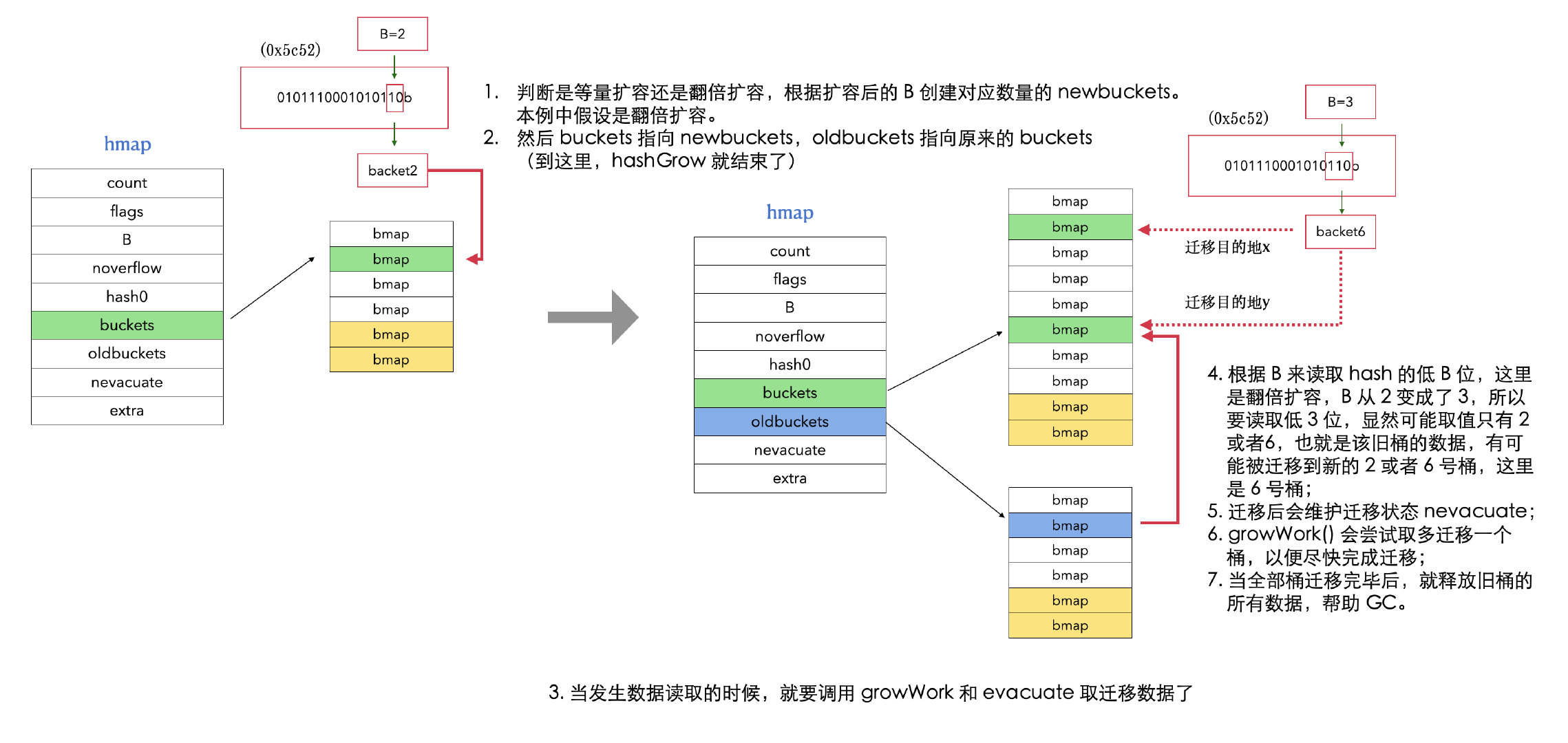
type hmap struct { // Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go. // Make sure this stays in sync with the compiler's definition. count int// # live cells == size of map. Must be first (used by len() builtin) flags uint8 B uint8// log_2 of # of buckets (can hold up to loadFactor * 2^B items) noverflow uint16// approximate number of overflow buckets; see incrnoverflow for details hash0 uint32// hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0. oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing nevacuate uintptr// progress counter for evacuation (buckets less than this have been evacuated) clearSeq uint64
extra *mapextra // optional fields }
count:map 中元素个数
B:桶数量的对数(桶数 = 2^B)
buckets:当前桶数组 []bmap 指针
oldbuckets:扩容时的旧桶数组 []bmap
nevacuate:扩容迁移进度计数器
hash0:哈希种子(防止哈希碰撞攻击)
2.2 bmap(桶结构)
1 2 3 4 5 6 7 8 9 10 11 12
// A bucket for a Go map. type bmap struct { // tophash generally contains the top byte of the hash value // for each key in this bucket. If tophash[0] < minTopHash, // tophash[0] is a bucket evacuation state instead. tophash [abi.OldMapBucketCount]uint8 // Followed by bucketCnt keys and then bucketCnt elems. // NOTE: packing all the keys together and then all the elems together makes the // code a bit more complicated than alternating key/elem/key/elem/... but it allows // us to eliminate padding which would be needed for, e.g., map[int64]int8. // Followed by an overflow pointer. }
// Possible tophash values. We reserve a few possibilities for special marks. // Each bucket (including its overflow buckets, if any) will have either all or none of its // entries in the evacuated* states (except during the evacuate() method, which only happens // during map writes and thus no one else can observe the map during that time). emptyRest = 0// this cell is empty, and there are no more non-empty cells at higher indexes or overflows. emptyOne = 1// this cell is empty evacuatedX = 2// key/elem is valid. Entry has been evacuated to first half of larger table. evacuatedY = 3// same as above, but evacuated to second half of larger table. evacuatedEmpty = 4// cell is empty, bucket is evacuated. minTopHash = 5// minimum tophash for a normal filled cell.
