
我觉得可以用道法术器来对复杂度管理进行一个重点概述:
- 道(目标):管理复杂度
- 法(基石):抽象、分治、分层、模块化
- 术(方法):SOLID 原则、设计模式、架构模式、领域驱动设计(DDD)
- 器(工具):单元测试、可观测性
道:管理复杂度是我们的终极目标
"道"是我们的终极目标,是我们实施软件工程一切的 WHY,
在三年的工作经历中,我对"屎山"的理解太深刻了。我亲手维护了大量前人留下的屎山代码,不做分层设计、模块划分不恰当、全局变量到处飞、命名随便起、概念不明晰。我也亲眼见证我由我经手的代码是如何一步步变成屎山的,需求的随意修改、为了应付 deadline 而习惯成自然的"龙卷风战术"、迭代时对现有字段的概念胡乱扩充、解决问题不处理根源而为了炫技在外面包装一层,金玉其外败絮其中。
这些技术债,使得代码阅读难度飙升,功能迭代负担巨大,重构风险难以估量,对新人很不友好。随着破窗效应的不断扩大,为了快速应付哪些莫须有的 deadline 和"紧急"需求,领导们和底层员工都习惯于采取"龙卷风战术"来快速完全需求,加剧了恶性循环。截止到我离职之前,这些技术债已经对业务发展的技术支持度、研发效率和产品质量造成了严重影响了。
我也试图做过一些努力,亲自全力推进了代码质量建设和服务监控建设两大专项,对于我个人来说改变是巨大的,我从工程认知、编码思维、业务理解等多方面都有巨大的突破。坦白说,从另一个层面来说,我庆幸过这些"屎山"的存在,我也很庆幸自己在职业初期就打下了坚实的基础,也认定了要成为一位优秀的软件工程师的目标。只不过,在历史长河中,我这两大专项对于团队的影响,却是杯水车薪,聊胜于无罢了。
我一直在思考,为什么?为什么复杂度就像"熵增"一样不可避免?我们程序员的宿命,难道就是不断地在屎山上雕花吗?若将来我有机会成为一位领导者,我如何避免上述问题的发生?
Fred Brooks 在《人月神话》中早已断言:软件的困难,在于其固有的复杂度 (Essential Complexity)。
- 复杂度不是难:不是指"这个算法很难",而是指"系统中组件间依赖关系的数量"。
- 复杂度是非线性增长的:一个 100 个模块的系统,其潜在的"依赖"和"状态组合"是天文数字。当认知负荷超过人脑(或团队)的上限时,系统就失控了。
- 复杂度是万恶之源:
- 你修复一个 Bug,却引发了三个新 Bug?—— 复杂度失控。
- 你无法安全地添加一个新功能?—— 复杂度失控。
- 你不敢重构?—— 复杂度失控。
所以我觉得不管是什么样的技术栈、设计原则、编程思维、架构模式,或是那么多的软件工程管理方法论,比如敏捷开发、极限编程,或是现在的终极大杀器领域驱动设计,都是为了管理复杂度。因此,本篇后续的所有内容都是为了服务于"管理复杂度"这唯一且根本的道。
法:管理复杂度的四大核心原则
既然我们无法消灭复杂度,我们就只能管理它。在众多编程思想、设计模式、架构模式中,我觉得其中最最最根本、生命力最最持久、最有可能以不变应万变的是以下 4 点:
- 抽象:隐藏实现细节,只暴露意图契约。
- 分治:将一个大问题,拆解为一堆可独立解决的小问题。
- 分层:规定模块间的依赖关系,且依赖必须是单向的。
- 模块化:高内聚 (High Cohesion),低耦合 (Low Coupling)。
抽象
抽象的作用
我发现!抽象这个词是真的抽象!我们经常在聊抽象,当发现原有代码不好迭代的时候,我们会说"这个抽象得不够好",当看到代码比较混乱、重复较多时,我们会说"这个有空可以抽象一下",当然有时候也会吐槽"这个代码写得真抽象",或者"这有点过度抽象了"。
我时常想不明白当我们在谈抽象的时候,我们到底在说些什么?什么是抽象?怎么判断要不要抽象?怎么做抽象?要抽象的东西到底是什么?抽象到什么程度是恰当的?怎么评判一个抽象行为的好坏?如何避免过度抽象?如何在不断变化的业务需求中做一个稳定的抽象?
用一句话形容就是:我们经常在谈抽象,它在软件工程中无处不在,但又极其"主观"和"暧昧"。
为了更靠近上述问题的答案,或许我们应该退一步,回归它的第一性原理:它不是一种代码技巧,而是一种管理复杂度的核心战略。
本篇我们在谈管理复杂度的问题,但是人脑的认知负荷是有限的(米勒定律说我们只能同时处理 7±2 个信息块)。一个拥有 100 个模块的系统,其潜在的依赖关系和状态组合是天文数字,远超人脑上限。
而抽象是我们对抗认知负荷的第一武器。既然我们没法同时处理那么多的信息块,那就想办法让自己只需要同时处理少数信息块。所以抽象的本质是就是信息隐藏。它将一个复杂系统,拆分为两部分:
- 契约或 API:这是 What,即它能做什么。它是简单的、稳定的、易于理解的。
- 实现: 这是 How,即它如何做的。它是复杂的、易变的、被隐藏的。
因此,一个好的抽象,就是一套简单易懂的契约;而一个坏的抽象,就是一套让人猜不透的契约。
抽象的难点
在实际编码过程中,最常见的抽象行为就是定义接口。但是我们经常会发现很多接口的定义是毫无意义甚至是负作用的。我总结了过去 3 年工作中存在的关于接口定义问题最大的 3 个点:
- 毫无接口定义:起初在我们的 Web 服务中,没有任何的接口定义,甚至都只有两层架构,只能面向实现编程,各个模块耦合严重,写代码牵一发而动全身,在代码理解、模块划分、职责明晰、组件升级、代码复用、架构重构、单元测试、问题排查和业务迭代等各个方面都带来了层层阻力。
- 单一实现大接口:在我们的老匹配服中,倒是定义了一些接口,但是这些接口都非常大,动辄三四十个方法,而且都只有一种实现。这种接口定义,除了给阅读代码带来多一层跳转的心智负担之外,毫无意义。
- 接口繁多且职责不匹配:在我们的新匹配服中,倒是吸取了过往不少的教训,但是过犹不及。我们定义了一大堆接口,引入了一堆的设计模式和编码技巧,使得代码极其抽象,阅读难度很高,经常为了理清一个逻辑要跳转十几次,看了后面忘了前面。而且很多接口定义的方法和接口本身该有的职责是不匹配的,这带来了非常大的困扰。这种我统一称为炫技。比如所以外表虽然看起来牛逼,但实际上代码可读性极差。
至今我依然觉得做好接口定义真是一件不容易的事情,而且想一次定义一个好的接口,也几乎是不现实的。不过至少现在我们可以得出一个结论:
[!IMPORTANT]
抽象是有成本的:它增加了间接性,代码不再是平铺直叙的,需要多一次跳转,这本身也会增加认知负荷。
如果收益 < 成本,这就是过度抽象。过度抽象的本质是:你为你"猜想"的、但"永远不会发生"的"变化",提前支付了"抽象的成本"。
抽象的本质
现在需要回到一个最关键的问题,当我们在谈抽象的时候,我们究竟在"抽"什么?如果不知道"抽"什么,我们就会"瞎抽"。
[!IMPORTANT]
答案是:我们抽象的不是"代码",我们抽象的是"变化"。软件的宿命就是不断变化。而抽象的目的,就是隔离变化——把系统中易变的部分和不变的部分隔离开,在它们之间建立一道防火墙。
关于变化,我觉得可以从 2 个方面进行思考:
- 技术抽象:是不变的业务 vs 易变的技术。
- 业务抽象:是不变的业务本质 vs 易变的业务流程。
技术层面的抽象
这里我想以业务逻辑层(Service)和持久化层(Repository)之间的交互来展开谈一谈。
比如说我们有一个订单服务 OrderService,这个时候很多的教学视频都会说,那我们要给持久化层定义一个 OrderRepository,这样后面我们不管是使用 MySQL、还是换成 Mongo、Oracle 都不会影响到 Service 层的逻辑。我个人觉得如果是以这样的目的去做的接口定义,离真正的抽象还是有不少距离的。事实上,在一个系统中,你几乎不会更换数据库的类型,因为它的影响面和风险实在太大了,即便有,频率也是极低的,为了一个极大概率不发生的"变化"提前支付了长时间的"抽象成本",是不划算的。
那还有没有必要定义 Repository 接口呢?当然是有必要的,不过它的出发点应该是为了应付那些日常研发过程中经常会碰到的"变化",比如:
- 为了可测试性:如果你不为 Repository 层定义接口,那你测试 Service 层的时候,就不得不连接到数据库,可测试性极差。
- 为了不污染核心业务:数据库不常变,但是访问数据库的方式却是有可能变化的,Repository 可以为 Service 提供一个干净稳定的数据访问契约,屏蔽掉易变化的细节。
- 为了可控的外部依赖:如果我们依赖的不是数据库,而是第三方服务,比如说短信 API 服务,那修改第三方服务的可能性也就大大提升了,不同厂商或是同一厂商的不同版本 API 所需要的参数、返回值都可能是不一样的。
接下来我们举 3 个例子来分别阐述一下。
首先是为了可测试性而抽象,这是抽象在工程实践中最刚需、最不可辩驳的理由。假如说我们接口了一个 OrderService,它没有任何的抽象:
1 | // 反例:没有抽象,"业务逻辑" 和 "技术实现" 焊死 |
我们根本无法为 CreateOrder
方法写单元测试。你写的任何测试,都会真的去
s.db.Create,它会真的尝试连接
MySQL。这是一个集成测试,它慢、依赖环境、而且极其脆弱。你也无法单独测试
if order.Price < 0 这行核心业务逻辑。
针对这种情况,我们做的抽象,就是要把那个易变的 s.db
从具体实现抽象为契约。
1 | // 正例:抽象出 "Repository" 契约 |
这个时候我们的收益是 100% 可以兑现的,即 OrderService
现在100% 可被单元测试。
1 | // order_service_test.go |
接下来是为了不污染核心业务而抽象,假如我们的
OrderService V1 运行良好。老板说:V1
太慢了,给创建订单加一层 Redis 缓存!
如果没有抽象,那你会被迫入侵 OrderService
的实现细节:
1 | // 反例:业务逻辑被 "基础设施" 污染 |
噩梦是什么:
- 职责混乱:
OrderService不再纯粹,它现在同时关心"业务规则"、"MySQL 写入"和"Redis 缓存"。 - 测试灾难:
你的单元测试(如果有的话)现在又需要 Mock
redis.Client了。 - 下一个噩梦: 下周老板说再加一个 Kafka
消息,通知履约’中台,你是不是要在这个函数里再加
kafka.Producer?
我们的解决方案是 OrderService
一行代码都不用改。它只认识 OrderRepository
这个契约。
1 | // 正例:我们 "实现" 一个新的 "How" |
这里我们只需要初始化的时候,做出以下修改,OrderService 完全不用动,我们就可以享受到扩展时不污染核心业务的收益,这种收益,是时常会发生的。
1 | // v1 |
最后一个例子是为了可控的外部依赖而抽象。假如说我们有个用户注册服务,需要调用腾讯云短信
API 发送验证码。如果没有抽象,那就会在 UserService
中硬编码了腾讯云的 SDK。
1 | // 反例:焊死 "外部依赖" |
噩梦是什么:
- 测试地狱: 你每跑一次
Register的测试,就真的给手机发了一条短信!测试成本高昂,且依赖网络。 - SLA 绑架: 腾讯云短信 API 挂了(这经常发生),你的注册服务跟着一起挂。
- 迁移灾难:
老板说腾讯云太贵,换成阿里云。你必须入侵
UserService内部,把tx_sms.Client的所有 API 调用,逐行改成ali_sms.Client的 API。
我们的解决方案是:定义一个你自己的防腐层。
1 | // 正例:抽象 "短信服务" 契约 |
收益是什么:
- 可测试性: 单元测试时,你注入
MockSMSService。 - 环境隔离: 开发/测试环境时,你注入
LogSMSService(它只打印日志不发短信)。 - 可迁移性: 从腾讯换阿里,
UserService一行不用改,你只需要在main.go替换实现类。 - 健壮性: 你甚至可以实现一个
FailoverSMSService高可用实现,它内部尝试先用腾讯、失败后自动降级到阿里。而UserService毫不知情。
这种收益在实际业务开发过程中,也是时常会发生的。
业务层面的抽象
前面提到的 3 个技术层面的例子,难度小、代价低、收益高、可复制性强,所以我觉得任何时候我们工程师都要尽力把这些方面做好。
但是业务层面的抽象就不一样了,我们工程师的噩梦,就是业务方(PM)每天都在改需求,我们被易变的流程牵着鼻子走,导致核心代码日益腐化。所以业务抽象的唯一目的,就是在易变的业务规则(流程)中,保护不变的业务本质。
这里我想引用《服务端开发·技术、方法与实用解决方案》一书中的一个例子,这也是我在 2024 年年中绩效总结时对前司部门提出的一个建议(虽然事实上并没起到什么作用)。书中提出了一个疑问:
[!WARNING]
产品需求退化的根本原因是什么?
—— 是缺乏抽象
通过抽象可以理清业务的核心问题并设计体系化的方案予以解决,而缺乏抽象则只能通过具体的、复杂的描述来反映事务的表面特征。
比如有以下需求:
"优惠立减"活动上线后,在 App 主页,如果用户是在活动开始后首次进入,则弹出一个提示窗口,展示"优惠立减"活动信息,吸引用户参与;如果用户点击弹窗信息,则跳转进入到对应的活动页面,之后在 App 主页不再弹窗提示,避免打扰用户;如果用户不点击弹窗信息,则弹窗 5s 后自动关闭,之后用户若再进入 App 主页,则以每周弹窗 3 次的频率提醒用户,直到用户点击弹窗信息为止。
如果我们完全按照这个需求方案来进行编码,那估计又是一个函数里面硬编码了很多的逻辑,那势必会在需求的每日变化中不断腐化。那这个业务的本质是什么呢:
这是一个"控制疲劳度"(疲劳频次)的问题,即"业务场景 S 对应 F 次/周期 Q"。
- S:任意场景
- F:整数
- Q:时间单位, 天、周、月、年、终身等
不过我觉得,策划和运营团队,对于"运营活动"的模型理解跟技术团队是有区别的,技术团队面对的是具体到一个个细节、完整的需求,而在策划和运营团队那,可能有一套不一样的底层逻辑。技术团队要做到抽象,只能是在接触了多个明显相似的需求后,才有可能进行抽象提取,哪怕是这个时候,跟业务方的理解也可能有偏差。所以如果可以从业务方源头就做好抽象,那真是可以起到四两拨千斤的作用。
接下来我们来看两个研发过程中最常见的业务痛点(变化点):规则和流程。
痛点一:If-Else 怪物 —— 业务规则的腐化
现在有一个计算订单价格的服务
OrderService.CalculatePrice(),它经历了以下几个版本:
- V1(上线):
逻辑很简单:
price = product.Price * quantity - V2(双十一): PM
跑来说:加个双十一规则,所有商品打 8 折!
- 你入侵了
CalculatePrice:if (isDoubleEleven) { price = price * 0.8 }
- 你入侵了
- V3(拉新): PM 又来说:新用户第一单,再打 9 折!
- 你再次入侵:
if (isNewUser) { price = price * 0.9 } else if (isDoubleEleven) { ... }
- 你再次入侵:
- V4(VIP 会员): PM:VIP 用户,折上再打 95 折!
- 你:
if (isVIP) { ... } else if (isNewUser) { ... } else if ...
