1. gRPC
要彻底掌握 gRPC,我们不能仅停留在会写 .proto
文件和生成代码的层面。我们需要从 第一性原理
出发,理解它到底解决了什么问题,它是如何构建在网络协议之上的,以及在生产环境中会遇到哪些真实挑战。
特此声明,本篇是笔者与 Google Gemini 3Pro 共创所作,非常庆幸在当今 AI 时代下获取知识已是如此便利,且也为学习者从第一性原理理解所学知识大大降低了门槛。不过本篇的篇章安排和叙述逻辑,均由笔者把控和审阅,欢迎放心阅读。
1.1 为什么需要 gRPC
在深入技术细节前,必须理解 gRPC 诞生的背景。它本质上是 RPC (Remote Procedure Call) 技术的一种现代演进
RPC 的核心愿景是:让调用远程服务就像调用本地函数一样简单。
- 本地函数:
result = calculator.add(a, b),在内存中跳转,极快。 - 远程调用:
result = request("http://api/add", {a, b}),需要跨越网络,面临延迟、丢包、序列化开销。
要掌握 gRPC,首先要明白它为什么要革 REST 的命:
| 特性 | REST (JSON + HTTP/1.1) | gRPC (Protobuf + HTTP/2) | 原理差异 |
|---|---|---|---|
| 协议 | 文本协议 (Text) | 二进制协议 (Binary) | 计算机处理二进制比处理文本快得多(无需频繁的字符串解析)。 |
| 传输 | 请求/响应模型,连接复用差 | 多路复用 (Multiplexing) | HTTP/2 允许在一个 TCP 连接上并行处理多个请求,解决了队头阻塞 (Head-of-Line Blocking)。 |
| 约束 | 弱类型,依赖文档 (OpenAPI) | 强类型,依赖 IDL (.proto) | IDL (Interface Definition Language) 是 gRPC 的核心,它是强契约,保证了客户端和服务端的数据结构绝对一致。 |
| 方向 | 主要是单向 (Request-Response) | 双向流 (Bi-directional Streaming) | HTTP/2 的流特性允许服务端主动推送数据。 |
gRPC 的高性能并非魔法,而是通过 空间效率(Protobuf 压缩率高)和 时间效率(HTTP/2 并发高、序列化快)的物理层优化换来的。
1.2 两大基石
1.2.1 Protocol Buffers (Protobuf)
不要只把它当作 XML/JSON 的替代品,要理解其 编码原理。
- TLV 格式: Protobuf 采用
Tag - Length - Value的紧凑存储方式,没有字段名(字段名在编译后的代码中),只有字段编号 (Field ID)。 - Varint 编码: 对于整数,使用变长编码(Base 128
Varints)。例如数字
1只需要 1 个字节存储,而不是标准的 4 个字节 (int32)。 - 向后兼容性: 掌握如何安全地增加、删除字段而不破坏现有的客户端(永远不要修改已存在的 Field ID)。
1 | // The greeter service definition. |
1.2.2 HTTP/2 传输机制
gRPC 强依赖 HTTP/2。你需要理解以下概念在 gRPC 中如何映射:
- Frame (帧): HTTP/2 通信的最小单位。gRPC 的数据被封装在 DATA 帧中。
- Stream (流): 一个 RPC 调用对应一个 Stream。
- HPACK: HTTP 头压缩。RPC 调用往往 Header 重复度高,HPACK 能极大减少带宽消耗。
1.3 四种模式与工程化
1.3.1 四种通信模式