// flags iterator = 1// there may be an iterator using buckets oldIterator = 2// there may be an iterator using oldbuckets hashWriting = 4// a goroutine is writing to the map sameSizeGrow = 8// the current map growth is to a new map of the same size
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize))) bOrig := b // 保存原始桶,用于emptyRest优化时回溯 top := tophash(hash)
search: // 遍历桶链表 for ; b != nil; b = b.overflow(t) { // 遍历桶内8个槽位 for i := uintptr(0); i < abi.OldMapBucketCount; i++ { // tophash不匹配,快速跳过 if b.tophash[i] != top { if b.tophash[i] == emptyRest { break search } continue }
// 获取key并比较 k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize)) k2 := k if t.IndirectKey() { k2 = *((*unsafe.Pointer)(k2)) } if !t.Key.Equal(key, k2) { continue }
// 优化:如果后面都是空的,将连续的emptyOne转为emptyRest // 这样后续查找遇到emptyRest可以立即终止 if i == abi.OldMapBucketCount-1 { if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest { goto notLast } } else { if b.tophash[i+1] != emptyRest { goto notLast } }
// 向前回溯,将emptyOne改为emptyRest for { b.tophash[i] = emptyRest if i == 0 { if b == bOrig { break } // 跳到前一个桶的最后一个槽位 c := b for b = bOrig; b.overflow(t) != c; b = b.overflow(t) { } i = abi.OldMapBucketCount - 1 } else { i-- } if b.tophash[i] != emptyOne { break } }
// overLoadFactor reports whether count items placed in 1<<B buckets is over loadFactor. funcoverLoadFactor(count int, B uint8)bool { return count > abi.OldMapBucketCount && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen) }
// tooManyOverflowBuckets reports whether noverflow buckets is too many for a map with 1<<B buckets. // Note that most of these overflow buckets must be in sparse use; // if