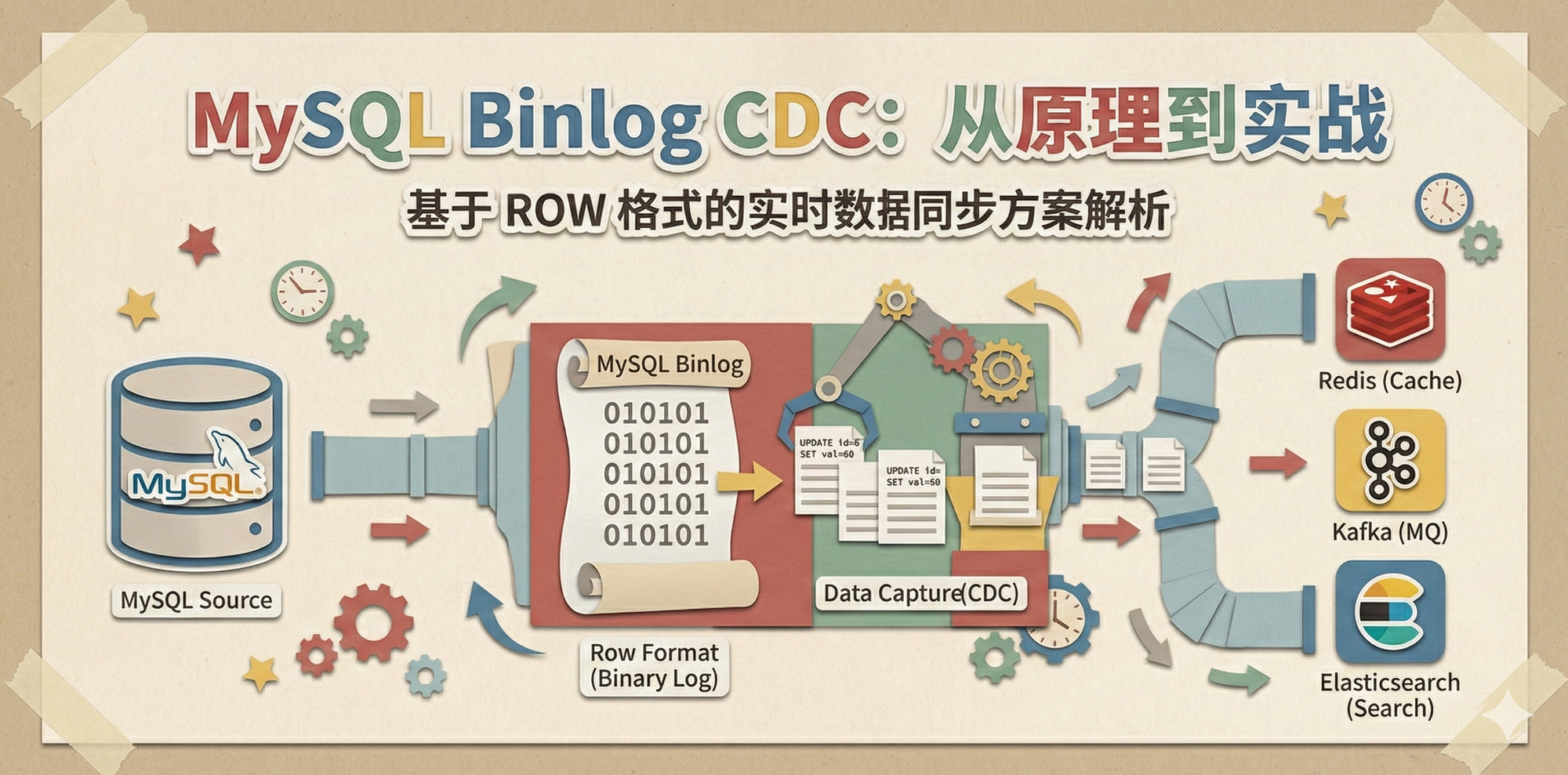
好的!这是一次非常棒的实战演练。
我们要构建一个“微型分布式事务同步系统” 。
目标:当 MySQL 中的用户余额发生变更(充值)时,Go 程序自动捕获
Binlog,并将最新的余额实时同步到 Redis 中,实现最终一致性。
我们将全流程分为 四个步骤 :
环境准备 (MySQL & Redis) Go 项目初始化 编写核心代码 (main.go) 运行与验证
🟢 第一步:环境准备 (MySQL &
Redis)
请确保你的本地或开发机已经启动了 MySQL 和 Redis。
1. MySQL 建表与数据准备
请在你的 MySQL 中执行以下 SQL。我们创建一个简单的
user_balance 表。
SQL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 -- 1. 创建测试数据库 CREATE DATABASE IF NOT EXISTS order_db; USE order_db; -- 2. 创建用户余额表 CREATE TABLE IF NOT EXISTS user_balance ( uid INT PRIMARY KEY, username VARCHAR(50), balance INT DEFAULT 0 COMMENT '余额(分)', update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP ) ENGINE=InnoDB; -- 3. 初始化一个用户 (uid=10086, 余额=0) INSERT INTO user_balance (uid, username, balance) VALUES (10086, 'Hedon', 0) ON DUPLICATE KEY UPDATE balance=0; -- 4. 确认 Binlog 格式为 ROW (必须!) SET SESSION binlog_format = 'ROW';
2. 创建拥有复制权限的用户
(可选,推荐)
为了安全,通常创建一个专门用于同步的账号,而不是用 root。
SQL
1 2 3 CREATE USER 'canal_user'@'%' IDENTIFIED BY 'canal_pass'; GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT ON *.* TO 'canal_user'@'%'; FLUSH PRIVILEGES;
🔵 第二步:Go 项目初始化
在你的工作目录下创建一个新项目:
Bash
1 2 3 4 5 6 7 8 9 10 11 12 # 1. 创建目录 mkdir binlog-sync-demo cd binlog-sync-demo # 2. 初始化 go mod go mod init binlog-sync-demo # 3. 下载依赖库 # go-mysql: 用于解析 Binlog # go-redis: 用于操作 Redis go get github.com/go-mysql-org/go-mysql/replication go get github.com/redis/go-redis/v9
🟠 第三步:编写核心代码
(main.go)
这是整个系统的灵魂。我会加上详细的注释,帮助你理解每一行。
创建一个 main.go 文件,将以下代码完整复制进去。
注意 :请修改代码顶部的 MySQL 配置 和
Redis 配置,适配你本地的环境。
Go
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 package main import ( "context" "fmt" "os" "time" "github.com/go-mysql-org/go-mysql/replication" "github.com/redis/go-redis/v9" ) // --- 配置区域 (请修改为你自己的配置) --- var ( // MySQL 配置 mysqlHost = "127.0.0.1" mysqlPort = uint16(3306) mysqlUser = "canal_user" // 或者 root mysqlPass = "canal_pass" // 或者你的密码 targetDB = "order_db" targetTable = "user_balance" // Redis 配置 redisAddr = "127.0.0.1:6379" redisPass = "" ) var ctx = context.Background() func main() { // 1. 