- Unary RPC: 一问一答。适用于常规 API。
- Server Streaming: 客户端发一个,服务端回一堆。适用于:大列表数据、实时行情推送。
- Client Streaming: 客户端发一堆,服务端回一个。适用于:物联网传感器上报、大文件上传。
- Bidirectional Streaming: 双向实时对话。适用于:聊天室、实时游戏同步。
1.3.2 Interceptor (拦截器)
这是 gRPC 的中间件机制。彻底掌握它是做架构设计的关键。
- 用途: 鉴权 (Auth)、日志 (Logging)、监控 (Metrics)、分布式追踪 (Tracing)。
- 实践: 学会编写一个
UnaryServerInterceptor,在其中计算每个请求的耗时并打印日志。
笔者的开源项目 goapm 中提供了 gRPC Server 和 Client 的链路追踪封装,有需要的读者可参考。
1.3.3 Error Handling (错误处理)
gRPC 的错误不是 HTTP Status Code(虽然底层映射了)。
- gRPC Status Code: 掌握标准码的含义,如
OK(0),CANCELLED(1),DEADLINE_EXCEEDED(4),UNAVAILABLE(14)。 - Rich Error Model: 学会使用
google.rpc.Status传递更详细的错误信息(如具体的字段校验错误),而不仅是一个简单的错误码。
1.4 注意事项
1.4.1 负载均衡的陷阱
- 问题: gRPC 基于 HTTP/2,连接是 长连接 (Persistent Connection)。一旦连接建立,后续请求都在同一个 TCP 连接中复用。
- 后果: 传统的 L4 负载均衡器(如 AWS NLB、LVS)只在连接建立时起作用。结果就是:一个后端实例累死,其他实例闲死。
- 解决方案:
- 客户端负载均衡 (Client-side LB): 客户端感知所有后端 IP(需配合 Service Discovery,如 Consul/Etcd),自己做轮询。
- 代理负载均衡 (Proxy LB / L7 LB): 使用支持 HTTP/2 的网关(如 Envoy, Nginx)来拆解请求并分发。
14.2 Deadlines (超时控制)
- 原则: 永远不要发起没有 Deadline 的 RPC 调用。
- 级联故障: 如果服务 A 调 B,B 调 C,A 必须设置超时,且该超时上下文 (Context) 应该传递给 B 和 C。如果 A 超时了,C 的运算也应该立即取消 (Context Cancel),避免浪费资源。
2. 数据编码
为了更深入理解 gRPC 的高性能,从根本上掌握为什么 gRPC 要使用 Protobuf 编码格式。本篇将参考 Designing Data-Intensive Applications(DDIA) 一书,对业内常用的数据编码格式进行统一梳理。
| 协议 | 类型 | Schema 依赖 | 核心设计哲学 | 典型场景 |
|---|---|---|---|---|
| JSON | 文本 | 无 (Self-describing) | 可读性至上。万物皆文本,浏览器原生支持。 | 前后端交互、配置文件、调试接口。 |
| MessagePack | 二进制 | 无 (Schema-less) | 二进制版 JSON。旨在无缝替换 JSON 以换取更小的体积,无需预定义 IDL。 | Redis 缓存存储、内部简单服务交互。 |
| Protobuf | 二进制 | 强 (Static IDL) | 微服务契约。强调字段编号 (Tag) 管理,极致的向后兼容性。 | gRPC、微服务内部通信。 |