- 你:
CalculatePrice 方法变成了 500 行的 if-else
怪物。它腐化了。
- 认知负荷:没人(包括你自己)能说清一个价格到底是怎么算出来的。
- 测试灾难:你需要
2*2*2=8种,甚至更多的组合来测试所有规则。 - 维护地狱:PM 让你去掉双十一,保留
VIP,你得小心翼翼地去修改
CalculatePrice这个函数,删多删少咱也就不好说了。
我们的解决方案是:策略模式 (Strategy Pattern)
- 不变的本质是什么? 订单价格需要被一系列规则所计算。
- 易变的是什么? 规则本身(今天双十一,明天 618)。
我们要抽象的,就是规则这个易变的东西。
1 | // 1. "抽象" 出 "契约":一个 "促销规则" (What) |
收益是什么:
- 腐化被阻止了: 你的
OrderService不会再变了。它变得极其稳定、干净、且纯粹。 - 开闭原则的实现:
- PM 让你去掉双十一?你只需要在
policies列表里,删除DoubleElevenPolicy即可。核心业务代码 0 修改。 - PM 让你新增 618?你只需要新建一个
SixEighteenPolicy.go文件,然后加到列表里。核心业务代码 0 修改。
- PM 让你去掉双十一?你只需要在
这就是业务抽象的第一个巨大价值:用组合 (Composition) 代替修改 (Modification),隔离核心与规则。
痛点二:上帝服务 —— 业务流程的膨胀
还是 OrderService。
- V1(上线):
CreateOrder逻辑很简单:repo.Save(order)。 - V2(“通知”): PM
跑来说:订单创建后,要给用户发个短信!
- 你入侵了
CreateOrder:repo.Save(order); sms.Send(...)
- 你入侵了
- V3(加积分): PM
又来说:发短信后,顺便给用户加个积分!
- 你再次入侵:
...; sms.Send(...); loyalty.AddPoints(...)
- 你再次入侵:
- V4(通知履约):
PM:加完积分,还要通知一下履约中台(WMS)!”
- 你:
...; loyalty.AddPoints(...); wms.Notify(...)
- 你:
CreateOrder 方法变成了上帝方法。它什么都干。
- 职责膨胀:
OrderService不仅要管"订单",它现在还被迫认识了"短信"、"积分"和"履约"。它高耦合了。 - 事务地狱: "积分"挂了,
CreateOrder事务要不要回滚?"短信"超时了,要不要让用户多等 30 秒? - 测试灾难:
为了测试"创建订单",你被迫要 Mock
sms,loyalty,wms三个外部依赖。
我们的解决方案是:领域事件 (Domain Events)
- 不变的本质是什么?
OrderService的核心职责 只有一个:创建订单(即,保证"订单"这个聚合根的状态一致性)。 - 易变的是什么? 订单创建后引发的下游副作用(短信、积分、履约...)。
我们要抽象的,就是副作用这个易变的东西。
1 | // 1. "抽象" 出 "契约":一个 "事件" (What) |
收益是什么:
- 上帝服务被拆解了:
OrderService的职责被净化了。它回到了它不变的本质——只管"订单"。 - 高内聚、低耦合的实现:
- PM 让你去掉短信通知?你只需要下线
SMSSubscriber即可。OrderService毫不知情。 - PM
让你新增财务对账通知?你只需要新建一个
FinanceSubscriber即可。OrderService毫不知情。
- PM 让你去掉短信通知?你只需要下线
我们总结一下,技术抽象是在实现(How)层面做替换(MockRepo
替换
MySQLRepo)。而业务抽象是在逻辑(What)层面做组合和解耦,这里我给出了
2 个思路:
- 策略模式(应对规则): 当
if-else开始腐化你的核心算法时,把规则 (Rules)抽象成策略,用组合代替修改。 - 领域事件(应对流程): 当下游开始污染你的核心职责时,把副作用 (Side Effects)抽象成事件,用发布/订阅代替直接调用。
接口定义在哪
这里我想再多谈一下接口定义在哪里的问题,这会涉及到一组概念:需求方接口和提供方接口。这也是我在阅读了《软件设计·从专业到卓越》一书后,觉得收获非常大的地方,从那之后,这组概念一直是指导我进行业务抽象和接口定义的核心思想武器。
前面我们提到了要为 OrderService 配一个
OrderRepository
接口,以实现可测试性、扩展时不污染业务和可控的外部依赖。这里我想提出一个问题:OrderRepository
是定义在 service 层还是定义在 repository 层?
答案是应该定义在 service 层!这可能会有一点反直觉!
如果定义在了 repository,那就说明 service 依赖了 repository,不管你依赖的是接口,还是具体的实现,都是依赖,在 Go 语言里面的体现就是你需要在 service package 中 import 关于 repository 的东西。
但是如果定义在 service 层,那 service package 中将不会存在任何关于 repository 的引用的,你只需要在依赖注入的时候去 repository 层找到能实现 service 要求的接口实现即可,这个时候反而是 repository 依赖了 service(的要求),也就是所谓的依赖倒置原则 (DIP)!
那为什么要这样呢?我们前面提到了接口抽象就是定义契约,那这个契约由谁来定呢?应该由需求方来定义,因为只有需求方,才知道自己需要什么东西。OrderService
需要一个 Save(order) 的方法。它不需要(也不应该)关心
MySQLOrderRepo 还提供了(或被迫实现了)其他 10
个它用不到的方法(比如 GetConnectionPoolStats)。
关于需求方接口和提供方接口的更进一步阐述,感兴趣的读者可以阅读我之前整理的笔记:需求方接口 vs. 提供方接口,这里就不赘述了。
抽象的时机
前面我们总结了抽象的作用、难点和核心,也在技术和业务两个层面进行了展开并给出了一些切实有效的实施建议。我们已经知道"抽"什么(变化),但什么时候"抽"呢?那最后我们就来谈一谈抽象的时机,即如何尽可能减少过早或过度抽象?
我觉得可以遵循一个原则(收益 > 付出)两个策略:
- 策略一:为测试而抽象。这是刚需,当你的判断出一个业务逻辑值得撰写单元测试的时候,你为了让它(
OrderService)可被单元测试,你必须能够替换它的依赖(OrderRepository)。 - 策略二:事不过三原则。这是对抗过度抽象的最佳启发式规则。
- 第一次:你写了一个功能,不要抽象。就写具体实现。坚守 YAGNI (You Ain't Gonna Need It) 原则。
- 第二次:你写一个类似功能,你可能会复制-粘贴-修改。忍住,还是不要抽象。但你要开始警惕了。
- 第三次:当你复制-粘贴第三次时,说明变化的模式已经稳定出现。此时,你不再是猜测变化,你是在响应已经发生的变化。这是抽象的最佳时机。 从具体的代码中提炼出抽象的接口,远比凭空设计一个抽象要靠谱得多。
分治
分治 (Decomposition) 的第一性原理是将一个大规模的、难以直接处理的大问题,拆解为一系列可独立解决的小问题,然后通过组合这些小问题的解,来得到大问题的解。
这个道理我们都懂,因为人脑的认知负荷有限。一个庞大且 All-in-One 的系统,其内部状态和依赖关系的组合呈指数级增长,很快会超过任何工程师(或团队)的处理上限。
在我的三年经验里,我最恐惧的,莫过于在 💩 代码中,一头扎进一个几千行的函数中:
- 你根本不知道它的主线是什么,因为
if-else的支线已经把它变成了意大利面条。 - 你不敢重构,因为你根本不知道你手里这个小问题,是多少个大问题共享的内脏,负负得正你受得了吗?
- 你无法测试,因为你连单元的边界都找不到。
分治的本质
在我看来,分治的本质在于治,而不在于分。分(divide)只是手段,而治(Conquer)才是目的。
"分"(Divide)是为了什么?
降低认知负荷
隔离变化
提高可测试性
实现复用
但这些都是为了"治"(Conquer)服务的:
能够独立理解每个部分
能够独立开发每个部分
能够独立测试每个部分
能够独立修改每个部分
最终能够有效地控制复杂度
如果只"分"不"治",就会出现:
过度拆分,反而增加复杂度
形式上分离,但依赖关系混乱
看起来模块化,但实际上改一处牵一发而动全身
分治的边界
分治最大的风险,是错误的边界划分。一个错误的分治,即将一个本应内聚的整体强行拆开,这非但不能降低复杂度,反而会因为引入高耦合和通信开销(如不必要的网络调用),而增加了系统的意外复杂度。
关于分的边界,我个人觉得可以从两个层级进行考虑:
- 代码层级:单一职责(SRP)
- 系统层级:限界上下文(Bounded Context)
在代码级别,我们面对的问题是什么?是变更。一个软件的生命周期中,最大的成本是维护,而维护的核心就是应对变更需求。
A class should have only one reason to change. —— Robert C. Martin (Uncle Bob)
一个类应该只有一个变更的理由。
- 分 (Divide): 如何分?SRP
告诉我们,变更的理由 (Reason to Change)
就是你分的边界。
- 问题: 假设一个
Employee类,它既负责计算薪酬 (A 理由:财务规则变更),又负责保存数据到数据库 (B 理由:DBA 变更表结构),还负责生成报表 (C 理由:HR 变更报表格式)。 - 复杂度: 这 3 个理由(A, B, C)被耦合在同一个类里。A 的变更可能会破坏 B 的功能;B 的变更又可能影响 C。这就是 \(N^2\) 复杂度的雏形。
- 问题: 假设一个
- 治 (Conquer): 我们将这个大问题分解。
PayrollCalculator(只因 A 而变)EmployeeRepository(只因 B 而变)EmployeeReporter(只因 C 而变)
- 合 (Combine): 通过清晰的接口将它们组合起来,完成完整的业务。
所以在代码级别,SRP 就是分治思想在管理变更复杂度这个特定场景下的应用。 它的分是以"变更的理由"为边界,把不同变更轴心上的逻辑(职责)隔离开,从而实现高内聚、低耦合,降低代码的认知和耦合复杂度。
在系统级别(特别是大型企业应用),我们面对的问题是什么?是业务的规模和语义的模糊性。当一个系统大到需要几十上百人协作时,最大的问题不再是"变更理由",而是"我们说的'客户'是同一个东西吗?"
- 销售团队的客户 (Customer):有购买意向的潜在个体。
- 客服团队的客户 (Customer):有服务工单的已注册用户。
- 财务团队的客户 (Customer):有付款记录的法律实体。
如果试图建立一个统一的 God Model
来满足所有人,这个模型将变得无比复杂、充满
if-else,并且对所有人来说都是错的。
领域驱动设计(DDD)提出的限界上下文(Bounded Context)就是来解决这个问题的。
分 (Divide): 如何分?BC 告诉我们,业务的领域边界和团队的组织边界就是你分的边界。
- 问题: 试图用一个统一模型描述整个企业的业务。
- 复杂度: 语义冲突(Semantic Conflict)和组织沟通的开销(\(N^2\) 沟通路径)。
治 (Conquer): 我们将这个大领域分解为多个子领域。
- 销售上下文 (Sales Context): 在这个边界内,客户模型只包含销售所需的属性。
- 客服上下文 (Support Context): 在这个边界内,客户模型只包含服务所需的属性。
- 财务上下文 (Billing Context): 在这个边界内,客户模型只包含账务所需的属性。
合 (Combine): 通过明确的上下文映射图(Context Map),比如防腐层(ACL)或开放主机服务(OHS),来定义这些上下文之间的关系。
在系统级别,BC 就是分治思想在管理业务和语义复杂度这个特定场景下的应用。 它的分是以"语义一致性"为边界,把庞大的、模糊的业务领域分解为多个边界清晰、语义明确的子域,从而让每个子域(微服务)内部实现高内聚、低耦合。
真正的分治
坦白说,目前我在系统级别层面的分治能力还较为欠缺,这方面还需要更多的沉淀和学习,所以现在我还无法做更进一步的阐述。但是这里我想通过我过去工作中的一个例子,来尝试阐述一下我所认为的真正的分治。
在我所负责的游戏业务中,我们有一个接口负责游戏结算的,它所包含的需求(部分)功能大概如下:
它要负责多款联机游戏模式的结算逻辑,即要计算成绩、保存成绩、更新历史荣誉,还要涉及师徒系统、任务系统的各个加成、奖励和活跃度更新,有时候还要涉及各种运营活动的发奖逻辑(而且它们发的奖励要在结算接口返回给客户端,不能纯异步)。
HTTP 层简化的代码如下:
1 | func (api *Api) Settle(c *gin.Context) { |
光这一层就存在了非常多的问题,具体来说:
混杂了三个抽象层次
HTTP 层:参数绑定、响应构建
业务编排层:模式判断、流程控制
业务执行层:计分逻辑、事件发布、任务检查
职责过载(至少 5 个职责)
HTTP 请求处理
参数验证和解析
业务模式路由
副作用管理(事件发布、任务通知)
响应构建
业务逻辑层就更夸张了,几百行的意大利面条代码,这里我就不贴了,你可以想想得到,里面就是平铺直叙写把业务要的逻辑一行行实现起来。你可以会说,我把他们都抽成一个个函数,这样不就可以了吗?比如:
1 | func (api *Api) processGameMode1(ctx context.Context, score *Score) map[string]interface{} { |
看起来"分"了,但这种拆分没有实现"治理",只是把混乱从一个地方搬到了五个地方。
❌ 无法独立理解:必须看完整流程才能理解每个函数
❌ 无法独立测试:每个函数都依赖上下文
❌ 无法独立修改:改一个函数会影响其他函数
❌ 无法独立复用:函数与特定流程强耦合
那怎样才算是真正的治理呢?我们可以从 4 个维度进行思考:
可独立理解(认知治理)
可独立修改(演化治理)
可独立验证(测试治理)
可灵活组合(组合治理)
好的架构让复杂度可控 —— 不是消除复杂度(业务本来就复杂),而是让复杂度在每个局部都是可管理的。
首先我们看认知治理:每个单元可以独立理解。
1 | // ❌ 无法独立理解(当前代码的问题) |
再来看演化治理:每个单元可以独立修改。
1 | // ❌ 无法独立修改 |
再来看测试治理:每个单元可以独立验证。
1 | // ❌ 无法独立验证 |
最后看组合治理:整体可以灵活组装。
1 | // ❌ 无法灵活组合 |
这里我给一个分治后的架构供各位读者参考:
1 | 第1层:接口隔离 |
好处显而易见:
- 职责彻底分离:每个 Processor 只做一件事,15-30 行代码就能看清楚逻辑。
- 可组合性:底层的业务逻辑层和领域服务层可以复用给各个不同的游戏模式。
- 可测试性:每个单元都非常小,依赖尽可能少,测试难度大大降低。
- 性能可观测性:管道可以实现自动记录每个 Processor 的耗时,可以精准定位性能瓶颈。
- 错误隔离:任何一个 Processor 失败,都能清晰知道是哪个环节出问题
- 并行优化:如果某些 Processor 之间没有依赖,可以并行执行。
[!IMPORTANT]
总结一下,"分"只是手段,"治"才是目的的深刻含义:
不要为了拆分而拆分 —— 如果拆分后没有提升治理能力,那就是过度设计。
拆分的目标是治理 —— 每次拆分都要问:这样拆是否让问题更容易控制?
治理的四个标准:
可独立理解(认知治理)
可独立修改(演化治理)
可独立验证(测试治理)
可灵活组合(组合治理)
好的架构让复杂度可控 —— 不是消除复杂度(业务本来就复杂),而是让复杂度在每个局部都是可管理的
游戏结算接口的例子完美诠释了这一点:不是要把 800 行代码拆成 80 个函数,而是要把不可控的复杂度转化为可控的、独立的、可组合的单元。这才是真正的"治理"。
分层
分层和分治看起来很像,不过在我看来它们的侧重点还是有所不同的。在我看来,分治面临的是一个问题规模过大,导致单个处理单元(人、CPU、服务)无法在有效时间内解决,或者逻辑过于复杂以至于无法一次性正确实现。它的思路是分解、解决和合并。而分层面临的问题是系统的各个部分过度耦合。当一个模块的实现细节(比如换个数据库)会影响到另一个模块(比如 UI 界面)时,系统就变得僵化和脆弱。概括来说:
- 分治侧重于高内聚,其原则是按单一变更理由(SRP)将逻辑聚合到同一单元。
- 分层侧重于低耦合,其原则是按技术关注点(SoC)管理依赖方向,隔离实现细节。
OK,我们还是尝试回归到第一性原理上:
[!important]
分层到底"分"的是什么呢? —— 变化速率。
分层的最终目的其实是隔离变化。一个好的分层设计,其核心标准是:当系统的一部分发生变化时,其他部分应该尽可能少地受到影响。要做到这一点,不仅仅是画出几个框框然后把代码扔进去那么简单。这需要一套严格的原则和实践。
做好分层,关键在于回答三个问题:① 按什么标准分? ② 层与层如何对话? ③ 谁能依赖谁?