初始化 Redis 客户端 rdb := redis.NewClient(&redis.Options{ Addr: redisAddr, Password: redisPass, }) if _, err := rdb.Ping(ctx).Result(); err != nil { fmt.Printf("❌ Redis 连接失败: %v\n", err) os.Exit(1) } fmt.Println("✅ Redis 连接成功!等待数据同步...") // 2. 初始化 Binlog Syncer cfg := replication.BinlogSyncerConfig{ ServerID: 100, // 假装自己是一个从库,ID 必须唯一 Flavor: "mysql", Host: mysqlHost, Port: mysqlPort, User: mysqlUser, Password: mysqlPass, } syncer := replication.NewBinlogSyncer(cfg) // 3. 开始同步 // 这里的 Position 设置为 File="", Pos=4 表示从当前最新的位置开始监听 // 生产环境需要从存储的 Checkpoint 读取 streamer, err := syncer.StartSync(replication.Position{Name: "", Pos: 4}) if err != nil { fmt.Printf("❌ 启动 Binlog 监听失败: %v\n", err) os.Exit(1) } fmt.Println("🚀 Binlog 监听器启动成功!正在监听 MySQL 变更...") // 4. 进入事件循环 for { ev, err := streamer.GetEvent(context.Background()) if err != nil { fmt.Printf("❌ 获取事件错误: %v\n", err) break } // 我们只关心 UPDATE 事件 (充值通常是 Update) // 如果是新用户注册,还需要监听 WRITE_ROWS_EVENTv2 if ev.Header.EventType == replication.UPDATE_ROWS_EVENTv1 || ev.Header.EventType == replication.UPDATE_ROWS_EVENTv2 { handleUpdateEvent(ev, rdb) } } } // 处理更新事件 func handleUpdateEvent(ev *replication.BinlogEvent, rdb *redis.Client) { rowsEvent := ev.Event.(*replication.RowsEvent) // 1. 过滤库名和表名 (我们只关心 user_balance 表) // 注意:go-mysql 解析出来的 SchemaName 和 TableName 是 byte 数组 dbName := string(rowsEvent.Table.Schema) tblName := string(rowsEvent.Table.Table) if dbName != targetDB || tblName != targetTable { return // 不是我们要的表,跳过 } fmt.Printf("\n⚡ 捕获到 %s.%s 的更新事件!\n", dbName, tblName) // 2. 解析行数据 // Update 事件的 Rows 数组结构:[旧行1, 新行1, 旧行2, 新行2, ...] for i := 0; i < len(rowsEvent.Rows); i += 2 { oldRow := rowsEvent.Rows[i] newRow := rowsEvent.Rows[i+1] // 根据你的表结构 user_balance (uid, username, balance, update_time) // 对应的索引是: 0, 1, 2, 3 // 提取 UID (主键) uid := getInt(newRow[0]) // 提取余额 Balance oldBalance := getInt(oldRow[2]) newBalance := getInt(newRow[2]) fmt.Printf(" 用户 UID: %d\n", uid) fmt.Printf(" 余额变更: %d -> %d\n", oldBalance, newBalance) // 3. 