本系列文章通过逐章回答《Fundamentals of Software Architecture》(下文简称 FOSA)一书中的课后思考题,来深入理解书中的核心概念和理论,从而提升我们的软件架构设计能力。本篇为第八章内容。
本章的课后题是:
We define the term component as a building block of an application—something the application does. A component usually consist of a group of classes or source files. How are components typically manifested within an application or service?
组件在应用程序或服务中通常如何体现?
What is the difference between technical partitioning and domain partitioning? Provide an example of each.
技术分区和领域分区有什么区别?请各举一个例子。
What is the advantage of domain partitioning?
领域分区的优点是什么?
Under what circumstances would technical partitioning be a better choice over domain partitioning?
在什么情况下,技术分区会是比领域分区更好的选择?
What is the entity trap? Why is it not a good approach for component identification?
"实体陷阱"是什么?为什么它不是一种好的组件识别方法?
When might you choose the workflow approach over the Actor/Actions approach when identifying core components?
在识别核心组件时,你何时会选择 workflow 方法而不是 actor/actions 方法?
组件范围
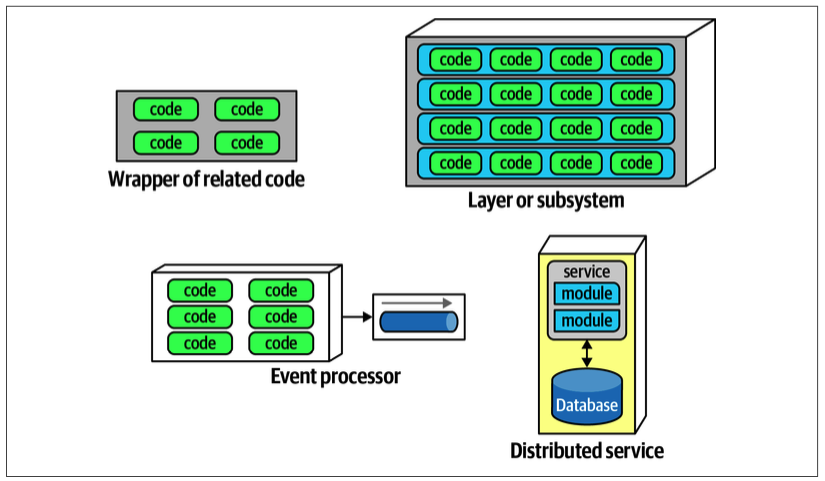
在软件架构中,组件被定义为模块的物理体现。它代表了相关代码的逻辑分组,并通过不同的方式进行物理打包。
组件在应用程序或服务中的典型体现方式包括:
- 库文件:这是最简单的组件形式,它将代码包装成更高层次的模块,通常在与调用代码相同的内存地址空间中运行,并通过语言函数调用机制进行通信。例如,Java 中的 JAR 文件、.NET 中的 DLL 文件和 Ruby 中的 Gem 文件。
- 子系统或层:组件也可以作为架构中的子系统或层来出现。
- 服务:特别是在微服务等架构风格中,服务是一种组件,它在自己的地址空间中运行,并通过低级网络协议(如 TCP/IP)或高级格式(如 REST 或消息队列)进行通信,形成独立的、可部署的单元。
- 逻辑边界:从领域驱动设计(DDD)的角度来看,有界上下文(Bounded Contexts)物理组件,例如服务、子系统等。每个有界上下文应作为一个独立的服务或项目来实现,这意味着它可以独立于其他有界上下文进行实现、演进和版本控制。有时一个有界上下文可以包含多个子域,此时有界上下文是物理边界,而其每个子域是逻辑边界,这些逻辑边界在不同编程语言中可能被称为命名空间、模块或包。
