要彻底掌握分库分表环境下的 ID 生成方案,不能只背诵"雪花算法"的配置,而必须从数据库底层原理(B+ 树)和分布式系统的 CAP 定理出发,建立一套完整的评估体系。
我们可以从 "不可能三角" 开始,层层拆解,最后落实到工业级的设计。
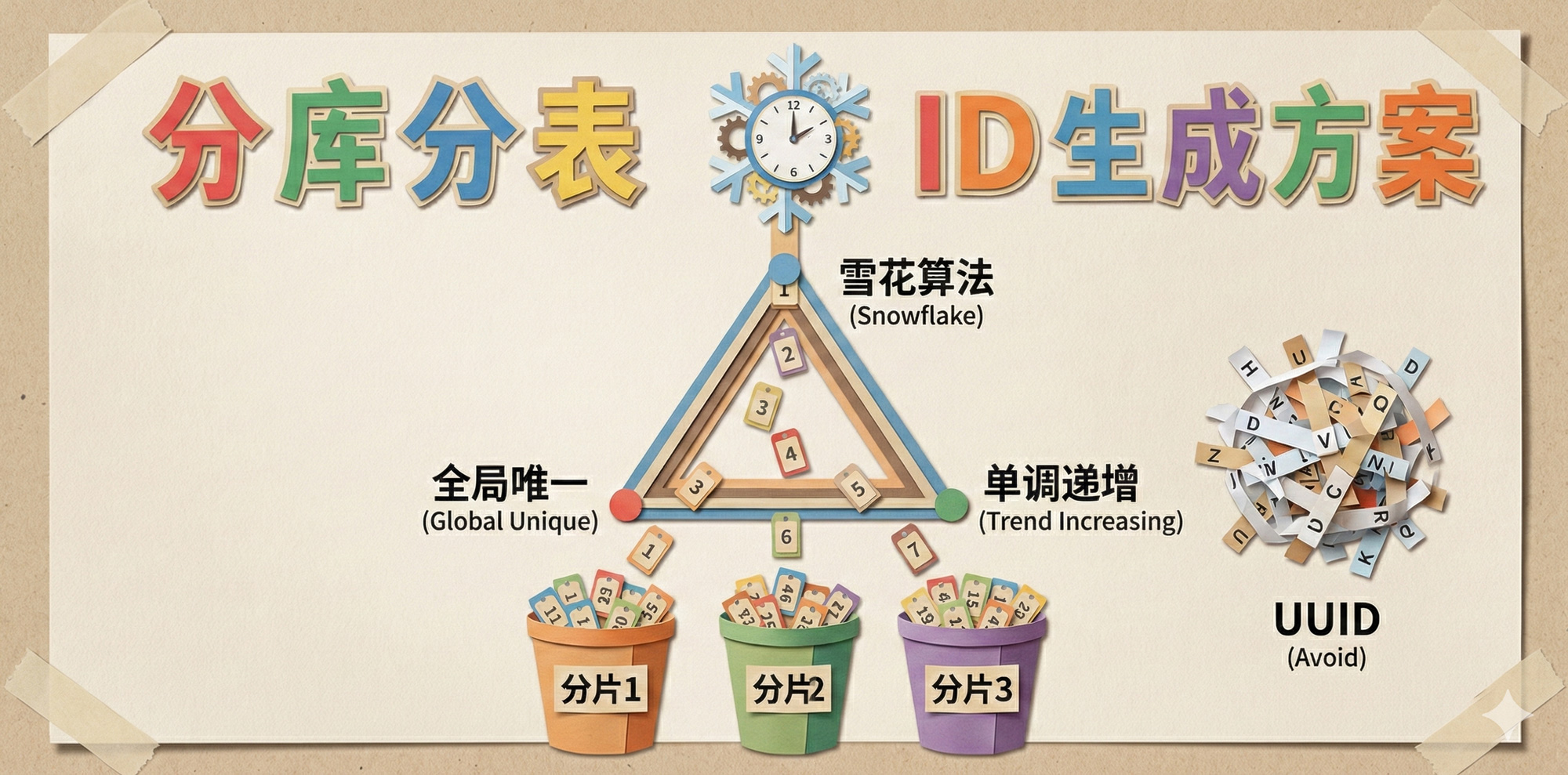
1. 不可能三角
在分库分表场景下,一个优秀的 ID 必须同时满足以下三个维度的苛刻要求,但这往往存在权衡:
- 全局唯一性 (Uniqueness):这是基本底线。不能出现两个分片生成了同一个 ID。
- 单调递增性 (Trend Increasing):这是 MySQL 场景下的核心痛点。MySQL 的 InnoDB 引擎使用 聚簇索引 (Clustered Index)。数据是直接挂在主键 B+ 树叶子节点上的。如果 ID 是随机的(如 UUID),插入新数据时,会频繁导致 B+ 树中间节点的 页分裂 (Page Split),造成大量的随机磁盘 I/O 和碎片,极大地降低写入性能。所以:ID 必须尽量有序,最好是严格递增。
- 高可用与高性能 (Availability & Performance):发号器不能成为系统的瓶颈,也不能因为单点故障导致整个业务停摆。
2. 方案演进
2.1 反面教材:UUID
UUID 是原理是利用网卡 MAC 地址、时间戳、随机数生成 128 位字符串。它适用于生成 Token、文件名,但绝不用于数据库主键。
主要缺点有:
- 性能杀手:无序,导致 MySQL 频繁页分裂(写入性能比有序 ID 差 N 倍)。
- 存储浪费:128 位字符串太长,且作为二级索引的叶子节点值,会膨胀整个数据库索引空间。
- 不可读:无法在日志中快速定位时间或业务含义。
2.2 远古方案:数据库步长法
利用 MySQL 的
auto_increment,但不同分片设置不同的起始值和步长。
- DB1: start=1, step=2 -> 1, 3, 5...
