
特此声明,本篇是笔者基于 Go 1.25.3 版本源码、并与 Google Gemini 3Pro 共创所作,非常庆幸在当今 AI 时代下获取知识已是如此便利,且也为学习者从第一性原理理解所学知识大大降低了门槛。不过本篇的篇章安排和叙述逻辑,均由笔者把控和审阅,欢迎放心阅读。
1. 垃圾回收
抛开具体的语言,垃圾回收(GC)在计算机科学中解决的核心问题只有一个:对象生命周期的自动化管理。
如果手动管理内存(如 C/C++ 的
malloc/free),我们面临的是由于"人为疏忽"导致的两个极端错误:
- 悬挂指针(Dangling Pointer):过早释放,导致后续访问出错。
- 内存泄漏(Memory Leak):忘记释放,导致资源耗尽。
GC 的出现,是为了将"判断内存是否不再使用"这个逻辑,从业务代码剥离,下沉到运行时(Runtime)。
从大的方面来讲,实现垃圾回收主要是要解决 2 个问题:
- 怎么判断哪些对象是垃圾?
- 如何清理垃圾?
1.1 垃圾搜索算法
从原理上讲,一个对象被判定为垃圾,意味着当前程序的后续执行中,再也无法访问到它了。这在计算机科学中被称为对象存活性(Object Liveness)问题。
主要有 2 个思路:引用计数法和可达性分析。
1.1.1 引用计数法
- 给每个对象贴一个计数器。只要有一个地方引用它,计数器就 +1;引用失效(比如指针置空或离开作用域),计数器就 -1。当计数器归零时,该对象即为垃圾。一旦变成垃圾,立刻就能被回收,不需要等待特定的 GC 时间点。
- 但是存在循环引用的缺陷:假如对象 A 引用 B,B 也引用 A,除此之外没有其他人引用它们。虽然它们在外部已经无法访问(本质是垃圾),但它们互相揪着对方,计数器永远是 1,导致内存泄漏。
- CPython(Python 的解释器)的主力 GC
机制就是引用计数,但它配合了"标记-清除"来专门处理循环引用问题。PHP 和
C++ 的
std::shared_ptr也是基于此思路。
1.1.2 可达性分析

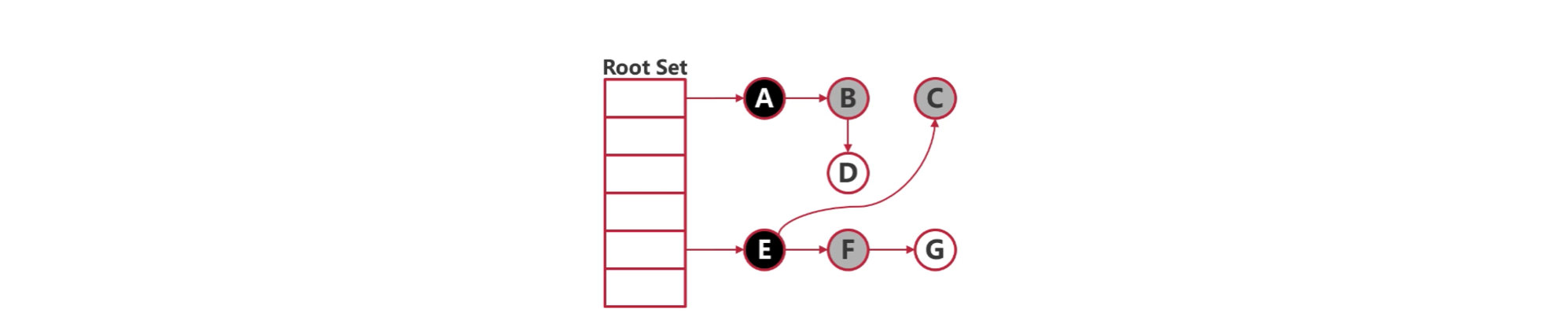
- 从根(GC Roots)节点向下搜索对象节点,搜索走过的路经称为引用链,当一个对象到根之间没有连通的话,则对象不可用。
- 可以作为 GC Roots
的对象通常是指那些肯定在使用中的对象:
- 被栈上的指针引用;
- 被全局变量的指针引用;
- 被寄存器中的指针引用;
- 可达性分析的核心挑战是在遍历过程中,如果程序还在运行(对象引用关系在变),图就在变,怎么保证准确性?传统的做法是 STW (Stop The World),暂停所有用户线程专门来做 GC。现代的做法是 三色标记法 (Tri-color Marking)(如 Go 语言),允许 GC 线程和用户线程并发运行,用读写屏障(Barrier)技术来修正并发带来的标记误差,从而尽可能减少 STW 的时长。
1.2 垃圾回收算法
找出了垃圾,下一步就是回收内存。这里的核心矛盾是:效率 vs 空间碎片。
1.2.1 标记清理法
算法分成 标记 和 清除 两个阶段,先标记出要回收的对象,然后统一回收这些对象。
- 简单。
- 效率不高,标记和清除的效率都不高。
- 标记清除后会产生大量不连续的内存碎片,从而导致在分配大对象时触发 GC。
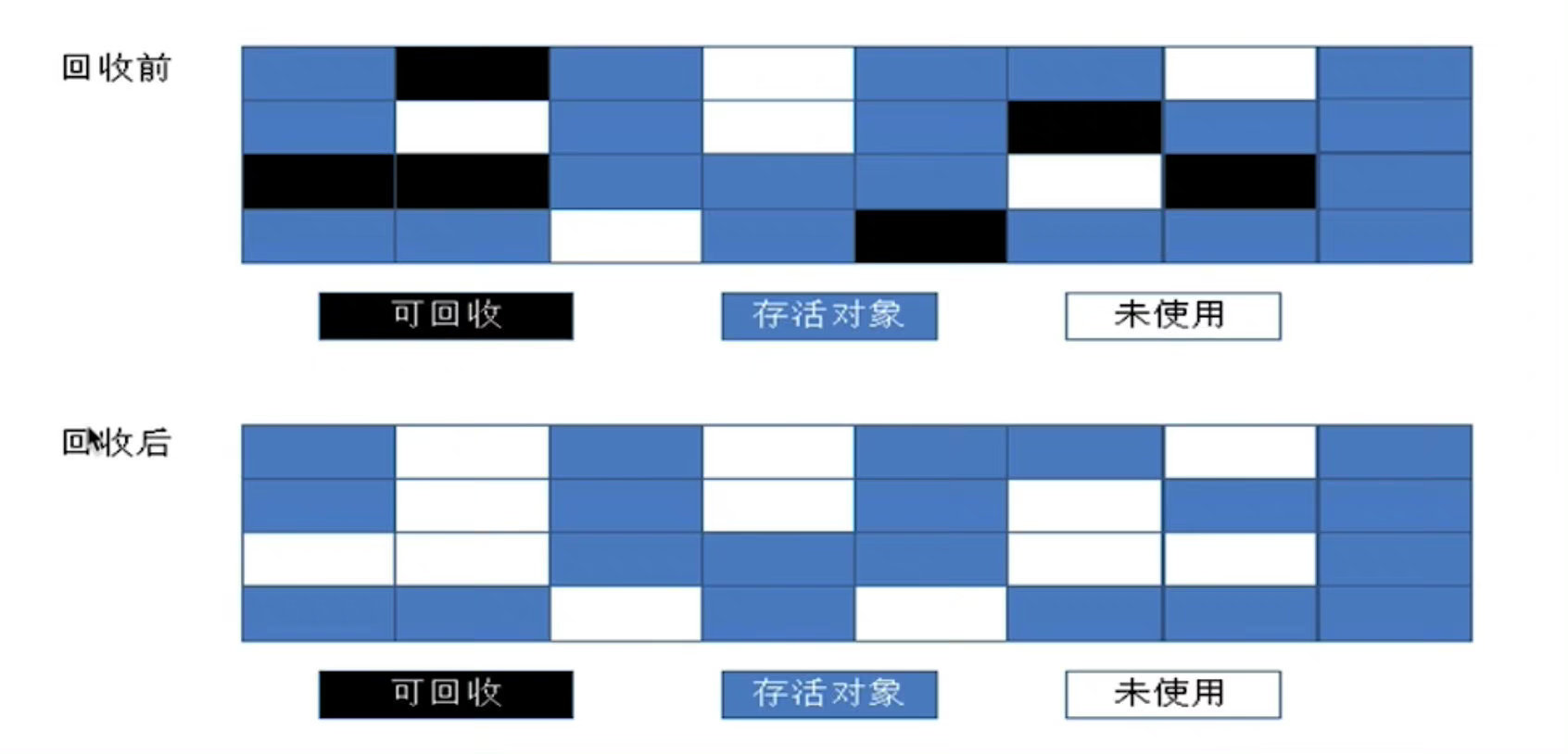
Go 使用的就是标记清除法
虽然普通的标记清除法会造成内存碎片的问题,但是由于 Go 的内存模型中,将内存天然划分成多个 span,所以不存在内存碎片问题。故 Go 用了这种实现简单的标记清除法。对于 Go 内存模型不熟悉的读者,可参阅:Go 底层原理丨内存模型。
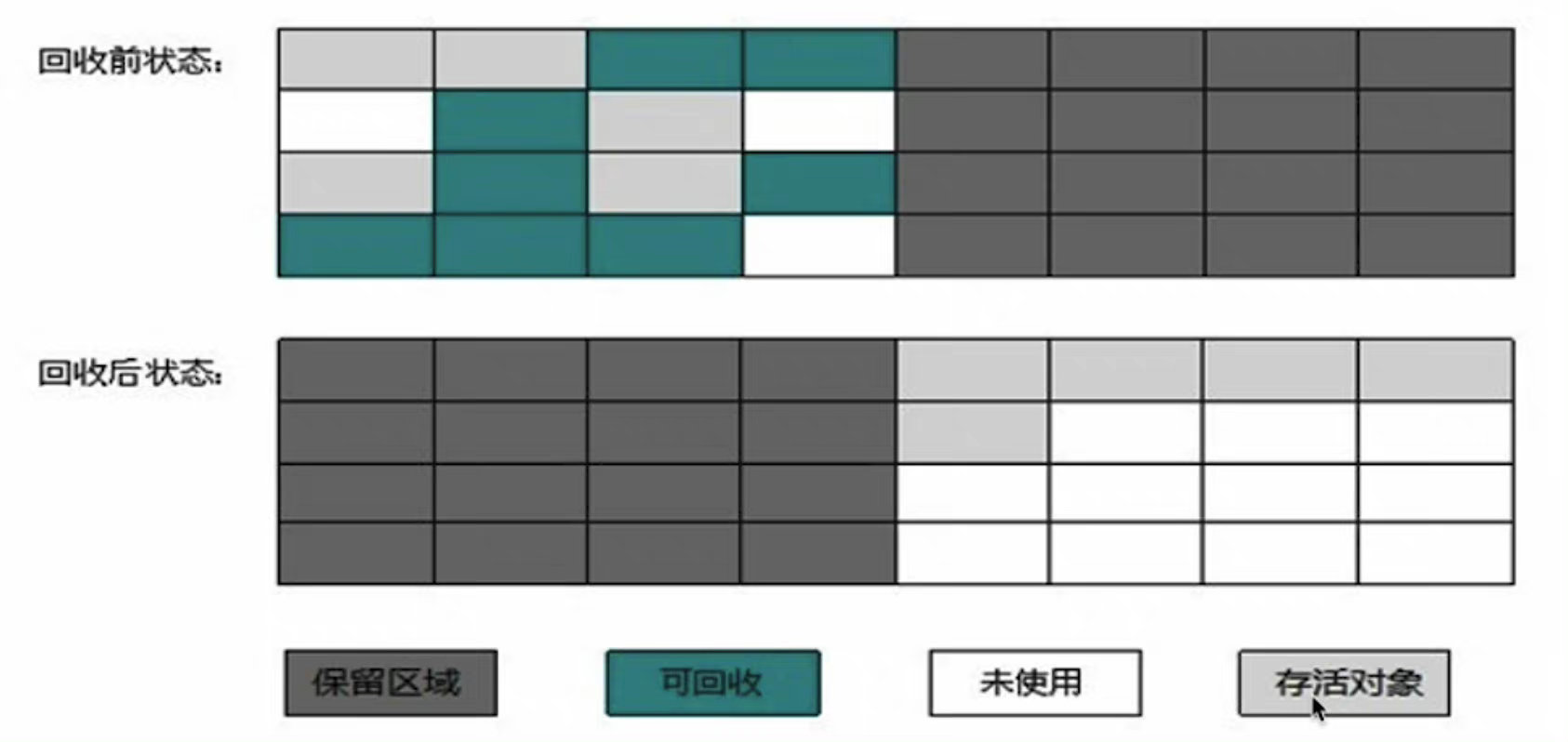
1.2.2 标记复制法
把内存分成两块完全相同的区域,每次使用其中一块,当一块使用完了,就把这块上还存活的对象拷贝到另外一块,然后把这块清除掉。
- 实现简单、运行高效,不用考虑内存碎片的问题。
- 内存有些浪费。
JVM 实际实现中,是将内存分为一块较大的 Eden 区和两块较小的 Survivor 空间,每次使用 Eden 和一块 Survivor,回收时,把存活的对象复制到另外一块 Survivor。
HotSpot 默认的 Eden 和 Survivor 比是 8:1,也就是每次能用 90% 的新生代空间。
如果 Survivor 空间不够,就要依赖老年代进行分配担保,把放不下的对象直接进入老年代。
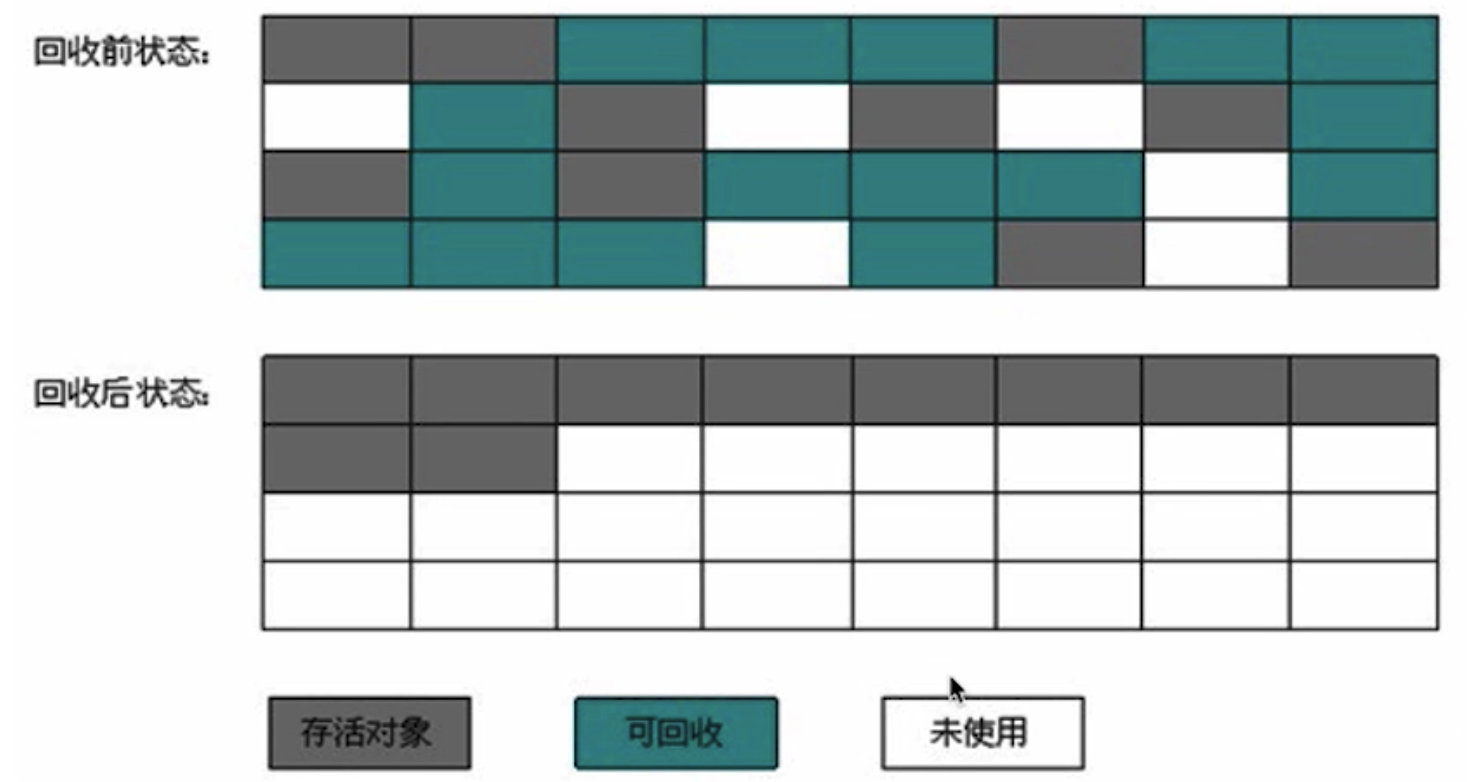
1.2.3 标记整理法
标记过程跟标记清除一样,但后续不是直接清除可回收对象,而是让所有存活对象都向一端移动,然后直接清除边界以外的内存。
