本系列文章通过逐章回答《Fundamentals of Software Architecture》(下文简称 FOSA)一书中的课后思考题,来深入理解书中的核心概念和理论,从而提升我们的软件架构设计能力。本篇为第十一章内容。
本章的课后题是:
Can pipes be bidirectional in a pipeline architecture?
在管道架构中管道可以是双向的吗?
Name the four types of filters and their purpose.
说出 4 种类型的过滤器及它们的作用。
Can a filter send data out through multiple pipes?
一个过滤器能否通过多条管道将数据发送出去?
Is the pipeline architecture style technically partitioned or domain partitioned?
管道架构是技术分区还是领域分区?
In what way does the pipeline architecture support modularity?
管道架构是如何支持模块化的呢?
Provide two examples of the pipeline architecture style.
举 2 个管道架构的例子。
拓扑
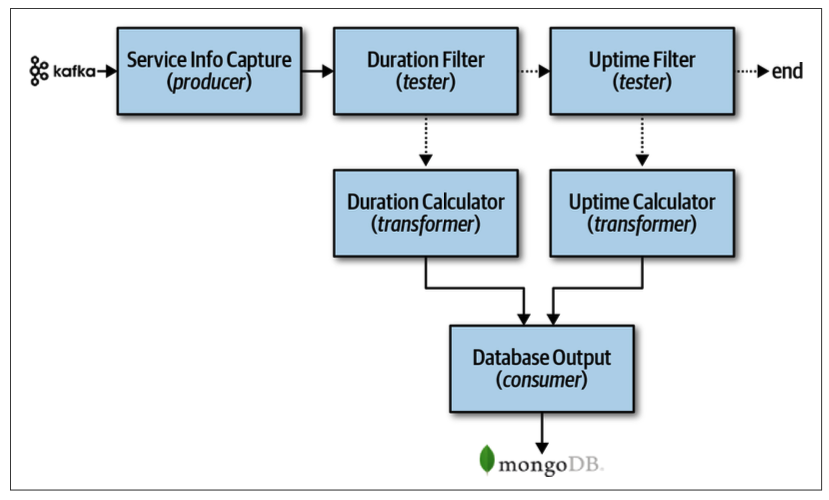
管道架构,又称为管道与过滤器架构(Pipes and Filters Architecture),是一种用于处理数据流的强大模式。它的核心思想非常直观,就像一条工厂的流水线:原材料从一端进入,经过一系列独立工站的加工、处理、检验,最终在另一端形成成品。
要理解管道架构,首先要理解它的两个基本构件:
- 过滤器 (Filter):它是一个独立的、可执行的处理单元,负责接收数据、执行单一任务(例如转换格式、过滤内容、扩充信息),然后将处理后的数据传递出去。关键在于,每个过滤器都是自包含(Self-Contained)和无状态(Stateless)的,它不关心上一个过滤器是谁,也不关心下一个过滤器是谁。
- 管道 (Pipe):代表流水线上的"传送带"。它是一个单向的数据通道,负责将一个过滤器处理完的数据传递给下一个过滤器。
在管道架构中,每个过滤器通常代表一个具体的技术操作,而不是一个完整的业务领域。整个管道将这些技术步骤串联起来,以完成一个业务流程,但其划分的单元(过滤器)是技术性的。
管道
管道的单向性(Unidirectional)是该架构风格的基石。原因在于:
- 维持简单性与解耦:单向流动保证了数据处理的顺序性和可预测性。每个过滤器只需关注自己的输入和输出,无需处理复杂的双向通信或回调逻辑。
- 避免状态依赖:如果管道是双向的,就意味着过滤器之间可能存在请求-响应(Request-Response)式的交互。这会引入状态和时间上的耦合,破坏了过滤器作为独立、无状态组件的核心原则。一个需要双向通信的场景,更适合采用其他架构风格(如客户端-服务器模式),而非管道架构。
因此,严格意义上的管道架构,其管道必须是单向的。同时,管道也可以支持强大的分支(Forking)和扇出(Fan-out)能力,一个过滤器可以根据处理结果,将数据发送到不同的下游管道,这个过程依旧保持了其单向性。
过滤器
生产者 (Producer / Source):作为整条管道的起点。它不接收来自管道的数据,而是负责创建数据,并将这些初始数据泵入管道。
转换器 (Transformer):它从上游管道接收数据,对其进行某种形式的修改或转换,然后将结果发送到下游管道。
测试器 (Tester):它接收数据,并根据一个或多个条件对数据进行检验。如果数据满足条件,就将其传递到下游管道;如果不满足,则数据流在此处被中断(或被导向另一条错误处理管道)。
消费者 (Consumer / Sink):作为整条管道的终点。它从上游管道接收最终处理好的数据,并将其消费掉,通常不会再将数据传递出去。
模块化
- 高内聚、低耦合(High Cohesion, Low Coupling):每个过滤器都是一个高内聚的模块,只专注于完成一件定义明确的任务。同时,过滤器之间通过管道这一标准接口进行通信,实现了极低的耦合,它们互相不知道对方的存在。
- 可组合性(Composability):过滤器就像乐高积木。我们可以通过不同的排列组合,快速地搭建出全新的数据处理流程,而无需修改过滤器本身的代码。
- 可复用性(Reusability):一个通用的过滤器(例如
GzipCompressor)可以被用在任何需要数据压缩的管道中,实现了代码的高度复用。 - 可替换性(Replaceability):只要遵守管道中的数据格式约定,我们可以轻易地用一个性能更好的新过滤器来替换掉一个旧的过滤器,而不会影响到管道的其他部分。
例子
1. UNIX/Linux 命令行
1 | cat access.log | grep "ERROR" | sort | uniq -c |
cat access.log:生产者,读取日志文件并产生数据流。|:管道,将标准输出连接到下一个命令的标准输入。grep "ERROR":测试器/转换器,过滤出包含 "ERROR" 的行。sort:转换器,对错误日志进行排序。uniq -c:转换器/消费者,统计重复行并输出最终结果。
2. ELT(Extract, Transform, Load) 流程
- Extract(抽取):生产者过滤器,从各种源系统(如业务数据库、日志文件、API)中读取原始数据。
- Transform(转换):一系列转换器和测试器过滤器,对数据进行清洗(去除无效值)、转换(统一格式)、扩充(关联其他数据)、聚合(计算统计值)等操作。
- Load(加载):消费者过滤器,将最终处理好的、高质量的数据加载到目标数据仓库或数据湖中,供后续分析使用。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




