[!NOTE]
💡 本文基于 Go 1.25.3 源码编写,相比 Go 1.16 版本,增加了 User
Arena、Weak Pointer、Cleanup
机制等重要特性。后续版本可能会有变化。建议结合实际使用的 Go
版本阅读相关源码。
特此声明,本篇是笔者与 Google Gemini 3Pro 共创所作,非常庆幸在当今 AI
时代下获取知识已是如此便利,且也为学习者从第一性原理理解所学知识大大降低了门槛。不过本篇的篇章安排和叙述逻辑,均由笔者把控和审阅,欢迎放心阅读。
结论先行
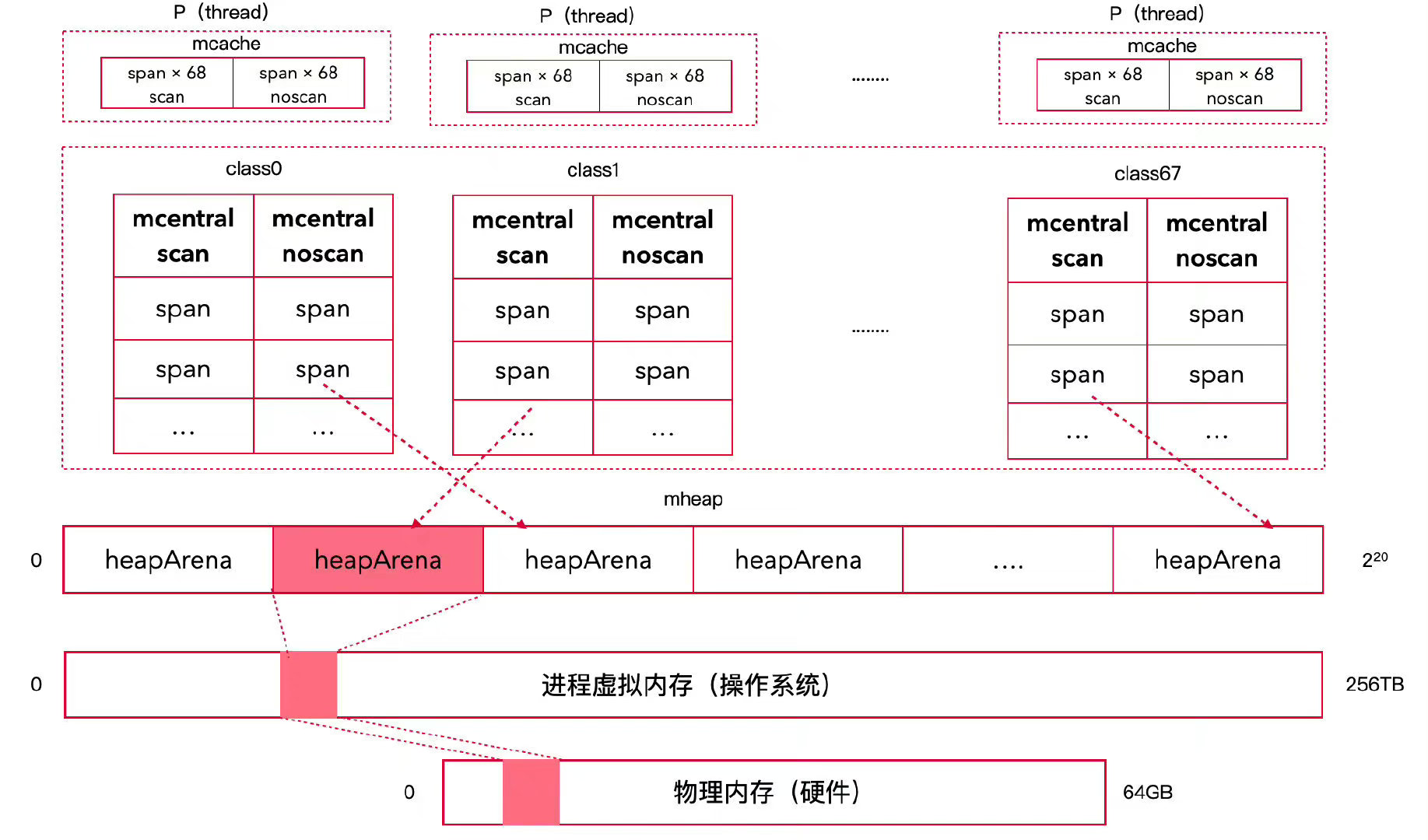 Go内存模型架构
Go内存模型架构
Go 的内存分配器设计源于
TCMalloc,采用了多层级缓存架构来减少锁竞争并提高性能。核心设计如下:
核心架构
- Go 将堆内存抽象为 mheap 结构体;
- Go 进程会从虚拟内存中申请 n 个 heapArena(64
位系统每个 64MB);
- 每个 heapArena 被按需划分成不同 class 的
mspan,共有 68 个 size class;
- 每个 mspan 由 n 个相同大小的 span 组成;
- 为了快速定位合适的 span,为 mheap 建立了 136
个中央索引 mcentral;
- 每个 mcentral 存储对应 class 的 mspan,每种 mspan 又划分为 gc scan
和 no scan 两种,故共有 68 × 2 = 136 个 mcentral;
- 为了解决中央索引的并发锁竞争问题,为每一个 P(线程)建立一个本地缓存
mcache;
- 每个 mcache 存储 136 个 span,分别是每种 class 的
mspan 的一个 scan 和 noscan 的 span。
内存分配策略
- Go 中根据对象大小分为 tiny、small
和 large 三种对象;
- tiny (0~16B 无指针) 对象主要分配到 class 2 的 span 中(通过 tiny
allocator);
- small (16B~32KB) 对象会被分配到 class 2 ~ class 67 的 span 中;
- class 1 (8B) 仅用于 64 位平台上的单指针对象,使用极少;
- large (>32KB) 对象会量身定做分配到 class0 的 span 中,直接从
mheap 上申请;
- 为对象分配内存时,会先从 mcache 上找 span,找不到就去 mcentral
上交换,还找不到就去 mheap 上申请,最后找不到就 OOM。
1. 协程栈
1.1 作用
协程栈是 Go 协程执行的核心数据结构,主要用于:
- 记录执行路径:追踪函数调用链
- 存储局部变量:每个栈帧保存函数的局部变量
- 函数传参:通过栈传递函数参数
- 保存返回值:存储函数的返回值
1.2 位置
- Go 协程栈位于 Go 堆内存上(而非操作系统栈)
- Go 堆内存位于操作系统虚拟内存上
- 这种设计使得 Go 可以灵活管理协程栈的大小
1.3 图解
以下面的代码为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
| package main
func sum(a, b int) int {
sum := 0
sum = a + b
return sum
}
func main() {
a := 3
b := 5
print(sum(a, b))
}
|
栈帧结构如下:
 协程栈结构
协程栈结构
1.4 参数传递
Go 采用值传递
- 传递结构体时:拷贝结构体中的全部内容
- 传递结构体指针时:拷贝结构体指针(8 字节)
1.5 栈大小
Go 1.25.3 中,协程栈的初始大小为
2KB,相比早期版本(如 Go 1.2 的 8KB)更加轻量。
1.6 逃逸分析
不是所有的变量都能放在协程栈上。以下三种情况会导致变量逃逸到堆上:
1. 指针逃逸
函数返回局部变量的指针:
1
2
3
4
| func newInt() *int {
x := 42
return &x
}
|
2. 空接口逃逸
函数参数为 interface{},编译器无法确定具体类型:
1
2
3
| func println(v interface{}) {
}
|
3. 大变量逃逸
变量太大,栈帧放不下。在 64 位机器中,一般超过 64KB
的变量就会逃逸。
1.7 栈扩容
Go 栈的初始空间为 2KB。在函数调用前会执行 morestack
判断栈空间是否足够。
栈扩容策略演进
分段栈(Go 1.3 之前)
- 优点:没有空间浪费
- 缺点:栈帧在不连续的空间之间横跳,性能较差("热分裂"问题)
连续栈(Go 1.3 及之后)
- 优点:空间连续,性能更好
- 缺点:扩容时需要拷贝,开销较大
- 策略:小于 1KB 时翻倍,否则增长 25%
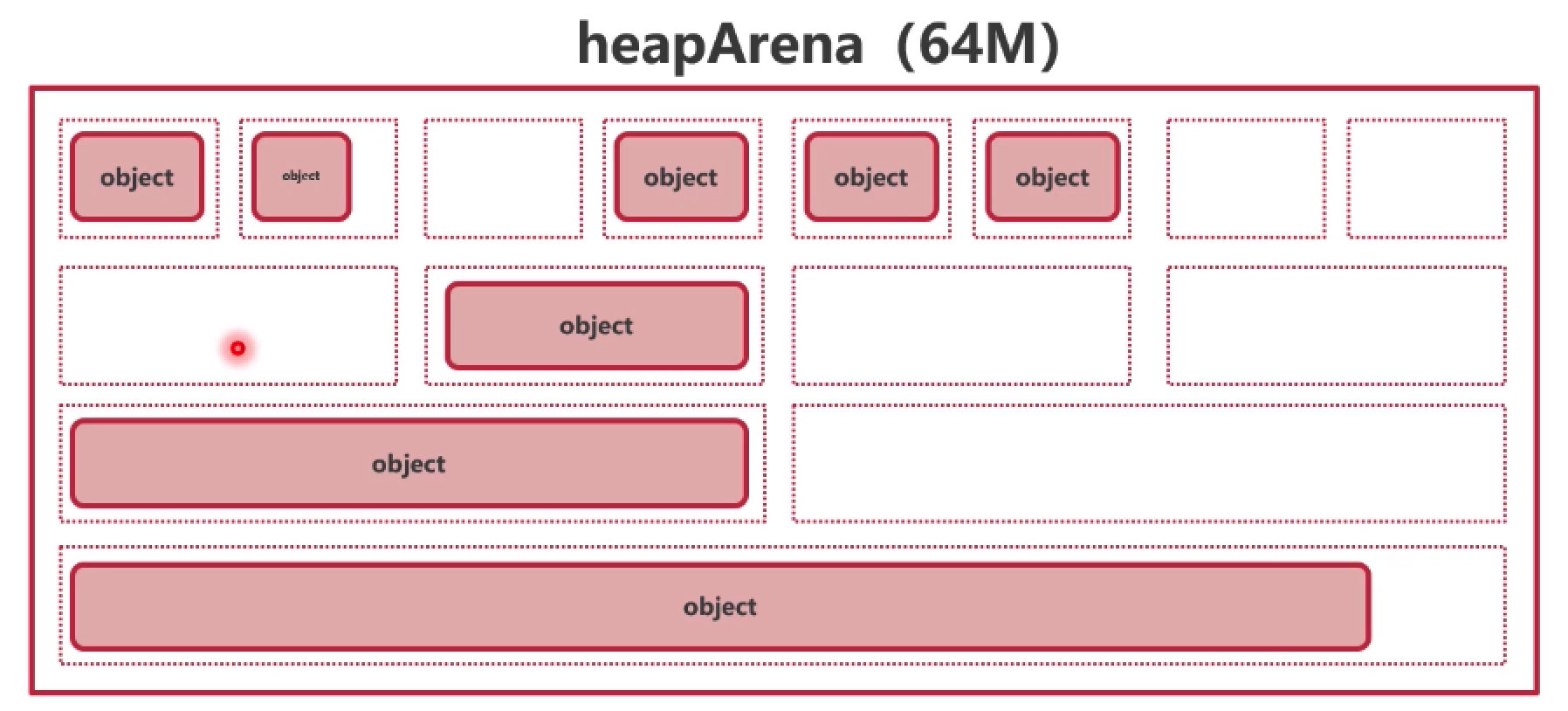
2. 虚拟内存单元 heapArena
2.1 概述
- 在物理内存为 64GB 的机器中,每个 Go 进程最多可被分配到
256TB 的虚拟内存
- Go 的虚拟内存单元为
heapArena,每次申请
64MB(64 位非 Windows 系统)
- 最多可以申请 2²⁰ (约 100 万) 个 heapArena
- 所有的
heapArena 组成了 mheap(Go
堆内存)
 heapArena 结构
heapArena 结构
💡 相关阅读:操作系统
- 虚拟内存