标记整理法的开销较大,Java 的老年代就采用标记整理法,因为老年代的 GC 频率较低。
2. 宏观概述
在对 GC 有了一个简单的了解之后,我们先来详细了解 Go 语言的垃圾回收机制的宏观详细设计,在下一章节我们将在 AI 的帮助下,深入源码(Go1.25.3)去了解去背后的底层实现细节和那些令人叹为观止的优化思路。
截止 Go1.25,Go 还是使用的三色标记法 + 并发标记清理法 + 混合写屏障进行垃圾回收,Go 官方透露在 Go1.26 将默认开启 Green Tea GC,关于 Green Tea GC,将会在下篇进行详细展开。
2.1 核心架构特征
- 并发标记-清扫(Concurrent Mark-Sweep)
- 类型精确(Type Accurate):知道内存中哪些是指针
- 写屏障(Write Barrier):保证并发标记的正确性
- 非分代(Non-generational)
- 非压缩(Non-compacting)
- Per-P 分配:减少锁竞争
2.2 三色标记法
2.2.1 基本原理
Go 将对象用三种颜色来进行标记:
- 黑色:本对象已经被 GC 访问过,且本对象的子引用对象也已经被访问过了
- 灰色:本对象已访问过,但是本对象的子引用对象还没有被访问过,全部访问完会变成黑色,属于中间态
- 白色:尚未被 GC 访问过的对象,如果全部标记已完成依旧为白色的,称为不可达对象,既垃圾对象
2.2.2 基本步骤
- 起初所有堆上的对象都是【白色】的;
- 将 GC Roots 直接引用到的对象挪到【灰色】中;
- 对【灰色】的对象进行根搜索算法:
- 将该对象引用到的其他对象加入【灰色】中;
- 将自己挪到【黑色】中;
- 重复 3 直到【灰色】为空;
- 回收【白色】中的对象。
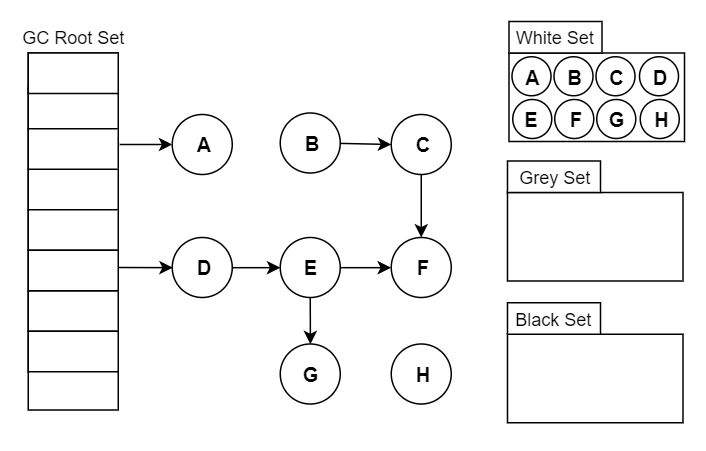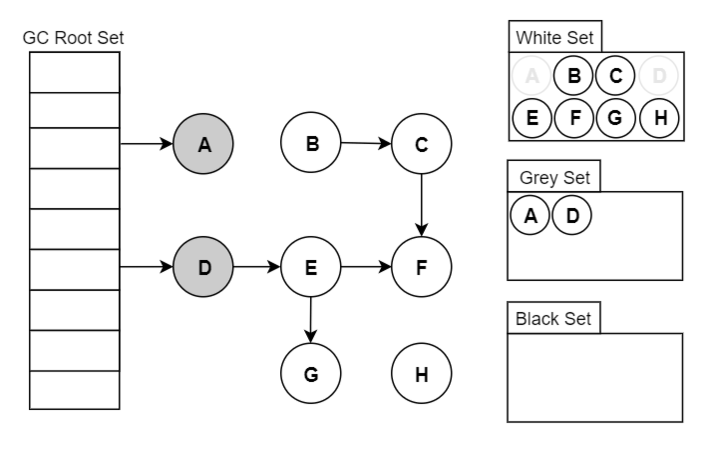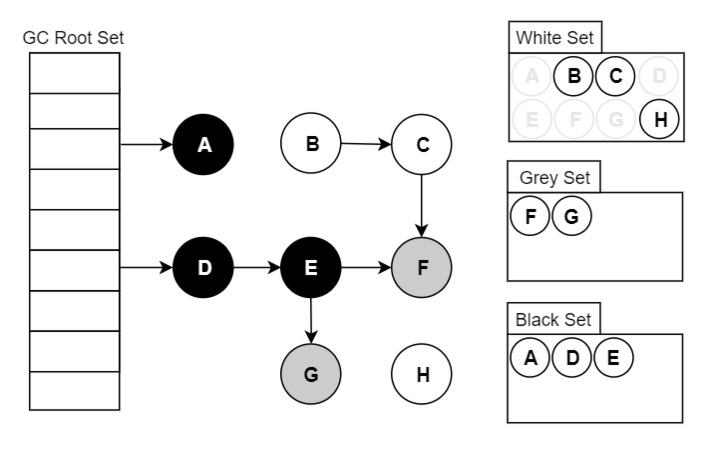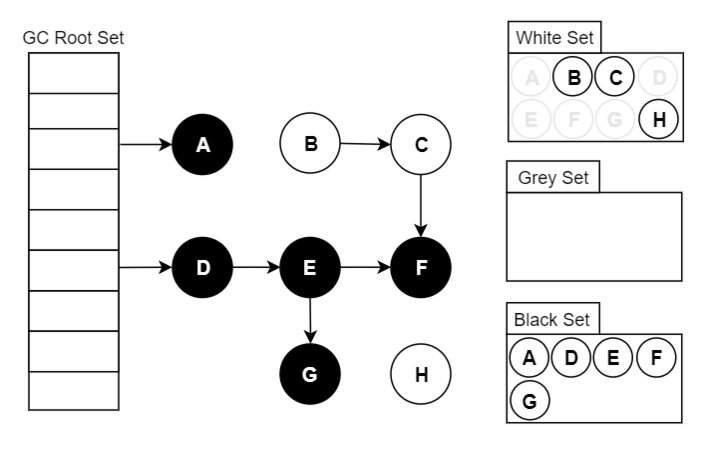
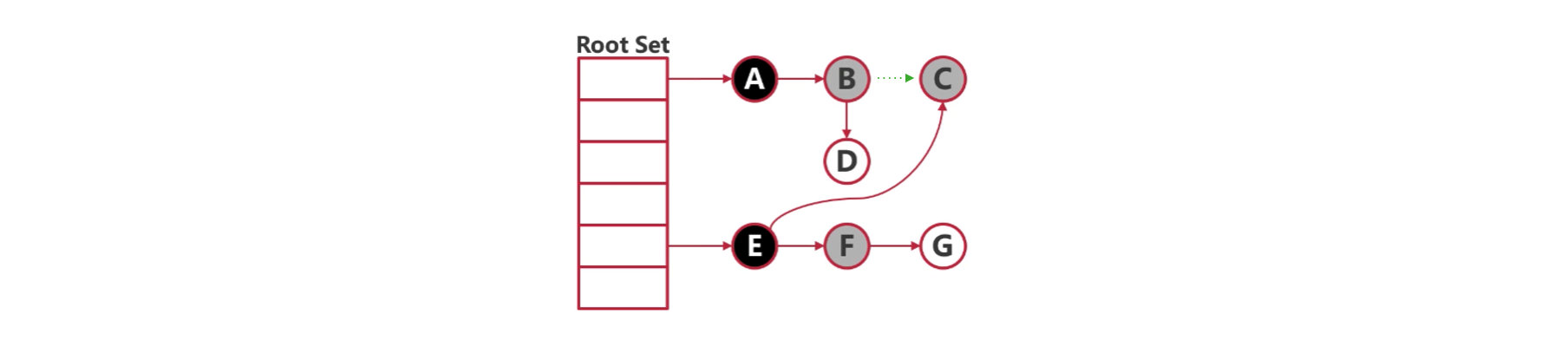
2.2.3 删除屏障
并发标记时,对指针释放的白色对象置灰。
这样可以避免在并发 GC 的过程中,由于指针的转移造成对象被误清。
比如一开始 B → C,当 B 在灰色集合的时候,释放了对 C 的指针,但是这个时候有一个在黑色集合的 E 指向了 C,也就是 E → C。由于 E 已经分析过了,所以在对 B 进行分析的时候,就会漏掉 C,导致后面 C 还是在白色集合中,就被误清了。
加入删除屏障后,C 会被强制置灰,就不会误清了。
2.2.4 插入屏障
并发标记时,对指针新指向的白色对象置灰。
这样可以避免在并发 GC 的过程中,误清掉指针新指向的对象。
比如一开始并没有指向 C 的对象,但是在 GC 过程中,E → C,但是由于 E 已经分析过了,已经进入黑色集合了,所以最后会漏掉 C,导致 C 被误清。
加入插入屏障后,C 会被强制置灰,就不会误清了。
2.3 GC 四阶段循环
graph TB
%% 定义样式
classDef stw fill:#ffcdd2,stroke:#c62828,stroke-width:2px,color:#b71c1c;
classDef concurrent fill:#e1f5fe,stroke:#0277bd,stroke-width:2px,color:#01579b;
classDef trigger fill:#fff9c4,stroke:#fbc02d,stroke-dasharray: 5 5,color:#f57f17;
%% 节点定义
subgraph Cycle [GC 循环周期]
direction TB
P1(Phase 1: Sweep Termination
清扫终止):::stw
P2(Phase 2: Concurrent Mark
并发标记):::concurrent
P3(Phase 3: Mark Termination
标记终止):::stw
P4(Phase 4: Concurrent Sweep
并发清扫):::concurrent
end
%% 触发条件
Trigger(GC Trigger
堆阈值/定时/手动):::trigger
%% 连线关系
Trigger --> P1
P1 -->|开启写屏障
SetGCPhase: _GCmark| P2
P2 -->|所有对象标记完成
gcMarkDone| P3
P3 -->|关闭写屏障
SetGCPhase: _GCoff| P4
P4 -->|清理结束 & 等待下一轮| Trigger
%% 补充说明
note1[STW: 准备根对象, 清理上一轮残余] -.-> P1