| Thrift | 二进制 | 强 (Static IDL) | 全栈 RPC。不仅是序列化,还包含完整的 RPC 传输层和框架实现。 | 早期大规模跨语言服务 (Facebook 系)。 |
| Avro | 二进制 | 动态 (Schema w/ Data) | 大数据吞吐。Schema 与数据分离或随数据头传输,去掉 Tag 冗余。 | Hadoop、Kafka、数据湖 (Data Lake)。 |
2.1 JSON
基于文本的、自描述 (Self-describing) 的键值对格式。
JSON 实际上是一长串 Unicode 字符。
- 自描述性: 数据中包含了结构信息(
{,},[,])和字段名称。这意味着接收端不需要任何预先的沟通,只要有一个标准的 JSON 解析器就能读懂。 - 编码方式:
数字存储为字符串(ASCII/UTF-8)。例如整数
12345在内存中通常是 4 字节整数,但在 JSON 中变成了 5 个字符"1", "2", "3", "4", "5",占用 5 个字节。
1 | { |
对于上面的例子,去掉空格后,JSON 格式需要占用 81 bytes。
2.2 Message Pack
二进制的 JSON (Binary JSON)。
MessagePack 的目标是:在保留 JSON 的灵活性的前提下,极致压缩体积和提升解析速度。 它不需要 Schema,依然存储 Key,但它引入了 类型前缀 (Type Prefix) 系统。
对于 JSON {"a": 1},MessagePack 的二进制流可能如下:
- Map 标记 (1 byte):
0x810x8表示这是一个 Map。0x1表示这个 Map 有 1 个元素。
- Key 标记 (1 byte):
0xa10xa表示这是一个 String。0x1表示字符串长度为 1。
- Key 内容 (1 byte):
0x61(ASCII 'a') - Value (1 byte):
0x01,MessagePack 使用FixInt,对于小整数,直接用一个字节存值,不需要额外的类型标记。
与 JSON 的核心差异:
- 无分隔符: 它不需要
{或:。解析器读到0xa1就知道接下来读 1 个字节作为字符串,无需扫描,直接进行内存拷贝,速度极快。 - Key 依然存在: 它虽然压缩了结构,但
"userName"这种字段名依然被完整地编码进去了。
我们来看相同的例子:
1 | { |
对于上面列举的数据,MessagePack 会将其进行如下图所示编码:
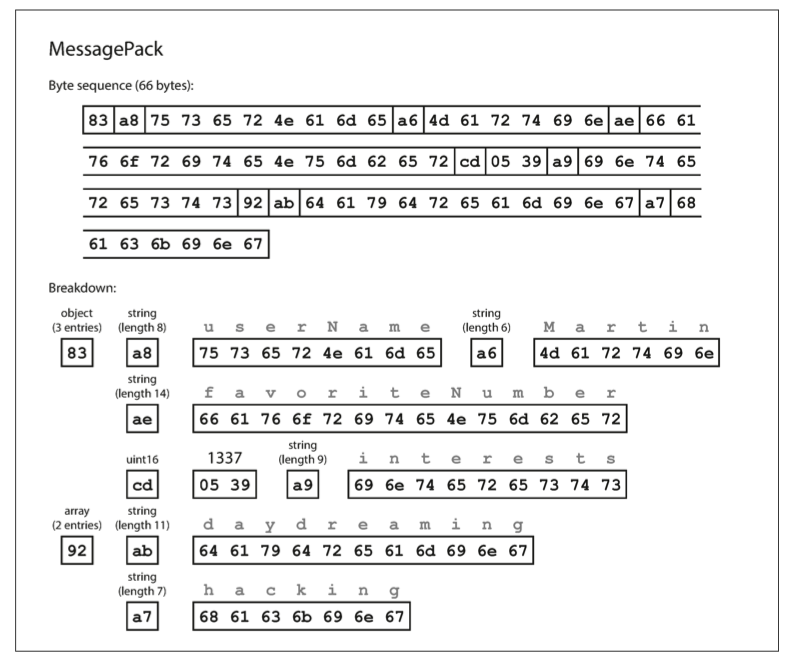
- 第 1 个字节
0x83表示接下来是一个对象(顶部四位 =0x80),有三个字段(底部四位 =0x03)。(如果你想知道,如果一个对象有超过15个字段,字段数不适合四位,它会得到不同的类型指示器,字段数编码为两字节或四字节。) - 第 2 个字节
0xa8表示接下来是一个字符串(顶部四位 =0xa0),长度为八字节(底部四位 =0x08)。 - 接下来的 8 个字节是 ASCII 中的字段名 userName。既然之前已经标明了长度,就不需要任何标记来告诉我们弦的终点(或任何逸出点)。
- 接下来的 7 个字节编码带有前缀
0xa6的六字母字符串值 Martin,依此类推。
同样的数据,MessagePack 将数据大小压缩到了 66 bytes。
2.3 Protocol Buffer
基于 IDL (接口定义语言) 的 Tag-Length-Value (TLV) 协议。
Protobuf 的核心哲学是
"约定优于配置"。通信双方必须预先持有
.proto 文件(契约)。 因为有了契约,数据包里
完全抛弃了字段名,只保留了字段编号 (Field ID)。
其核心由三个机制组成:
- Varint (Base 128): 用变长字节存储整数。数字