use was dense, then we'd have already triggered regular map growth. functooManyOverflowBuckets(noverflow uint16, B uint8)bool { // If the threshold is too low, we do extraneous work. // If the threshold is too high, maps that grow and shrink can hold on to lots of unused memory. // "too many" means (approximately) as many overflow buckets as regular buckets. // See incrnoverflow for more details. if B > 15 { B = 15 } // The compiler doesn't see here that B < 16; mask B to generate shorter shift code. return noverflow >= uint16(1)<<(B&15) }
// A hash iteration structure. // If you modify hiter, also change cmd/compile/internal/reflectdata/reflect.go // and reflect/value.go to match the layout of this structure. type hiter struct { key unsafe.Pointer // Must be in first position. Write nil to indicate iteration end (see cmd/compile/internal/walk/range.go). elem unsafe.Pointer // Must be in second position (see cmd/compile/internal/walk/range.go). t *maptype h *hmap buckets unsafe.Pointer // bucket ptr at hash_iter initialization time bptr *bmap // current bucket overflow *[]*bmap // keeps overflow buckets of hmap.buckets alive oldoverflow *[]*bmap // keeps overflow buckets of hmap.oldbuckets alive startBucket uintptr// bucket iteration started at offset uint8// intra-bucket offset to start from during iteration (should be big enough to hold bucketCnt-1) wrapped bool// already wrapped around from end of bucket array to beginning B uint8 i uint8 bucket uintptr checkBucket uintptr clearSeq uint64 }
关键特性:
随机起始位置:防止依赖迭代顺序
快照机制:记录迭代开始时的 buckets 指针
扩容兼容:同时检查新旧桶,确保不重复/遗漏
6. 负载因子选择