note2[STW: 保证全局标记完成, 必须全局一致] -.-> P3
2.4 GC 触发机制
- 堆大小触发:GOGC=100 时,堆增长 100% 触发(4M→8M)
- 定时触发:sysmon 会定时检查,如果 2min 内没有进行 gc,那 runtime 就会进行一次 gc。
- 手动触发:
runtime.GC()
3. 源码解析
结论先行,整个 GC 的全景图如下所示:
1 | ┌─────────────────────────────────────────────────────────────┐ |
3.1 GC 触发 gcStart()
GC 的触发通过 gcTrigger 机制来检测三种条件:
1 | type gcTrigger struct { |
当 gcTrigger.test()
返回 true 时,就会执行 gcStart() 函数:
1 | func (t gcTrigger) test() bool { |
gcStart() 函数的核心流程:
1 | func gcStart(trigger gcTrigger) { |
3.2 并发标记 gcBgMarkWorker
在上面 gcStart() 中,会调用 gcBgMarkStartWorkers()
准备后台标记工作者:
1 | func gcBgMarkStartWorkers() { |
它的逻辑很简单,就是为每一个 P 调用一个 gcBgMarkWorker(ready):
1 | func gcBgMarkWorker(ready chan struct{}) { |
gcBgMarkWorker() 主要包含 2 个核心逻辑:
根据不同标记的工作者类型调用不同的标记函数,如
gcDrainMarkWorkerDedicated()、gcDrainMarkWorkerFractional()和gcDrainMarkWorkerIdle()。而事实上,这 3 个函数,都是调用了gcDrain()。gcDrain()函数是 GC 标记阶段的核心工作循环,负责"排空"(drain)标记工作队列,将灰色对象扫描并标记为黑色。这是标记工作者执行实际标记工作的主要函数。调用层级如下所示:
1
2
3
4
5
6gcBgMarkWorker (后台工作者)
└─> gcDrainMarkWorkerDedicated/Fractional/Idle
└─> gcDrain
├─> markroot (扫描根对象)
├─> scanobject (扫描堆对象)
└─> scanSpan (扫描 span)检测标记终止:
gcMarkDone(),我们将在 3.3 章节进行详细展开。
3.2.1 标记工作者类型 gcMarkWorkerMode
Go GC 使用三种类型的标记工作者:
gcMarkWorkerDedicatedMode:专用标记工作者,持续标记直到没有更多工作或被抢占。gcMarkWorkerFractionalMode:分数标记工作者,按照目标使用率工作。gcMarkWorkerIdleMode:空闲标记工作者,仅在 P 空闲时工作。
1 | switch pp.gcMarkWorkerMode { |
3.2.2 标记工作队列 gcWork
gcWork
是 GC 标记工作的生产者-消费者接口,每个 P 都有自己的
gcWork,通过双缓冲减少全局队列竞争。
1 | type gcWork struct { |
它有两个核心方法:
putObj():将一个灰色对象加入工作队列(生产)tryGetObj():从工作队列取出一个灰色对象(消费)
1 | // putObj 将一个灰色对象加入工作队列(生产) |
设计要点:
- 双缓冲机制:减少对全局队列的访问频率,降低锁竞争
- 本地优先:优先使用 P 本地缓冲区,只在必要时访问全局队列
- 滞后效应:一个缓冲区的容量作为滞后,摊销获取/放回缓冲区的成本
3.2.3 根对象扫描准备 gcPrepareMarkRoots()
在 gcStart() 的时候,会先执行 gcPrepareMarkRoot()
扫描根对象,即所谓的 GC Roots,如我们前面的可达性分析章节所述, GC Roots
的对象通常是指那些肯定在使用中的对象:
- 被栈上的指针引用
- 被全局变量的指针引用
- 被寄存器中的指针引用
1 | func gcPrepareMarkRoots() { |
3.2.4 标记循环 gcDrain()
前面我们提到 gcDrain() 函数是 GC 标记阶段的核心工作循环,负责"排空"(drain)标记工作队列,将灰色对象扫描并标记为黑色。它的核心流程很简单,就是从工作队列中持续取出灰色对象进行扫描,直到满足退出条件:
- 工作队列为空
- 被抢占(如果允许抢占)
- 满足退出条件(空闲/分数模式)