2.2 底层结构
heapArena 定义在 runtime/mheap.go#L266:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| type heapArena struct {
_ sys.NotInHeap
spans [pagesPerArena]*mspan
pageInUse [pagesPerArena / 8]uint8
pageMarks [pagesPerArena / 8]uint8
pageSpecials [pagesPerArena / 8]uint8
pageUseSpanInlineMarkBits [pagesPerArena / 8]uint8
checkmarks *checkmarksMap
zeroedBase uintptr
}
|
2.3 分配策略对比
| 线性分配 |
链表分配 |
分级分配 |
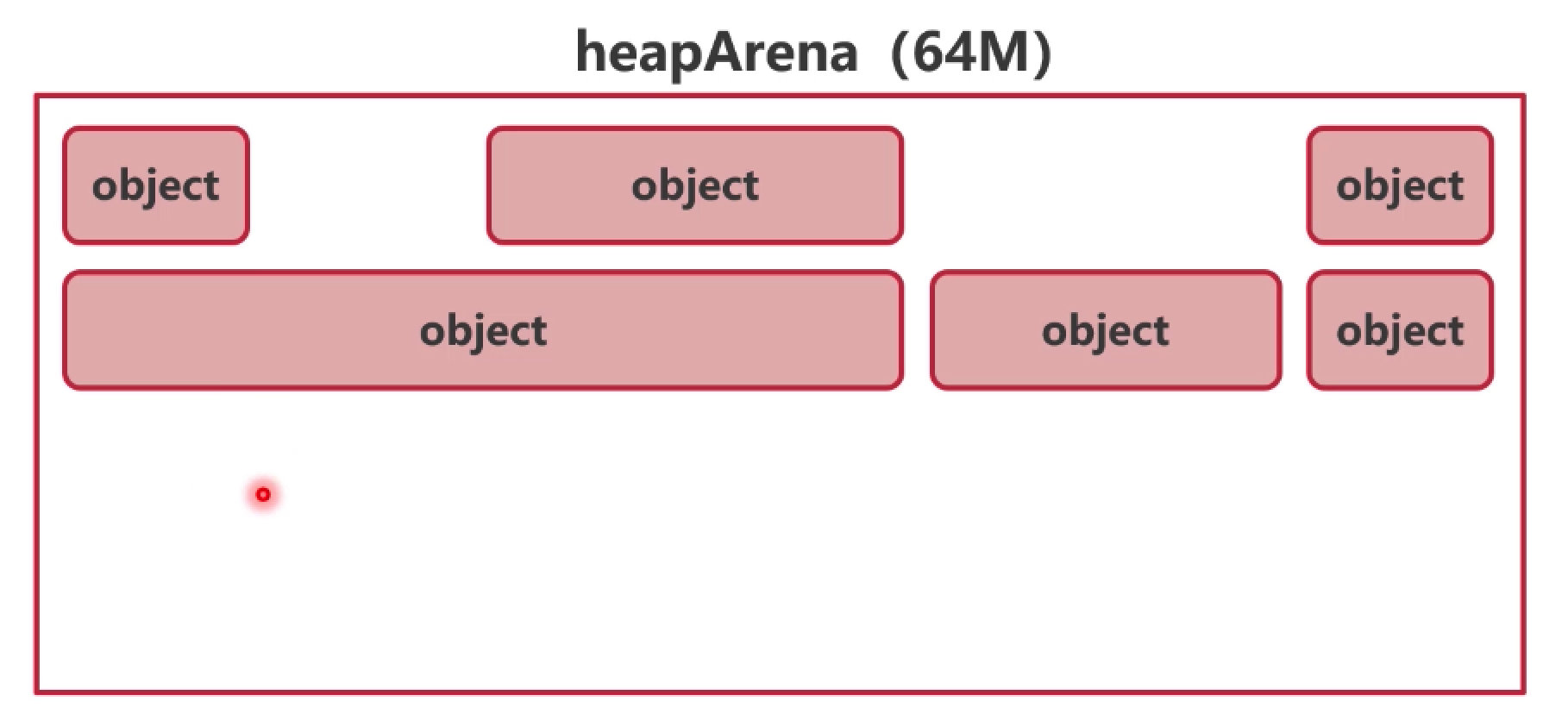 |
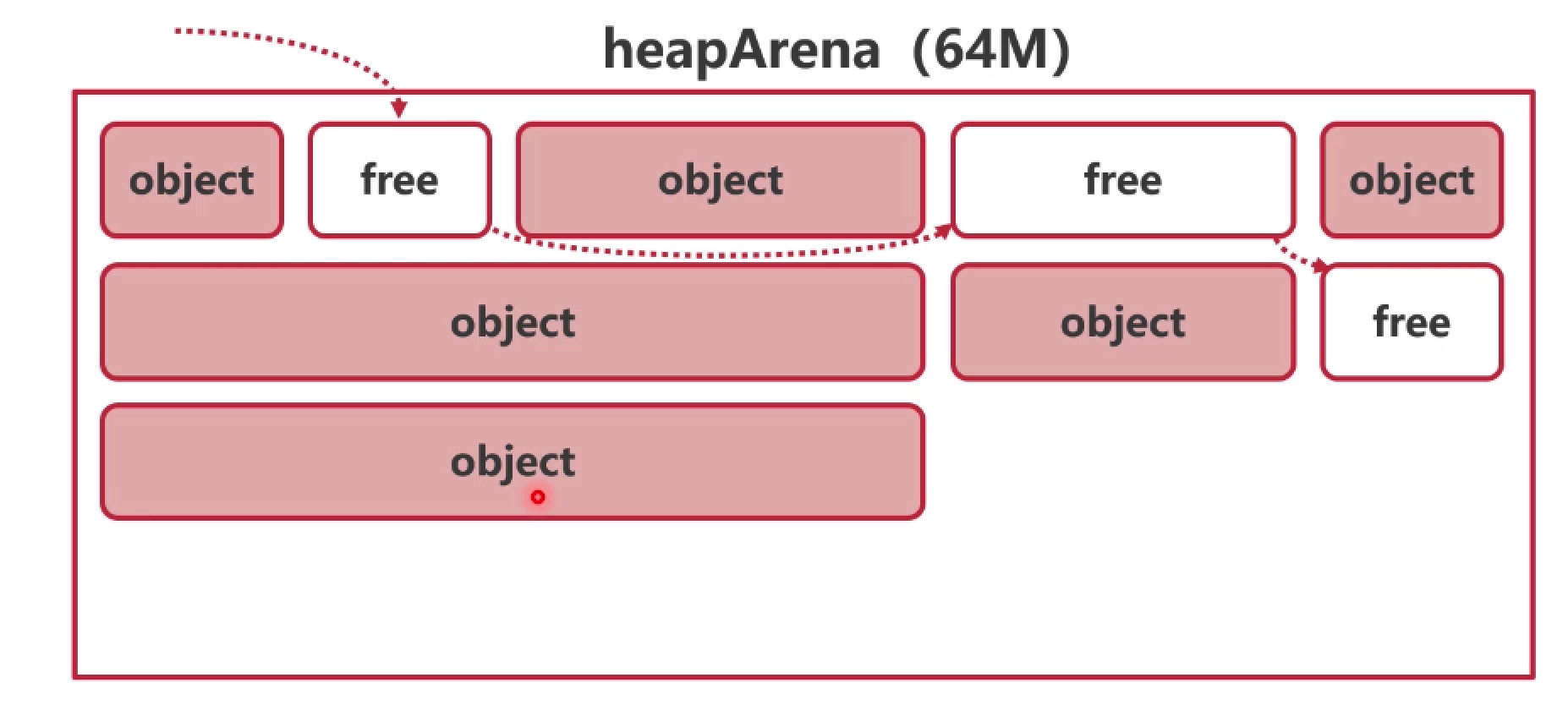 |
 |
| 实现简单,但内存碎片较多 |
将空闲块连接起来,牺牲部分性能来缓解内存碎片 |
将内存按级别分成很多块,根据对象大小存放在能容纳它的最小块中 |
Go 采用分级分配策略,参考了 TCMalloc,将每一个级定义为
mspan。
3. 内存管理单元 mspan
3.1 概述
- Go 使用内存时的基本单位是
mspan
- 每个
mspan 由 N 个相同大小的 span
组成
- Go 1.25.3 中有 68 种 size class(class 0 ~ class
67)
Size Class 表(部分)
 mspan 结构
mspan 结构
3.2 底层结构
mspan 定义在 runtime/mheap.go#L420:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| type mspan struct {
_ sys.NotInHeap
next *mspan
prev *mspan
list *mSpanList
startAddr uintptr
npages uintptr
freeindex uint16
freeIndexForScan uint16
nelems uint16
allocCount uint16
allocBits *gcBits
gcmarkBits *gcBits
pinnerBits *gcBits
spanclass spanClass
elemsize uintptr
state mSpanStateBox
sweepgen uint32
isUserArenaChunk bool
userArenaChunkFree addrRange
scanIdx uint16
largeType *_type
speciallock mutex
specials *special
}
|
3.3 关键字段说明
3.3.1 分配位图(allocBits)
使用位图标记对象是否已分配:
3.3.2 双索引设计(Go 1.19+)
freeindex:分配器使用freeIndexForScan:GC 扫描器使用
这样设计避免了竞争条件,确保 GC 只在对象完全初始化后才能看到它。
3.3.2 状态机
1
2
3
4
5
| const (
mSpanDead mSpanState = iota
mSpanInUse
mSpanManual
)
|
4. 中心索引 mcentral
4.1 概述
heapArena 中的 mspan
不是一开始就全部划分好的,而是按需划分。
由于每个 heapArena 中的 mspan
分布是动态的,为了给要分配空间的对象快速定位到合适的 mspan,Go
定义了中心索引 mcentral。
- 总共有 136 个
mcentral 结构体
- 其中 68 个用于需要 GC 扫描的对象(scan)
- 另外 68 个用于无需 GC 扫描的对象(noscan)
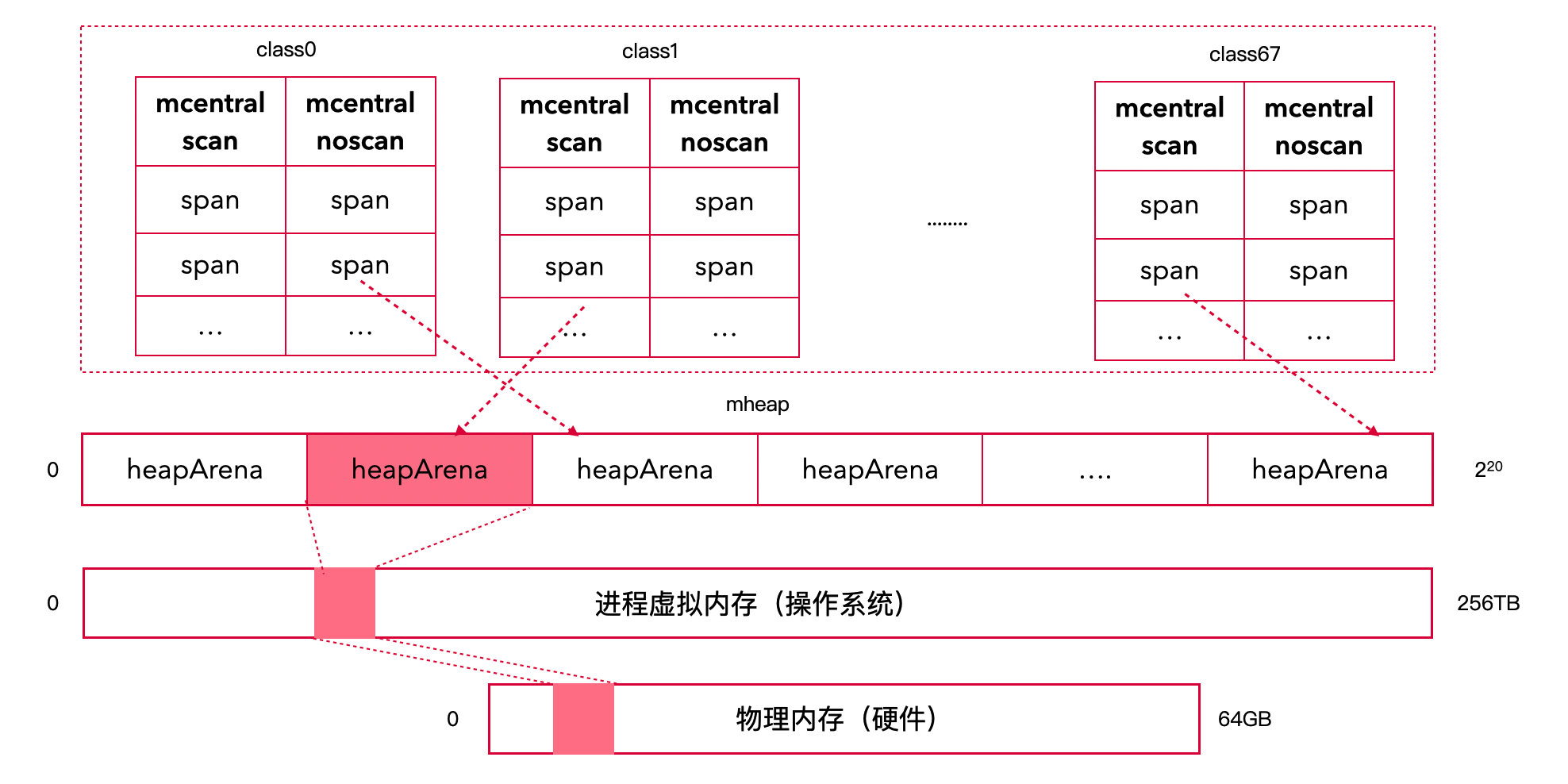 mcentral 结构
mcentral 结构
4.2 底层结构
mcentral 定义在 runtime/mcentral.go#L22:
1
2
3
4
5
6
7
8
9
| type mcentral struct {
_ sys.NotInHeap
spanclass spanClass
partial [2]spanSet
full [2]spanSet
}
|
4.3 双缓冲机制
mcentral 使用双缓冲配合 GC 的清扫机制:
sweepgen 每次 GC 增加 2partial[sweepgen/2%2] 是已清扫的 spanpartial[1-sweepgen/2%2] 是未清扫的 span
这种设计使得 GC 和分配可以并发进行,无需等待所有 span
都清扫完毕。
5. 线程缓存 mcache
5.1 概述
mcentral
是一个中心索引,修改它需要使用互斥锁进行保护,锁竞争会造成性能问题。
Go 参考 GMP 模型,为每个
P(逻辑处理器)建立了线程本地缓存
mcache,极大缓解了并发锁争夺的性能消耗。
设计要点:
- 每个 P 有一个
mcache
- 对于每一种 size class,取一个 scan 和一个 noscan span
- 一个
mcache 拥有 136 个
mspan(68 个 scan + 68 个 noscan)