分层的原则
原则一:按什么分?以变化的速率作为切分标准
这是最根本的原则。为什么表现层和数据访问层要分开?因为 UI 界面(颜色、布局)变化的频率和原因,与数据存储方式(用 MySQL 还是 PostgreSQL)变化的频率和原因是完全不同的。
- 高内聚: 把变化原因和速率相近的代码放在同一层。例如所有处理 HTTP 请求、解析 JSON、参数校验的代码,都属于表现层的职责,它们一起变化。
- 低耦合: 变化速率不同的代码,应该被坚决地隔离在不同的层。
很多失败的分层,是因为分错了。例如,在业务逻辑层(Service)里,既有核心业务规则(订单总价
> 100 才能免运费),又混杂着数据格式的转换(把 Entity
转成 DTO)。核心业务规则(免运费策略)可能几个月不变,而
DTO(返回给 App 的 JSON
格式)可能每周都在变。把它们混在一起,就违反了按变化速率切分的原则。
原则二:谁依赖谁?依赖倒置原则
这是做好分层的关键。相信不少读者跟我一样,在一开始学习
MVC 架构的时候,都是遵循传统的朴素分层:表现层 → 业务层 →
数据层。这种依赖是具体的,即表现层直接依赖业务层的具体实现;业务层直接依赖数据层的具体实现。例如,UserService
直接
new UserRepositoryImpl())。它的问题在于业务逻辑层(高层策略)依赖了数据访问层(底层细节)。当底层细节(如数据库实现)更换时,业务逻辑层也可能需要修改。
而依赖倒置就不一样了,它的操作过程大致如下:
- 高层(业务逻辑层)定义需求方接口(Interface)。例如:
UserService定义一个IUserRepository接口,接口中声明它需要的方法,如User GetUser(string id)。 - 高层(业务逻辑层)只依赖这个需求方接口。
UserService的代码只认识IUserRepository,完全不知道数据库、Redis 或什么Impl的存在。 - 低层(数据访问层)去实现这个需求方接口。
UserRepositoryImpl实现IUserRepository接口。 - 通过依赖注入将具体实现注入给高层。
系统的核心价值在于其业务规则(高层策略),而不是它用什么数据库(底层细节)。因此,策略不应该依赖细节,而应该是细节依赖于策略。这才是分层的精髓:保护高价值的业务逻辑不受低价值的实现细节的污染。
原则三:层与层如何对话?严格的接口与封装
层与层之间绝对不能越级访问或泄露实现细节。上层只应该知道它所需要的最小接口。当数据需要跨越层的边界时,使用数据传输对象(DTO / VO / PO)来传递,而不是直接传递内部实现。
在简单业务中,这可能看起来很繁琐,但这是保持分层纯洁性的代价,需要权衡,没有绝对的答案。
分层坏味道
在我的工作过程中,曾经见到过不少的坏分层,导致各种循环依赖、层次混乱,被它们折磨够呛,我将它们进行简单总结,如果在你的代码中也发现了这些情况,那可能就需要引起重视了。
- 泄露的抽象:业务逻辑层(Service)向上(Controller)返回了一个数据库 ORM 的实体对象。这逼得 Controller 被迫知道了"数据库长什么样",表现层和数据层被耦合了。
- 层跳跃:Controller 为了图方便,绕过了 Service,直接调用了 Repository 来获取数据。短期内看似更简洁,实际上导致了业务逻辑被架空。未来如果这个获取数据需要增加权限校验或缓存逻辑(本应在 Service 层做),Controller 里的这处调用就会被遗漏。
- 胖瘦不均:要么是 Service
层非常"瘦",里面没有任何业务逻辑(或干脆没有 Service
层),只是简单地调用 Repository 的
save()、get()。所有的业务逻辑(如校验、计算)都堆积在 Controller 层。要么一个 GodService 类包含了上万行代码,处理了几十种不相关的业务。这违反了高内聚原则,分层失去了意义。 - 依赖反向:Repository 反过来
import了 Service/Controller 的代码。这是最痛苦的,这会造成循环依赖,这在逻辑上是致命的,说明职责划分彻底混乱。
分层的典范
在现代软件工程中,洋葱架构或整洁架构(Clean Architecture)是依赖倒置原则的最佳实践。

如上图所示,它将分层想象成一个洋葱:
最中心:领域实体 (Entities)
企业级的核心业务规则,最稳定,变化最少。
第二层:用例/应用服务 (Use Cases / Application Services)
具体的业务流程,编排“实体”来完成一个操作(例如“用户注册”用例)。
第三层:接口适配器 (Interface Adapters)
Controller、Presenter、Repository的实现。它们是“翻译官”。最外层:框架与驱动 (Frameworks & Drivers)
Web 框架 (Gin, Spring)、数据库 (MySQL)、UI (Web) 等。
这个架构的唯一规则:依赖箭头永远指向内部。
Controller(外) 依赖Use Case(内)。Repository(外) 实现Use Case(内) 定义的接口。
通过这种方式,最核心的业务逻辑(Entities 和 Use Cases)完全不知道外部世界有 Web、有 MySQL 的存在。你可以把 Web 替换成命令行,把 MySQL 替换成内存数据库,而中心的业务代码一行都不用改。
这,就是做好分层的终极目标:保护核心业务逻辑,让其独立于外部实现细节而存在。
分层的实践
在软件工程出现之前,分层早已是系统工程的基石。所以这一小节,我想借这个机会,梳理一下我们司空见惯的那些计算机核心技术和编程语言(Go/Rust),它们在哪些地方都用到了分层的思想。
网络协议
最经典的分层实践就是 OSI 七层协议了,如下图所示。
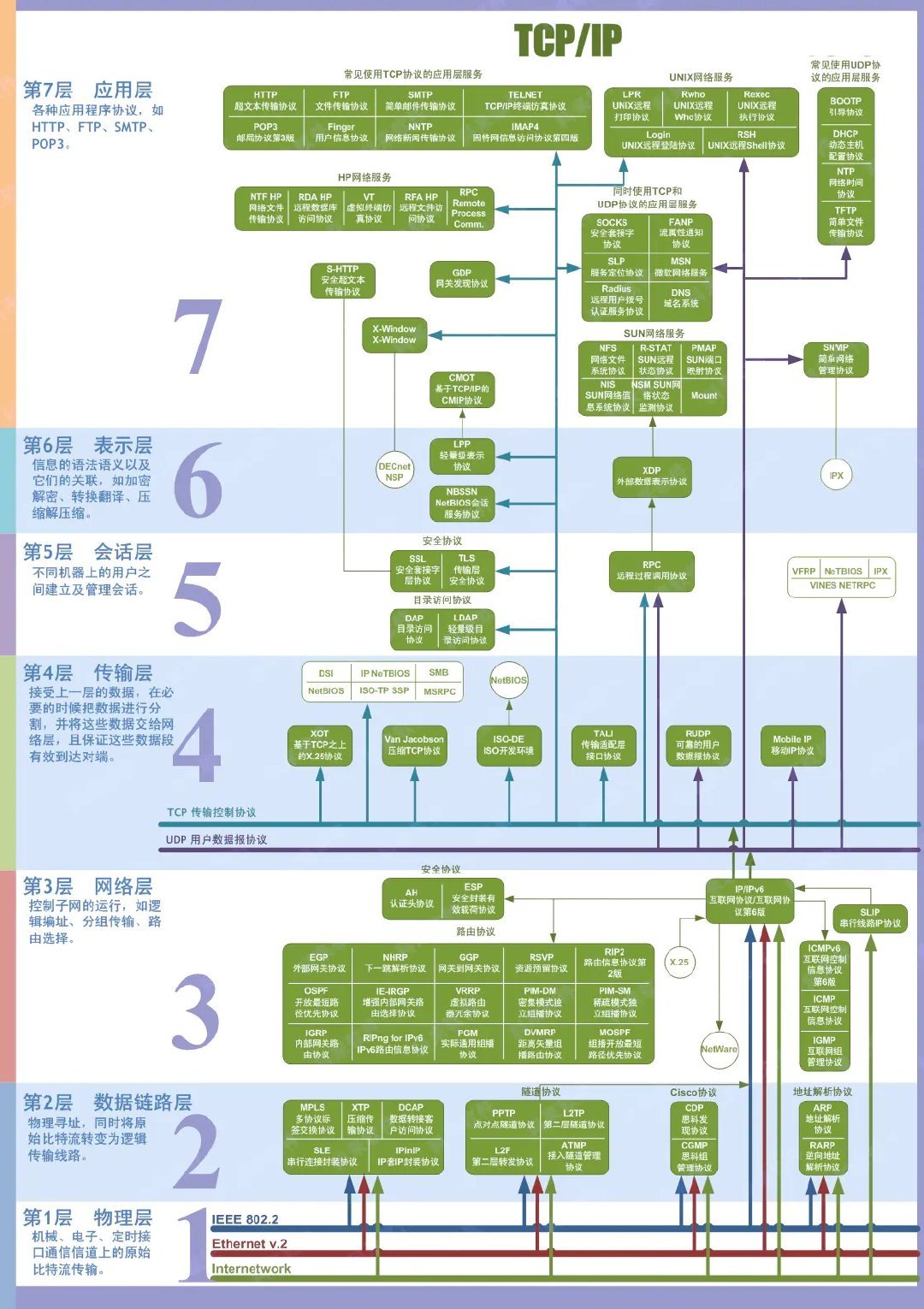
在实践中,TCP/IP 四层协议对其进行了简化:
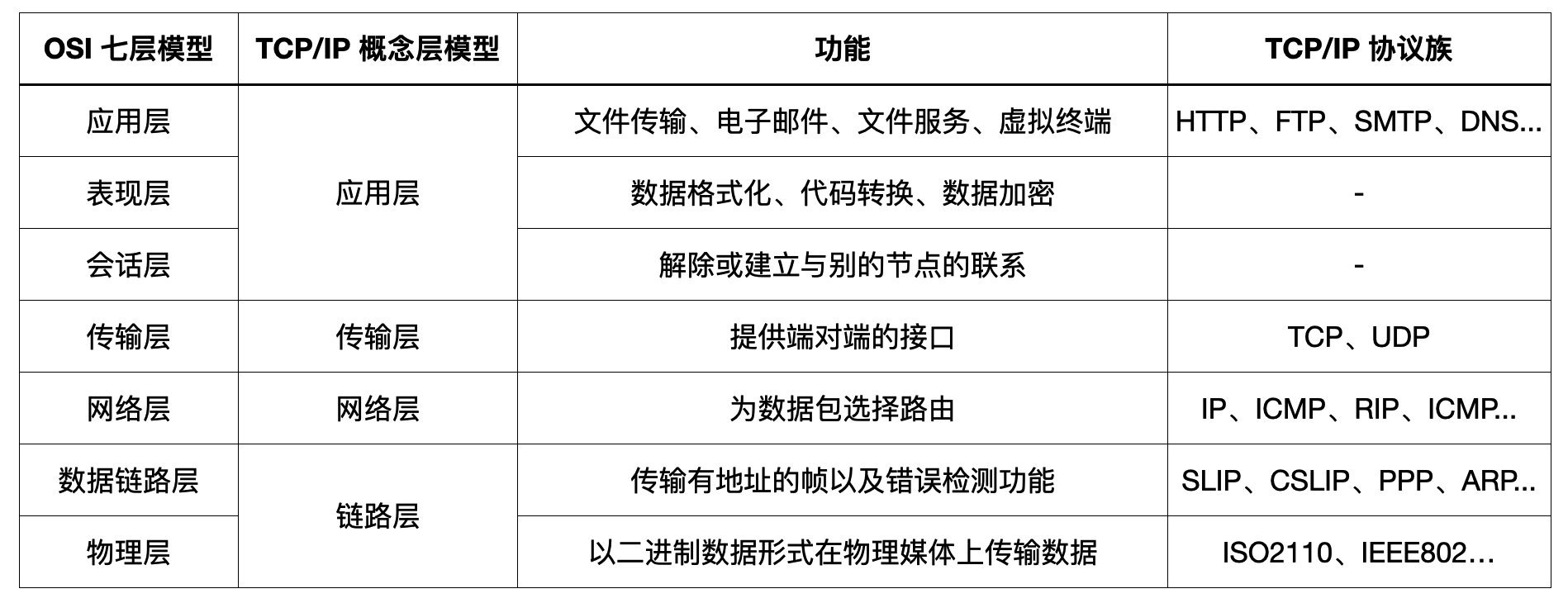
TCP/IP 四层协议完美践行了关注点分离(SoC):
- 应用层
(HTTP):只关注应用数据的语义(比如
GET /user这个请求)。 - 传输层 (TCP):只关注进程到进程的可靠性(如三次握手、丢包重传)。
- 网络层 (IP):只关注主机到主机的路由寻址。
- 数据链路层 (Ethernet):只关注物理帧的相邻传输。
并且它也严格执行了单向依赖的原则,上层(如 HTTP)依赖下层(TCP)提供的可靠字节流服务。但 TCP(下层)完全不认识(也不依赖)HTTP。这种分层带来的低耦合是革命性的:
- 我们可以在不修改 TCP 和 IP 的情况下,发明新的应用层协议(如 WebSocket,gRPC)。
- 我们也可以在不修改 HTTP 和 TCP 的情况下,将网络层从 IPv4 无缝升级到 IPv6。
操作系统
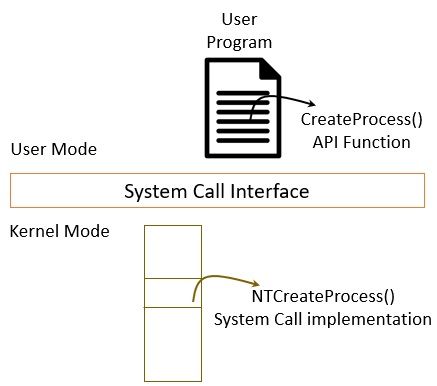
操作系统的用户态和内核态也是分层的杰作。
- 用户态 (User Mode): 关注业务逻辑(例如,我们用 Go 编写 Web 程序)。
- 内核态 (Kernel Mode): 关注硬件资源管理(如进程调度、内存分配、I/O 驱动)。
它们之间的层就是系统调用接口 (System Call Interface)。我们的 Go 程序(上层)通过系统调用请求 I/O,它不需要(也不知道)内核(下层)是如何与 Intel SATA 驱动还是三星 NVMe 驱动的实现细节打交道的。这导致了我们的 Go 程序只依赖 Linux 内核这一层,因此它可以移植到运行在任何实现了 Linux 内核 API 的物理机器上,隔离了硬件这个易变的实现。
数据库系统
即使是一个单一的程序,比如我们常用的数据库系统 MySQL,其内部也是严格分层的。

- 查询解析/优化器 (Query Optimizer): 只关注 SQL 语句的语义和执行计划(如决定使用哪个索引)。
- 存储引擎 (Storage Engine) (如 InnoDB): 只关注数据的物理存取(如如何在 B+ 树上读/写、如何管理事务日志)。
它们之间通过存储引擎 API
这一层来通信。这种分层,使得 MySQL
可以可插拔地替换存储引擎。Query Optimizer(上层)不依赖
InnoDB(下层)的实现,它只依赖契约。这就是为什么 MySQL
既可以支持 InnoDB(事务型)也可以支持
MyISAM(非事务型)。
Go 网络编程
Go 的网络编程模型同样完美践行了关注点分离(SoC),下图自顶向下清晰地展示了这种分层:
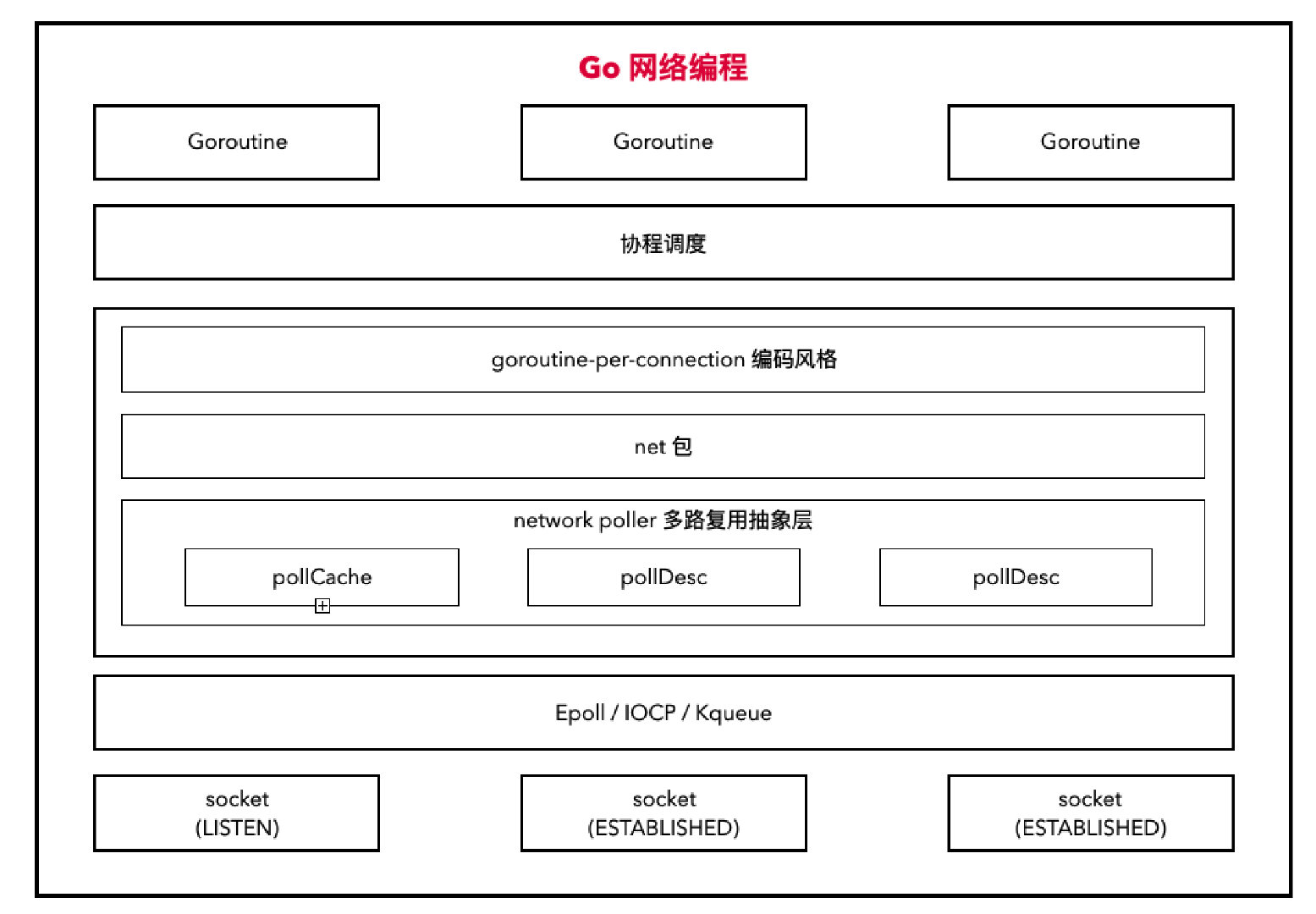
- L6: 业务层 (Goroutine & 编码风格):
只关注业务逻辑。开发者只需用同步阻塞的风格(如
conn.Read())编写业务。 - L5: Go 并发调度层 (GMP 调度器): 只关注 Goroutine
的并发调度。它隐藏了 L3(
netpoller)的 I/O 事件机制,当 L3 报告 I/O 就绪时,它(GMP)负责唤醒对应的 L6(Goroutine)。 - L4: Go 协议层 (net 包): 只关注 TCP/UDP/HTTP
等网络协议的实现,并提供了平台无关的 API(如
net.Conn)。 - L3: Go Runtime 适配层 (network poller):
只关注跨平台 I/O 多路复用。它封装(Wrapping)并屏蔽了
L2(
epoll/kqueue/iocp)的平台差异。 - L2: OS I/O 机制层 (epoll/kqueue/iocp): 只关注高性能 I/O 事件的通知机制。
- L1: OS 协议/资源层 (socket): 只关注传输层协议(TCP/UDP)的内核实现和资源管理(文件描述符)。
并且它也严格执行了多重的单向依赖原则:
- L6(业务)依赖 L5(GMP)提供的并发能力。
- L5(GMP)依赖 L3(netpoller)提供的 I/O 就绪通知。
- L4(net 包)依赖 L3(netpoller)提供的跨平台 I/O 能力。
- L3(netpoller)依赖 L2(epoll 等)提供的 OS 事件能力。
- L2(epoll 等)依赖 L1(socket)提供的资源。
这种分层带来的低耦合是革命性的:
- 开发者可以在不修改业务代码的情况下,享受 Go Runtime 团队对协程调度或 network poller 的性能优化。
- Go 团队也可以在不修改
net包的情况下,将network poller适配到 Linux 最新的io_uring,开发者无需改动任何代码即可获得性能提升。 - 最重要的是,开发者可以只关注
goroutine-per-connection这种同步的业务逻辑,而不必关心 Epoll/Kqueue 这些异步非阻塞的底层实现细节,极大地降低了高性能网络编程的认知负荷。
模块化
分治是在思维层面上将大问题拆分为多个小问题,而分层更多专注在技术层面上的关注点分离。那模块化呢?在我看来,模块化是将一个更加广泛的概念,它跟分治和分层一样,都是为了解决一个高复杂度问题所采取的抽象行为,只不过模块化它的产物更加具体化,比如拆分成一个个的微服务、同一个系统内部的多个 module/package,或是具体到一个个负责不同职责的类。
可以理解为分层是模块化的一个特定应用,它按照技术职责进行模块化区分,如果 UI 层、接口层、业务逻辑层、数据访问层等。而分治的某些场景下的落地实现就是模块化,比如微服务的拆分、业务系统不同组件的拆分等。
在我看来,模块化的终极目标就是老生常谈的:高内聚、低耦合。
- 高内聚:一个模块只做一件事,并把它做好。
- 低耦合:模块之间的互不依赖,只通过接口进行交互。
而要做好模块化,主要是要做好两步:
- 封装:隐藏秘密。把自己的内部实现(私有函数、辅助函数)藏好。
- 接口:做出承诺。只对外暴露一个清晰、稳定、最小化的接口(契约),告诉别人我能做什么。
模块化的实践
硬件与计算机体系结构:总线与 PCle
在电脑的主板上,CPU、内存、显卡(GPU)、硬盘(SSD)都是独立的模块。
- 接口:它们通过统一的总线(如 PCle)进行通信。PCle 就是一个标准化的接口。
- 封装:NVIDIA 只需要按照 PCle 接口规范设计显卡,它不知道知道 Intel 的 CPU 如何工作,Intel 的 CPU 也不需要知道显卡内部是如何渲染图形的。
- 高内聚:显卡高度内聚,只负责图形处理。
- 低耦合:这使得我们可以随意插拔、更换不同厂商的显卡或 SSD(只要接口兼容),而系统其他部分完全不受影响。
操作系统:从驱动程序到微内核
操作系统是模块化设计的殿堂。它面临的第一个史诗级挑战就是:世界上有成千上万种硬件(网卡、显卡、磁盘),操作系统如何支持它们,而不让自己崩溃?if else 肯定是行不通的道路,那 Linux 给出的答案就是驱动程序架构。
- 模块:硬件驱动程序(如 NVIDIA 显卡驱动、Intel 网卡驱动)
- 接口:由操作系统内核(如 Linux
Kernel)定义的一组标准化的函数调用。例如,块驱动设备必须实现