1 | func gcDrain(gcw *gcWork, flags gcDrainFlags) { |
关键设计点:
- 工作优先级:
P-local workbuf→P-local span→全局 workbuf→全局 span,优先使用本地缓存,减少全局竞争。 - 工作平衡:防止工作集中在某个 P,其他 P 空闲。
- 抢占检查:响应抢占请求、STW 请求、forEachP 调用。
- 信用系统:后台标记工作产生"信用",Mutator assist 消耗"信用",平衡 GC 工作和应用程序分配。
gcDrain() 包含了 3 个最重要的子逻辑:
markroot(): 标记 GC 的根集(root set),这些是追踪的起点。scanobject():扫描一个堆对象,标记它引用的所有对象。scanSpan():扫描 span,批量处理 span 中的对象,这是 Green Tea GC 的优化,这个我们下一篇再进行展开。
3.2.5 标记根对象 markroot()
关键点:
根对象种类:全局变量(data/BSS)、栈、finalizer、cleanup、span specials
分片处理:大的根对象(如全局变量)被分成多个任务,并行处理
栈扫描:需要暂停 goroutine,扫描后恢复
1 | // markroot 标记第 i 个根对象任务 |
3.2.6 对象扫描 scanobject()
关键点:
Oblet 机制:大对象(>128KB)被拆分成多个 oblet,每个 ≤128KB
优势:提高并行性,降低扫描延迟(~100µs)
其他 oblet 被放入工作队列,可能被其他工作者处理
类型指针迭代器:高效遍历对象中的指针字段,跳过标量字段
快速过滤:过滤 nil 和自引用,减少不必要的
findObject调用
1 | // scanobject 扫描地址 b 处的对象,将其变黑,并将引用的对象变灰 |
3.2.7 对象标记 greyobject()
scanobject() 会将正在扫描的堆对象引用的对象调用
greyobject() 将其从白色标记为灰色。
关键点:
幂等性:重复标记同一对象是安全的(已标记则直接返回)
原子操作:标记位和页位图的设置都是原子的,支持并发标记
noscan 优化:没有指针的对象直接变黑,不入队
预取优化:将对象预取到缓存,提高后续扫描性能
1 | // greyobject 将对象 obj 标记为灰色 |
3.2.8 并发标记小节
gcDrain
的核心逻辑是一个消费循环。它从本地或全局的工作缓冲区(gcWork)中提取指针(灰色对象),并调用
scanobject
对其进行处理。其工作流可以形式化为以下几个步骤:
- 本地获取(Local Fetch):首先尝试从当前 P 的本地
gcWork缓存中获取工作。这是一个无锁操作(Lock-free),效率极高。 - 全局获取与窃取(Global Fetch &
Steal):如果本地缓存为空,
gcDrain必须尝试从全局队列获取工作,或者从其他 P 的本地队列中窃取工作。这一步涉及到跨 P 的协调,是锁竞争的高发区。 - 扫描与着色(Scan &
Shade):对获取到的每一个对象调用
scanobject,识别其引用的子对象,并通过greyobject将子对象加入工作队列(即着色为灰色)。 - 抢占检查(Preemption
Check):为了保证调度的公平性,
gcDrain会周期性地检查是否需要让出 P。
整个 gcDrain() 的标记循环流程可以总结为如下图所示:
graph LR
A[灰色对象队列] -->|取出| B[gcDrain]
B --> C[扫描函数]
C -->|markroot| D[扫描根]
C -->|scanobject| E[扫描对象]
C -->|scanSpan| F[扫描Span]
D --> G[greyobject]
E --> G
F --> G
G -->|白→灰| H[设置标记位]
H -->|入队| A
style B fill:#e1f5ff,stroke:#0277bd,stroke-width:3px
style G fill:#ffebee,stroke:#c62828,stroke-width:3px
style A fill:#fff9c4,stroke:#f57f17,stroke-width:2px
3.3 标记终止检测 gcMarkDone()
为了进入并发清理阶段,需要先确保所有标记已经终止,即 Mark Termination。这是最复杂的阶段,Go 使用分布式终止算法和 Ragged Barrier 来确保所有标记工作完成。
所谓检测并发标记阶段是否完成,即确认所有可达对象都已标记,没有遗漏的灰色对象。
在并发环境中,标记工作分散在多个位置:
P-local buffers:每个 P 的 gcWork 缓冲区