- 当本地缓存用完后,才需要上锁去 mcentral 交换
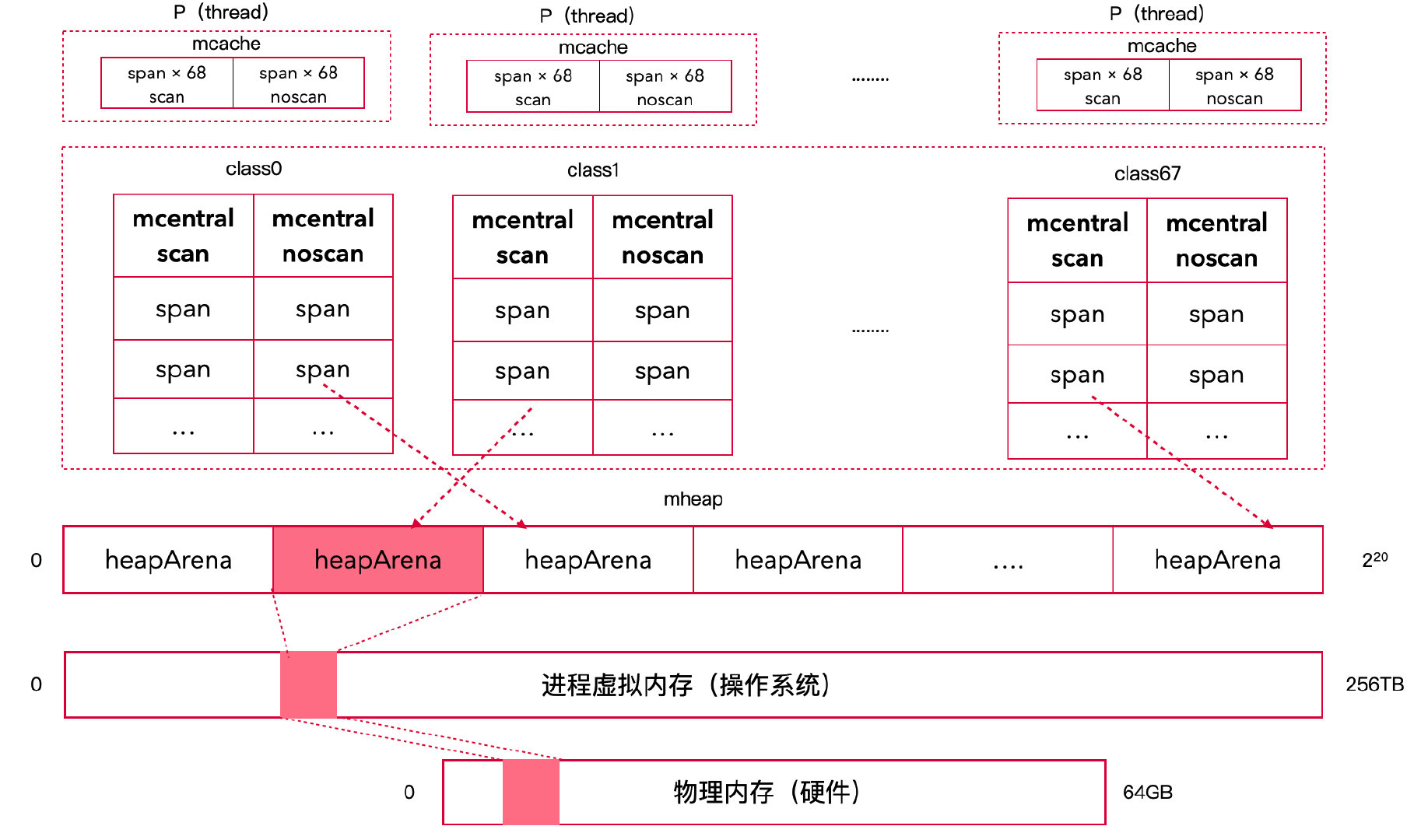 mcache 结构
mcache 结构
5.2 底层结构
mcache 定义在 runtime/mcache.go#L20:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| type mcache struct {
_ sys.NotInHeap
nextSample int64
memProfRate int
scanAlloc uintptr
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
alloc [numSpanClasses]*mspan
stackcache [_NumStackOrders]stackfreelist
flushGen atomic.Uint32
}
|
5.3 与 P 的关系
1
2
3
4
5
| type p struct {
mcache *mcache
}
|
每个 P 持有一个 mcache 指针,实现无锁快速路径。
6. 堆 mheap
mheap 是 Go 堆内存的全局管理者,统筹所有内存分配。
6.1 底层结构
mheap 定义在 runtime/mheap.go#L64:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| type mheap struct {
_ sys.NotInHeap
lock mutex
pages pageAlloc
sweepgen uint32
pagesInUse atomic.Uintptr
pagesSwept atomic.Uint64
sweepPagesPerByte float64
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
heapArenas []arenaIdx
curArena struct {
base, end uintptr
}
central [numSpanClasses]struct {
mcentral mcentral
pad [cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte
}
allspans []*mspan
spanalloc fixalloc
cachealloc fixalloc
specialfinalizeralloc fixalloc
specialWeakHandleAlloc fixalloc
specialCleanupAlloc fixalloc
specialPinCounterAlloc fixalloc
speciallock mutex
arenaHintAlloc fixalloc
userArena struct {
arenaHints *arenaHint
quarantineList mSpanList
readyList mSpanList
}
userArenaArenas []arenaIdx
cleanupID uint64
immortalWeakHandles immortalWeakHandleMap
}
|
6.2 关键设计
1. 二级映射(arenas)
为了支持稀疏的虚拟地址空间,使用二级数组:
- L1 map:索引 arena 组
- L2 map:索引具体的 heapArena
在大多数 64
位平台上,arenaL1Bits = 0,退化为单级映射。
2. Cache Line 对齐
1
| pad [(cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize) % cpu.CacheLinePadSize]byte
|
填充字节避免伪共享(false sharing),提升多核性能。
3. 页回收器
1
2
| reclaimIndex atomic.Uint64
reclaimCredit atomic.Uintptr
|
后台异步回收未使用的页,减少内存占用。
7. 内存分配
7.1 对象分级
Go 根据对象大小将分配分为三类:
| 类型 |
大小范围 |
分配方式 |
Size Class |
| Tiny |
0 ~ 16B(无指针) |
多个对象合并到 16B |
class 2 |
| Tiny |
8B(单指针) |
64 位上使用 class 1 |
class1 |
| Small |
16B ~ 32KB |
从 mcache 分配 |
class 2 ~ 67 |
| Large |
> 32KB |
直接从 mheap 分配 |
class 0 |
注意:Class 1 (8B) 在实践中使用极少,仅在 64
位平台上分配恰好 8 字节且包含指针的对象时使用。绝大多数 8
字节对象要么无指针(走 tiny allocator),要么是结构体的一部分。
7.1.1 Tiny 对象分配
对于 < 16B 且无指针的对象,Go
使用特殊的 tiny allocator:
1
2
3
4
|
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
|
- 尝试在当前 tiny block 中分配(根据对齐要求)
- 如果空间不足,从 class 2 (16B) 的 span 中获取新的 tiny block