read、write、ioctl等接口;网络驱动必须实现open、stop、xmit等接口。 - 封装:
- OS 内核的封装:NVIDIA 不需要知道 Linux 进程调度器和 VFS(虚拟文件系统)的内部实现。它只需要知道内核提供的网络设备接口长什么样。
- 驱动的封装:Linux 内核不需要知道显卡芯片是如何通过 CUDA
核心进行计算的。内核只关心一件事:我已经把数据包给你了(调用
xmit接口),请你把它发出去。
- 高内聚/低耦合:内核与驱动是极端的低耦合。我们可以随意更新显卡驱动,而无需重新编译整个内核系统。反而,内核升级时,只要不改变驱动接口(保持 ABI 稳定),老的驱动模块就可以继续工作。
计算机网络:TCP/IP 协议栈
我们之前提到的 OSI 七层协议和 TCP/IP 四层协议,即是分层的完美实践体现,也是模块化的典范。协议栈中的每一层就是一个模块,它们之前都定义了数据传递接口,使得每一层的关注点分离,从而实现了高内聚低耦合。
数据库系统:SQL 与存储
数据库系统也是一样的,以 MySQL 为例,可插拔存储引擎架构就是模块化的完美体现。
- 模块:存储引擎(如 InnoDB、MyISAM)和 SQL 解析/优化器(Server 层)。
- 接口:MySQL 定义了一套存储引擎 API。任何存储引擎,只要实现了这套标准接口,就可以被集成为 MySQL 中。
- 封装:
- SQL 层的封装:优化器(Server
层模块)只负责生成最优的执行计划。它不需要知道 InnoDB 是如何实现 MVCC
的,也不需要知道 MyISAM 是如何存储索引的。它只需要通过接口手:请你从
idx_user_name索引中取出数据。 - 引擎的封装:InnoDB 模块(存储引擎)只负责管理数据页、事务日志、锁。它不需要知道 SQL 是如何被解析和优化的。
- SQL 层的封装:优化器(Server
层模块)只负责生成最优的执行计划。它不需要知道 InnoDB 是如何实现 MVCC
的,也不需要知道 MyISAM 是如何存储索引的。它只需要通过接口手:请你从
- 高内聚/低耦合:Server 层和 Storage Engine 层是两个高度解耦的模块。Server 层高度内聚,只负责 SQL 解析、优化、网络连接;InnoDB 高度内聚,只负责事务和存储。这完美将"如何解析和优化 SQL"和"如何存储和管理数据"这两个核心且复杂的关注点进行彻底分离,使得它们可以独立演进而互不干扰。
Redis:插件系统
Redis Modules 同样的模块化运用的典范。
- 模块:可加载的 .so 动态库(如 RediSearch、RedisJSON、RedisGraph)。
- 接口:
redismodule.h头文件。Redis 核心暴露了一整套 C API,允许模块向 Redis 注册新明了、操作内部数据结构、甚至实现新的数据类型。 - 封装:
- Redis 核心的封装:RediSearch 模块(全文搜索引擎)不需要知道 Redis 是如何处理网络事件循环或 RDB 快照的。它只需要通过 API 说:请帮我注册一个 FT.SEARCH 命令。
- 模块的封装:Redis 核心完全不知道 RediSearch 内部是如何构建倒排索引的。它只知道 RediSearch 是一个可加载的黑盒模块。
- 高内聚/低耦合:Redis 通过 Modules API 将核心 K-V 功能与扩展功能完美解耦。这既保证了核心的轻量与稳定,又提供了无限扩展性。
Kafka:管道与插头的分离
Kafka 的核心(Borker)是一个高内聚的模块,它只做一件事:高吞吐、可持久化的日志系统。但 Kafka 面临的挑战是:数据如何流入(例如从 MySQL Binlog),又如何流出(例如到 S3)?如果让 Kafka 核心团队去写所有这些连接器,他们包顶不住的,核心系统也会变得异常臃肿。那 Kafka 给出的答案就是 Kafka Connect 框架。
- 模块:Connect
框架作为主模块,负责所有脏活累活,如容错、偏移量提交、并行化、REST
API。Connecor 作为子模块,如
debezium-connector-mysql是一个 Source 模块,kafka-connect-s3是一个 Sink 模块。 - 接口:Kafka Connect 定义了一组 API,如 SourceConnector、SinkConnector、Converter 等 Java 接口。
- 封装:
- Kafka 核心的封装:
debezium-connector-mysql模块不需要知道 Kafka Broker 是如何实现 Raft 协议或管理磁盘 Log 文件的。它只需要通过接口说:请把这个 Change Event(数据)发送到 mysql-binlog topic。 - Connector 的封装:Kafka Broker 核心完全不知道 Debezium 是如何通过伪装成 MySQL 从库来读取 binlog 的。Broker 只认识标准的接口数据。
- Kafka 核心的封装:
- 高内聚低耦合:这种模块化使得 Kafka Broker 高度内聚,只负责高吞吐、可持久化的日志系统。所有与外部系统的集成全部被解耦到了 Connect 模块中,这使得 Kafka 成为了一个万能插座,任何系统都可以通过编写一个 Connector 模块来接入。
RAG 与 AI Agent:天生的模块化
LLM 作为一个封闭的大脑,它不会使用工作,也没有长期记忆,更不知道我们私有的一些内部文档和资料。为了 AI 能更好的服务我们的实际需求,RAG 和 AI Agent 应运而生。在我看来,RAG 和 AI Agent 的架构天生就是模块的。
RAG 最主要就是两个模块:
- Retriever(检索器模块):只负责根据查询从知识库检索相关文档
- Generator(生成器模块,即 LLM):只负责根据给定的上下文和查询生成答案。
这使得我们可以随意替换不同的向量数据库、检索策略和 LLM。
AI Agent 最主要的是三个模块:
- Orchestrator(协调器模块 )只负责解析 LLM 意图、循环执行。
- LLM(大脑模块):只负责思考和选择工具。
- Tools(工具模块):只负责执行一个具体的任务并给出结果。
LLM 不需要知道工具是如何实现 API 调用的,它只知道这个工具的接口描述。这使得你可以无限地插拔新工具,赋予 AI Agent 无限想象的新能力。
术:构建与设计的指导框架
SOLID 原则
SOLID 原则由 Robert C. Martin (Uncle Bob) 提炼并推广,如果想要理解并运用好这五大原则,核心不在于我们把它们背诵得多么熟练,也不在于我们能多快速地识别现有代码符不符合哪些原则,关键是要将它们看成一个整体,去思考它们背后到底是在解决什么问题。
当我们聊 SOLID 原则时,我们不是在谈论五条独立的规则,而是在谈论一个统一的核心思想:在面向对象 (OOP) 范式下,如何科学地管理依赖关系,以应对软件的复杂性和持续不断的变化。
当然,在非严格 OOP 编程语言上,也是可以借鉴类似思想的,如 Go 的 struct/interface 和 Rust 的 struct/trait。
一个软件系统的生命周期中,最大的成本不是来自“首次开发”,而是来自“持续维护”——即修复 Bug、修改功能和添加新功能。
一个腐化的软件系统(高耦合、低内聚)在面对变化时,会表现出两个致命特征:
- 僵化性 (Rigidity):改动一个地方很困难,因为它牵连着许多其他模块。
- 脆弱性 (Fragility):改动一个地方,导致系统中许多不相关的地方出现了意料之外的 Bug。
SOLID 原则就是一套组合拳,它们共同的目标是创建高内聚、低耦合的模块化结构,从而战胜这两种特征。最终产出的系统应该是:
- 易于修改的 (Flexible):添加新功能时,对现有代码的影响最小。
- 易于理解的 (Understandable):模块边界清晰,职责单一。
- 易于测试的 (Testable):模块可以被独立地隔离和测试。
单一职责原则 (SRP - Single Responsibility Principle)
- 它解决了什么: 模块的"边界"问题。
- 它的角色: 解耦的起点。
- 逻辑: 它强制我们进行拆分。它定义了一个模块(在 OOP 中通常是 Class,Go/Rust 里面是 struct)应该具有高内聚性。高内聚意味着只为一个变化的原因而存在。如果一个类混合了业务逻辑、数据持久化和日志记录,那么这三个变化的原因中任何一个发生,都可能破坏这个类。SRP 通过拆分,首先在微观上隔离了变化。
开放封闭原则 (OCP - Open/Closed Principle)
- 它解决了什么: 系统的"扩展"问题。
- 它的角色: 解耦的目标。
- 逻辑: 这是 SOLID 的核心目标。它指出系统应该对扩展开放,对修改封闭。这意味着当新需求(变化)到来时,我们应该通过添加新代码(例如实现一个新类)来完成,而不是通过修改旧的、已验证的代码。
- 关键问题: OCP 只是一个目标,它没有说 如何 做到。SRP 拆分了模块,但 OCP 告诉我们这些模块之间必须依赖抽象,而不是具体实现。
里氏替换原则 (LSP - Liskov Substitution Principle)
- 它解决了什么: 抽象的"可靠性"问题。
- 它的角色: 实现 OCP 的基石。
- 逻辑: OCP 依赖于抽象(如接口或基类)和多态。LSP
提供了实现多态的正确性规范。它确保任何子类(具体实现)都必须能够替换其父类(抽象)而程序的行为不发生任何改变。如果一个子类的实现违反了父类的约定(例如,一个
Square类继承Rectangle,并重写了setHeight方法导致其Width也发生变化),那么这个抽象就是不可靠的。 - 作用: LSP 是保证 OCP 得以实现的行为契约。没有 LSP,抽象就毫无意义,对修改封闭也就无从谈起。
接口隔离原则 (ISP - Interface Segregation Principle)
- 它解决了什么: 抽象的"粒度"问题。
- 它的角色: 降低依赖的成本。
- 逻辑: 即使我们有了 OCP(依赖抽象)和 LSP(抽象可靠),但如果这个抽象(接口)本身非常臃肿,它会强迫客户端(使用者)依赖它们根本不需要的方法。这种不必要的依赖会造成耦合。
- 作用: ISP 告诉我们,抽象应该精细化、客户化。它本质上是 SRP 在接口设计上的应用。它通过拆分大接口,确保了依赖关系的最小化和精准化。
依赖倒置原则 (DIP - Dependency Inversion Principle)
- 它解决了什么: 依赖的"方向"问题。
- 它的角色: 解耦的架构蓝图。
- 逻辑: 这是 SOLID
的最高层指导。它规定了系统中所有依赖关系的方向。
- A. 高层模块(如业务策略)不应依赖低层模块(如数据库实现)。
- B. 两者都应依赖于抽象(如接口)。
- 作用: DIP 将传统的"高层 -> 低层"的依赖关系,倒置 为"高层 -> 抽象"和"低层 -> 抽象"。这使得系统的核心业务逻辑(高层)完全独立于任何具体的实现细节(低层)。这是实现对修改封闭的最强有力的架构手段。这也是 DDD 和洋葱架构的典型实现。
总结
SOLID 原则提供了一套完整的、从微观到宏观的解耦策略:
- SRP 负责创建高内聚的模块。
- OCP 设定了依赖抽象的最终目标。
- LSP 保证了这些抽象的实现是可靠和可替换的。
- ISP 保证了这些抽象本身是精简和低耦合的。
- DIP 最终定义了整个系统的架构,确保了依赖关系朝向正确的(即稳定的)方向。
设计模式
设计模式清单
创建型模式 (Creational Patterns):这些模式提供了不同种类的对象创建机制,使得一个系统在运行时可以选择其中的一个适当的创建方法来创建对象。
- 单例模式 (Singleton Pattern):确保一个类只有一个实例,并提供全局访问点来访问该实例。
- 工厂模式 (Factory Pattern):定义一个用于创建对象的接口,让子类决定实例化哪个类来创建对象。
- 抽象工厂模式 (Abstract Factory Pattern):提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
- 建造者模式 (Builder Pattern):将一个复杂对象的构造与其表示分离,使得同样的构造过程可以创建不同的表示。
- 原型模式 (Prototype Pattern):通过复制现有的实例来创建新实例。
结构型模式 (Structural Patterns):这些模式描述如何将类或对象组合成更大的结构,以满足特定的需求。
- 适配器模式 (Adapter Pattern):将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
- 桥接模式 (Bridge Pattern):将抽象部分与它的实现部分分离,使得它们都可以独立地变化。
- 装饰器模式 (Decorator Pattern):动态地给一个对象添加一些额外的职责。就增加功能而言,装饰器模式比生成子类更为灵活。
- 组合模式 (Composite Pattern):将对象组合成树形结构以表示“部分-整体”的层次结构。