总之,组件是架构中最基本的模块化构建块,它们定义了代码的组织方式以及系统各部分之间的交互方式。
架构分区
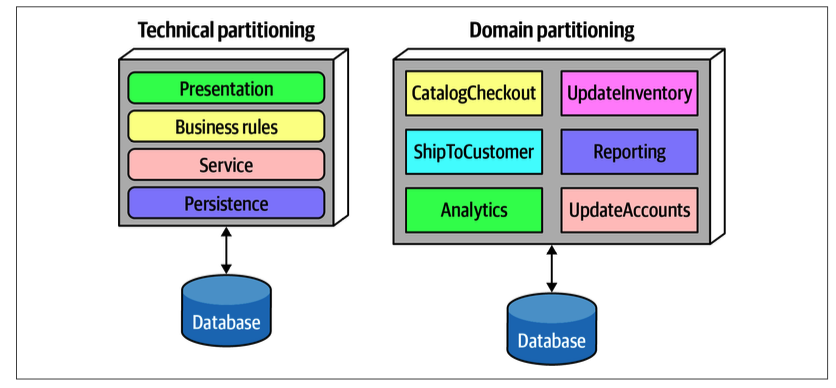
技术分区
技术分区 (Technical Partitioning): 是 根据代码的技术职责 来组织代码。这是传统分层架构的典型做法。每一层都有明确的技术目标,例如处理 HTTP 请求、执行业务规则或与数据库交互。
典型分层:
- 表现层 (Presentation/UI):
负责处理用户交互和展示,例如 MVC 框架中的
Controller和View。 - 业务逻辑层 (Business/Service): 负责实现核心业务规则和流程,是系统的核心。
- 数据访问层 (Data Access/Persistence): 负责与数据库或其他数据存储进行交互,执行增删改查 (CRUD)。
优点:
- 简单直观,上手快
- 清晰的技术关注点分离
- 促进技术层面的代码复用
缺点:
- 业务内聚性极低 (Low Business Cohesion): 这是技术分区最大的问题。一个完整的业务功能(例如,"用户下单")的逻辑被强制拆散,散落在所有三个层次中。当你需要理解或修改这个功能时,必须在多个目录和文件中来回跳转,增加了认知负荷。
- 功能开发导致高耦合 (High Coupling for Feature
Development):
由于功能代码被分散,任何一个业务需求的变更,都可能导致从上到下的“全垒打”式修改(即
Controller->Service->Repository都需要改)。这使得变更的影响范围变大,回归测试的成本也更高。 - 容易形成“上帝类”和瓶颈 (Prone to "God Classes" and
Bottlenecks): 随着业务越来越复杂,业务逻辑层
(
Business Layer) 很容易膨胀成一个巨大而臃肿的“上帝模块”,它了解所有业务细节,被所有表现层组件依赖。这个模块会变得难以维护和测试,成为整个系统演进的瓶颈。 - 阻碍团队自治和独立扩展 (Impedes Team Autonomy and Scalability): 很难将一个完整的业务功能垂直地分配给一个团队。两个团队开发不同功能时,很可能会在共享的业务逻辑层或数据访问层产生代码冲突。在分布式架构中,你也无法仅仅因为订单逻辑复杂就单独扩展业务逻辑层,而必须扩展整个单体应用。
适用场景:
- 小型、简单的应用程序: 尤其是 CRUD 密集型的管理后台、内容管理系统等。
- 业务领域稳定且不复杂: 如果业务在可预见的未来不会有大的变化,技术分区的简单性就是一种优势。
- 项目初期或概念验证 (PoC): 当业务边界尚不明确,需要快速验证想法时,可以从技术分区开始。
- 按技术职能划分的团队: 如果你的公司有独立的前端团队、后端 Java 团队和 DBA 团队,这种分区方式能匹配组织结构。
领域分区
领域分区 (Domain Partitioning): 是 根据业务领域或业务能力 来组织代码。每个组件都封装了某个特定业务领域所需的所有技术实现。这与领域驱动设计 (DDD) 的思想高度一致。
典型分区:
- 订单组件 (Ordering): 包含处理订单的所有逻辑,从 API 端点到数据库交互。
- 库存组件 (Inventory): 负责管理商品库存。
- 支付组件 (Payment): 封装与支付相关的所有功能。
优点:
- 业务内聚性极高
- 领域间的低耦合
- 支持团队自治和并行开发
- 易于独立扩展和部署
