:Person):变量p+ 标签Person(p:Person {name: 'Alice', age: 30}):带属性的节点。
- 关系:用方括号
[]表示,放在两个短横线中间(--),方向用箭头(→或←)指定。-[:KNOWS]-:无变量、类型为KNOWS的无向关系-[r:ACTED_IN {roles: ['Neo']}]-→:变量r+ 类型ACTED_IN+ 属性
2. 模式匹配(MATCH)
核心是通过路径模式描述图结构:
1 | MATCH (p:Person)-[r:ACTED_IN]->(m:Movie {title: 'The Matrix'}) |
- 可选匹配:
OPTIONAL MATCH处理可能不存在的关系。
3. 数据操作语句
创建:
CREATE (p:Person {name: 'Alice'}):创建节点。CREATE (a)-[:FRIEND]->(b):创建关系(需先匹配a,b)
更新:
SET修改属性1
MATCH (p:Person) SET p.age = 31
合并:
MERGE存在则匹配,不存在则创建1
2MERGE (p:Person {name: 'Alice'})
ON CREATE SET p.created_at = timestamp()删除:
DELETE n:删除节点(需先断开关系)DETACH DELETE n:删除节点及关联关系
4. 查询控制条件
过滤:
WHERE条件筛选1
MATCH (p:Person) WHERE p.age > 30 OR p.name STARTS WITH 'A'
返回:
RETURN指定输出连接查询:
WITH传递中间结果1
2
3
4MATCH (p)-[:FRIEND]->(f)
WITH p, count(f) AS friendCount
WHERE friendCount > 10
RETURN p.name聚合与排序:
COUNT(),COLLECT():聚合函数ORDER BY p.age DESC LIMIT 10:排序和分页
5. 索引与约束
索引:加速节点查找
1
CREATE INDEX FOR (p:Person) ON (p.name)
约束:确保数据唯一性
1
CREATE CONSTRAINT ON (m:Movie) ASSERT m.title IS UNIQUE
10.1.2 nebula graph
nebula graph 使用的语言是 nGQL。
10.2 典型流程
- 将问题提交给 LLM,让其提取(总结)关键词;
- 通过关键词来地毯式查询节点,尝试命中图数据库中定义的节点;
- 如果有命中的,则通过节点来查询关联的关系和节点信息;
- 将查询到的信息组织上上下文提交给 LLM,解答最初的问题。
10.3 实战案例
11. ReAct RAG
ReAct = Reasoning + Acting = 推理 + 行动
- 核心理念:让大型语言模型像人一样,在解决复杂问题时,能够先思考分析(推理),然后根据思考结果采取行动(行动),再观察行动结果,接着进行新一轮的思考,如此循环,直到问题解决。
- 核心流程:
- 思考(Thought)
- 行动(Action)
- 观察(Observation)
- 思考(Thought)
- ...
- 最终答案(Final Answer)
11.1 Prompt
1. 明确的规则制定(Rule Formulation)
- 循环结构:强制模型遵循 "Thought -> Action -> Observation" 的循环。
- 输出格式:严格规定每一个环节的输出格式,便于程序解析。
- 终止条件:明确告诉模型何时任务算完成,以及如何提交最终答
2. 精确的工具授权(Tool Granting)
- 功能单一:每个工具最好只做一件事,这让模型更容易选择。
- 描述清晰:工具的描述 (description) 是模型决定使用哪个工具的唯一依据。描述要用自然语言写得清晰、准确,说明白“这个工具能干什么”。
- 参数明确:工具的输入参数 (parameters) 必须定义清楚,包括名称、类型和用途。
- 有了 MCP 后,这一步可以用 MCP 来替代。
3. 高质量的示例引导(Example Guidance)
- 展示思维链:清晰地展示从问题到第一个思考,再到行动的逻辑。
- 覆盖典型场景:展示如何使用不同的工具,甚至是如何组合使用工具。
- 处理异常情况:最好能包含一个处理错误的示例 (比如搜索不到结果时该怎么办),这能极大地提升模型的鲁棒性。
Prompt 示例骨架:
1 | You are an expert assistant capable of solving complex problems by breaking them down into a sequence of thought and action. You must strictly follow the format of "Thought, Action, Observation" to solve the problem. |
Few Shot 示例:
1 | Question: 苹果公司的现任 CEO 是谁?他的前任是谁? |
11.2 实战案例
12. RAG 相关思考
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