- 外观模式 (Facade Pattern):为子系统中的一组接口提供一个一致的界面,该模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
- 享元模式 (Flyweight Pattern):运用共享技术有效地支持大量细粒度的对象。
- 代理模式 (Proxy Pattern):为其他对象提供一种代理以控制对这个对象的访问。
行为型模式 (Behavioral Patterns):这些模式涉及到算法和对象间职责的分配,并描述了在对象之间的通信模式。
- 责任链模式 (Chain of Responsibility Pattern):使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。
- 命令模式 (Command Pattern):将请求封装成对象,从而让你使用不同的请求、队列或者日志来参数化其它对象。命令模式也可以支持撤销操作。
- 解释器模式 (Interpreter Pattern):给定一个语言,定义它的文法的一种表示,并定义一个解释器,该解释器使用该表示来解释语言中的句子。
- 迭代器模式 (Iterator Pattern):提供一种方法顺序访问一个聚合对象中的各个元素,而又不暴露该对象的内部表示。
- 中介者模式 (Mediator Pattern):用一个中介对象封装一系列的对象交互。中介者使得各个对象之间不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
- 备忘录模式 (Memento Pattern):在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可以将该对象恢复到原先保存的状态。
- 观察者模式 (Observer Pattern):定义了对象之间的一对多依赖关系,这样一来,当一个对象改变状态时,它的所有依赖者都会收到通知并自动更新。
- 状态模式 (State Pattern):允许对象在内部状态改变时改变它的行为,对象看起来似乎修改了它所属的类。
- 策略模式 (Strategy Pattern):定义一系列算法,把它们一个个封装起来,并使它们可以相互替换。本模式使得算法的变化可独立于使用它的客户端。
- 模板方法模式 (Template Method Pattern):定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法结构即可重定义该算法的某些特定步骤。
- 访问者模式 (Visitor Pattern):表示一个作用于某对象结构中的各元素的操作,它使你可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
设计模式的代码实战可参考:https://github.com/hedon954/go-designmode
理解设计模式
看完前面梳理的 23 种设计模式,相信大多数人跟我一样头都大了,即便我已经做了简单的分类。我一直在思考如何更好地理解和运用设计模式,从而写出更加优雅的代码。AI 的出现,真的让我感觉非常幸运,AI 可以很好地从第一性原理和根本源头上对设计模式进行展示和阐述,所以在我跟 AI 进行深入探讨之后,我对设计模式的理解又更进一步了,这里做一下简单总结。
从第一性原理出发,当我们谈论设计模式时,我们主要在谈论两件事:
- 一个共享的词汇库:设计模式提供了一套高带宽、无歧义的专业词汇,它让我们谈论复杂抽象的方案时,就像谈论变量或函数一样简单。
- 一套经验的结晶:设计模式就是把这些被反复验证、证明是健壮的、优雅的解决方案提取出来,并给它们命了名。
所以,设计模式不是最佳实践的清单,而是在特定上下文 (Context)中,针对特定问题 (Problem)的一种解决方案 (Solution)。它本质上是前人经验的固化。
理解 23 种设计模式的最好方法,不是去背诵它们,而是去分类和抓意图。你不需要记住 23 种模式的实现细节,你只需要理解 23 种问题,以及它们分别属于哪一类意图。
创建型模式
如何才能在不暴露创建细节的情况下,灵活且可控地创建对象? —— 解耦对象的创建过程
- Singleton (单例模式):我需要保证这个类在整个应用程序中,有且仅有一个实例(比如,配置管理器、日志记录器)。
- Factory Method
(工厂方法):我有一个基类(或接口),但我不想让客户端(调用方)直接
new它的某个具体子类。我想把这个new的决定权推迟到子类去做。 - Abstract Factory
(抽象工厂):我需要创建一系列相互关联的对象(一个产品族,比如
UI的深色主题需要DarkButton、DarkCheckbox),并且我想一键切换整个产品族(比如一键切换到浅色主题)。 - Builder
(建造者模式):我要创建的这个对象太复杂了,它的构造函数有一大堆参数,其中很多还是可选的。我不想写一堆重载的构造函数,也不想让对象在创建过程中处于不完整状态。(在
Go 或 Rust 中可能更熟悉的是
Option模式,这是 Builder 的一种变体) - Prototype (原型模式):创建一个新对象的成本非常高(比如涉及 I/O 或复杂的计算)。如果我有一个已有的对象,通过复制(clone)它来创建新对象会快得多。
结构型模式
如何才能灵活地组合类与对象,形成更大的、功能更强的结构?—— 解耦对象的组合方式
- Adapter (适配器模式):我有一个现成的类(A),它的功能很棒,但我无法直接使用,因为客户代码要求的是另一个不兼容的接口(B)。我需要一个"转换插头"。
- Decorator
(装饰器模式):我想在不修改一个类(或对象)的代码的前提下,动态地给它添加新的功能(职责)。而且我想可以层层嵌套地添加(比如
Buffered->Gzipped->FileInputStream)。 - Proxy (代理模式):我不想让客户端直接访问某个对象。我想在中间加一层代理,来控制对这个对象的访问(比如,权限检查、懒加载、日志记录、RPC)。
- Facade (外观模式):我这里有一个非常复杂的子系统,内部有一堆类和复杂的调用关系。我只想给客户端提供一个极其简单的、统一的访问入口。
- Bridge
(桥接模式):我有两个独立变化的维度(比如形状和颜色)。我不想用继承(比如
RedCircle,BlueCircle,RedSquare… 导致类的爆炸),我想把这两个维度分开,让它们各自独立演化。 - Composite (组合模式):我需要处理一个树形结构(比如文件系统的文件和文件夹)。我希望能够用完全相同的方式(同一个接口)来对待单个对象(叶节点)和对象组合(分支节点)。
- Flyweight (享元模式):我需要创建海量的小对象,它们绝大多数的内部状态都是相同的。为了节省内存,我想把这些相同的状态共享(复用)起来。
行为型模式
如何才能高效地分配职责,并管理对象之间复杂的通信? —— 解耦对象间的通信与职责
- Strategy (策略模式):我有一堆
if...else if...else或者一个巨大的switch,它们在根据不同条件选择不同的算法或行为。我想把这些算法(策略)独立出来,让它们可以互相替换。 - Observer (观察者模式):我有一个"主题"对象,当它的状态发生变化时,需要自动通知其他所有依赖它的"观察者"对象,但我又不想让"主题"直接知道"观察者"的具体实现(实现广播式解耦)。
- Command (命令模式):我想把一个操作(请求)封装成一个对象。这样我就可以把这个"命令"传递、排队、记录日志,甚至实现撤销(Undo)。
- Template Method (模板方法):我有一个算法,它的骨架(步骤)是固定不变的,但其中一两个步骤的具体实现是易变的。我想在基类中定义好"骨架",让子类去实现那些"易变"的步骤。
- Iterator (迭代器模式):我有一个聚合对象(比如 List, Map, Set),我想让客户端能够遍历它,但又不想暴露它的内部实现细节。
- Mediator (中介者模式):我有一堆对象,它们之间互相通信,形成了一个复杂的网状结构(M-N 关系),导致高耦合。我想引入一个"中介",让所有对象只和"中介"通信(M-1-N),简化这个通信网。
- State
(状态模式):一个对象的行为完全取决于它的内部状态。我现在的代码里有一堆
switch在检查"当前状态"来决定下一步做什么。我想把每种"状态"下的行为封装成独立的类。 - Chain of Responsibility
(责任链模式):一个请求需要被多个对象中的某一个处理。但我不确定是哪一个,或者我想让它们依次尝试处理(比如
HTTP中间件)。我想把这些对象串成一条链,让请求沿着链传递下去。 - Visitor (访问者模式):我有一组稳定的对象结构(比如一个语法树),但我想为它们添加各种各样的新操作(比如类型检查、代码生成)。我不想每加一个操作就去修改那些稳定的对象类。
- Memento (备忘录模式):我需要保存一个对象的内部状态(创建快照),以便在未来某个时刻能恢复到这个状态(比如实现撤销或存档),同时我又不希望暴露这个对象内部的实现细节。
- Interpreter (解释器模式):我需要为一个简单的语言(比如正则表达式、SQL 查询)构建一个解释器。(这是最不常用的模式之一,通常有现成的工具)
用好设计模式
我觉得想要用好设计模式,只有一个途径,就是多用,甚至是刻意多用,也就是"手里拿着锤子,看什么都是钉子"那样的多用。用对了,你才能真实体验到设计模式给你带来的收益,你才会更理解它们的由来,你也才会更愿意在这方面花更多的思考和实践。用错了,发现过度设计了,发现代码变得更难理解和维护了,你才能真正感受到理论与实践的差距,你才能从另外一个角度去更全面理解你所运用的设计模式。当然,这种刻意多用,最好更多是在自己的个人项目中,而不是在工作项目上,因为后者的犯错成本要更高,风险也相应更大。当然,工作上的使用,总有第一次,所以不妨大胆一点,只要你是在思考,只要你是在努力做好事情,我觉得,一切都是不亏的。
我很庆幸在我刚入职两三个月的时候,就接手了重构一坨屎山代码的重任,并且在我使用模板方法设计模式对其进行彻底重构后,代码变得极其优雅并在后面的两年多中持续为我带来收益。这些体验和正反馈,让我对设计模式一直有一层滤镜,使得我这三年来一直愿意主动去思考如何将代码写得更加优雅。
这个项目是这样的,我们对接了 20 多个广告商,每个广告商下面有多个不同公司主体下的多个不同 APP,即存在 3 个维度,我们要去请求广告商的 API 去统一汇总所有 APP 的广告收入数据。之前的人开发的时候就是纯复制粘贴,重复代码直接爆了,而且相同步骤还存在非常多不一致的逻辑,这给代码阅读、问题排查、新增广告商/公司主体/APP、业务数据诉求等方面都带来了究极折磨。我发现其实所有广告数据获取都遵循这样一个步骤:请求数据、格式统一、合并数据、异常处理、转存数据。我发现只有请求数据和格式统一这两步是跟广告商 API 强相关且必须单独定制开发的,其他都是一样的逻辑。所以我就采用了模板方法设计模式,对这个流程进行了抽象和重构,并且由于骨架非常固定,我还顺带开发了代码生成 CLI 工具,进一步提高开发效率。就这样简单套用了一个设计模式,整个代码的风格和简洁度,焕然一新,又由于架构的简洁统一,使得后续的数据修复、问题排查、新增需求等操作都非常简单和高效高质量。
反面例子也有,我们组内其他同学在重构匹配服的时候,由于对接口定义理解的不足,同时对状态模式、策略模式的理解不足,但又强行套用,同时又有很多其他不必要的抽象操作,我称之为炫技。这一顿操作导致了我们的新匹配服过度抽象、接口定义不合理、架构混乱,进而导致了代码可读性较差、新人接手难度高等一系列问题。但是坦白说,这个失败的例子给我带来的收获和思考,并不比上面提到的成功的例子少。
"手里拿着锤子,看什么都是钉子"是我们刚接触设计模式时的通病,这往往会导致过度设计。我个人觉得想要减少"硬套"设计模式的核心原则是 :永远让问题驱动模式,而不是反过来。
- KISS (Keep It Simple, Stupid) 优先: 永远先写出最简单、最直白的代码。不要一开始就思考我该用哪个模式。
- YAGNI (You Ain't Gonna Need It) 原则:
不要为了未来可能的扩展性而去应用一个复杂的模式。如果现在简单的
if...else就能解决问题,并且没有明确的迹象表明它马上会变得复杂,那就用if...else。 - 把模式当作重构的手段: 这是应用模式的最佳时机。
- 你的简单代码跑起来了。
- 随着需求(变化)的到来,你的简单代码开始变得腐化。
- 此时,代码的坏味道已经清晰地暴露了问题。
- 现在,你才应该引入设计模式,作为一种重构手段,去解决这个已经实际发生的、而不是臆想出来的设计问题。
- 评估引入的成本: 没有任何模式是银弹。
- Factory 带来了灵活性,但也增加了类的数量。
- Observer 实现了完美的解耦,但也让程序的控制流变得难以追踪(回调地狱)。
- Singleton 简化了访问,但也引入了全局状态,使测试变得极其困难。
当你决定要套用一个模式时,必须明确地问自己:为了解决我眼前的这个问题,我是否愿意支付这个模式带来的额外复杂性的代价?