- 增强系统的演进能力
缺点:
- 初期复杂度和设计门槛高 (Higher Initial Complexity): 正确地识别和划分领域边界是领域分区的核心挑战。这需要架构师对业务有深刻的理解,并投入大量的前期分析设计(例如通过领域驱动设计 DDD 中的事件风暴等实践)。如果边界划分错误,后期的重构成本会非常高。
- 可能导致代码重复 (Potential for Code Duplication): 不同的领域组件可能需要相似的功能,例如身份验证、日志记录、数据访问模式等。如果缺乏良好的治理,这些横切关注点 (Cross-cutting Concerns) 可能会在多个组件中被重复实现。这通常需要通过共享库、平台服务或服务网格 (Service Mesh) 来解决。
- 分布式架构的额外开销 (Overhead of Distributed Architecture): 如果将每个领域组件实现为微服务,就需要处理分布式系统带来的所有复杂性,如服务发现、网络延迟、数据一致性、分布式事务等。
适用场景:
- 大型、复杂的企业级系统: 尤其是那些业务逻辑复杂、需要长期演进的系统。
- 微服务架构 (Microservices Architecture): 领域分区是实现微服务的标准和基础。
组件识别
组件识别是指在定义了宏观的架构风格(例如,分层单体、微服务)之后,发现和划定系统中各个功能模块(即组件)边界的过程。这个过程的目标是创建一组高内聚、低耦合的组件。
组件识别不是一个随意的过程,它需要系统性的方法和深刻的业务理解。如果边界划分错误,将会导致维护困难、扩展不易等一系列问题。接下来我们将要讨论的几个概念,正是服务于这个目的的方法论和需要警惕的陷阱。
实体陷阱
这是在组件识别过程中最常见、也最需要警惕的一个反模式 (Anti-pattern)。
实体陷阱是指
错误地将数据实体(通常直接对应数据库中的表)当作组件来进行划分。例如,系统中有
User, Product, Order
三张表,就草率地创建 User 组件、Product 组件和
Order 组件。
为什么是陷阱?
软件的核心价值在于处理 业务流程 (Business Workflow),而不仅仅是管理数据。一个有意义的业务流程往往会跨越多个数据实体。
我们以经典的"用户下单"流程为例。这个行为需要:
- 读取 用户信息 (User) 以确认其身份和收货地址。
- 查询 商品信息 (Product) 以获取价格并检查库存。
- 创建一个新的 订单记录 (Order)。
- 更新 商品库存 (Product)。
如果 User、Product、Order
各自是一个独立的组件,那么"用户下单"这段核心业务逻辑应该放在哪里呢?
- 放在
Order组件里?那么它就需要频繁调用User组件和Product组件,并且可能需要了解它们的内部数据结构,形成了紧密的耦合。 - 放在一个单独的
PlacingOrderService里?这个服务本身没有归属,像一个"流浪"的脚本,操纵着另外三个“只有数据没有行为”的贫血组件。
结论: 实体陷阱导致了 业务逻辑的碎片化 和 组件间的高度耦合。
👉🏻 正确的做法是围绕 业务能力 来划分组件,而不是围绕数据实体。一个更合理的组件应该是
Ordering(订单管理),它封装了Order实体以及所有相关的业务行为(如下单、取消订单、查询订单状态等)。
Actor/Actions
这是一种非常直观且有效的自顶向下的组件识别方法。它的核心是回答:"谁 (Who) 会对系统做什么 (What)?"