- 多个 tiny 对象共享同一个 16B 块,减少内存浪费
 Tiny 对象分配
Tiny 对象分配
Class 1 的特殊性:Class 1 (8B)
在实践中使用极少,仅在 64 位平台上分配恰好 8
字节且包含指针的对象时使用。典型例子如单个逃逸的指针变量。由于这种场景非常罕见,class
1 基本处于"保留但不常用"的状态。大多数 8 字节对象要么:
- 无指针 → 走 tiny allocator(class 2)
- 是结构体字段的一部分 → 随结构体一起分配
- 是栈上变量 → 不进行堆分配
7.1.2 Small 对象分配
对于 16B ~ 32KB 的对象:
- 根据对象大小查表确定 size class
- 在 mcache 中寻找对应 class 的 span
- 从 span 的 allocBits 中找到空闲 slot
- 如果 mcache 中 span 已满,去 mcentral 交换
- 如果 mcentral 也没有,去 mheap 申请
7.1.3 Large 对象分配
对于 > 32KB 的大对象:量身定做 class0,直接从
mheap 上申请内存。
7.2 mcache 替换
在 mcache 中,每个 class 的 mspan 只有一个,当 mspan 满了之后,会从
mcentral 中兑换一个新的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| func (c *mcache) refill(spc spanClass) {
s := c.alloc[spc]
if s != &emptymspan {
if s.sweepgen != mheap_.sweepgen+3 {
throw("bad sweepgen in refill")
}
mheap_.central[spc].mcentral.uncacheSpan(s)
}
s = mheap_.central[spc].mcentral.cacheSpan()
if s == nil {
throw("out of memory")
}
c.alloc[spc] = s
}
|
7.3 mcentral 扩容
mcentral 中,只有有限数量的 mspan,当 mspan 缺少时,会像 mheap
中开辟新的 heapArena,并申请对应 class 的 span。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| func (c *mcentral) grow() *mspan {
npages := uintptr(class_to_allocnpages[c.spanclass.sizeclass()])
size := uintptr(class_to_size[c.spanclass.sizeclass()])
s := mheap_.alloc(npages, c.spanclass)
if s == nil {
return nil
}
n := (npages << pageShift) / size
s.limit = s.base() + size*n
return s
}
|
7.4 mallocgc 源码分析
mallocgc
是 Go 内存分配的核心函数,核心结构如下:
1
2
3
4
5
6
| mallocgc
├── mallocgcTiny // Tiny 对象 (0~16B, 无指针)
├── mallocgcSmallNoscan // Small 对象 (16B~32KB, 无指针)
├── mallocgcSmallScanNoHeader // Small 对象 (带指针, 无 header)
├── mallocgcSmallScanHeader // Small 对象 (带指针, 有 header)
└── mallocgcLarge // Large 对象 (>32KB)
|
源码注释如下(省略了与内存分配无关的次要代码):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
if size == 0 {
return unsafe.Pointer(&zerobase)
}
var x unsafe.Pointer
var elemsize uintptr
if size <= maxSmallSize-gc.MallocHeaderSize {
if typ == nil || !typ.Pointers() {
if size < maxTinySize {
x, elemsize = mallocgcTiny(size, typ)
} else {
x, elemsize = mallocgcSmallNoscan(size, typ, needzero)
}
} else {
if !needzero {
throw("objects with pointers must be zeroed")
}
if heapBitsInSpan(size) {
x, elemsize = mallocgcSmallScanNoHeader(size, typ)
} else {
x, elemsize = mallocgcSmallScanHeader(size, typ)
}
}
} else {
x, elemsize = mallocgcLarge(size, typ, needzero)
}
return x
}
|
7.4.1 Tiny
对象分配:mallocgcTiny
