本系列文章通过逐章回答《Fundamentals of Software Architecture》(下文简称 FOSA)一书中的课后思考题,来深入理解书中的核心概念和理论,从而提升我们的软件架构设计能力。本篇为第十五章内容。
本章的课后题是:
Where does space-based architecture get its name from?
空间架构的名字从何而来?
What is a primary aspect of space-based architecture that differentiates it from other architecture styles?
空间架构区别与其他架构的主要方面是什么?
Name the four components that make up the virtualized middleware within a space-based architecture.
说出空间架构的虚拟化中间层的 4 个组成结构。
What is the role of the messaging grid?
消息网格的作用是什么?
What is the role of a data writer in space-based architecture?
数据写入器在空间架构中的作用是什么?
Under what conditions would a service need to access data through the data reader?
一个服务在什么情况下需要通过数据读取器去获取数据?
Does a small cache size increase or decrease the chances for a data collision?
缓存越小,数据冲突概率是增大还是减小?
What is the difference between a replicated cache and a distributed cache? Which one is typically used in space-based architecture?
复制缓存和分布式缓存的区别是什么?空间架构更倾向于使用哪个?
List three of the most strongly supported architecture characteristics in space- based architecture.
列出 3 个空间架构中非常优秀的架构特性。
Why does testability rate so low for space-based architecture?
为什么空间架构的可测性较差?
背景
基于空间的架构(SBA)是一种专门为解决高伸缩性(Scalability)、高弹性(Elasticity)、高并发(High Concurrency)、变动剧烈且不可预测的应用场景,例如在线票务系统或在线拍卖系统。
传统三层 Web 拓扑在用户量剧增时呈倒三角:Web 层易横向扩容,数据库层最难扩容,最终成为性能上限。为削弱数据库瓶颈,业界先用本地缓存,再出现集中式分布式缓存,但网络跳转仍是热点。把数据直接放到每个处理节点的 复制型内存网格 并实时同步,才真正让数据库从"同步路径"上消失,空间架构由此成形。
空间架构的名称来源于元组空间(Tuple Space)多个并行处理器通过共享内存进行通信。SBA 的核心理念便是将应用数据保存在内存中(in-memory),并在所有活跃的处理单元(Processing Units)复制,从而移除中心数据库作为同步约束,实现近乎无限的伸缩性。
拓扑
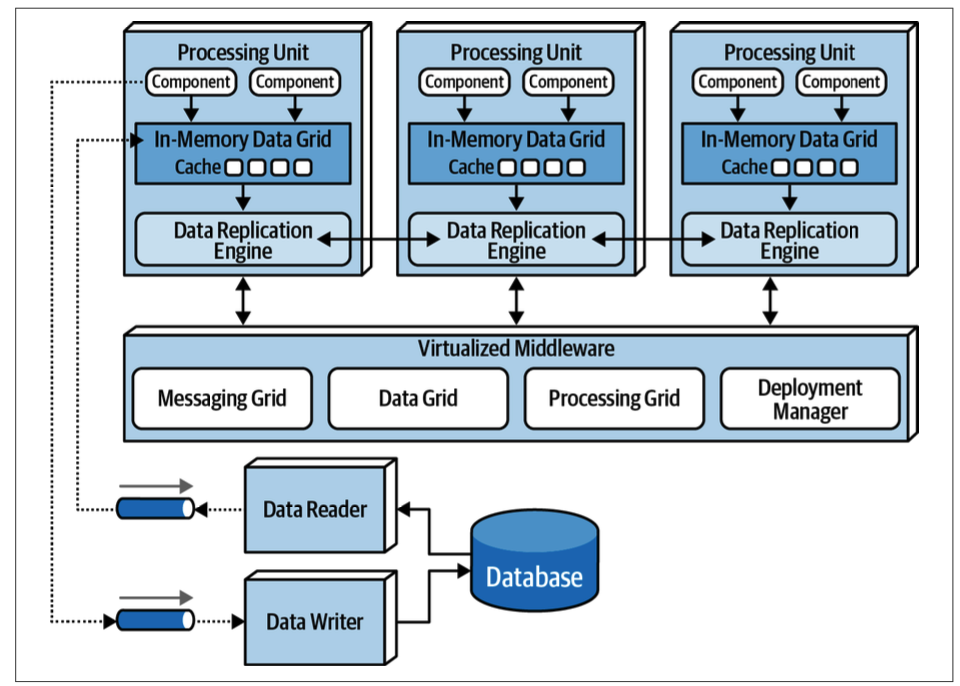
处理单元 Processing Unit
- 处理单元包含了应用逻辑(包括基于 Web 的组件和后端业务逻辑)。
- 它还包含一个内存数据网格和复制引擎,通常由 Hazelcast、Apache Ignite 或 Oracle Coherence 等产品实现。