实施步骤:
- 识别执行者 (Identify Actors): 列出所有会与系统交互的"人"或"外部系统"。例如:顾客 (Customer)、管理员 (Admin)、仓库管理系统 (WMS)、支付网关 (Payment Gateway)。
- 识别操作 (Identify Actions):
针对每一个执行者,列出他们会对系统发起的具体操作(可以理解为用例)。
- 顾客 可以:搜索商品、查看商品详情、添加购物车、提交订单、支付。
- 管理员 可以:上架商品、调整价格、查看销售报表。
- 组件划分: 将相关的操作进行分组,形成初步的组件。
搜索商品、查看商品详情-> 可能属于Catalog(商品目录) 组件。添加购物车、提交订单-> 可能属于Ordering(订单) 组件。上架商品、调整价格-> 可能属于ProductManagement(商品管理) 组件。
优点:
- 简单直观,易于上手。
- 以用户为中心,能很好地识别出面向用户的核心功能。
缺点:
- 可能遗漏那些没有明确执行者的后台流程或系统内部流程。
Event storming
事件风暴是领域驱动设计 (DDD) 中一种强大的 协作式工作坊技术,用于快速、全面地探索复杂的业务领域,并从中识别出聚合 (Aggregates) 和限界上下文 (Bounded Contexts),而这些正是划分高质量组件(尤其是微服务)的理想边界。
核心过程: 这是一个由业务专家和技术专家共同参与的会议,大家在一个足够大的墙上,用不同颜色的即时贴 (sticky notes) 来“风暴”出整个业务流程。
- 橙色贴 - 领域事件 (Domain Event):
- 规则: 用过去时态描述业务中发生过的、有价值的事情。这是整个风暴的核心。
- 例子:
订单已提交、商品已添加到购物车、用户已注册。 - 大家将所有能想到的事件,按照时间顺序从左到右贴在墙上。
- 蓝色贴 - 命令 (Command):
- 规则: 触发领域事件的用户操作或系统指令。
- 例子:
提交订单(触发订单已提交)、添加商品到购物车(触发商品已添加到购物车)。
- 黄色小贴 - 执行者 (Actor):
- 规则: 发出命令的人或系统。
- 例子:
顾客(发出提交订单命令)。
- 粉色/黄色大贴 - 聚合 (Aggregate):
- 规则: 聚合是处理命令并产生事件的业务实体,它负责维护一组相关对象的数据一致性。
- 例子:
订单聚合负责处理提交订单命令,并产生订单已提交事件。
- 划定边界 - 限界上下文 (Bounded Context):
当整个流程可视化之后,团队会发现某些事件、命令和聚合在业务上高度相关,形成了一个个的"簇"。这些"簇"的边界,就是
限界上下文 的边界,也是 组件/微服务
的理想边界。例如,所有与订单创建、修改、状态流转相关的即时贴会自然地聚集在一起,形成
Ordering上下文。
优点:
- 协作性: 打破了业务与技术之间的隔阂,让所有人对业务有统一的理解。
- 深度洞察: 能发现隐性的业务规则和流程,识别出比 Actor/Actions 更自然的边界。
- 结果可靠: 通过事件风暴识别出的边界通常非常稳定,是划分微服务的黄金标准。
Workflow
这种方法是对 Actor/Actions 方法的一个重要补充,它专注于识别那些 没有明确、单一执行者的端到端业务流程。
核心思想: 寻找系统中的关键业务事件,并追踪由该事件引发的一系列后续处理步骤,将整个流程封装成一个组件。
实施步骤:
- 识别关键业务事件或调度任务: 例如:"订单支付成功"、"每月一日进行财务结算"。
- 描绘工作流:
画出该事件发生后,系统需要依次完成的所有步骤。
- 事件:订单支付成功 (Order Paid)
- 工作流:
- 更新订单状态为“待发货”。
- 调用仓库管理系统 (WMS) 接口,通知发货。
- 向用户发送“支付成功”的邮件/短信。
- 为用户增加积分。
- 组件划分:
整个工作流可以被识别为一个或多个组件。例如,可以有一个
OrderFulfillment(订单履行) 组件来编排这个流程。
适用场景:
- 后台处理: 如报表生成、数据同步、月末结算等。
- 异步流程: 一个操作触发后,后台需要执行一系列复杂的、耗时的任务。
- 编排服务 (Orchestration): 一个组件的主要职责是调用其他多个组件/服务来完成一个复杂的业务目标。
架构师职责
- 架构职责:架构分区
- 按层分区
- 按模块分区
- 按技术分区
- 按领域分区
- 开发职责:组件识别
- 识别基础组件
- 为组件赋予需求
- 分析组件角色和职责
- 分析架构特征
- 重构组件
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