Global work queues:全局工作队列 work.full
Write barrier buffers:写屏障缓冲区 wbBuf
Root scan jobs:根对象扫描任务
那么问题就来了:如何在不停止世界的情况下,确保检查所有缓冲区时,不会有新的工作产生?
[!IMPORTANT]
gcMarkDone()通过"检查所有工作者空闲(nwait==nproc)且全局队列为空 → Ragged Barrier 同步刷新所有 P 的写屏障缓冲和工作队列到全局 → STW 后验证写屏障无残留工作"的三步循环检测,任一步骤发现新的灰色对象就回到起点重新检测,直到确认不存在任何隐藏的本地工作和灰色对象后才进入标记终止阶段。
下面是 gcMarkDone() 的源码解析:
1 | func gcMarkDone() { |
这里再简单解释一下 Ragged Barrier:
Ragged Barrier 是分布式系统中的一个同步原语,名字来源于它的行为特征:不同处理器/线程到达屏障的时间是"参差不齐"(ragged)的。
用一句话来解释就是 Ragged Barrier 是一种异步同步原语,让多个处理单元独立完成各自的本地状态刷新操作,无需等待其他单元,最终达到全局状态一致的目的。
在并发标记完成检测时,通过 Ragged Barrier 将所有 P 的本地缓冲区(写屏障缓冲和工作队列)刷新到全局,使隐藏的工作可见,从而能够正确判断是否真的没有剩余标记工作。
3.4 并发清理 gcSweep()
标记完成后,进入扫描阶段,gcSweep()
负责初始化和启动垃圾回收的扫描(清理)阶段,将未标记的对象回收,准备下一个
GC 周期。
gcSweep() 可以概括为:
- 递增 sweepgen(+2):建立新旧 GC 周期的边界
- 选择执行模式:同步立即完成 vs 并发后台进行
- 启动扫描机制:直接调用 sweepone() 或唤醒 bgsweep
1 | // 返回 bool:true = 同步扫描完成,false = 后台并发扫描 |
其中 sweepgen 是一个单调递增的计数器,用于追踪
span 的扫描状态,通过设置全局的
mheap_.sweepgen,可以巧妙区分不同状态的
span,从而避免重复扫描。
1 | sweepgen 的三种状态(对于当前 sweepgen = N): |
有两种扫描方式,分别是同步扫描和并发扫描,并发扫描实际上执行的是
bgsweep(),它们俩的核心逻辑都在
sweepone(),sweepone() 用于扫描单个
span:
1 | func sweepone() uintptr { |
核心逻辑都在 s.sweep(false)
中,它的核心职责是回收未标记的对象,准备 span
给下次分配使用。
1 | // sweep 回收未标记的对象,准备 span 给下次分配使用 |
处理流程可参考下图进行理解:
flowchart TD
Start([sweep 入口]) --> Verify[验证状态
sweepgen == global-1]
Verify --> Specials[处理 Specials]
Specials --> FinCheck{有 finalizer?}
FinCheck -->|是| Revive[复活对象
加入执行队列]
FinCheck -->|否| FreeSp[释放 specials]
Revive --> Zombie
FreeSp --> Zombie
Zombie[检查僵尸对象] --> ZombieCheck{存在?}
ZombieCheck -->|是| Error[throw]
ZombieCheck -->|否| Core
Core[核心: 位图交换]:::highlight
Core --> Swap["allocBits = gcmarkBits
gcmarkBits = new()"]:::highlight
Swap --> Update[更新 sweepgen
global-1 → global]
Update --> Classify[归类 span]
Classify --> CheckN{nalloc?}
CheckN -->|0| ToHeap[freeSpan
归还堆]
CheckN -->|nelems| ToFull[fullSwept
完全占满]
CheckN -->|其他| ToPartial[partialSwept
部分占用]
ToHeap --> RetTrue[return true]
ToFull --> RetFalse[return false]
ToPartial --> RetFalse
RetTrue --> End([结束])
RetFalse --> End
Error --> End