1占 1 字节,数字300占 2 字节。 - ZigZag: 将有符号整数映射为无符号整数,解决了负数 varint 编码效率低的问题。
- TLV 结构: 每一个字段都是 \(Tag + [Length] + Value\)。\(Tag\) 包含了 Field ID 和 Wire Type。
Protobuf 的关键是其兼容性:
- 向后兼容性:如果接收端的
.proto是旧的,它读到了一个新的 Tag(例如 ID=5),它通过 Wire Type 知道这个字段的数据类型,因此它可以安全地 跳过 这段数据,继续解析下一个字段,而不会报错。 - 向前兼容性:如果接收端的
.proto是新的,客户端没有传递新的字段,如果该字段被定义为optional可选的,则接收端依旧可以跳过该缺失的字段,继续解析下一个字段,而不会报错。
对于上面给出的例子,proto 文件定义如下:
1 | message Person { |
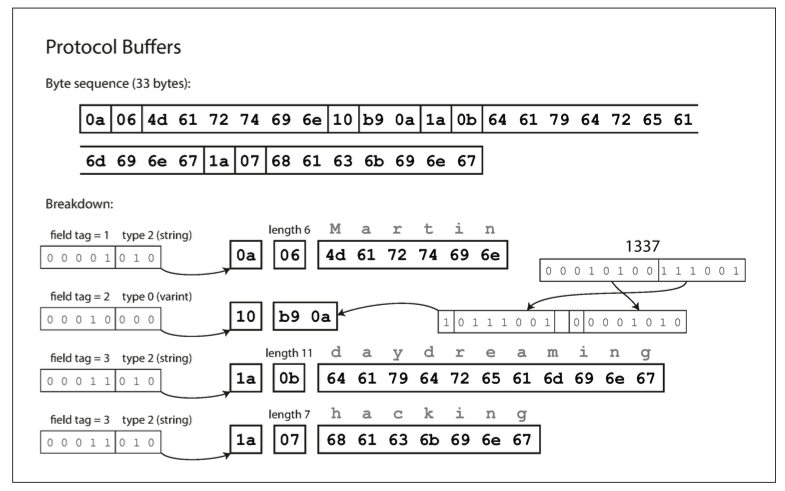
- 每一个字段都是 \(Tag + [Length] + Value\)。\(Tag\) 包含了 Field ID 和 Wire Type。
- 第 1 个字节
0x0a的低 3 位010代表 Wire Type 2(Length-delimited,即后面跟着长度)。这告诉解析器:准备好读取一段指定长度的数据(通常是字符串或嵌套对象)。高 5 位00001代表 Field ID=1。 - 第 2 个字节
0x06表示接下来的数据长度为 6 字节。既然 Tag 里的 Wire Type 是 2,解析器就知道这里必须读一个 Varint 来确定长度。06就是长度。 - 接下来的 6 个字节
4d 61 72 74 69 6e是 ASCII 编码的字符串值 "Martin"。解析器读完这 6 个字节后,知道当前字段结束,准备读取下一个 Tag。 - 重点的对于数组,它们的 tag 是一样的,如上图都是
0x1a,Protobuf 会把一样的tag组成数组。
同样的数据,Protobuf 将数据大小压缩到了 33 bytes:
- 没有 Key: 整个流里你找不到 "userName"
这个单词,只有
0x0a(ID=1) 和0x10(ID=2) 这样的编号。 - 紧凑的数字: 1337 这种数字被压缩成了变长格式,且低位在前(Little Endian 风格)。
- 无分隔符: 字符串没有结束符(如
\0),完全依靠前面的 Length (06,0b,07) 来精确定位边界。这使得解析过程可以利用内存拷贝(Memcpy),非常高效。
2.4 Thrift
全栈式的 RPC 框架与序列化协议。
Thrift 是由 Facebook 开发的跨语言 RPC 框架。与 gRPC (Protobuf) 相比,Thrift 最显著的特点是它把"传输格式"抽象出来了:
- BinaryProtocol: 简单粗暴,不做压缩,解析速度极快,但占用带宽。
- CompactProtocol: 极致压缩,逻辑复杂,节省带宽(类似 Protobuf)。
其实还有 DenseProtocol,不过只支持 C++,不具备跨语言,所以暂不讨论。
对于上面给出的例子,thrift 文件定义如下:
1 | struct Person { |
2.4.1 BinaryProtocol
核心特征: 定长、豪横、浪费。它不喜欢做位运算,喜欢用标准的 4 字节(32位)或 8 字节(64位)来存储数字,哪怕数字很小。
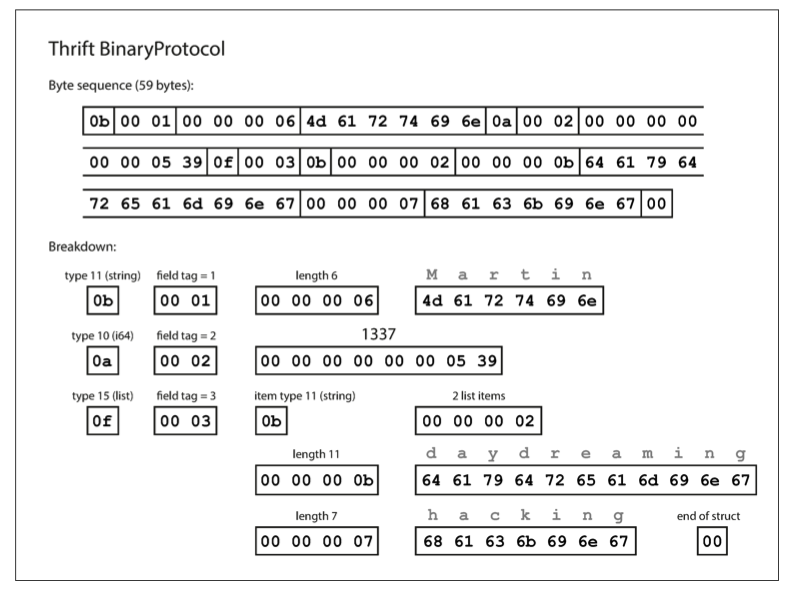
我们看第一个字段 userName="Martin":
- 第 1 个字节
0b(Type)用于表示数据类型(String)。 - 第 2-3 个字节