- DB2: start=2, step=2 -> 2, 4, 6...
这种方案有一个最大的缺陷:一旦设定了 step=2,后续想扩容成 3 个分片,所有旧数据的 ID 生成逻辑都要改,几乎无法平滑扩容。
美团的 Leaf-segment 对这个方案进行了改进,它的核心思路是单独搞一个发号服务,每次从数据库领 1000 个 ID(号段)放在内存里慢慢发。
- 优点:减轻数据库压力,容忍数据库短时间宕机。
- 缺点:ID 不严格连续,依赖中心化服务。
2.3 黄金标准:雪花算法
这是目前最主流的分布式 ID 方案,由 Twitter 提出。它本质上是一个位运算 (Bit Manipulation) 的艺术。

- 1 bit:不使用(符号位)。
- 41 bits:毫秒级时间戳(可以使用 69 年)。
- 10 bits:机器 ID(5 位数据中心 ID + 5 位工作机器 ID,支持 1024 个节点)。
- 12 bits:序列号(每毫秒内支持生成 4096 个 ID)。
笔者认为,雪花算法最大的价值在于提出了ID 分段的思想,我们大可以根据需求、借助时间戳和分段,自由切割 ID 的不同比特位,赋予其不同的含义,灵活设计自己的 ID 算法。
雪花算法有两大优势:
- 本地生成:不依赖网络请求,性能极高。
- 趋势递增:高位是时间,整体随时间递增,对 B+ 树友好。
但是雪花算法强依赖服务器系统时间。如果服务器时间校准(NTP)导致时间回退,可能会生成 重复 ID。
2.3.1 直接拒绝
如果发现当前时间 < 上次生成时间,抛出异常,拒绝服务(最简单,但影响可用性)。
1 | // Rust 伪代码示例 |
2.3.2 等待追赶
NTP 的校准通常非常微小。如果发现回拨了 2ms,程序可以选择 不报错,死循环等待。
1 | // Rust 伪代码示例 |
- 代价:这次 ID 生成请求会增加几毫秒的延迟(用户无感知)。
- 收益:服务不会挂,数据不会错。
2.3.3 扩展位
如果回拨时间较长(比如几秒),等待策略会导致请求超时。 百度开源的 UidGenerator 使用了一种"未来时间"的思路,或者利用保留位。
- 思路:Snowflake 的 64 位中,通常有
1-2位是保留位(Reserved)。 - 做法:当发生回拨时,将
last_timestamp继续递增(使用虚拟时间),同时修改sequence或者启用回拨位。 - 本质:此时生成的 ID 里的"时间戳部分"已经不是真实的物理时间了,而是逻辑时间。只要保证 ID 的单调递增性,物理时间不准确并不影响数据库的主键性能。
这里还有个问题!self.last_timestamp
是存在内存中的,服务重启怎么办?
解决方案是:
每次服务启动时,先去 ZK/Redis 拿一下这台机器"上次汇报的时间"。如果
当前系统时间 < 上次汇报时间,说明机器时间有问题,拒绝启动报警。当然,这里肯定是异步汇报的,而且,可以汇报未来时间,比如当前系统时间+3s,这样,哪怕我崩溃了,Redis 里记录的时间戳一定比我发出的最后一个 ID 的时间戳要大。重启时只要检查 Redis,就能 100% 保证时间轴没有重叠。
3. 多维查询
分库分表的 ID 问题,除了 ID 的生成问题,还有 ID 的选择问题。
思考一下:订单ID、用户ID、商户ID。 当拆分的时候,根据哪个维度进行拆分呢?
假设按用户 ID 维度拆分,同一个用户 ID 的所有订单会落到同一个库的同一张表里。 当查询的时候,按用户 ID 查,可以很容易地定位到某个库的某个表。但如果按订单 ID 或 商户 ID 维度查询,就很难做。
解决思路有:
- 建立一个映射表:商户 ID 和用户 ID 之间的映射关系,订单 ID 和用户 ID 之间的映射关系,存在分布式事务问题。
- 业务双写:同一份数据,两套分库分表。一套按用户 ID 切分,一套按商户 ID 切分。同样,存在写入多个库的分布式事务问题。
- 异步双写:还是两套表,只是业务单写。然后通过监听 Binlog,同步到另外一套表。
- 基因法:两个维度统一到一个维度,把订单 ID 和用户 ID 统一成一个维度,比如订单 ID 固定前几位是用户 ID。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




