本系列文章通过逐章回答《Fundamentals of Software Architecture》(下文简称 FOSA)一书中的课后思考题,来深入理解书中的核心概念和理论,从而提升我们的软件架构设计能力。本篇为第十三章内容。
本章的课后题是:
How many services are there in a typical service-based architecture?
在一个经典的基于服务的架构中通常有多少个服务?
Do you have to break apart a database in service-based architecture?
在基于服务的架构中,你是否必须将数据库进行拆分?
Under what circumstances might you want to break apart a database?
在什么场景下你会对数据库进行拆分?
What technique can you use to manage database changes within a service-based architecture?
在基于服务的架构中,你会使用什么样的技术来管理数据库变更?
Do domain services require a container (such as Docker) to run?
领域服务需要在容器(如 Docker)中运行吗?
Which architecture characteristics are well supported by the service-based architecture style?
基于服务的架构在哪些架构特性表现很优异?
Why isn’t elasticity well supported in a service-based architecture?
为什么基于服务的架构的架构弹性不是很好?
How can you increase the number of architecture quanta in a service-based architecture?
在基于服务的架构中,你如何增加架构量子的数量?
简介
在软件架构的演进光谱中,如果说单体(Monolith)和微服务(Microservices)是两个广为人知的端点,那么基于服务的架构(Service-Based Architecture, SBA)就是它们之间那个常常被忽略,却又极具现实意义的"务实中间派"。它既非庞大到笨拙,也非精细到繁杂,为许多成长中的系统提供了一条平滑的演进路径。
SBA 的本质是一种将一个大型的单体应用,分解为少数几个、逻辑独立的、可独立部署的"服务" 的架构风格。SBA 的服务数量通常不多,一般在 4 到 12 个之间。它不像微服务那样追求极致的拆分(可能会有几十上百个服务),而是将应用按照核心的业务领域(Domain)进行划分。
拓扑
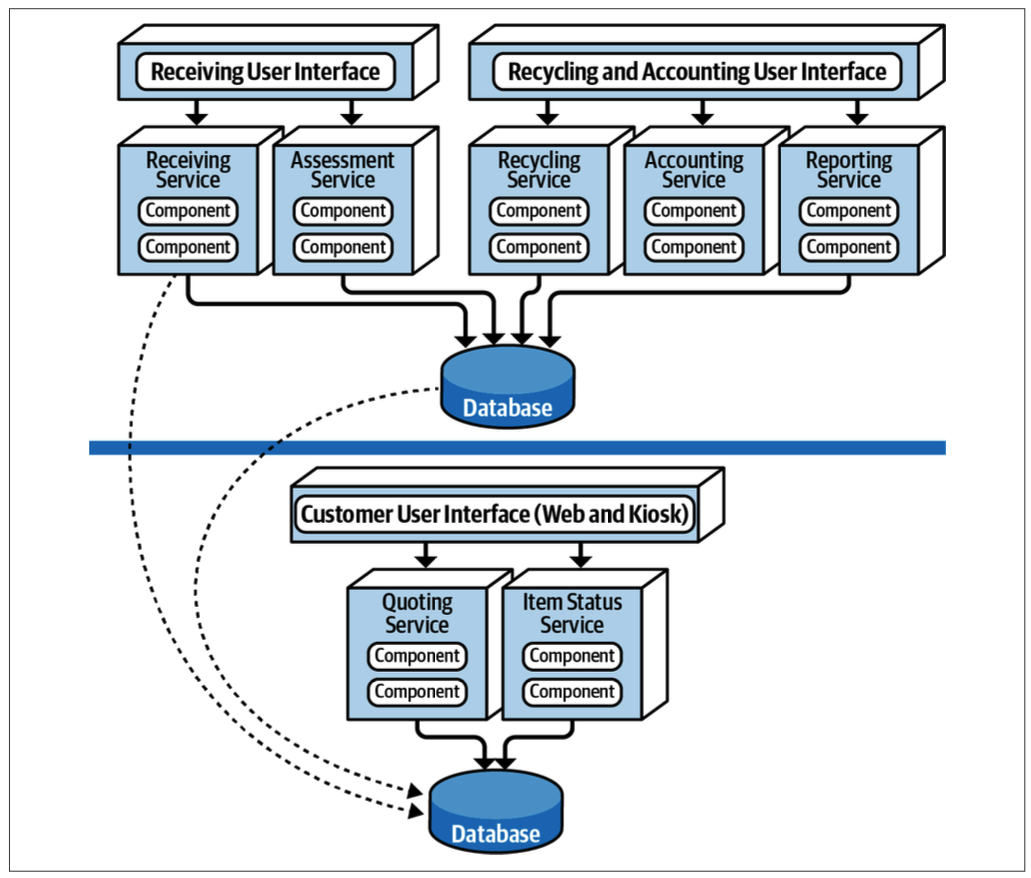
数据库
SBA 最具标志性,也是与微服务最根本的区别之一,就在于它对数据库的处理方式。这直接引出了接下来的两个问题。
Do you have to break apart a database in service-based architecture?
在基于服务的架构中,你是否必须将数据库进行拆分?