00 01表示 Field ID = 1。用了 2 个字节表示 ID,很奢侈啊! - 第 4-7 个字节
00 00 00 06表示字符串长度为 6。用了 4 个字节表示长度,真奢侈啊! - 第 8-13 个字节即为
Martin的 ASCII 编码。
再来看第二个字段 favoriteNumber=1337:
- 第 1 个字节
0a(Type)表示数据类型I64。 - 第 2-3 个字节
00 02表示 Field ID = 2。 - 第 4-11 个字节,用 8 字节的定长证书来表示 1337,真是奢靡!
接下来比较复杂的第三个字段 interest(List):
- 第 1 个字节
0f(Type)表示接下来是一个 List。 - 第 2-3 个字节
00 03表示 Field ID = 3。 - 第 4 个字节
0b表示数组元素的数据类型的 String。 - 第 5-8 个字节
00 00 00 02表示数组列表长度是 2,又是豪横的 4 字节整数。 - 剩下的就是数组的两个元素的 Length + Value。
最后还有一个结尾字符 00,类似于 C 语言字符串的
\0,表示整个 Struct 结束。
同样的数据,Thrift Binary Protocol 用了 59 bytes:
2.4.2 CompactProtocol
核心特征: 变长、紧凑、巧妙。这一张图的逻辑和 Protobuf 非常像,但有一个关键的区别(Delta Encoding)。

我们看第一个字段 userName="Martin":
- 第 1 个字节
0x18(Tag)跟 Protobuf 一样,是一个组合字节,低 4 位1000(Type)表示数据类型是 String,高 4 位0001(Delta)表示 FieldID = 上一个 ID + 1。因为这是第一个字段,所以 ID=1。 - 第 2 个字节
06(Length) 表示字符串长度为 6。Compact Protocol 使用 Varint 存储长度 6。只占 1 字节。 - 第 3-8 个字节即为
Martin的 ASCII 编码。
再来看第二个字段 favoriteNumber=1337:
- 第 1 个字节
0x16(Tag)低 4 位0110(Type)表示数据类型是 i64,高 4 位0001(Delta)表示 FieldID = 上一个 ID + 1。因为这是第二个字段,所以 ID=1+1=2。 - 第 2-3 个字节
f2 14是 1337 的 ZigZag Varint 编码。和 Protobuf 一样,它把 1337 编码成了变长格式,只用了 2 个字节,而不是 BinaryProtocol 的 8 个字节。
接下来比较复杂的第三个字段 interest(List):
- 第 1 个字节
0x19(Tag)低 4 位1001(Type)代表数据类型 List,高 4 位0001(Delta)表示 FieldID=1+2=3。 - 第 2 个字节
28也是一个组合字节,低 4 位(ElemType)表示数组元素类型是 String,高 4 位(Size)代表有 2 个元组。 - 剩下的就是数组的两个元素的 Length + Value。
最后一样有一个结尾字符 00 表示整个 Struct 结束。
同样的数据,Thrift Compact Protocol 用了 34 bytes:
2.5 Avro
Schema 与数据分离的、面向大数据的序列化协议。
Avro 是为 Hadoop 生态系统设计的。它的第一性原理假设是:一次定义 Schema,处理百万条数据。 因此,Avro 采取了最激进的策略:数据包里连 Field ID (Tag) 都不存。
假设 Schema 定义如下:
1 | { "type": "record", "fields": [ |