classDef highlight fill:#ffeb3b,stroke:#f57c00,stroke-width:3px
style Start fill:#4caf50,color:#fff
style End fill:#4caf50,color:#fff
3.5 计算下次触发点
GC 结束时,通过 pacer 计算下次触发点:
1 | // 在 gcController.endCycle 中计算 |
简单来说,Pacer 通过测量上次 GC 的分配速率和扫描速率,计算出一个合适的触发点(Trigger),让 GC 既不会太频繁(浪费 CPU),也不会太晚(OOM),实现自适应的垃圾回收调度。
3.6 STW 分析
graph TB
%% 定义样式
classDef stw fill:#ffcdd2,stroke:#c62828,stroke-width:2px,color:#b71c1c;
classDef concurrent fill:#e1f5fe,stroke:#0277bd,stroke-width:2px,color:#01579b;
classDef trigger fill:#fff9c4,stroke:#fbc02d,stroke-dasharray: 5 5,color:#f57f17;
%% 节点定义
subgraph Cycle [GC 循环周期]
direction TB
P1(Phase 1: Sweep Termination
清扫终止):::stw
P2(Phase 2: Concurrent Mark
并发标记):::concurrent
P3(Phase 3: Mark Termination
标记终止):::stw
P4(Phase 4: Concurrent Sweep
并发清扫):::concurrent
end
%% 触发条件
Trigger(GC Trigger
堆阈值/定时/手动):::trigger
%% 连线关系
Trigger --> P1
P1 -->|开启写屏障
SetGCPhase: _GCmark| P2
P2 -->|所有对象标记完成
gcMarkDone| P3
P3 -->|关闭写屏障
SetGCPhase: _GCoff| P4
P4 -->|清理结束 & 等待下一轮| Trigger
%% 补充说明
note1[STW: 准备根对象, 清理上一轮残余] -.-> P1
note2[STW: 保证全局标记完成, 必须全局一致] -.-> P3
我们再来看一下这张图,分析一下为什么 ① ③ 阶段需要 STW,而 ② ④ 却不需要呢?
Sweep Termination - STW
1 | 需要做的事: |
必须 STW 的核心原因:
- 写屏障必须同时在所有 P 上生效
- 如果不 STW,某些 P 开启了写屏障,某些还没开
- 会导致指针写入不一致,漏标记对象 ❌
Mark Termination - STW
1 | 需要做的事: |
必须 STW 的核心原因:
- 需要全局一致性视图:确认所有标记工作真的完成了
- 禁用写屏障必须原子:不能有些 P 关了,有些还开着
- 位图状态切换:sweepgen += 2 需要在稳定状态下进行
Mark Phase - 并发
为什么可以并发?
1 | 有写屏障保护: |
关键技术:
- 写屏障:Dijkstra 插入屏障,拦截所有指针写入
- 并发安全:标记位操作是原子的
- 增量处理:每个 worker 独立工作,不需要全局同步
Sweep Phase - 并发
为什么可以并发?
1 | 扫描和分配互不干扰: |
关键技术:
- sweepgen 版本控制:每个 span 有独立状态
- CAS 操作:原子获取扫描所有权
- 按需扫描:分配路径自动扫描,不阻塞其他操作
对比总结
[!IMPORTANT]
Sweep Termination 和 Mark Termination 需要 STW 是因为必须原子地切换写屏障状态和确认全局一致性,而 Mark Phase 和 Sweep Phase 可以并发是因为有写屏障和 sweepgen 机制保护,不需要全局同步。
本质:STW 用于状态切换,并发用于实际工作。🎯
| 阶段 | STW | 原因 | 时长 |
|---|---|---|---|
| Sweep Termination | ✋ 是 | 同步启用写屏障 | ~100μs |
| Mark Phase | ✅ 否 | 写屏障保护 | ~数十 ms |
| Mark Termination | ✋ 是 | 全局一致性确认 | ~100μs |
| Sweep Phase | ✅ 否 | sweepgen + CAS | ~数十 ms |
3.7 核心机制总结
- 三色标记法:白色(未扫描)→ 灰色(已发现)→ 黑色(已扫描)