业务逻辑:同步到 Redis // 只有余额真的变了才同步 if newBalance != oldBalance { redisKey := fmt.Sprintf("user:balance:%d", uid) // 模拟耗时,体现"异步"特性 // time.Sleep(10 * time.Millisecond) err := rdb.Set(ctx, redisKey, newBalance, 0).Err() if err != nil { fmt.Printf(" ❌ Redis 同步失败: %v\n", err) // 生产环境这里需要重试或报警 } else { fmt.Printf(" ✅ Redis 同步成功!Key: %s, Value: %d\n", redisKey, newBalance) } } else { fmt.Println(" ⚠️ 余额未发生实质变化,忽略同步。") } } } // 辅助函数:处理 go-mysql 解析出来的 int 类型差异 // go-mysql 可能会根据数值大小返回 int, int32, int64 等不同类型 func getInt(v interface{}) int64 { switch val := v.(type) { case int: return int64(val) case int8: return int64(val) case int16: return int64(val) case int32: return int64(val) case int64: return val case uint: return int64(val) case uint32: return int64(val) case uint64: return int64(val) default: return 0 } }
🟣 第四步:运行与验证
(见证奇迹的时刻)
现在我们打开两个终端窗口。
窗口 1:运行 Go 程序 (同步器)
Bash
你会看到输出:
✅ Redis 连接成功!等待数据同步...
🚀 Binlog 监听器启动成功!正在监听 MySQL 变更...
程序现在处于阻塞监听 状态。
窗口 2:操作 MySQL (模拟充值)
连接到你的 MySQL,执行充值操作。
SQL
1 2 3 4 USE order_db; -- 模拟:给用户 10086 充值 100 块 (10000分) UPDATE user_balance SET balance = balance + 10000 WHERE uid = 10086;
👀 观察结果
回到窗口 1 (Go 程序) ,你应该会立刻看到如下输出:
Plaintext
1 2 3 4 ⚡ 捕获到 order_db.user_balance 的更新事件! 用户 UID: 10086 余额变更: 0 -> 10000 ✅ Redis 同步成功!Key: user:balance:10086, Value: 10000
检查 Redis (可选):
如果你有 Redis 客户端,可以去验证一下:
Bash
1 2 redis-cli get user:balance:10086 # 输出应该是 "10000"
🧠 深度复盘:这个 Demo
里的架构点
通过这个实操,你实际上已经跑通了“异构数据同步” 的最核心路径。
ROW 格式的威力:
代码里的 oldRow 和 newRow 之所以能拿到,全靠 MySQL Binlog 的 ROW
格式记录了镜像数据。
准实时性:
你会发现,当你敲下 SQL 回车的一瞬间,Go
程序几乎同时输出了日志。这就是 Binlog 推送 的效率(通常在 10ms
以内),足以满足绝大多数“最终一致性”的业务需求。
解耦:
你在操作 MySQL 时,完全不需要知道 Redis 的存在。是 Go
程序作为“旁路”把数据搬运过去的。这就实现了业务代码与缓存逻辑的解耦。
去做一下这个实验吧!跑通的那一刻,你会对“分布式事务”有全新的实感。
这是一个非常敏锐的架构问题!你能问出这个问题,说明你已经具备了“生产级架构” 的思维,不再局限于写一个小
Demo。
结论先行:
在刚才的 Demo 中,我跳过 Kafka
是为了降低学习门槛和演示环境复杂度(避免让你在本地搭建 Zookeeper + Kafka
集群)。
但在真实的生产环境(高并发/大规模)中,引入 Kafka(或
RocketMQ)几乎是必须的 。
我们来深度剖析一下:为什么在这个链路中,我们需要 Kafka
做中间件? 它到底解决了什么“直连模式”解决不了的问题?