对于数据 id=10, name="foo",Avro 的二进制流里只有:
[Varint 10] + [Length 3] +
[Bytes 'foo']
- 没有 Key,没有 Tag: 没有任何标记告诉解析器
10是id。 - 依序解析: 解析器必须手里拿着 Schema,严格按照顺序读:"Schema 说第一个字段是 int,那我读一个 Varint;Schema 说第二个是 string,那我读一个 string..."。
既然没有 ID,怎么处理 Schema 变更(比如加字段)? Avro 引入了 Writer Schema(写数据时的格式)和 Reader Schema(读数据时的格式)。 在反序列化时,Avro 库会对比这两份 Schema:
- 如果 Reader 想要字段 A,但 Writer 里没有,且 Reader 定义了默认值,则自动填入默认值。
- 如果 Writer 有字段 B,但 Reader 不需要,则自动跳过。 这种 动态解析 能力使得它非常适合存储历史数据。
Avro 的优缺点也很明显:
- 优点: 对于大批量数据(数组、文件),体积最小(因为完全去除了每条记录的元数据)。支持动态 Schema。
- 缺点: 如果没有 Schema,数据完全是一堆乱码,无法解析。单条小数据传输时,如果还要带上 Schema,开销反而巨大。
我们还是回到前面介绍的例子,它的 avro 定义如下:
1 | record Person { |
或者同等含义的 JSON 结构:
1 | { |
对于上面的例子,Avro 会编码成如下图所示:
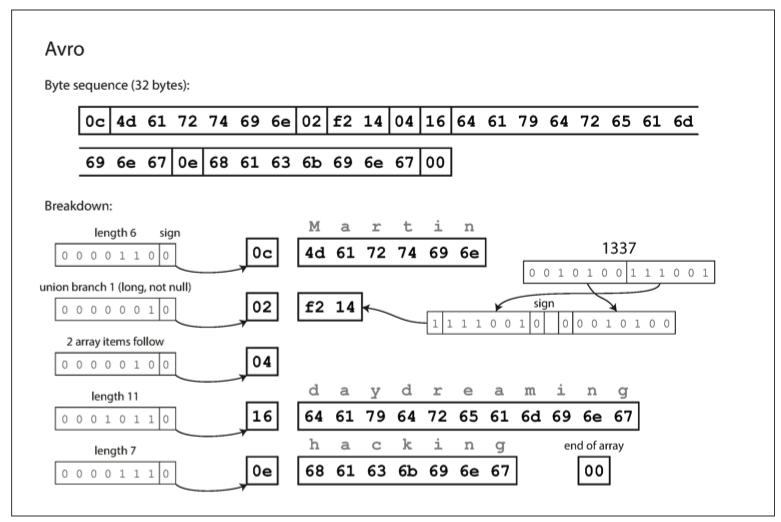
如前面所说的,在解析这张图之前,解析器必须先加载对应的
schema。
我们看第一个字段 userName="Martin":
- 第 1 个字节
0c(Length)表示字符串长度。那问题就来了,字符串 "Martin" 长度是 6,为什么这里是 12 (0x0c)?这是因为 Avro 对长度也使用了 ZigZag 编码。- Thrift/Protobuf 认为:长度永远是正数,所以用 无符号数 (Unsigned Varint)。
- Avro 认为:为了统一简单的底层实现,所有整数都当
有符号数 (ZigZag Varint)
处理;而且在数组场景下,长度甚至
真的可以是负数(作为一个特殊标记)。所以 Avro
最低位留给符号位,所以
1100中,110表示大小 6,而最后的0表示正数。
- 第 2-7 个字节即为
Martin的 ASCII 编码。前面没有任何 Tag 告诉我们这是userName,解析器只是因为这是第一个字段所以把它当字符串读。
再来看第二个字段 favoriteNumber=1337:
- 第 1 个字节
02表示 Union Index,这是 Avro 的关键特性。 Schema 定义这个字段可能是null,也可能是long。数据流必须明确这次传的是哪个。由于 Schema 中定义的顺序是[null, long],所以index0=null、index1=long。我们要选择 index1,又根据 ZigZag 编码,所以 \(1×2=2=0x02\)。 - 第 2-3 个字节
f2 14是 1337 的 ZigZag Varint 编码,跟 Protobuf/Thrift Compact 完全一致。
接下来比较复杂的第三个字段 interest(List):
- 第 1 个字节
0x04表示接下来有 2 个元素(\(2×2=4=0x04\))。 - 剩下的就是数组的两个元素的 Length + Value。
- 最后有一个
00代表数组的结束标志。
同样的数据,Avro 只用了 33 bytes,这目前的最好成绩!