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// Picking loadFactor: too large and we have lots of overflow // buckets, too small and we waste a lot of space. I wrote // a simple program to check some stats for different loads: // (64-bit, 8 byte keys and elems) // loadFactor %overflow bytes/entry hitprobe missprobe // 4.00 2.13 20.77 3.00 4.00 // 4.50 4.05 17.30 3.25 4.50 // 5.00 6.85 14.77 3.50 5.00 // 5.50 10.55 12.94 3.75 5.50 // 6.00 15.27 11.67 4.00 6.00 // 6.50 20.90 10.79 4.25 6.50 // 7.00 27.14 10.15 4.50 7.00 // 7.50 34.03 9.73 4.75 7.50 // 8.00 41.10 9.40 5.00 8.00 // // %overflow = percentage of buckets which have an overflow bucket // bytes/entry = overhead bytes used per key/elem pair // hitprobe = # of entries to check when looking up a present key // missprobe = # of entries to check when looking up an absent key
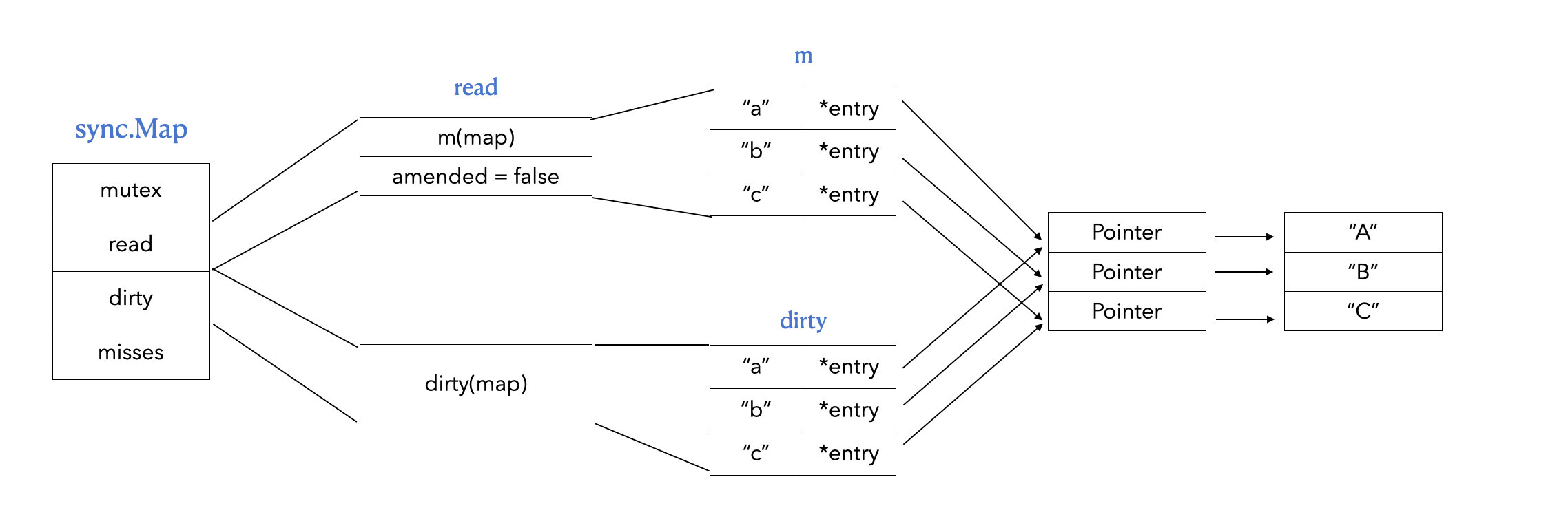