架构模式
什么是架构
架构这个词,很多人都在谈,那到底什么是架构呢?架构师又是做啥的呢?《P9 工作法:夯实技术硬实力、架构力和领导力》一书总结得非常好。
书中说,架构师就是运用技术架构的思维框架深入分析业务需求,识别关键问题,并通过持续的演进和迭代来提升系统能力,以支持业务实现商业成功。可以用两组词来表述架构的概念:模块与关系、过程与结果。
- 模块与关系:软件架构是由哪些模块组成,这些模块由哪些领域模型组成,每个模块的权责边界是什么,以及模块间如何协作。
- 过程与结果:软件架构是一个动词,代表一系列决策过程。这些决策主要从全局和未来视角出发,寻找解决实际问题的最佳架构。这就是“架构即过程”的含义。同时,软件架构也是一个名词,是技术解决实际问题、支撑业务发展的结果,也是不同角色进行协作的界面。
当我们聊架构设计的时候,我们其实是在谈论一个完整的生命周期,我将其概括为以下 6 个步骤:
- 理解商业与组织上下文: 我们在谈论深入挖掘利益相关方的真实诉求、明确用户核心痛点、对齐关键商业指标,并诚实评估我们团队现有的技术栈与组织能力。
- 定义架构特性与约束: 我们在谈论从性能、可用性、成本等众多特性中,识别出对本次设计最关键的 3-5 个,并清晰定义那些不可逾越的约束红线,以此作为后续所有技术权衡 (trade-off) 的核心基准。
- 探索方法与决策: 我们在谈论通过系统地探索多种可选方案、进行客观的利弊权衡与风险评估,最终做出理性的技术决策并将其(例如使用 ADR)沉淀为文档。
- 设计实施路径与验证机制: 我们在谈论如何将架构蓝图转化为可执行的实施计划,包括通过 PoC 验证关键难点、拆解任务与里程碑,并通过构建适应度函数来持续验证架构特性的落地。
- 部署、观测与效果衡量: 我们在谈论通过 CI/CD 将设计交付上线,并借助 APM 和业务指标监控来实时观测系统的运行状态与商业效果,以此获取最真实的反馈。
- 复盘、沉淀与演进: 我们在谈论对线上问题进行彻底的根因分析、将经验教训沉淀为改进后的流程与原则,最终推动人员与组织的共同成长,并为下一轮架构演进做好准备。
架构选择的两大原理
- 第一原理:一切都是权衡。
- 第二原理:为什么比如何更重要。
架构原则
- KISS (Keep It Simple, Stupid) 原则: 在所有解决方案中,优先选择最简单、最清晰的那一个。
- YAGNI (You Ain't Gonna Need It) 原则: 只实现你当前明确需要的功能,不要为"未来可能的需求"编写代码。
- DRY (Don't Repeat Yourself) 原则: 确保系统中的每一处知识(逻辑、数据)都只有一个权威的、明确的表示。
- TDA (Tell, Don't Ask) 原则: 你应该"告诉"对象去做事,而不是"询问"它的内部状态来替它做决策。
- SoC (Separation of Concerns) 原则: 将一个复杂的系统划分为多个独立的、只关注一个方面的模块。
- LoD (Law of Demeter) 原则: 一个对象应该尽可能少地了解其他对象的内部结构,只与其必要部分通信。
这些原则共同服务于一个目标:创建一个易于理解、易于修改、易于维护的系统,从而在软件的整个生命周期内,最大化地控制住"复杂度"这个敌人。
你可以按照下面的思路在运用这六大原则:
- 当一个新需求来了,你首先用 YAGNI 和 KISS 来过滤它:我们真的需要它吗?我们能用最简单的方法实现它吗?
- 一旦决定要做,你用 SoC 来划分它的边界:这个功能应该属于哪个关注点?它是一个新模块吗?
- 在实现这个模块时,你用 DRY 来避免内部的重复代码,通过抽象来保证知识的唯一性。
- 当这个模块需要与外部模块通信时,你用 LoD 和 TDA 来指导你的交互设计:只和邻居说话(LoD),并且是告诉它们做事(TDA),而不是打听它们的内部状态。
常用架构模式
这里我梳理了《Fundamentals of Software Architecture》一书提到的最常用、最经典的架构模式,具体的描述和权衡之道可以参考我梳理的笔记:读书笔记丨《Fundamentals of Software Architecture》。
- 分层架构:分层架构的核心驱动力是关注点分离(Separation of Concerns)。它将一个复杂的系统按照不同的职责或技术关注点,垂直地划分成若干个水平的“层(Layer)”。
- 管道架构:又称为管道与过滤器架构(Pipes and Filters Architecture),是一种用于处理数据流的强大模式。它的核心思想非常直观,就像一条工厂的流水线:原材料从一端进入,经过一系列独立工站的加工、处理、检验,最终在另一端形成成品。
- 微核架构:也被称为插件化架构(Plug-in Architecture),是一种能够提供极高扩展性、灵活性和演化能力的系统设计模式。它的核心思想是将系统功能划分为两部分:一个最小化的、稳定的核心系统(Core System)和一个由独立插件组件(Plug-in Components)构成的可扩展生态。
- 基于服务的架构:本质是一种将一个大型的单体应用,分解为少数几个、逻辑独立的、可独立部署的"服务" 的架构风格。SBA 的服务数量通常不多,一般在 4 到 12 个之间。它不像微服务那样追求极致的拆分(可能会有几十上百个服务),而是将应用按照核心的业务领域进行划分。
- 事件驱动架构:对特定情况做出反应,并根据该事件采取行动。分为代理模式(broker)和中介者模式(mediator)两种模式,二者最大的区别在于后者具有一个统一的协调者,这会对异常处理、全局统筹有很好的管控手段,当同时也牺牲了系统的解耦程度、灵活度和性能。
- 空间架构:名称来源于元组空间(Tuple Space)多个并行处理器通过共享内存进行通信。SBA 的核心理念便是将应用数据保存在内存中(in-memory),并在所有活跃的处理单元(Processing Units)复制,从而移除中心数据库作为同步约束,实现近乎无限的伸缩性。
- 微服务架构:核心在于高度解耦。它倾向于复制而非耦合。这意味着,如果架构师的目标是高度解耦,那么他们会选择复制而不是重用。微服务通过物理上建模限界上下文(Bounded Context)的逻辑概念来实现高度解耦。
领域驱动设计
在复杂度管理的术篇最后,我想用 DDD(领域驱动设计)来收个尾。很遗憾我并没有在上份工作中积累 DDD 的相关经验,我们的业务复杂度其实已经到了难以管理甚至失控的程度了,领导也提出了要尝试使用 DDD 来进行治理,不过后面也不知为何就搁置了。团队这种习惯性有头无尾的风格,也是我下定决定离开的原因之一。
DDD 存在的意义
话回正题,我们一直在谈论复杂度管理。软件的复杂度有两个来源:
- 技术复杂度:由技术选型、框架、性能、并发等引入的复杂度。
- 领域复杂度 :业务本身固有的复杂度。比如一个电商系统的"优惠券计算规则",一个金融系统的"估值模型",一场联机游戏的"结算过程"。
为什么传统开发的"术"在业务发展到一定规模的时候,在管理复杂度时往往会失效呢?
在很多项目中,我们花了大量时间在技术复杂度上,而对领域复杂度的处理,往往是数据驱动的:先设计数据库表 (DAO/Models),然后写服务 (Service),最后写接口 (Controller)。这种方式在业务初期很简单。
但随着业务发展,业务规则会变得极其复杂(比如,一场联机游戏的结算,可能要调用 10 个微服务,涉及 20 张表,处理 30 种运营活动策略)。
此时,业务逻辑被切割并分散在各个 Service、Helper、Utils 甚至 Controller 层中。代码(技术实现)与真实的业务(领域)之间的认知鸿沟越来越大。最终,系统变得无法维护,因为没有人能说清楚一个完整的业务流程到底是怎么运作的。
软件的核心是其为用户解决的领域问题。因此,管理复杂度的根本,在于精准地捕获、表达和隔离领域复杂度。它要求我们从技术实现驱动转向领域模型驱动。这便是 DDD 存在的意义。
DDD 两大核心
要想理解 DDD 的核心思想,重点在于弄清楚它的战略设计和战术设计,以及其背后的第一性原理。
战略设计:在宏观上划分战场
这是 DDD 最重要的部分,它决定了系统的宏观架构。
- 统一语言 (Ubiquitous Language):统一语言是业务专家、产品经理和开发团队在同一个限界上下文中共同锤炼、严格遵守的、无歧义的词汇表,它贯穿于所有沟通、文档和代码实现之中,是构建领域模型的基石。
- 限界上下文 (Bounded Context):限界上下文是一个明确的业务边界(比如一个子系统或微服务),它封装并保护一个独立的领域模型,确保"统一语言"在该边界内的含义是唯一且自洽的,从而允许不同上下文对同一业务概念(如商品)拥有不同的模型。
- 上下文映射 (Context Map):上下文映射是一种宏观架构图,它通过定义不同限界上下文之间的集成模式(如防腐层、共享内核或遵从者)来清晰地描绘它们之间的技术依赖和团队组织关系,从而在战略层面管理跨模型的集成复杂度。
战术设计:在微观上保护模型
当我们通过战略设计划分好了边界之后,战术设计提供了具体的编码方式,来确保我们在代码中实现的模型不被破坏。其中最核心的有三点:
- 聚合 (Aggregate):聚合是将一个或多个实体与值对象(如订单和订单项)组合成一个业务上的一致性单元,外界只能通过其聚合根这唯一入口来访问,从而强制封装所有业务规则(不变量)并确保其作为一个整体被事务性地持久化。
- 值对象 (Value Object):值对象是一种通过其属性(而非唯一 ID)来定义的对象(如金额或地址),它被设计为不可变的以消除副作用,并在领域模型中承载那些用于度量、描述或限定业务概念的值。
- 资源库 (Repository):资源库是定义在领域层的一个接口,它通过模拟一个内存中的集合来封装数据持久化的所有技术细节,其具体实现(如 SQL 查询)则被隔离在基础设施层,从而使领域模型(尤其是聚合根)保持纯洁,无需关心数据是如何存取的。
目前我对于 DDD 的理解和实践仅在于阅读了《悟道领域驱动设计》一书,感兴趣的读者可以参考我梳理的读书笔记丨《悟道领域驱动设计》。
器:验证与洞察的质量手段
如果说心法是道,术是招式,那么器就是"眼睛"和"标尺"。没有器,我们永远不知道招式打得对不对,也无从得知我们的道是不是走偏了。这里我想重点总结我认为 2 个最重要的工具:单元测试和可观测性。这也是我在第一份工作中做的最有成就感、也是我进步最大的两个专项:代码质量建设专项和服务监控建设专项。
我之所以认为单元测试和可观测性是管理软件复杂度的两大利器,是因为它们分别为软件生命周期中两个截然不同的复杂度阶段——静态复杂度和动态复杂度——提供了必不可少的反馈与控制机制。
- 静态复杂度:代码在"写下时"的复杂度。它关乎代码的结构、依赖、正确性和可读性。
- 动态复杂度:系统在"运行时"的复杂度。它关乎成千上万个模块交互时所涌现出的、难以预测和跟踪的行为。
单元测试

这里我强烈建议所有软件工程师都去阅读《Unit Testing Principles, Practices, and Patterns》这本书!绝世好书!而且最好的阅读英文原版!我使用了 2 个月的时间(每天 1 个小时)完完整整阅读了这本书 2 次,它对我在单元测试和代码质量上的理解和实践能力都起到了非常大的帮助。
这里我就不再重复此书的内容,但是如果你曾经或是现在依旧被以下问题所困扰的话,建议你去仔细阅读一下这本书,也可以参考我整理的读书笔记丨《Unit Testing Principles, Practices, and Patterns》。
- 为什么要写单元测试?单元测试的目标是什么?
- 单元测试的粒度是怎样的?什么叫单元?a class, a function, or a behavior, or an observable behavior?
- 单测覆盖率真的有用吗?有什么用?又有哪些限制?
- 怎样才能写好单元测试?怎样才能写出性价比最高的单元测试?
- 如何判断一个单元测试的好坏?有没有具体可供参阅的维度?
- 哪些代码需要写单元测试,哪些代码没必要写单元测试?
- 单元测试和集成测试的边界是什么?
- (单元丨集成)测试到底是要测什么东西?
- 单元测试的侧重点是什么?集成测试的侧重点是什么?二者的比例该是怎样的?
- 如何使用 Mock?哪些东西是需要 Mock 的?哪些东西是不应该 Mock 的?需要 Mock 的东西,应该在哪个层次进行 Mock?(你的 repository 层需要 Mock 吗?)
- 为什么你的测试代码很脆弱,总是需要频繁修改,维护起来难度很大?
- 如何减少测试结果的假阳性和假阴性?