通过上图的分析,我们可以清晰地看到 Avro 与 Protobuf/Thrift 的根本区别:
- 消失的 Tag:
- Protobuf:
08(Field ID=1) -> Value - Avro: 直接 Value
- Protobuf:
- Length 的 ZigZag 化:
- Protobuf 的长度就是单纯的 Varint。
- Avro 连长度都要乘 2 (ZigZag),这是为了保持整个协议整数编码的一致性。
- Union 的代价:虽然省去了 Tag,但在处理
Nullable字段时,Avro 需要一个额外的字节来标记非空。
2.6 总结
通过对同一个 Person 对象(包含 String, Int64,
Array)的编码过程进行显微镜式的观察,我们可以从
空间效率 和 设计哲学
两个维度对这些数据编码协议进行最终的复盘。
在去除了所有不必要的空格和换行后,各协议的编码结果如下表所示:
| 协议 | 最终大小 | 核心开销来源 | 技术评价 |
|---|---|---|---|
| JSON | 81 bytes | 文本冗余:包含完整的字段键名
("userName")、结构符号 ({,:)
及数字的文本表示。 |
极低效率:保留了完全的可读性与自描述性,但空间代价最高。 |
| MessagePack | 66 bytes | 键名冗余:虽然移除了结构符号并对数字进行了二进制处理,但依然保留了完整的字段键名。 | 低效率:仅解决了 JSON 的解析速度与部分体积问题,未解决结构冗余。 |
| Thrift Binary | 59 bytes | 定长编码:使用固定的 4 字节或 8 字节存储整数与长度,不进行 Varint 压缩。 | 中等效率:以空间换时间,追求内存映射级别的解析速度。 |
| Thrift Compact | 34 bytes | Delta Encoding:字段 ID 采用差值存储;ZigZag:整数采用变长编码。 | 高效率:通过位运算极大降低了元数据占比。 |
| Protobuf | 33 bytes | Tag 机制:使用数字 ID 替代文本键名;Varint:整数变长压缩。 | 高效率:利用静态 IDL 契约,实现了极高的信噪比。 |
| Avro | 32 bytes | Schema 分离:移除 Field ID (Tag),仅保留数据值与必要的长度/索引信息。 | 极致效率:完全依赖 Schema 顺序解析,适合大批量数据存储。 |
从底层设计原理来看,这几种协议代表了三种不同的数据治理哲学:
- 自描述模式 (Self-describing) —— JSON, MessagePack
- 特征: 数据包内部自带 Schema 信息(键名、类型)。
- 优势: 灵活性极高,无需预定义 IDL,完全解耦。
- 劣势: 存在大量冗余信息,不适合高频或高吞吐场景。
- 静态契约模式 (Static IDL) —— Protobuf, Thrift
- 特征: 依赖预定义的 IDL 文件(
.proto/.thrift)。数据包通过 Field ID(Tag)与 IDL 映射。 - 优势: 实现了强类型约束与向后兼容性(Tag 机制),解析速度快。
- 劣势: 需要维护 IDL 文件,客户端与服务端需同步更新代码。
- 特征: 依赖预定义的 IDL 文件(
- 动态分离模式 (Schema-on-Read) —— Avro
- 特征: 数据与 Schema 分离(或在文件头仅定义一次)。数据体中不包含任何字段标识,仅包含值。
- 优势: 在处理大规模数据集(如数仓文件)时,消除了每条记录的元数据开销。支持读写 Schema 动态演进。
- 劣势: 必须严格依赖 Schema 解析,单条数据传输时若需附带 Schema 则开销巨大。
在实际架构设计中,应根据业务场景的 I/O 特性 与 协作模式 进行选择:
- 对外 API / 前端交互 / 调试接口 \(\rightarrow\) JSON