- 混合写屏障:Dijkstra + Yuasa 保证并发标记的正确性
- 分布式终止检测:Ragged Barrier 确保所有本地缓冲区都被刷新
- Mutator Assist:分配速度过快时,分配者协助标记以保持 GC 进 度
- 代数机制:
sweepgen通过 +2 的方式区分不同 GC 周期的 span 状态
整个 GC 周期是一个精密设计的并发系统,在保证程序正确性的同时,最大化地减少 STW 时间,实现了低延迟的垃圾回收。
4. 工程建议
4.1 参数调优
4.1.1 GOGC 参数
GOGC 控制 GC 的激进程度:
| GOGC 值 | 含义 | 效果 |
|---|---|---|
| GOGC=off | 禁用 GC | 内存会无限增长 |
| GOGC=50 | 堆增长 50% 触发 | 频繁 GC,低内存使用 |
| GOGC=100 | 堆增长 100% 触发(默认) | 平衡 |
| GOGC=200 | 堆增长 200% 触发 | 低频 GC,高内存使用 |
| GOGC=400 | 堆增长 400% 触发 | 极低频 GC,极高内存 |
4.1.2 GOMEMLIMIT
Go1.19 新增的软内存限制,优先级高于 GOGC,GOMEMLIMIT 让
Go 程序知道"不能超过多少内存",接近时自动加大 GC 力度,既防止 OOM
又提高内存利用率,是容器化部署的必备配置。
建议配置为:GOMEMLIMIT = 容器限制 × 0.9。
4.2 性能优化
- 减少分配
1 | // ❌ 避免:频繁小对象分配 |
- 对象池复用
1 | var bufPool = sync.Pool{ |
- 预分配切片
1 | // ❌ 避免:动态扩容 |
- 避免指针密集结构
1 | // ❌ 避免:大量指针 |
- 栈分配优先
1 | // ❌ 逃逸到堆 |
4.3 分析工具
- go tool pprof
- go tool trace
- go build -gcflags -m
- GODEBUG="gctrace=1"
以下面程序为例:
1 | package main |
go tool pprof
启动程序后,访问:http://127.0.0.1:8080/debug/pprof/heap?debug=1

go build -gcflags -m
1
2
3
4
5
6
7
8
9
10
11
12
13➜ go build -gcflags -m main.go
# command-line-arguments
./main.go:15:7: can inline main.func1.1
./main.go:15:4: can inline main.func1.gowrap1
./main.go:20:12: inlining call to sync.(*WaitGroup).Done
./main.go:21:5: inlining call to main.func1.1
./main.go:21:5: inlining call to sync.(*WaitGroup).Done
./main.go:26:25: inlining call to http.ListenAndServe
./main.go:15:12: leaking param: wg
./main.go:12:3: moved to heap: wg
./main.go:15:7: func literal escapes to heap
./main.go:11:5: func literal escapes to heap
./main.go:26:25: &http.Server{...} escapes to heapGODEBUG="gctrace=1"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18➜ GODEBUG="gctrace=1" go run main.go
gc 1 @0.003s 3%: 0.056+0.93+0.074 ms clock, 0.68+0.18/0.53/0+0.89 ms cpu, 3->4->1 MB, 4 MB goal, 0 MB stacks, 0 MB globals, 12 P
gc 2 @0.005s 5%: 0.060+1.2+0.061 ms clock, 0.72+0.30/0.75/0+0.73 ms cpu, 3->4->1 MB, 4 MB goal, 0 MB stacks, 0 MB globals, 12 P
gc 3 @0.007s 6%: 0.037+0.92+0.079 ms clock, 0.45+0.32/0.80/0+0.95 ms cpu, 3->3->1 MB, 4 MB goal, 0 MB stacks, 0 MB globals, 12 P