本篇我想强调的是,单元测试的价值远远大于找 Bug。它首先是一种设计工具,其次才是一种测试工具。它在三个层面上管理了静态复杂度。
1. 它是高内聚低耦合的设计反馈机制
在软件设计中,高内聚、低耦合(模块化心法)是最重要的目标之一。单元测试是检验这一目标是否达成的第一个,也是最快的反馈工具。
当你试图为一个模块(一个函数或一个类)编写单元测试时,如果发现测试很难写,这就是一个明确的设计缺陷信号。难写通常意味着该模块依赖了过多具体实现(高耦合),而不是依赖抽象(接口)。例如,你为了测试
A,不得不去实例化
B、C、D 等多个真实对象。
为了使 A
变得可测试,工程师被迫使用抽象心法和依赖倒置(术)。不再让
A 直接依赖 B,而是依赖一个 IB
接口。这样,在测试中就可以传入一个模拟(Mock)的 B。
这个时候,单元测试反向强迫工程师在设计时就必须遵守"低耦合"和"强抽象"的心法和术。
2. 它是封装和重构的安全保障
软件的复杂度会随时间腐化。封装(抽象心法)的目的是隐藏内部实现,以便未来可以安全地修改它。单元测试是实现这一目标的安全保障。
当一个模块拥有完备的单元测试覆盖时,工程师(尤其是新接手的工程师)获得了重构的信心。他们可以大胆地修改模块的内部实现(例如优化算法、更换数据结构),而无需在认知上承载该模块的全部历史逻辑。
只要在重构后,所有的单元测试依然通过,工程师就能获得极大的信心——内部实现被优化了,但外部承诺未被破坏。这从根本上抑制了代码的腐化,管理了维护的复杂度。
3. 它是模块边界的精确定义
文档会过时,但代码不会。单元测试是一种可执行的、活的文档。
一个写得好的测试用例(例如
Test_Login_Fails_When_Password_Incorrect),它以代码的形式,精确地、无歧义地定义了登录模块这个抽象在特定输入下的行为边界。
单元测试是理解一个模块功能和接口承诺的最快、最准确的途径,它极大地降低了新成员理解系统的认知复杂度。
可观测性
单元测试在本地是完美的,但它对运行时的动态复杂度则无能为力。当 1000 个通过了单元测试的微服务(模块)被部署到网络上时,它们交互所产生的涌现行为,是单元测试无法覆盖的。
在我看来,可观测性一般包含 metrics、trace
和 logs 三大部分。
| 组件 | 核心 | 说明 |
|---|---|---|
| metrics | 帮助你判断是否有问题 | 统计埋点,包括系统监控、服务监控、业务监控。 |
| trace | 告诉你问题在哪里 | 实现链路追踪,展示系统拓扑图,梳理服务调用链路,洞察性能瓶颈点。 |
| logs | 帮助你定位到问题根源 | 制定日志规范,将规范灌输到日常开发的认知习惯中,尝试将部分规范集成到日志组件中,打更有意义的日志, 提高问题排查效率。 |
利用好这 3 个组件,可以帮助我们:
出现问题时,提高问题排查效率。
问题快来时,提供全局视野,提供预知问题的能力。
问题没出现时,提高开发质量,减少问题。
可观测性的作用
具体来说,可观测性在三个层面上管理了动态复杂度。
1. 它是分布式系统的交互可视化工具
在模块化的架构中,系统是一个分布式黑盒。任何一个请求都可能跨越几十个模块(服务)。单个模块(已通过单元测试)是正确的,但它们组合运行时的交互可能导致性能瓶颈、级联失败或数据不一致。
分布式追踪 (Tracing)
提供了请求级的可视化。它能精确地描绘出一个请求从 Service-A
到 Service-B 再到 Service-C
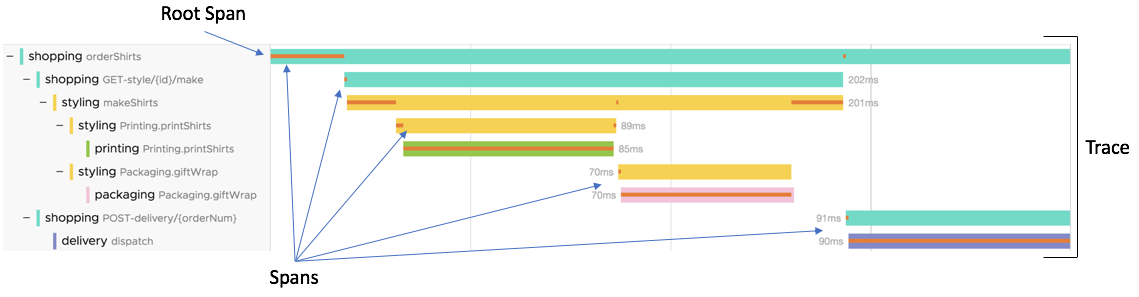
的实际路径和耗时分布。它将黑盒的动态交互复杂度,降维为一张清晰的瀑布图或依赖拓扑图,使工程师能定位涌现出的性能瓶颈或错误路径。
2. 它是设计权衡的运行时数据
我们所有的心法(抽象、分治、分层、模块化)都是有性能代价的。分层带来了数据复制的代价;模块化带来了网络调用的代价;消息队列(抽象)带来了延迟的代价。
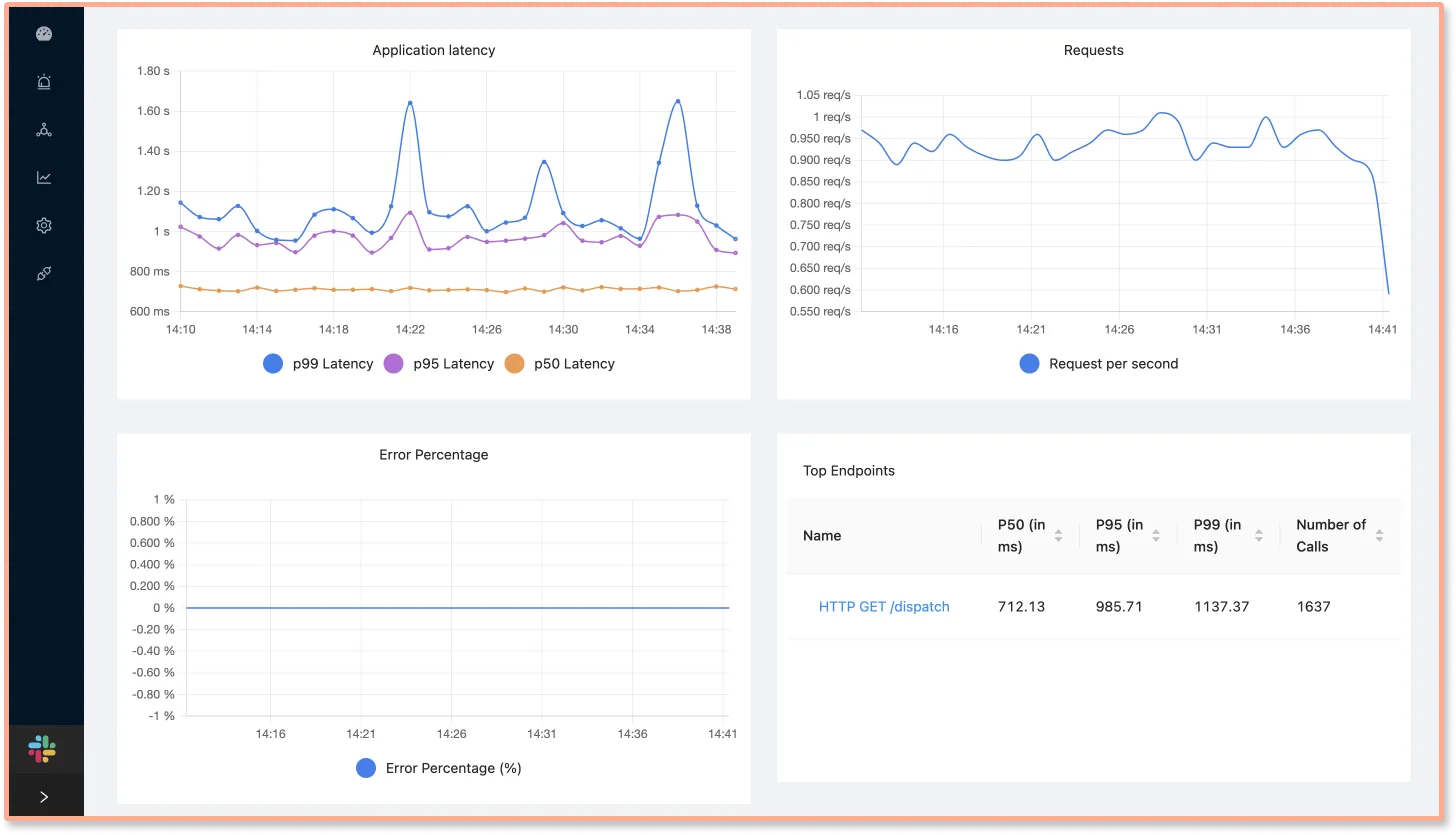
指标 (Metrics) 提供了量化这些代价的数据。例如 P99 延迟、GC 压力、队列深度会精确地告诉你:"你为这个分层付出了 30% 的 GC 额外开销","你为这个模块化(微服务调用)付出了 40ms 的 P99 延迟"。
可观测性提供了运行时的真实数据,使设计权衡(Trade-off)从拍脑袋变成了数据驱动。工程师可以基于数据,决定何时打破分层(例如合并 DTO 和 Model)或合并模块(例如合并微服务)以换取性能。
3. 它是未知问题的上下文
单元测试只能验证已知(Known)的场景。而系统在真实运行时,会遇到大量未知(Unknown)的、涌现的复杂问题。
日志 (Logs),尤其是结构化和高基数的日志,提供了高维度的上下文。
当黑天鹅事件(例如高并发+特定网络分区)发生时,只有
Traces、Metrics 和 Logs
结合,才能提供足够的现场信息,让工程师能事后回溯、定位和理解那些单元测试永远无法复现的动态复杂度。

可观测性的本质
可观测性到底在观测什么?我们观测的是一个系统(尤其是模块化和分层后的分布式系统)在运行时所涌现出的、不可预测的动态复杂度。
我们观测的不是工具(metrics、trace、logs),而是系统在真实压力下的:
- 外在行为 (External Behavior)
- 内在状态 (Internal State)
- 交互关系 (Interactions)
1. 观测外在行为:系统在做什么?
这是从外部看,我们的模块(服务)所承诺的接口(功能)是否正常。这通常对应 Google SRE 的黄金四信号中的前三个。
- 延迟 (Latency):一个抽象的接口(如 API)完成它的承诺需要多长时间?这是性能的直接体现。
- 流量 (Traffic):有多少请求或任务正在压向服务?这是负载的直接体现。
- 错误 (Errors):有多少承诺没有被兑现(例如 HTTP 500)?这是正确性的直接体现。
2. 观测内在状态:系统花多大代价在做?
这是从内部看,我们的模块(服务)为了完成上述外在行为,内部的资源和状态是什么样的。
- 饱和度 (Saturation):例如,CPU 使用率、内存占用、磁盘 I/O、连接池大小、队列(Kafka)的积压长度。这是容量和健康度的直接体现。一个外在行为看起来正常(例如延迟低),但其内部状态可能已经处于崩溃边缘(例如队列积压 99%)。
- 关键业务指标 (Business Metrics):例如,订单创建数、支付成功率、用户注册数。这连接了技术复杂度与业务价值。
3. 观测交互关系:行为和状态是如何关联的?
动态复杂度的根源在于“交互”——模块A 调用
模块B,B 再调用
C。当下单这个行为变慢时,我们必须观测这个交互链条。
- 上下文的传播:观测一个请求如何穿透抽象边界、模块边界和分层边界。这就是
TraceID所做的工作。 - 高基数的上下文:我们不仅观测
Latency = 500ms,我们观测的是:Latency{service="payment", user_id="12345", region="eu-west", error="true"}。这允许我们事后去探索那些"未知的未知"。例如:为什么只有eu-west地区的VIP用户的支付行为会失败?
可观测性的方案
对于落地可观测性,我的建议是尽可能拥抱 OpenTelemetry,它可以说是目前业界的唯一标准。不要自己去造轮子,不要在自己的业务项目中去"创造"一个自己的 traceID,去拥抱开源标准,你会享受到它的强大和遍历。
我在工作过程中,开源了一套 Go 语言的可观测性方案,感兴趣的读者可参考:goapm。
总结
行文至此,我们完整地构建了"管理复杂度"的"道、法、术、器"四层体系。
我们从"道"出发,明确了软件工程的终极目标——对抗"复杂度"这唯一且根本的敌人。我们亲历的"屎山"、那些"龙卷风战术",本质上都是复杂度失控后的"熵增"表象。
为了对抗"熵增",我们找到了"法"——抽象、分治、分层、模块化。这不是空洞的理论,而是无数前辈总结出的、应对"认知局限"这一不变约束的四大“不变法则”。它们是我们的第一性原理,是我们构建一切“术”的基石。
"术"是我们手中的"招式"与"套路"。无论是 SOLID、设计模式,还是宏观的架构模式与 DDD,它们都是"法"在特定场景下的具象化应用。它们是"法"的实践工具箱,是确保我们的“招式”不走形、有据可依的“战法”。
最后,我们必须拥有"器"——单元测试与可观测性。它们是我们构建复杂系统的"双眼"。单元测试是我们管理"静态复杂度"的标尺,它在"设计时"强迫我们遵守"法"与"术";可观测性是我们管理"动态复杂度"的明镜,它在"运行时"为我们揭示"涌现"出的未知。没有"器",我们所有的"法"与"术"都只是盲人摸象。
回顾这三年的工作,我曾深陷"屎山",也曾亲手造"山"。我所经历的痛苦、迷茫与挣扎,其根源就在于,我试图用"术"(例如某个设计模式)去解决"道"(复杂度失控)的问题,却又缺乏"器"(可观测性)来度量结果。
这篇复盘,便是我为那段经历寻找的答案。
"道、法、术、器"不是一个需要背诵的清单,它是一个完整的、自洽的、循环反馈的作战体系。它定义了一个软件工程师从“编码”走向“工程”的必经之路。
理解这套体系,不是为了在“屎山”上“雕花”,而是为了让我们在面对下一个"紧急"需求、下一次"龙卷风战术"时,拥有拒绝“熵增”的武器和底气。
AI 时代下道法术器的进化
对于管理复杂度这一话题,我不想止步于此,我想多思考一下:
[!CAUTION]
在 AI 时代下的 AI 应用开发中,软件工程还有存在的意义吗?它的道法术器有什么变化吗?
我的结论是:
[!IMPORTANT]
AI 应用开发,它首先是一个软件工程问题,然后才是一个 AI 问题。软件工程的地位依旧无可撼动,并且它管理复杂度的"道"并没有发生变化,但是"法"、"术"和"器"必须进化,以应对新的变化和挑战。
在 AI 时代,尤其是大模型 (LLM) 时代,抽象、分治、分层、模块化这四大法则不仅没有过时,反而变得前所未有地重要。因为 AI 引入了一种全新的、更棘手的复杂度:非确定性 (Non-Determinism) 复杂度。
传统的软件工程对抗的是逻辑复杂度("If-Then-Else" 的复杂度)。 AI 时代的软件工程对抗的是逻辑复杂度 + 非确定性复杂度(黑盒模型、概率性输出、数据依赖)。
道的进化:从管理到驾驭
AI 时代的软件工程,道依然是管理复杂度。但 AI 时代,复杂度本身发生了根本性的变化。
- 旧的复杂度:是确定性的。源于我们自己代码中组件间依赖关系的数量。它是可被推导的,只是过于庞大。
- 新的复杂度:是非确定性和涌现性的。源于 LLM 这个黑盒的概率性本质。我们从管理"代码逻辑"转向管理"模型行为";我们从"调试 Bug"转向"对抗幻觉"。
因此,道的目标,在"管理复杂度"之外,增加了两个新的维度:
- 管理非确定性:我们如何为"屎山"找到根源?我们如何为"幻觉"构建护栏?我们如何为"概率"设计"重试"与"校验"?
- 驾驭涌现性:AI Agent 所展现的自主规划能力是一种涌现。我们的道不再是"自顶向下"地控制一切,而是自底向上地引导和驾驭这种涌现能力,让它在可控的边界内解决问题。
法的进化:从逻辑抽象到能力抽象
抽象
[!IMPORTANT]
不变的第一性原理 —— 隐藏实现细节,提供一个简洁、稳定的"接口"。
传统的抽象隐藏的是清晰的逻辑(例如,sort(list)
隐藏了快排的实现)。而 AI
时代的抽象需要隐藏的是一个模糊的、概率性的黑盒(例如,summarize(text)
隐藏了 LLM 内部上千亿个参数的复杂推理)。
它的进化:
- 从功能抽象到能力抽象:
- 传统: 我们抽象一个函数
(Function),它接受确定的输入,产生确定的输出(例如
getUser(id))。 - 进化: 我们抽象一种能力
(Capability)。例如,
OpenAI API本身就是一种强大的抽象。我们不关心它内部是 Transformer 还是 MoE,我们只关心它暴露了文本生成、图像理解的能力。
- 传统: 我们抽象一个函数
(Function),它接受确定的输入,产生确定的输出(例如
- Prompt 成为新的 API:
- 传统: API 是通过严格的函数签名 (Signature) 定义的。
- 进化: Prompt Engineering 本身就是一种新的抽象实践。一个精心设计的 Prompt(例如,"你是一个专业的法律助手,请...")就是创建了一个新的、更可控的抽象层,它将一个通用的 LLM(原始能力)抽象成了一个特定领域的专家(封装后的能力)。
- 特征存储成为数据抽象:
- 传统: 我们抽象数据访问层 (DAO / Repository)。
- 进化: 在 MLOps 中,Feature Store
(特征存储)
成为了关键的数据抽象。它向模型训练和推理隐藏了数据清洗、转换、聚合的复杂
ETL 过程。模型开发者(高层)不再关心数据(低层)是来自 Kafka 还是
MySQL,他们只关心获取
user_7day_purchase_amount这个被抽象出来的特征。
分治
[!IMPORTANT]
不变的第一性原理 —— 将一个无法一次性解决的大问题,分解为多个同类型、可独立解决的小问题,最后再合并。
在 AI 时代的新挑战 一个单一的、巨大的全能模型难以训练、难以调试、成本高昂。同时,一个复杂的现实问题(例如帮我规划一次东京旅行)也超出了单个 LLM 的能力范围。
它的进化:
- 模型训练中的分治 (MoE):
- 传统: 归并排序、MapReduce。
- 进化: 混合专家模型 (Mixture of Experts,
MoE) 是分治思想在模型架构上的极致体现。
- 分解 (Divide): 不训练一个 1.7 万亿参数的巨无霸模型,而是训练(比如) 8 个 2000 亿参数的专家模型。
- 解决 (Conquer): 当一个 Token 进来时,一个路由器 (Gating Network) 负责判断这个问题该由哪两个专家来解决?
- 合并 (Combine): 将这两个专家的输出加权合并。
- 应用架构上的分治 (RAG):
- 传统: 微服务架构。
- 进化: RAG (Retrieval-Augmented
Generation,检索增强生成) 是分治在 AI 应用架构上的最佳实践。
- 大问题: 如何让 LLM 回答关于我私有知识库的最新问题?