用于 < 16B 且无指针的对象,多个对象合并到 16B
块中。mallocgcTiny 进行了以下优化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| func mallocgcTiny(size uintptr, typ *_type) (unsafe.Pointer, uintptr) {
mp := acquirem()
mp.mallocing = 1
c := getMCache(mp)
off := c.tinyoffset
if size&7 == 0 {
off = alignUp(off, 8)
} else if goarch.PtrSize == 4 && size == 12 {
off = alignUp(off, 8)
} else if size&3 == 0 {
off = alignUp(off, 4)
} else if size&1 == 0 {
off = alignUp(off, 2)
}
if off+size <= maxTinySize && c.tiny != 0 {
x := unsafe.Pointer(c.tiny + off)
c.tinyoffset = off + size
c.tinyAllocs++
mp.mallocing = 0
releasem(mp)
return x, maxTinySize
}
span := c.alloc[tinySpanClass]
v := nextFreeFast(span)
if v == 0 {
v, span, _ = c.nextFree(tinySpanClass)
}
x := unsafe.Pointer(v)
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
if !raceenabled && (size < c.tinyoffset || c.tiny == 0) {
c.tiny = uintptr(x)
c.tinyoffset = size
}
size = maxTinySize
publicationBarrier()
return x, size
}
|
7.4.2
小对象无扫描分配:mallocgcSmallNoscan
用于 16B~32KB 且无指针的对象。
关键点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| func mallocgcSmallNoscan(size uintptr, typ *_type, needzero bool) (unsafe.Pointer, uintptr) {
mp := acquirem()
mp.mallocing = 1
c := getMCache(mp)
var sizeclass uint8
if size <= gc.SmallSizeMax-8 {
sizeclass = gc.SizeToSizeClass8[divRoundUp(size, gc.SmallSizeDiv)]
} else {
sizeclass = gc.SizeToSizeClass128[divRoundUp(size-gc.SmallSizeMax, gc.LargeSizeDiv)]
}
size = uintptr(gc.SizeClassToSize[sizeclass])
spc := makeSpanClass(sizeclass, true)
span := c.alloc[spc]
v := nextFreeFast(span)
if v == 0 {
v, span, checkGCTrigger = c.nextFree(spc)
}
x := unsafe.Pointer(v)
if needzero && span.needzero != 0 {
memclrNoHeapPointers(x, size)
}
publicationBarrier()
if writeBarrier.enabled {
gcmarknewobject(span, uintptr(x))
} else {
span.freeIndexForScan = span.freeindex
}
return x, size
}
|
用于带指针的小对象,且堆位图在 span 中。
关键点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| func mallocgcSmallScanNoHeader(size uintptr, typ *_type) (unsafe.Pointer, uintptr) {
mp := acquirem()
mp.mallocing = 1
c := getMCache(mp)
sizeclass := gc.SizeToSizeClass8[divRoundUp(size, gc.SmallSizeDiv)]
spc := makeSpanClass(sizeclass, false)
span := c.alloc[spc]
v := nextFreeFast(span)
if v == 0 {
v, span, checkGCTrigger = c.nextFree(spc)
}
x := unsafe.Pointer(v)
if span.needzero != 0 {
memclrNoHeapPointers(x, size)
}