- 处理单元可以包含小型、单一用途的服务,类似于微服务
虚拟化中间件 Virtualized Middleware
虚拟化中间件负责处理架构中的基础设施问题,控制数据同步和请求处理。它由以下四个关键组件组成:
- 消息网格(Messaging Grid):它负责将请求转发到任何可用的处理单元。
- 数据网格(Data Grid):它是 SBA 中最重要和关键的组件,通常在处理单元内部以复制缓存的形式实现。它确保每个处理单元都包含完全相同的数据,数据复制是异步且快速的。
- 处理网格(Processing Grid):这是一个可选组件,用于管理协调请求处理,当一个业务请求涉及多个处理单元时,它会协调这些处理单元之间的请求。
- 部署管理器(Deployment Manager):该组件根据负载条件管理处理单元实例的动态启动和关闭,对于实现应用的弹性伸缩至关重要。
数据泵 Data Pumps
数据泵是将数据发送到另一个处理器,然后该处理器更新数据库的方式。它们总是异步的,提供内存缓存与数据库之间的最终一致性(Eventual Consistency)。消息机制是数据泵的常用实现方式,因为它支持异步通信、保证消息传递和维护消息顺序。
数据写入器 Data Writers
数据写入器(Data Writers)负责接收来自数据泵的消息,并用消息中包含的信息更新数据库。它们可以是服务、应用或数据中心(如 Ab Initio)。写入器的粒度可以根据数据泵和处理单元的范围而变化,例如,领域驱动的数据写入器可以处理特定领域(如客户)内的所有更新。
数据读取器 Data Readers
负责从数据库读取数据,并通过反向数据泵将其发送到处理单元。服务需要通过数据读取器访问数据的情况有三种:
- 所有相同命名缓存的处理单元实例都崩溃时。
- 所有相同命名缓存的处理单元需要重新部署时。
- 需要检索复制缓存中不包含的归档数据时。
数据冲突
不同的 processing unit 处理同一个业务逻辑相关的数据时,由于数据同步存在时序问题,所以很容易出现数据不一致的情况。
可以从以下几个因素进行冲突概率的评估:
- N:处理相同缓存的 processing unit 的数量
- UR:缓存更新频率
- S:缓存大小
- RL:缓存复制的延迟
CollisitionRate = N* (UR2/S) *RL
其中缓存大小越小,意味着缓存能够容纳的数据量越少,因此在给定的更新速率和复制延迟下,数据被频繁覆盖和发生冲突的几率就越高。
分布式缓存
复制缓存:每个处理单元包含一个自己的内存数据网格,与其他共享相同命名缓存的处理单元同步。这是 SBA 通常采用的缓存模式,因为它提供高性能和高容错性。适用于小缓存大小(<100MB)、低更新率和相对静态数据。
分布式缓存:需要一个外部服务器或服务专门用于存放集中式缓存。它支持高水平的数据一致性,但性能较低(需要远程访问),且容错性存在问题(如果缓存服务器宕机)。适用于大缓存大小(>500MB)、高度动态数据和高更新率。
优点
- 弹性(Elasticity):处理单元可以根据负载动态启停,实现高度弹性。
- 伸缩性(Scalability):通过内存数据缓存和移除数据库约束,支持处理数百万并发用户。
- 性能(Performance):移除了数据库瓶颈,提供了极高的性能。
缺点
- 简洁性(Simplicity):SBA 是一种非常复杂的架构风格,因为它涉及到缓存、最终一致性以及众多动态组件。
- 可测试性(Testability):由于需要模拟极高的伸缩性和弹性负载,测试复杂且成本高昂,许多高负载测试甚至需要在生产环境中进行,带来巨大风险。
- 成本(Cost):由于缓存产品许可费和高资源利用率,SBA 通常相对昂贵。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