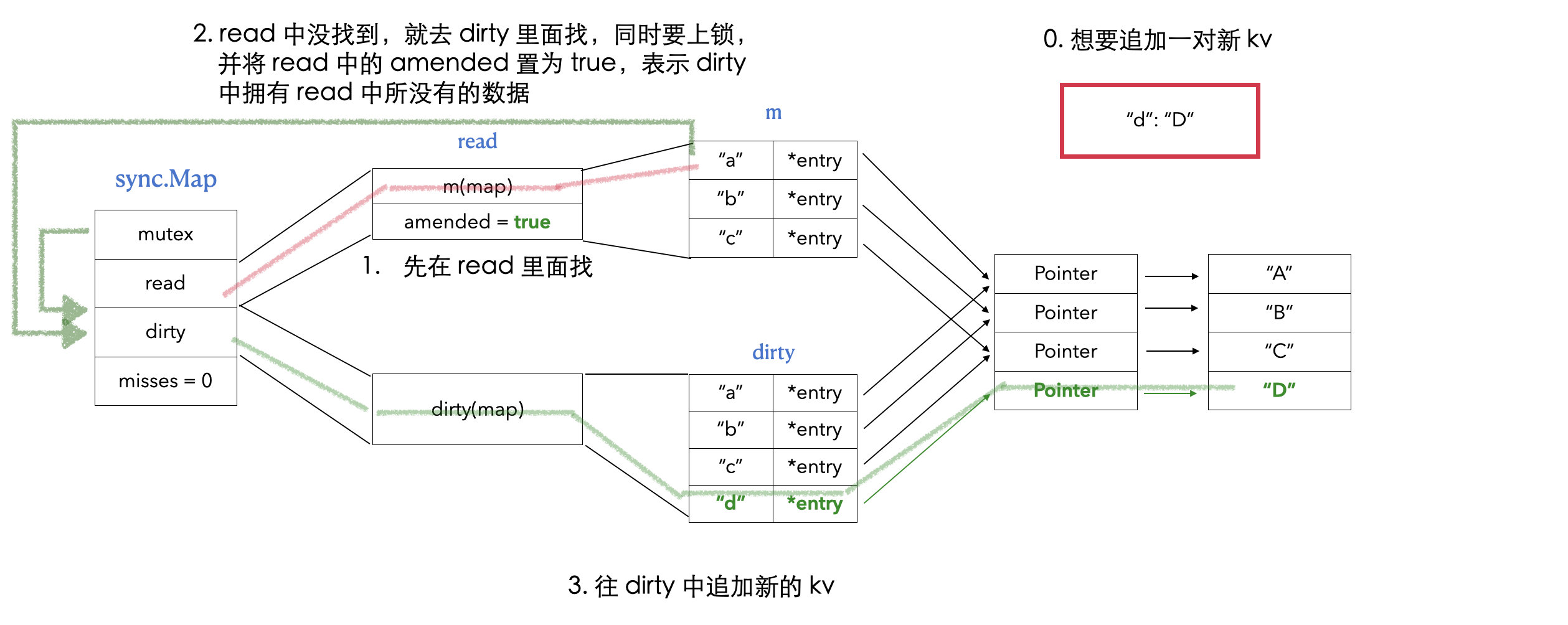
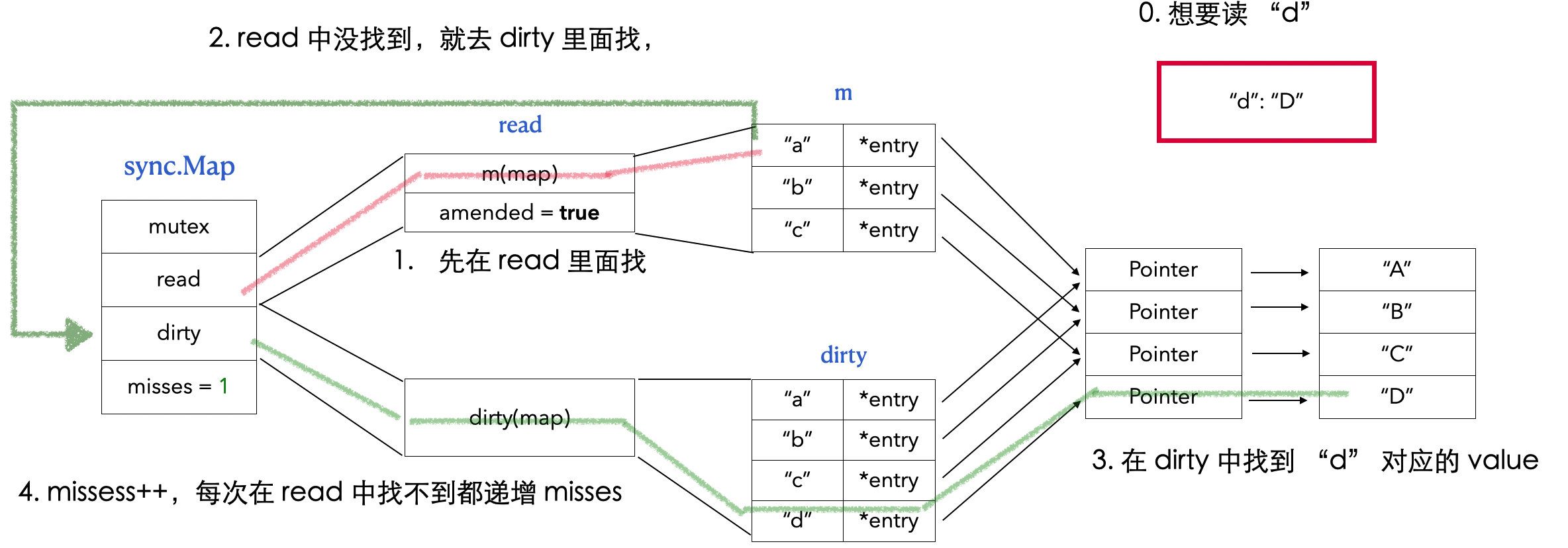
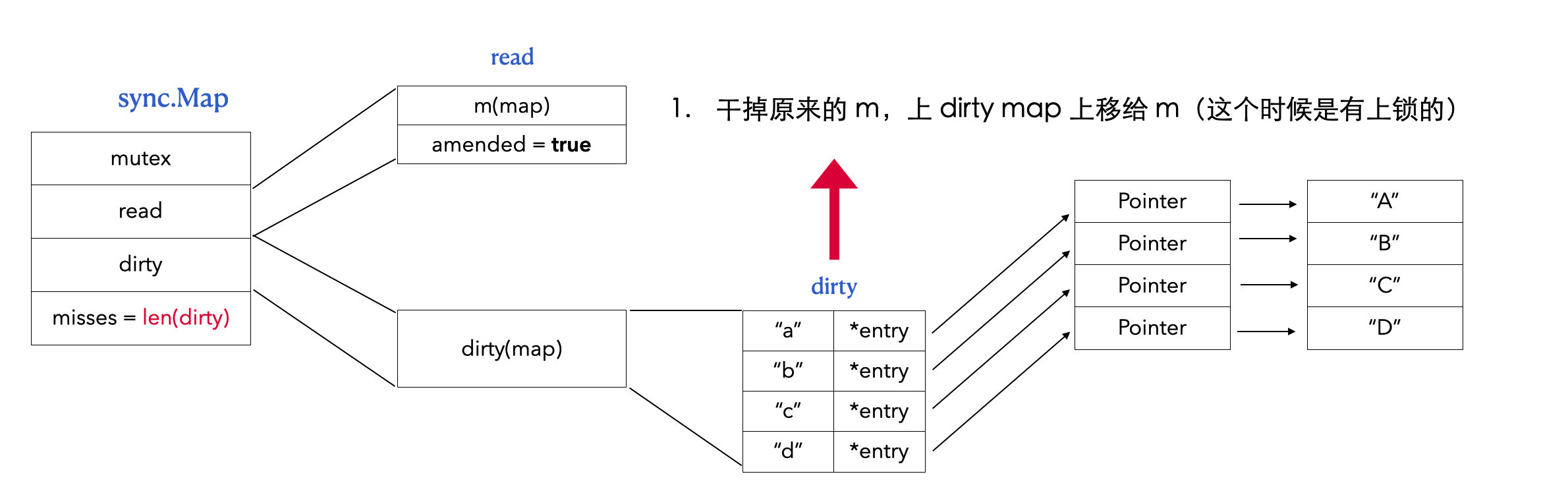
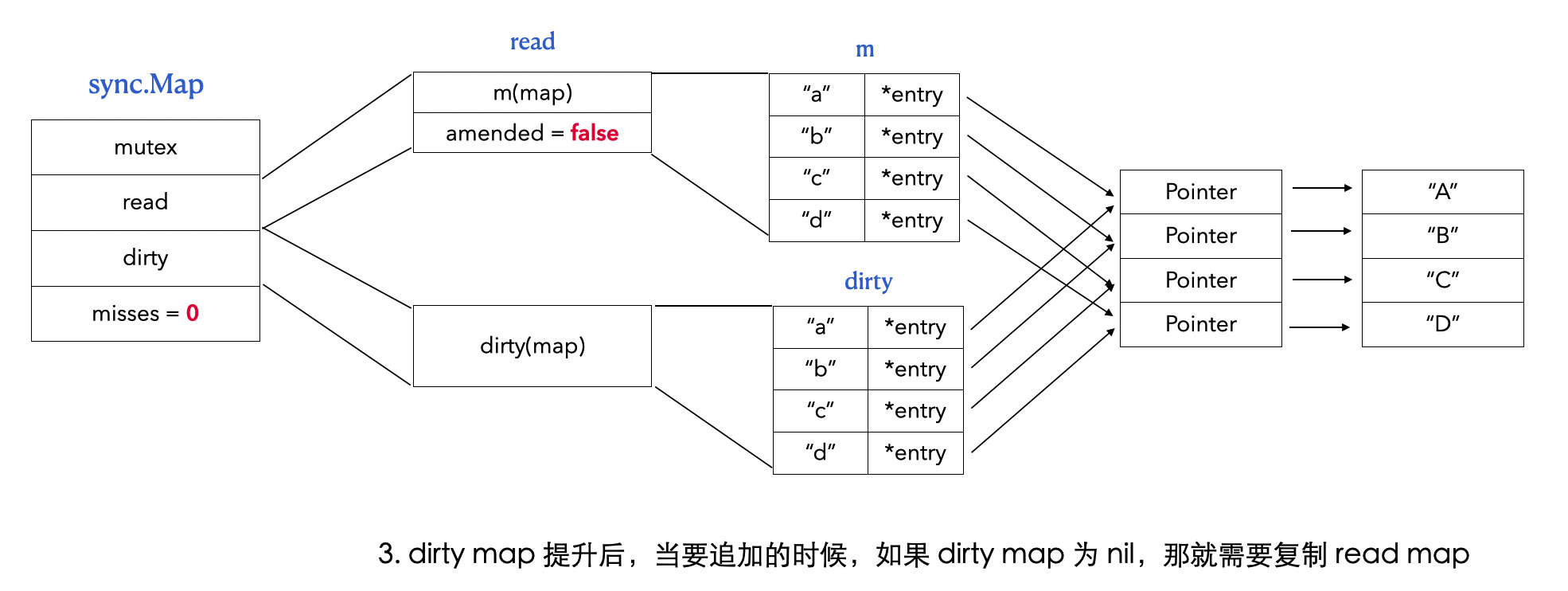
// readOnly is an immutable struct stored atomically in the Map.read field. type readOnly struct { m map[any]*entry // 存储 map 数据 amended bool// 当 dirtyMap 中有 m 没有的元素的时候,amended 值为 true }
entry
1 2 3
type entry struct { p unsafe.Pointer // 万能指针,指向 value }
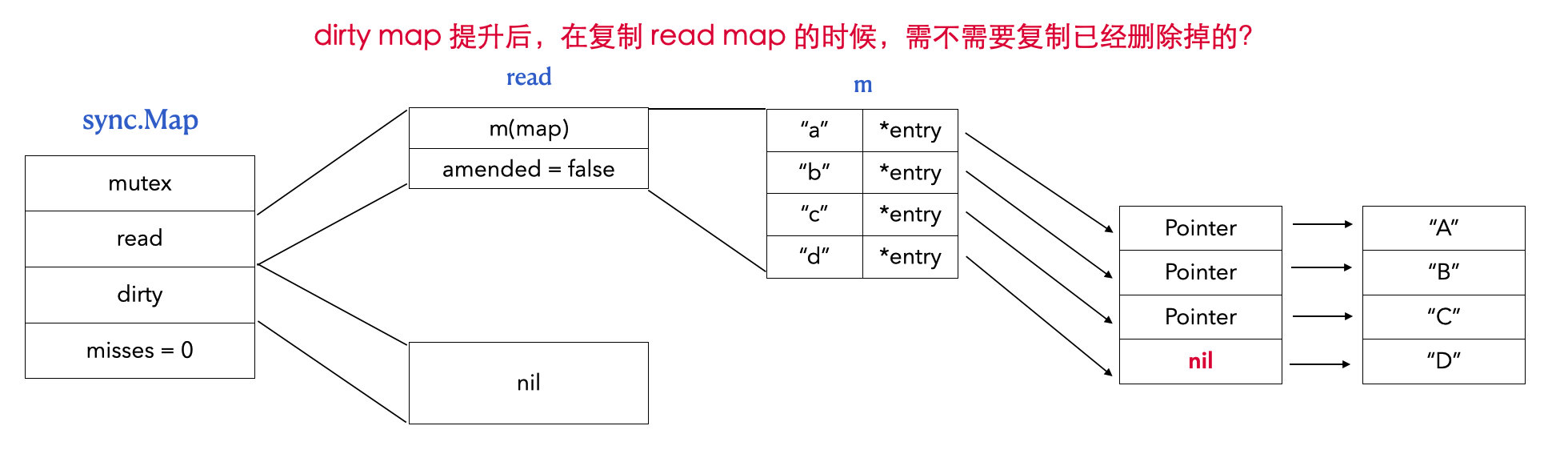
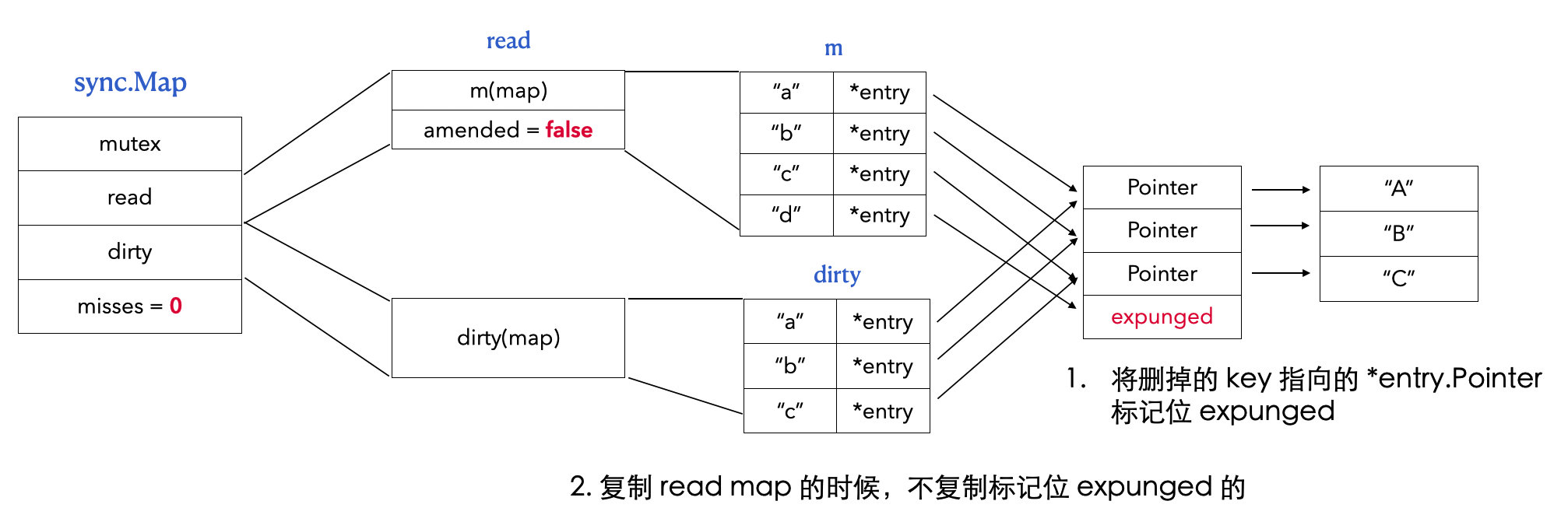
read, _ := m.read.Load().(readOnly) m.dirty = make(map[interface{}]*entry, len(read.m)) for k, e := range read.m { if !e.tryExpungeLocked() { m.dirty[k] = e } } }
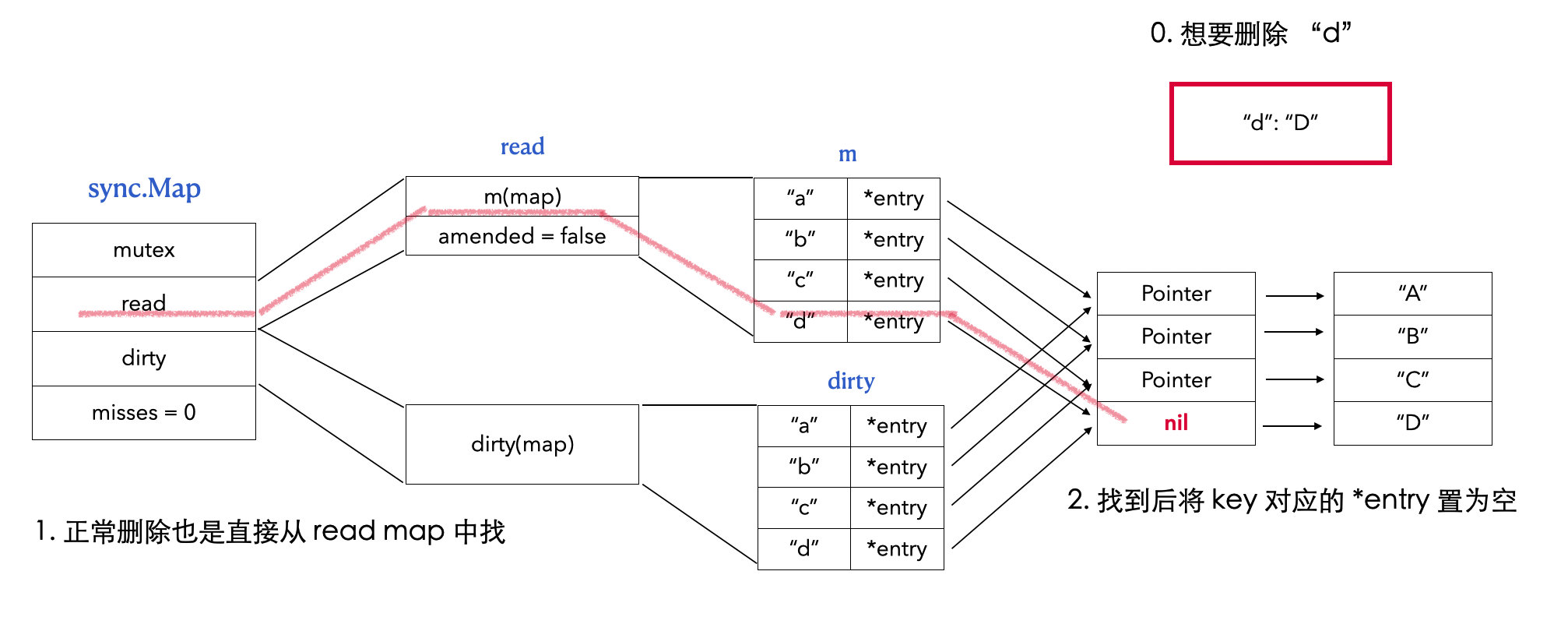
// Delete deletes the value for a key. func(m *Map) Delete(key interface{}) { m.LoadAndDelete(key) }
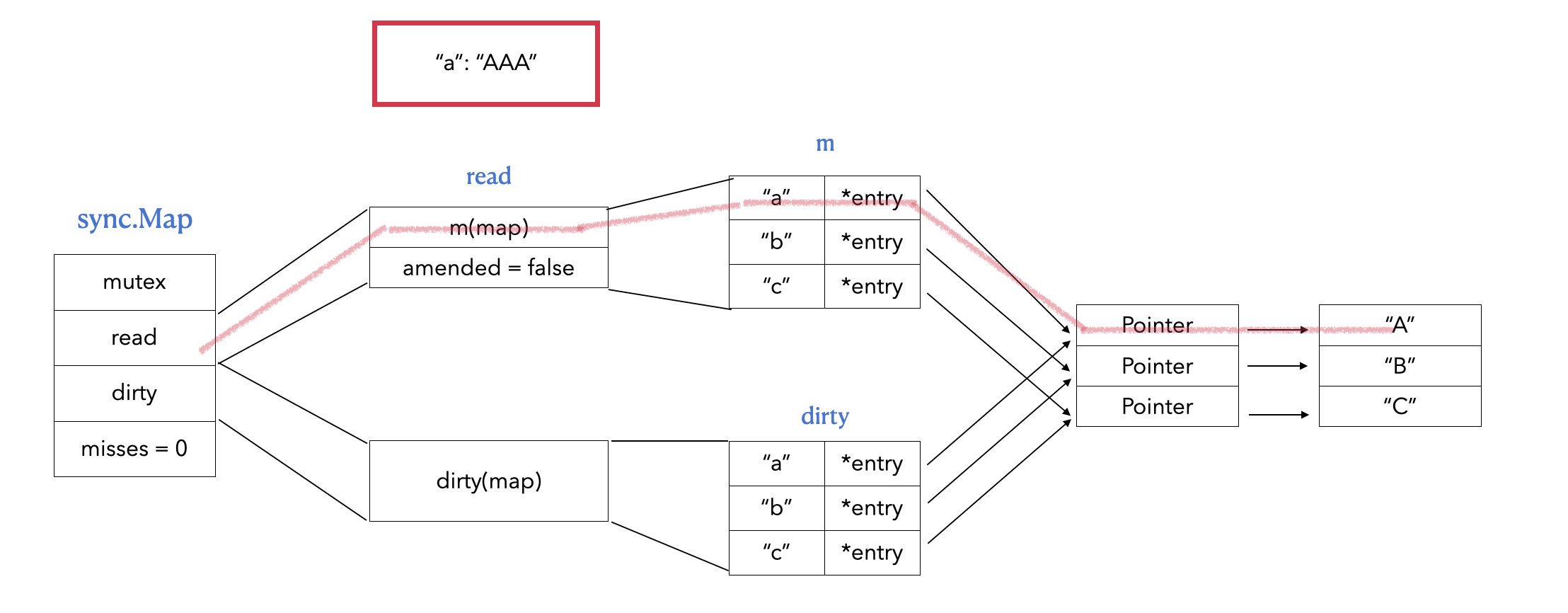