- 优先考虑可读性与通用性,浏览器原生支持是其不可替代的优势。
- 微服务内部通信 (RPC) \(\rightarrow\) Protobuf
(gRPC)
- 强契约(IDL)能有效降低多人协作中的接口不一致风险,且 Google 生态支持完善。
- 大数据存储与离线分析 (Data Lake) \(\rightarrow\) Avro
- 在 HDFS/S3 存储 TB 级数据时,移除 Tag 带来的存储成本节省十分显著,且适合 Schema 频繁变更的 ETL 场景。
- 遗留系统或特定语言栈 \(\rightarrow\) Thrift
- 如果需要完整的 RPC 框架且不仅限于序列化(如需要特定的 Server 模型),或者在 Protobuf 支持较弱的语言环境中使用。
3. 总结
回顾 gRPC 的设计架构,我们可以清晰地看到,其高性能并非源于单一技术的突破,而是源于 传输层 (HTTP/2) 与 表示层 (Protobuf) 两个维度的深度优化叠加。gRPC 从第一性原理出发,分别解决了网络通信中的"拥塞"与"冗余"问题。
在表示层,gRPC 坚定地选择了 Protocol Buffers,这不仅仅是为了更小的体积,更是为了更严谨的契约。
- 极高的信噪比:通过前文的字节级解剖,我们看到
Protobuf 将一个包含丰富信息的
Person对象压缩至 33 bytes,仅为 JSON (81 bytes) 的 40%。它通过移除字段名(Keys)并使用 Varint/ZigZag 压缩数字,极大地减少了网络带宽的占用。 - 解析效率:二进制协议允许计算机通过位运算直接解析数据,避免了文本协议中昂贵的字符串匹配与浮点数转换开销。
- 强契约保证:IDL (
.proto) 的存在使得通信双方必须遵守严格的类型约束,这种“静态”特性消除了运行时猜测数据类型的成本,同时也为大规模微服务治理提供了坚实的基础。
在传输层,gRPC 摒弃了文本格式的 HTTP/1.1,全面拥抱二进制的 HTTP/2,这从物理上改变了连接的使用方式。
- 多路复用 (Multiplexing):这是 HTTP/2 最核心的优势。gRPC 允许在同一个 TCP 连接上并发处理多个请求(Stream)。每个 Request/Response 被拆分成多个二进制帧 (Frame) 并打乱发送,接收端根据 Stream ID 重新组装。这彻底解决了 HTTP/1.1 的 队头阻塞 (Head-of-Line Blocking) 问题,使得单一连接的吞吐量成倍提升。
- 头部压缩 (HPACK):在微服务架构中,RPC 调用往往伴随着大量重复的 Header (如 Auth Token, Tracing ID)。HTTP/2 使用 HPACK 算法在客户端和服务端维护动态字典,对 Header 进行增量压缩,进一步减少了带宽消耗。
- 双向流 (Bi-directional Streaming):得益于 HTTP/2 的流特性,gRPC 原生支持四种通信模式,使得实时推送、长连接对话等复杂业务场景的实现变得像普通函数调用一样简单。
最终,彻底掌握 gRPC 意味着理解它在 互操作性 与 性能 之间所做的权衡:
- 它不是万能的:在浏览器前端、简单的 CRUD 接口或对调试可读性要求极高的场景下,REST/JSON 依然是更优的选择。
- 它是云原生的通用语:在微服务内部通信、移动端与后端的长连接交互、以及低延迟高吞吐的系统中,gRPC 凭借其 Protobuf 的极致编码 与 HTTP/2 的高效传输,成为了现代分布式系统事实上的标准。
理解了这些底层原理,我们才能在架构选型时,不盲目跟风,而是根据业务的真实需求(是追求极致的 Bytes 节省,还是追求开发的灵活性),做出最准确的技术决策。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