if goarch.PtrSize == 8 && sizeclass == 1 {
c.scanAlloc += 8
} else {
c.scanAlloc += heapSetTypeNoHeader(uintptr(x), size, typ, span)
}
size = uintptr(gc.SizeClassToSize[sizeclass])
publicationBarrier()
if writeBarrier.enabled {
gcmarknewobject(span, uintptr(x))
} else {
span.freeIndexForScan = span.freeindex
}
return x, size
}
|
用于带指针的小对象,需要 malloc header 存储类型信息。
Malloc Header 设计:
1
2
3
4
5
| +------------------+
| *_type (header) 丨 <- 指向类型元数据的指针
+------------------+
| 实际对象数据 | <- x 指向这里
+------------------+
|
为什么需要 Header:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| func mallocgcSmallScanHeader(size uintptr, typ *_type) (unsafe.Pointer, uintptr) {
mp := acquirem()
mp.mallocing = 1
c := getMCache(mp)
size += gc.MallocHeaderSize
var sizeclass uint8
if size <= gc.SmallSizeMax-8 {
sizeclass = gc.SizeToSizeClass8[divRoundUp(size, gc.SmallSizeDiv)]
} else {
sizeclass = gc.SizeToSizeClass128[divRoundUp(size-gc.SmallSizeMax, gc.LargeSizeDiv)]
}
size = uintptr(gc.SizeClassToSize[sizeclass])
spc := makeSpanClass(sizeclass, false)
span := c.alloc[spc]
v := nextFreeFast(span)
if v == 0 {
v, span, checkGCTrigger = c.nextFree(spc)
}
x := unsafe.Pointer(v)
if span.needzero != 0 {
memclrNoHeapPointers(x, size)
}
header := (**_type)(x)
x = add(x, gc.MallocHeaderSize)
c.scanAlloc += heapSetTypeSmallHeader(uintptr(x), size-gc.MallocHeaderSize, typ, header, span)
publicationBarrier()
if writeBarrier.enabled {
gcmarknewobject(span, uintptr(x)-gc.MallocHeaderSize)
} else {
span.freeIndexForScan = span.freeindex
}
return x, size
}
|
7.4.5 大对象分配:mallocgcLarge
用于 > 32KB 的对象。
大对象优化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| func mallocgcLarge(size uintptr, typ *_type, needzero bool) (unsafe.Pointer, uintptr) {
mp := acquirem()
mp.mallocing = 1
c := getMCache(mp)
span := c.allocLarge(size, typ == nil || !typ.Pointers())
span.freeindex = 1
span.allocCount = 1
span.largeType = nil
size = span.elemsize
x := unsafe.Pointer(span.base())
publicationBarrier()
if writeBarrier.enabled {
gcmarknewobject(span, uintptr(x))
} else {
span.freeIndexForScan = span.freeindex
}
if typ != nil && typ.Pointers() {
if !heapBitsInSpan(span.elemsize) {
span.largeType = typ
publicationBarrier()
} else {
c.scanAlloc += heapSetTypeLarge(uintptr(x), span.elemsize, typ, span)
}
}
if needzero && span.needzero != 0 {
if goexperiment.AllocHeaders {
memclrNoHeapPointersChunked(size, x)
} else {