gc 4 @0.008s 6%: 0.068+1.4+0.058 ms clock, 0.82+0.20/0.78/0+0.69 ms cpu, 3->4->1 MB, 4 MB goal, 0 MB stacks, 0 MB globals, 12 P
gc 5 @0.011s 6%: 0.015+0.44+0.013 ms clock, 0.18+0.020/0.85/1.0+0.15 ms cpu, 3->4->1 MB, 4 MB goal, 0 MB stacks, 0 MB globals, 12 P
gc 6 @0.014s 5%: 0.036+0.42+0.019 ms clock, 0.43+0.051/0.97/1.4+0.22 ms cpu, 3->3->2 MB, 4 MB goal, 0 MB stacks, 0 MB globals, 12 P
gc 7 @0.017s 6%: 0.067+1.0+0.029 ms clock, 0.81+0.23/2.4/4.8+0.35 ms cpu, 4->4->3 MB, 4 MB goal, 0 MB stacks, 0 MB globals, 12 P
gc 8 @0.027s 5%: 0.42+1.0+0.035 ms clock, 5.1+0.11/2.0/1.7+0.42 ms cpu, 5->6->4 MB, 6 MB goal, 0 MB stacks, 0 MB globals, 12 P
gc 9 @0.034s 5%: 0.078+0.83+0.023 ms clock, 0.94+0.28/1.9/1.6+0.28 ms cpu, 7->8->4 MB, 8 MB goal, 0 MB stacks, 0 MB globals, 12 P
gc 10 @0.037s 5%: 0.029+0.66+0.012 ms clock, 0.35+0.069/1.5/2.6+0.15 ms cpu, 8->8->3 MB, 9 MB goal, 0 MB stacks, 0 MB globals, 12 P
gc 11 @0.039s 5%: 0.041+0.58+0.003 ms clock, 0.49+0.059/1.4/2.5+0.045 ms cpu, 6->6->3 MB, 7 MB goal, 0 MB stacks, 0 MB globals, 12 P
gc 12 @0.041s 6%: 0.086+0.94+0.010 ms clock, 1.0+0.83/2.1/0.19+0.12 ms cpu, 6->8->4 MB, 7 MB goal, 0 MB stacks, 0 MB globals, 12 P
gc 13 @0.043s 6%: 0.064+0.73+0.008 ms clock, 0.77+0.30/1.6/1.2+0.096 ms cpu, 8->9->4 MB, 9 MB goal, 0 MB stacks, 0 MB globals, 12 P
gc 14 @0.044s 6%: 0.043+0.73+0.028 ms clock, 0.51+0.12/1.6/1.9+0.34 ms cpu, 7->9->4 MB, 9 MB goal, 0 MB stacks, 0 MB globals, 12 P
gc 15 @0.046s 7%: 0.077+1.0+0.022 ms clock, 0.92+2.5/2.3/0.047+0.27 ms cpu, 7->10->5 MB, 9 MB goal, 0 MB stacks, 0 MB globals, 12 P
gc 16 @0.048s 7%: 0.057+0.59+0.011 ms clock, 0.69+0.83/1.4/0.48+0.13 ms cpu, 8->10->4 MB, 10 MB goal, 0 MB stacks, 0 MB globals, 12 P
gc 17 @0.050s 7%: 0.025+0.52+0.003 ms clock, 0.30+0.098/1.4/2.1+0.039 ms cpu, 8->9->3 MB, 10 MB goal, 0 MB stacks, 0 MB globals, 12 P
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。

 - HedonWang&pics=/banner/go-gc-tri-color-marking.jpg&summary=本文深入剖析 Go 语言中的三色标记法垃圾回收机制,从基本原理、核心算法到运行时实现细节,系统讲解可达性分析、对象标记过程、并发与屏障机制等关键技术,帮助读者全面理解 Go GC 的设计理念与实际应用场景。)