答案是:通常不,而且默认不拆分是其主要特征。
SBA 的典型实现是,所有服务共享同一个数据库。这种设计的初衷是为了在享受独立部署带来的好处的同时,最大限度地降低数据层面的复杂性。共享数据库可以:
- 简化开发:开发者无需处理复杂的分布式事务和跨服务数据同步问题。
- 保证数据一致性:传统的 ACID 事务可以在数据库层面轻松实现。
- 降低技术门槛:团队无需掌握复杂的分布式数据管理技术。
在共享数据库的模式下,如何管理这个公共资产成了一个关键的治理问题。
What technique can you use to manage database changes within a service-based architecture?
在基于服务的架构中,你会使用什么样的技术来管理数据库变更?
当多个团队开发的服务都依赖同一个数据库时,随意的 Schema 变更会引发灾难。因此,必须采用严格的数据库治理技术。
核心方法是成立一个跨团队的数据库治理小组,或者由一个专职的数据库管理员(DBA)团队来担当此任。这个团队的职责是:
- 守护数据库 Schema 的所有权:任何对数据库结构的修改(增删改表、字段等)都必须通过该团队的评审。
- 执行数据库迁移脚本:使用专业的数据库迁移工具(如 Flyway 或 Liquibase)来统一管理和执行所有的变更脚本,确保变更的可追溯性、版本化和一致性。
- 保证向后兼容性:确保数据库的变更不会破坏现有服务的正常运行。
然而,这种共享模式并非一成不变,这就引出了下一个问题:
Under what circumstances might you want to break apart a database?
在什么场景下你会对数据库进行拆分?
随着业务发展,共享数据库的弊端会逐渐显现。在以下情况下,拆分数据库就成了合理的选择:
- 服务资源争用 (Service Contention):某个服务(如高流量的商品浏览服务)对数据库产生巨大压力,影响了其他关键服务(如订单服务)的性能。
- 数据隔离与安全 (Data Isolation and Security):某个服务处理的数据高度敏感(如支付服务中的金融信息),需要从主数据库中物理隔离出来,以满足合规性或安全要求。
- 技术栈不匹配 (Technology Mismatch):某个服务有特殊的数据存储需求。例如,搜索服务最适合使用 Elasticsearch,而核心业务数据则存储在关系型数据库中。
当这些情况发生时,SBA 允许你"渐进式"地将某个服务连同其数据一起剥离出去,赋予它独立的数据库。
部署
Do domain services require a container (such as Docker) to run?
领域服务需要容器(例如 Docker)来运行吗?
答案是:不需要,但强烈推荐。
从技术上讲,你可以将每个服务单独部署服务器上。但是,容器技术(如 Docker)和容器编排工具(如 Kubernetes)与 SBA 的理念天然契合。使用容器可以带来巨大好处:
- 环境一致性
- 部署简化
- 资源利用率
架构权衡
Which architecture characteristics are well supported by the service-based architecture style?
基于服务的架构在哪些架构特性表现很优异?
相比于单体架构,SBA 在以下方面有显著提升:
- 可部署性 (Deployability):这是最大的优势之一。每个服务都可以独立部署,使得发布更加频繁、风险更低。
- 模块化 (Modularity):通过按领域划分服务,实现了清晰的业务模块边界。
- 可维护性 (Maintainability):每个服务的代码库规模远小于整个单体,更易于理解、修改和维护。
- 容错性 (Fault Tolerance):一个服务的崩溃不会导致整个应用程序宕机(尽管共享数据库可能成为共同的故障点)。
然而,SBA 并非银弹,它也有其固有的局限性。
Why isn’t elasticity well supported in a service-based architecture?
为什么基于服务的架构的架构弹性不是很好?
弹性指的是根据实时负载,自动、精细地伸缩应用特定部分的能力。
SBA 对弹性的支持不佳,根源在于其服务的粗粒度。假设"订单服务"包含了"浏览历史订单"、"创建新订单"和"订单退款"三个功能。如果"创建新订单"功能因为促销活动而流量激增,你无法只针对这一个功能进行扩容。你必须将整个庞大的"订单服务"进行水平扩展,复制出多个实例。这不仅造成了资源浪费(其他两个功能并未承压),也远不如微服务那样能够对具体功能点进行精准、高效的弹性伸缩。
架构量子
How can you increase the number of architecture quanta in a service-based architecture?
在基于服务的架构中,你如何增加架构量子的数量?
首先要明确,在典型的、共享数据库的 SBA 中,整个系统只有一个架构量子。因为所有服务都与同一个数据库紧密耦合,它们无法被真正独立地部署和演化,形成了一个不可分割的整体。
增加架构量子的数量,唯一的途径就是打破这种共享依赖。具体方法是: 将某个服务连同其数据一起拆分出来,为其分配一个独立的、专用的数据库。
每完成一次这样的拆分,这个被分离出去的服务就演变成了一个独立的架构量子。因此,增加架构量子的过程,就是逐步从共享数据库模型向"每个服务一个数据库"模型演进的过程,也就逐渐趋向于微服务架构了。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