memclrNoHeapPointers(x, size)
}
}
return x, size
}
|
8. Go 1.20+ 新增特性
Go 在 1.16 之后的版本中引入了多项重要的内存管理特性,极大地增强了 Go
的能力和灵活性。
8.1 User Arena(Go 1.20+)
概述
User Arena
允许应用程序手动管理一组对象的生命周期,所有对象在同一个
arena 中分配,可以一次性释放整个 arena。
使用场景
- 临时数据处理:请求处理完后批量释放
- 请求级别内存池:每个请求一个 arena
- 减少 GC 压力:大量临时对象不进入 GC 扫描
数据结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| type mheap struct {
userArena struct {
arenaHints *arenaHint
quarantineList mSpanList
readyList mSpanList
}
}
type mspan struct {
isUserArenaChunk bool
userArenaChunkFree addrRange
}
|
使用示例
1
2
3
4
5
6
7
8
9
10
11
12
| import "arena"
func processRequest(data []byte) {
a := arena.NewArena()
defer a.Free()
obj := arena.New[MyStruct](a)
}
|
8.2 Weak Pointer(Go 1.23+)
概述
弱引用机制允许持有对象的引用,但不阻止 GC
回收该对象。
使用场景
- 缓存:缓存条目可以被 GC 回收
- Observer 模式:观察者不阻止被观察对象回收
- 循环引用打破:避免内存泄漏
数据结构
1
2
3
4
5
6
7
8
|
immortalWeakHandles immortalWeakHandleMap
specialWeakHandle struct {
special special
handle *atomic.Uintptr
}
|
使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import "weak"
type Cache struct {
items map[string]weak.Pointer[*Item]
}
func (c *Cache) Get(key string) *Item {
wp := c.items[key]
return wp.Value()
}
func (c *Cache) Set(key string, item *Item) {
c.items[key] = weak.Make(item)
}
|
实现细节
- 弱指针本身不占用 GC 扫描时间
- 对象被回收后,弱指针自动变为 nil
- 弱指针转强指针需要确保 span 已清扫
8.3 Cleanup 机制(Go 1.24+)
概述
类似 finalizer
但更安全的资源清理机制,不会使对象复活。
Cleanup vs Finalizer
| 特性 |
Finalizer |
Cleanup |
| 对象复活 |
会 |
不会 |
| 执行时机 |
第一次变成不可达 |
对象真正释放前 |
| 多个回调 |
不支持 |
支持 |
| GC 延迟 |
较大 |
较小 |
数据结构
1
2
3
4
5
6
7
8
9
|
cleanupID uint64
specialCleanup struct {
special special
fn *funcval
id uint64
}
|
使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import "runtime"
type Resource struct {
handle uintptr
}
func NewResource() *Resource {
r := &Resource{handle: openResource()}
runtime.AddCleanup(r, func() {
closeResource(r.handle)
})
return r
}
|
8.4 Pinner 机制(Go 1.21+)
概述
固定对象在内存中的位置,防止 GC 移动(为未来的移动式 GC
做准备)。
使用场景
- CGO 交互:C 代码持有 Go 对象指针
- DMA 操作:硬件直接访问内存
- 性能优化:避免某些热点对象移动
数据结构
1
2
3
4
5
6
7
8
|
pinnerBits *gcBits
specialPinCounter struct {
special special
counter uintptr
}
|
使用示例
1
2
3
4
5
6
7
8
9
10
11
| import "runtime"
func passToC(data []byte) {
var pinner runtime.Pinner
pinner.Pin(&data[0])
C.processData(unsafe.Pointer(&data[0]), C.int(len(data)))
pinner.Unpin()
}
|
8.5 GreenTeaGC(实验性,Go 1.24+)
概述
实验性的新 GC 算法,旨在进一步降低延迟。
关键改进
- Span Inline Mark Bits:将 mark bits 内联到 span