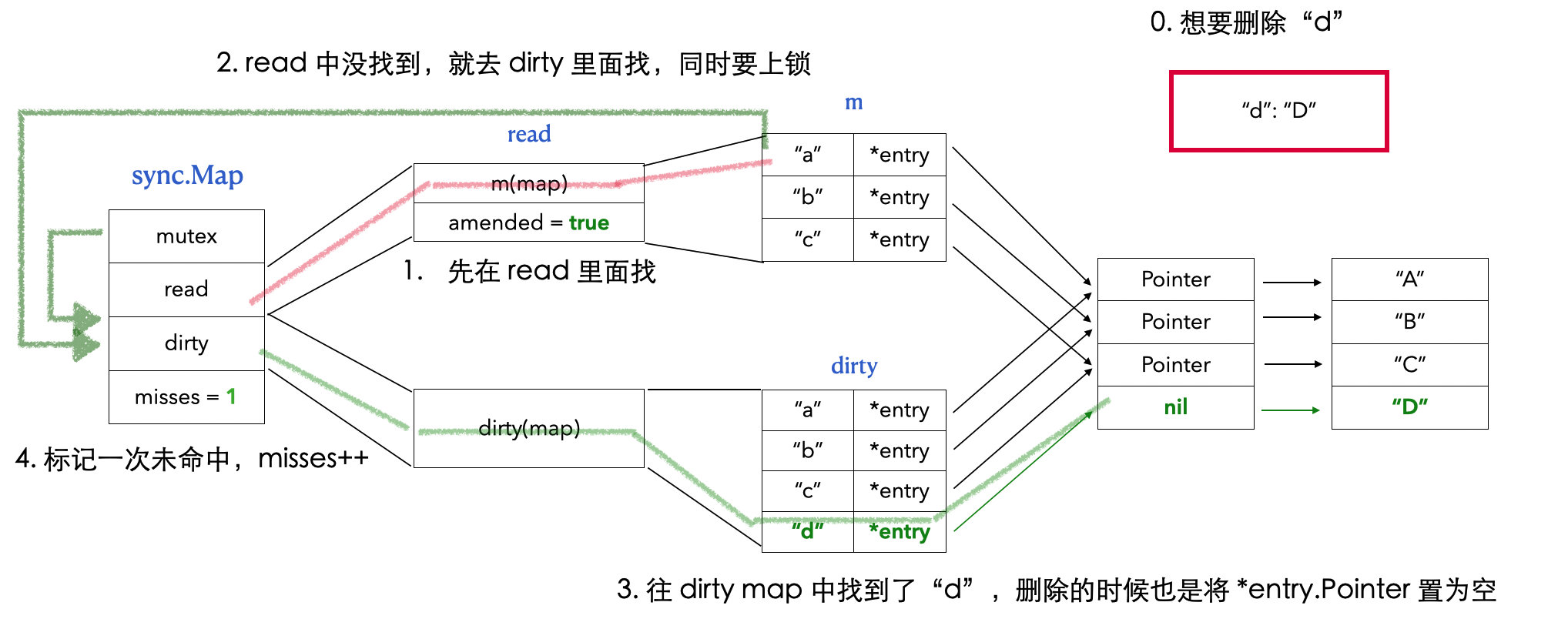
// LoadAndDelete deletes the value for a key, returning the previous value if any. // The loaded result reports whether the key was present. func(m *Map) LoadAndDelete(key interface{}) (value interface{}, loaded bool) { read, _ := m.read.Load().(readOnly) // 1. 先从 read map 中找 e, ok := read.m[key] ... // 2. 找到了,就直接在 read map 中删除 if ok { return e.delete() } returnnil, false }
func(e *entry)delete() (value interface{}, ok bool) { for { p := atomic.LoadPointer(&e.p) if p == nil || p == expunged { returnnil, false } // 3. 直接将 *entry 的 Pointer 置为空 if atomic.CompareAndSwapPointer(&e.p, p, nil) { return *(*interface{})(p), true } } }





 - HedonWang&pics=/banner/go-map-no-swiss.jpg&summary=本文系统解析 Go map(非 swiss 版本)的底层实现,涵盖数据结构、寻址与扩容、哈希冲突处理、迭代语义与适用场景,并对 sync.Map 的设计取舍与实现要点进行对照说明。)