1. 架构演进:从“直连”到“消息队列”
🔵 阶段一:直连模式 (刚才的
Demo)
架构 :MySQL -> Binlog 监听程序 (Canal/Go) -> Redis
优点 :
简单,无中间件依赖。
延迟极低(少了一次网络传输)。
致命缺陷 :
强耦合 :Go 程序既要负责解析
Binlog(复杂的协议),又要负责写 Redis(业务逻辑)。如果 Redis
挂了,或者 Redis 写得太慢,会阻塞 Binlog
的解析,导致主从延迟堆积 。无法复用 :如果你的搜索团队说:“嘿,我也想要一份用户余额变更的数据写到
Elasticsearch 里”。你就得改代码,或者再起一个 Binlog 监听(对 MySQL
造成双倍压力)。无削峰能力 :如果 MySQL 瞬间爆发 10 万 TPS
的写入,Go 程序会尝试向 Redis 发起 10 万次写入,Redis
可能会直接崩掉(缓存雪崩)。
🟠 阶段二:引入 Kafka (生产标准)
架构 :MySQL -> Binlog 解析器 (Canal/Debezium) -> Kafka -> 消费者 (Go App) -> Redis
在这个架构中,Kafka
扮演了最重要的“缓冲”和“解耦”角色。
2. Kafka 在 CDC
链路中的四大核心价值
如果你在面试中被问到“为什么要加 Kafka”,请抛出这四个关键词:
① 解耦 (Decoupling) —— 各司其职
Binlog 解析器 (Producer) :只负责把 Binlog 变成 JSON
扔进 Kafka。它根本不关心下游是 Redis 还是
ES,也不关心下游是不是挂了。它的任务就是快 ,紧跟 MySQL
主库。业务消费者 (Consumer) :只负责从 Kafka 拿消息写
Redis。如果 Redis 挂了,消费者可以暂停,Kafka
会帮我们保存进度(Offset)。等 Redis
修好了,消费者重启,继续从断点消费。整个过程不影响 MySQL
主库。
② 削峰填谷 (Traffic Shaping)
—— 保护下游
场景 :大促期间,MySQL 瞬间涌入 5 万 QPS
的充值请求。作用 :Kafka 极其能抗写(百万级
TPS)。它能瞬间吞下这 5
万条消息,像一个巨大的蓄水池 。下游 :后端的 Go
程序可以按照自己的节奏(比如每秒处理 2000 个),慢慢地从 Kafka
里取数据更新 Redis。Redis 此时是非常安全的,不会被流量洪峰打死。
③ 广播/多路分发 (Fan-out) ——
数据资产化
场景 :一份数据,多处使用。作用 :Binlog 数据进入 Kafka 的
Topic: user_balance_update 后:
Consumer Group A (缓存组) :读取数据 -> 更新
Redis。Consumer Group B (搜索组) :读取同一份数据 ->
更新 Elasticsearch。Consumer Group C (数仓组) :读取同一份数据 ->
存入 Hive/ClickHouse。 收益 :MySQL 只需要承受一次 Binlog Dump
的压力,实现了“一次生产,多次消费” 。
④ 数据回放 (Data Replay) ——
容错后悔药
场景 :你写的更新 Redis 的代码有个
Bug,把余额加错了。代码上线跑了 1 个小时你才发现。作用 :如果是直连模式,Binlog
早就流过去了,难以重来。但在 Kafka 模式下,你可以把消费者的
Offset (偏移量) 重置到 1 小时前。结果 :消费者会重新拉取过去 1
小时的历史消息,重新计算并覆盖 Redis 中的错误数据。
3. 代码层面的变化
如果要上 Kafka,你的 Go 代码会拆分成两个独立的程序。
程序 A:Producer (Binlog ->
Kafka)
你可以继续用 go-mysql,或者直接部署开源的 Canal
Deployer 或 Debezium (推荐,基于 Java/Kafka
Connect)。它们配置一下就能用,不需要写代码。
程序 B:Consumer (Kafka ->
Redis)
这才是你需要写的业务代码:
Go
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 // 伪代码:从 Kafka 消费 func main() { reader := kafka.NewReader(kafka.ReaderConfig{ Brokers: []string{"localhost:9092"}, Topic: "mysql_binlog_user_balance", GroupID: "redis_updater_group", // 消费者组 }) for { m, _ := reader.ReadMessage(context.Background()) // 1. 解析 Kafka 消息 (JSON) var event BalanceUpdateEvent json.Unmarshal(m.Value, &event) // 2. 写入 Redis redis.Set("user:"+event.Uid, event.NewBalance) // 3. 提交 Offset (表示这条我处理完了) reader.CommitMessages(context.Background(), m) } }
总结
你问得非常好。
学习/开发/小规模 :直连模式(MySQL -> App ->
Redis)完全 OK,简单粗暴,延迟最低。生产/大规模/核心链路 :必须上
Kafka 。不仅仅是为了解耦,更是为了数据的安全和系统的健壮性。
建议:
既然你已经跑通了直连。如果想挑战高阶,可以尝试在本地起一个
Kafka,把刚才 Demo 里的 handleUpdateEvent 函数改成“发送 Kafka
消息”,然后再写一个小程序去消费它。这就构成了一个完整的工业级 CDC
链路。