中
- 增量标记:更细粒度的标记控制
- 减少停顿:优化 STW 阶段
数据结构
1
2
3
4
5
|
scanIdx uint16
pageUseSpanInlineMarkBits [pagesPerArena / 8]uint8
|
启用方式
1
| GOEXPERIMENT=greentea go build myapp.go
|
9. 性能优化技巧
9.1 减少内存分配
1. 复用对象(sync.Pool)
1
2
3
4
5
6
7
8
9
10
11
12
13
| var bufferPool = sync.Pool{
New: func() interface{} {
return new(bytes.Buffer)
},
}
func process() {
buf := bufferPool.Get().(*bytes.Buffer)
defer bufferPool.Put(buf)
buf.Reset()
}
|
2. 预分配切片
1
2
3
4
5
6
7
8
9
10
11
|
var items []Item
for i := 0; i < 1000; i++ {
items = append(items, Item{})
}
items := make([]Item, 0, 1000)
for i := 0; i < 1000; i++ {
items = append(items, Item{})
}
|
3. 字符串拼接优化
1
2
3
4
5
6
7
8
9
10
11
12
13
|
s := ""
for i := 0; i < 100; i++ {
s += "a"
}
var b strings.Builder
b.Grow(100)
for i := 0; i < 100; i++ {
b.WriteString("a")
}
s := b.String()
|
9.2 避免逃逸
1. 返回值而非指针
1
2
3
4
5
6
7
8
9
10
|
func newPoint() *Point {
p := Point{x: 1, y: 2}
return &p
}
func newPoint() Point {
return Point{x: 1, y: 2}
}
|
2. 使用确定大小的数组
1
2
3
4
5
6
7
8
9
|
func process() {
data := make([]byte, n)
}
func process() {
var data [1024]byte
}
|
9.3 检测工具
逃逸分析
1
| go build -gcflags="-m" main.go
|
内存分析
1
2
3
4
5
6
7
8
9
| import _ "net/http/pprof"
func main() {
go func() {
http.ListenAndServe("localhost:6060", nil)
}()
}
|
Trace 分析
1
2
| go test -trace=trace.out
go tool trace trace.out
|
10. 总结
10.1 内存模型演进
从 Go 1.16 到 Go 1.25.3,内存模型的主要演进方向:
更灵活的内存管理
- User Arena:用户可控的批量分配/释放
- 适应更多场景需求
更丰富的引用语义
- Weak Pointer:支持弱引用
- 打破循环引用,优化缓存
更安全的资源管理
- Cleanup 机制:不会使对象复活
- 减少 finalizer 带来的问题
更好的 CGO 支持
- Pinner 机制:固定对象位置
- 安全地与 C 代码交互
持续的 GC 优化
- GreenTeaGC:实验性的低延迟 GC
- Inline mark bits:减少内存开销
10.2 核心设计原则
Go 内存分配器的核心设计原则始终如一:
- 多层级缓存:
- 本地缓存:mcache(Per-P,无锁)
- 中央索引:mcentral(按 size class,需要锁)
- 全局堆:mheap(全局,需要全局锁)
- 虚拟内存:heapArena(64MB 单元)
- 减少锁竞争:Per-P 缓存 + 细粒度锁
- 分级管理:68 个 size class 减少碎片
- 延迟归零:按需清零提高性能
- 与 GC 协作:双缓冲、sweepgen 等机制
10.3 最佳实践
- 理解内存分配路径:优先使用 mcache
的无锁快速路径
- 减少逃逸:让对象尽量在栈上分配
- 复用对象:使用 sync.Pool 减少分配
- 预分配容量:避免 slice/map 反复扩容
- 选择合适的特性:根据场景使用 User Arena、Weak
Pointer 等
10.4 参考资料
附录:常用命令
内存相关环境变量
1
2
3
| GOGC=100
GOMEMLIMIT=4GiB
GODEBUG=gctrace=1
|
性能分析
1
2
3
4
5
6
7
8
9
10
11
|
go test -cpuprofile=cpu.prof
go tool pprof cpu.prof
go test -memprofile=mem.prof
go tool pprof mem.prof
go test -trace=trace.out
go tool trace trace.out
|
逃逸分析
1
2
3
4
5
|
go build -gcflags="-m -m" main.go
go tool compile -S main.go
|