- 分解 (Divide): 强迫 LLM 知道一切是不可行的。我们将问题分解为:① 检索 和 ② 生成。
- 解决 (Conquer):
- 用一个专门的检索模块(例如向量数据库)解决独立的小问题:找到最相关的知识片段。
- 用 LLM 解决另一个独立的小问题:基于这些片段,生成通顺的回答。
- 合并 (Combine): 将检索到的片段(Context)和原始问题(Query)一起合并后,发给 LLM。
- AI 智能体 (Agents) 和工具使用 (Tool Use):
- 进化: 当 LLM
遇到一个复杂任务(例如明天天气怎么样?)时,它使用分治:
- 分解: ① 我需要知道"明天"和"地点"。② 我需要一个工具来查天气。③ 我需要组织语言。
- 解决: 它调用
call_weather_api("beijing", "tomorrow"),获得 JSON 结果。 - 合并: 它将 JSON 结果合并到它的上下文中,生成最终答案。
- 进化: 当 LLM
遇到一个复杂任务(例如明天天气怎么样?)时,它使用分治:
分层
[!IMPORTANT]
不变的第一性原理 —— 按"变化的速率"或"职责"划分,管理纵向依赖,上层依赖下层,隔离变化。
AI 系统的依赖变得极其复杂。它不再只是代码依赖,还包括数据依赖、模型依赖、环境依赖。
它的进化:
- MLOps 成为新的分层标准:
- 传统: 表现层 → 业务层 → 数据层。
- 进化: AI
系统的技术栈被重新分层,每一层都隔离了不同速率的变化:
- 应用层 (Application Layer): 传统的 Web 后端。它变化最快(例如 UI 调整)。
- AI 编排层 (Orchestration Layer): Prompt 模板、RAG 流程、Agent 逻辑。变化较快(例如调整 Prompt)。
- 模型服务层 (Model Serving Layer): API Gateway、模型推理服务 (Triton, vLLM)。变化中等(例如模型版本切换)。
- 模型训练层 (Model Training Layer): 训练流水线、实验跟踪 (MLflow)。变化较慢(例如重训模型)。
- 数据/特征层 (Data/Feature Layer): 特征存储、数据湖。变化最慢(例如增加新数据源)。
- 这种分层确保了:我可以更新一个 Prompt(编排层),而无需重新训练模型(训练层)或重启服务(服务层)。
- "数据-模型-代码" 的依赖分层:
- 进化: 我们必须严格区分三种依赖。在 AI 工程中,数据是新的代码。
- 我们必须建立新的分层依赖规则:代码 (Code) → 模型 (Model) → 数据 (Data)。
- 这意味着,数据的变更会触发模型的重训;模型的变更会触发代码的适配。管理这些"依赖链"和"缓存失效"(例如,数据变了,哪些特征和模型需要重算?)是 AI 时代分层的核心任务。
模块化
[!IMPORTANT]
不变的第一性原理 —— 高内聚、低耦合。将系统划分为"横向"的功能单元,通过清晰的接口协作。
在 AI 时代的新挑战是如何封装 AI 的非确定性?如何让一个概率性的模块与一个确定性的系统(例如支付模块)安全地协作?
它的进化:
- 模型即模块 (Model as a Module):
- 传统: 一个
.jar包或一个 Gopackage是一个模块。 - 进化: 一个经过训练并打包的模型(例如一个 Hugging Face 仓库)就是 AI 时代的新模块。它具有极高的内聚性(封装了解决特定任务的所有知识)和极低的耦合性(通过标准的 API 暴露服务)。
- 传统: 一个
- 可观测性成为接口的一部分:
- 传统: 模块的接口是 API 签名。
- 进化: AI 模块的接口不仅要包括输入/输出,还必须包括可观测性。因为我们无法 100% 信任它的输出,所以模块必须暴露它的内部状态:例如,它输出 "A" 的置信度是多少?它在推理时参考了哪些知识来源?
- 确定性外壳模块:
- 进化: 这是模块化思想最重要的进化。我们不能让非确定性泄露到系统的其他部分。
- 我们必须创建一个确定性外壳模块(一个高内聚的封装):
- 内部 (非确定性): 它调用 LLM、处理概率性输出。
- 外壳 (确定性): 它包含防护栏。例如:
- 解析与校验: 强迫 LLM 输出 JSON,如果解析失败则重试或返回错误。
- 过滤: 检查输出是否包含敏感词或幻觉。
- 回退: 如果 AI
失败或置信度低,则回退到传统的确定性逻辑(例如
if-else)。
- 这个外壳模块对外提供了一个看似确定、安全的接口,使得系统的其他部分(如订单处理、支付逻辑)可以安全地调用它。
术的进化:从管理逻辑到驾驭概率
AI 时代催生了一系列全新的"术",它们的核心不再是管理"逻辑的确定性",而是转向管理"语义的非确定性"和"编排认知(Cognition)"。
以下是我认为最重要的四大术之进化:
核心:提示词工程与 AI 编排
这是 AI 时代最根本的新"术",它几乎重塑了"法"中的抽象和分治。
- Prompt
即接口:传统的术是写代码来定义逻辑。全新的术是写
Prompt(自然语言)来定义能力和契约。Prompt成为了我们与 AI 这个非确定性黑盒交互的新 API。 - 编排即分治:单一
Prompt无法解决复杂问题。因此,术进化为AI 编排(Orchestration),如 LangChain 或 LlamaIndex 所做的那样。- RAG (检索增强生成):就是一种编排"术"。它将检索和生成这两个步骤分治开来,并通过编排合并结果。
- 链式思考 (Chain-of-Thought):这是一种引导 AI 分治其内部思维的"术"。
- AI 编排层:在 MLOps 分层中,这一层成为了新的核心。
涌现:智能体架构与工具调用
如果说 RAG 是"分治"的初级形态,那么 Agent 架构就是"术"在"分治"思想上的高级进化,它服务于"道"中"驾驭涌现性"的目标。
- LLM 即认知引擎:传统的"术"是工程师自顶向下设计一切。Agent "术"则将 LLM 视为一个可以自主规划的认知引擎或中央处理器。
- 工具即能力模块:这对应了"法"中的"模块化"。
Agent通过工具调用来扩展其能力。 - ReAct
循环:
Reason -> Act -> Observe的循环,是Agent架构中最核心的"术",它为 AI 的涌现行为提供了一个可控的执行框架。
防护:确定性外壳
这是 AI 时代保障系统安全和可靠性的第一防卫术,它源于"法"中"模块化"的思想。
AI 的非确定性是剧毒的,它绝不能泄露到你的核心业务逻辑中(比如支付、订单)。这个"术"的核心就是封装黑盒、管理边界。
这个外壳模块 负责所有脏活累活:
- 输入防护:检查
Prompt是否合规(防注入)。 - 输出解析:强迫 AI 输出
JSON,并进行严格的校验、
pydantic风格的类型转换。 - 安全过滤:检查 AI 输出是否有害、有偏见、或包含敏感信息。
- 回退机制:当 AI
失败、超时或输出"我不知道"时,回退 到一个确定的、经典的
if-else逻辑。
工业:MLOps 与 AI 资产管理
传统的"术"管理"代码"。AI 时代的"术"必须管理"代码、模型、数据"三位一体的复杂依赖链。这就是 MLOps。
- 模型即模块:AI 时代,一个(例如
Hugging Face上的)模型,就是一个可版本化、可部署的新模块。 - 数据即代码:数据是新的代码。因此,"术"必须进化到包含数据版本管理 (DVC)、特征工程 (Feature Engineering) 和特征存储 (Feature Store)。
器的进化:从确定性标尺到非确定性明镜
测试
在 AI 时代,尤其是 LLM 时代,传统测试的第一性原理受到了根本性的挑战。
- 传统测试: 验证 (Verification)。其核心是 确定性 (Determinism)。我们要求 1+1 必须等于 2。
- AI 时代的测试: 评估 (Evaluation)。其核心是 概率性 (Probabilism) 和 模糊性 (Fuzziness)。我们没有所谓的唯一确定的正确答案,但我们知道它应该是"简洁的"、"忠于原文的"、"通顺的"。
因此,传统测试在 AI 时代仍然极端重要,但已远远不够。它必须进化。
单元测试
在 AI 系统中,我们之前讨论过,模块化的进化是使用确定性外壳来包裹非确定性的 AI 内核。传统单元测试的职责,就是捍卫这个确定性外壳。它们不测试 AI 本身,而是测试所有与 AI 交互的、确定性的管道和护栏。
- 测试 Prompt 模板
- 测试输出解析器 (Parsers)
- 测试回退逻辑 (Fallbacks)
- 测试工具调用 (Tool Use)
单元测试从"测试业务逻辑"后退到"测试 AI 的输入输出管道"。它保证了无论 AI 表现得多糟糕(例如胡言乱语),我们的系统都不会崩溃,而是会优雅地处理失败。
集成测试
集成测试的职责,是捍卫 AI 工作流的连通性。它测试的是我们之前讨论的分层与分治架构中,各个模块(服务、数据库、模型 API)之间的胶水层。
- 测试 RAG 流程的集成
- 测试外部 API 的 Mocking
集成测试保证了 AI 应用的骨架是通的。它保证了数据流(Data Flow)在 RAG 管道、微服务和外部 API 之间能正确流转。
新型测试
这是全新的、最重要的一层。传统测试验证
func(in) == out,AI 测试评估
eval(func(in), criteria) 是否为
True。我们不再断言相等,而是评估品质。
- 基于"黄金数据集"的回归测试:检测"新回答"与"理想的回答范例"之间的语义相似度。防止有益的修改导致意外的衰退。
- 基于"启发式"的评估:定义一系列可计算的规则,如上下文相关性、上下文精确度、答案相关性、答案有用度。
- 基于"对抗性"的测试:传统安全测试中的渗透测试,专门测试 AI 的独特漏洞。如 Prompt 注入、偏见与安全和鲁棒性。
- LLM 作为评估者:使用一个更强大的 LLM 作为自动化评估的法官。
测试金字塔
AI 时代的测试不再是一个简单的金字塔,它演变成了一个双重结构:
- 确定性金字塔 (传统软件 1.0):
- 单元测试 (测试管道、解析器、护栏)
- 集成测试 (测试 RAG 流程、API 连通性)
- E2E 测试 (测试 UI 交互)
- 概率性评估层 (AI 软件 2.0):
- 质量评估 (基于黄金集、启发式、LLM-as-Judge)
- 安全评估 (对抗性测试、偏见测试)
- 生产监控 (CI/CT) (A/B 测试、用户反馈、数据漂移检测)
最后,测试从部署前延伸到了部署后。A/B 测试和生产环境的用户反馈成为了持续测试 (Continuous Testing) 的最终闭环。
可观测性
传统的动态复杂度是"服务 A 调用 B 变慢了"、"为什么服务 A 突然调不通服务 B 了?"。AI 时代的动态复杂度是"为什么 AI 突然开始胡言乱语了?"。我们必须观测那个非确定性黑盒的心智过程。
AI 时代的可观测性,其进化本质是从"监控系统健康"扩展到"评估 AI 行为与质量"。传统的三大支柱(metrics、trace、log)仍然是地基,但我们必须在上面加盖全新的楼层。
从三大支柱到四大支柱
为了解决上述问题,可观测性正在演化,增加了一个全新的、专为 AI 服务的支柱,我称之为 AI 交互 (AI Interactions)。这有时也被称为 LLM O11y 或 Trace-centric Observability。
这个新支柱专门捕获 AI 黑盒的"输入-处理-输出"全貌。
- 传统 Logs:
{"level": "info", "service": "payment", "msg": "payment processed"} - AI Logs/Traces :
- Inputs: 捕获完整的 Prompt(包括我们注入的 RAG 上下文、Few-shot 示例)。
- Outputs: 捕获完整的 Response(LLM 的原始回答)。
- Metadata:
- 模型参数:
model_name(gpt-4o, claude-3-sonnet),temperature,max_tokens。 - 使用情况 (Usage):
prompt_tokens,completion_tokens,total_tokens。 - 成本 (Cost):
cost_in_usd(例如 $0.0015)。 - 延迟 (Latency):
time_to_first_token,total_time。
- 模型参数:
这个新支柱是后续所有进化的数据基础。
metrics:从系统健康到 AI 质量
传统 Metrics 关注 RED(速率, 错误率, 耗时)。在 AI 时代,我们增加了全新的 AI 质量指标。
| 指标维度 | 传统可观测性 | AI 时代可观测性 |
|---|---|---|
| 系统健康 | http_requests_total
http_errors_ratecpu_usage |
(全部保留)llm_api_error_rate (如 429 限流) |
| 性能 | http_request_duration_p99 |
llm_time_to_first_token_p95
llm_token_generation_speed (tokens/sec) |
| AI 质量 | (无) | hallucination_rate (幻觉率)toxicity_score (有毒内容评分) pii_leakage_count (个人隐私泄露计数) user_feedback_score (用户点赞/点踩率) |
| 成本 | (无,或模糊的服务器成本) | total_cost_per_day (按模型/按用户)
cost_per_request (单次请求成本)
total_tokens_per_service |
这意味着可观测性平台 (如 Grafana) 上,除了 CPU 和延迟的图表,还必须有"每日成本"、"幻觉率"和"用户满意度"的图表。
tracing:从调用链到思维链
- 传统 Trace (OpenTelemetry):关注的是操作
(Operations)。一个 Span (跨度) 代表一个函数调用或一次 RPC。如
Service A->Service B (Redis GET)->Service C (DB Query)。它回答的是请求的瓶颈和问题点出现在哪里? - AI Trace (如 LangSmith,
OpenInference):关注的是上下文 (Context) 和
AI 的思考步骤。
- 一个 Span 不仅代表操作,更代表 AI 链条中的一步,并富含语义信息。
- 以一个 RAG (检索增强生成) 应用为例,一个 AI Trace 必须清晰地展示:
- [Span 1: Parse Query] 用户的原始问题。
- [Span 2: Embed Query] 用户的查询被转换成了哪个向量。
- [Span 3: Vector Search] 从向量数据库中检索到了哪几块(Chunks)文本?
- [Span 4: Build Prompt] 系统将这些 Chunks 和原始问题组装成了什么样的最终 Prompt?
- [Span 5: LLM Call] 调用 LLM (附带 Tokens, Cost 等元数据)。
- [Span 6: Parse Output] 得到 LLM 的原始回答,并解析。
AI Trace 是富上下文的。当一个 RAG 回答错误时,SRE 或工程师需要打开这个 Trace,一目了然地看到是 Vector Search 没查到相关文档,还是 Prompt 组装错了,还是 LLM 产生了幻觉。
log:从事件记录到评估数据集
- 传统 Logs: 主要用于事后排障。
- AI Logs:
- 主动排障 (Proactive): AI Logs (尤其是捕获的 Prompt/Response) 会被实时送入一个评估模型 (Evaluator)。例如,用一个 LLM (如 GPT-4) 去评估另一个 LLM (如 Llama 3) 的回答是否有害。如果评估不通过,立即触发告警。
- 黄金数据集 (Golden Dataset): 生产环境中的高质量问答对 (来自 AI Logs) 会被筛选出来,用于微调 (Fine-tuning) 未来的模型,形成一个持续改进的闭环。
可观测性系统不再只是一个"看"的系统,它成了一个"评估"和"再训练"的数据源头。
总结
| 方面 | 传统可观测性 (O11y 1.0) | AI 时代可观测性 (O11y 2.0) |
|---|---|---|
| 核心目标 | 监控系统健康 (Health) | 监控系统健康 + 评估 AI 质量 (Quality) |
| 主要挑战 | 分布式系统的复杂性 | LLM 的非确定性、黑盒性、幻觉 |
| Metrics | RED 指标 (速率、错误、耗时) | RED + 质量指标 (幻觉率、满意度) + 成本指标 (Tokens, Cost) |
| Tracing | 操作链 (Operation Chain) (如 OpenTelemetry) | 思维链 / 上下文链 (Context Chain) (如 LangSmith, OpenInference) |
| Logs | 事后排障的事件记录 | 评估数据集,用于实时告警和模型微调 |
| 核心工具 | Prometheus, Grafana, Jaeger, ELK | (保留上述工具) + LLM O11y 平台 (如 LangSmith, Arize AI, W&B) |
总而言之,AI 时代的可观测性,是传统 SRE/DevOps 和 MLOps/Data Science 两个领域的强制融合。我们不仅需要工程师,还需要懂 AI 质量评估的专家,共同盯着仪表盘。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。

管理复杂度 - HedonWang&pics=/banner/first-job-review-01-tech-01-manager-complexity.jpg&summary=三年工作复盘丨技术篇:软件工程是什么丨(一)管理复杂度)


