在单机数据库模式下,我们享受了太多的理所当然:ACID 事务、强一致性读写、瞬间的数据可见性。然而,一旦引入了异步主从复制,这个美好的世界就崩塌了。系统从 CP (一致性) 模型滑向了 AP (可用性) 模型。主从延迟(Replication Lag) 像一个幽灵,让许多在单机下奉为圭臬的最佳实践,变成了分布式环境下的致命陷阱。
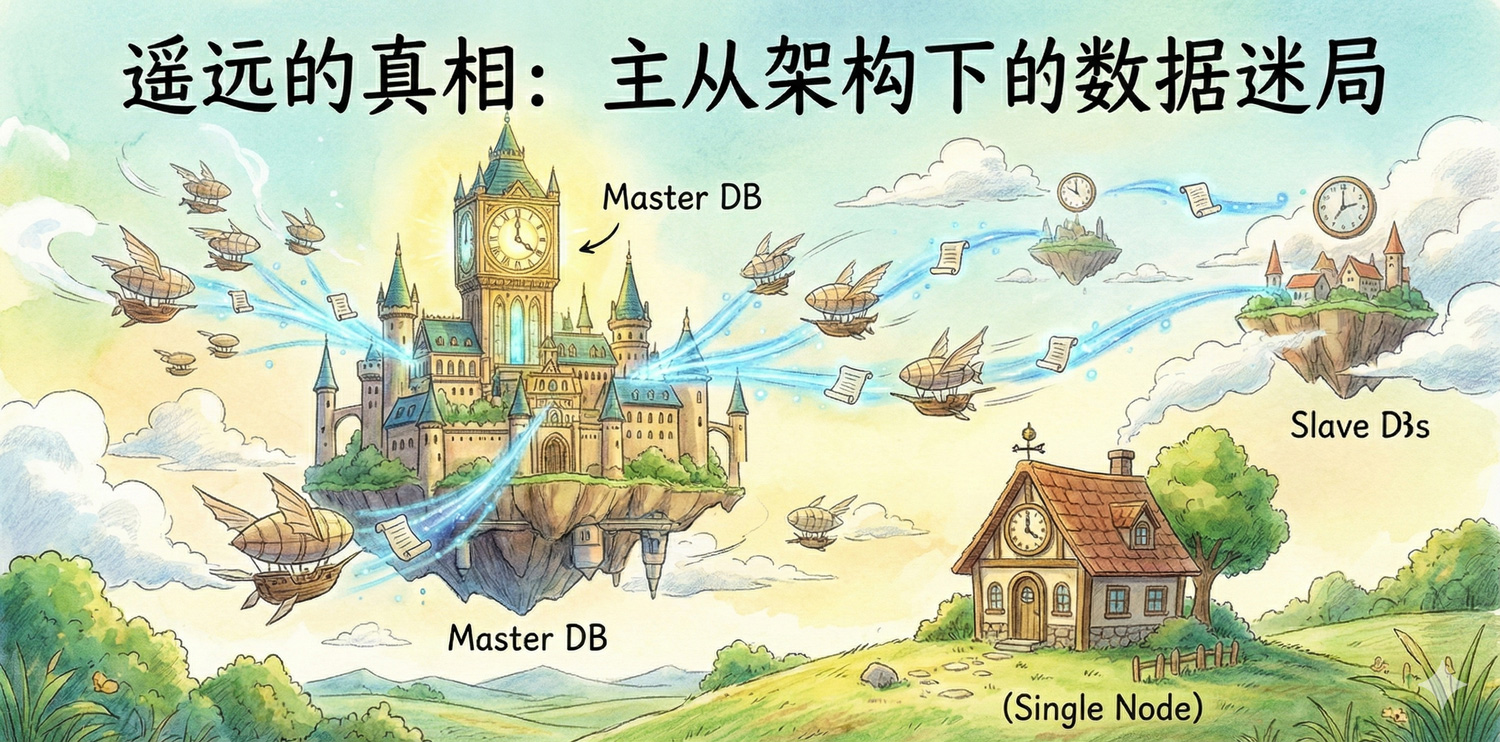
核心矛盾根源:真相的传播延迟
- 单机模式:"真相"只有一个(唯一的 DB 实例)。写入即事实,读取即真相。时间差近乎为零。
- 主从模式:"真相"在传播。主库是当前的真相,从库是几百毫秒甚至几秒前的"历史影像"。依赖历史影像做决策,必然出错。
从单机到主从架构的升级,不是简单的加几台机器,而是一场思维方式的革命:
- 放弃对实时强一致性的幻想:在分布式系统中,除了核心的金融级数据,大部分场景都要接受最终一致性。
- 识别真理之源:时刻清楚 Master DB 是唯一的真理。Slave DB 只是用于分担非敏感读压力的快照副本。
- 防御性编程:写代码时,永远要假设你读到的数据可能是旧的,并思考"如果它是旧的,我的业务逻辑会不会炸?"如果会炸,就必须升级方案(走主库、加异步校验链等)。
本篇接下来就梳理单机模式最佳实践在主从架构下失效的经典场景。
1. 缓存一致性
在单机模式下,为了应对 MySQL 和 Redis(缓存)的一致性,业界通用的解决方案是 Cache Aside(旁路缓存)。即:先更新 DB,再删缓存。下次读请求发现 Cache Miss,查 DB 并回填。因 DB 里的数据永远是最新的,回填缓存没问题。
但是在主从模式下就不一样了:
写请求删了缓存。读请求去从库查到了旧数据(因为延迟)。读请求把旧数据当作新数据塞回了 Redis。结果就导致了 Redis 里存储了脏数据。
总结
| 核心场景 | 单机模式下的最佳实践 (Best Practice) | 主从模式下的失效原因 (The Trap) | 必须升级的分布式方案 (The Upgrade Path) |
|---|---|---|---|
| 缓存一致性 (Cache-Aside) | 先写 DB,再删缓存 依赖读操作回填缓存。简单高效,极少出现不一致。 | 脏数据回填死结 写完主库删缓存后,读请求立刻打到延迟的从库,读到旧数据并永久回填入缓存。(即我们刚深入讨论的案例)。 | 方案 A (标准):Binlog
异步消息队列删除(引入异步重试机制兜底)。 方案 B (极强):回填前强制校验主库版本号(牺牲主库性能换取强一致)。 |
| 读己之写 (Read-Your-Own-Write) | 写完直接读 用户修改资料后,立刻刷新页面调用查询接口,能马上看到更新后的信息。 | 用户体验崩塌 刚写完主库,转头读了从库。用户发现自己刚改的数据没生效,产生恐慌或重复提交。 | 方案 A (折中):短期强制路由(写操作后的 N 秒内,该用户的读请求强制走主库)。 方案 B (复杂):客户端版本追踪(客户端记住自己刚修改的版本号,请求时带上,中间件判断从库是否追上)。 |
| 唯一性检查 / 业务前置校验 (Business Check) | 先查后写 (Check-Then-Act)
例如注册时:SELECT count(*) FROM user WHERE email=?,若为 0
则 INSERT。 |
并发重复与校验失效 两个请求同时发到不同从库查询,都以为 email 不存在,然后同时向主库发起 INSERT。虽然主库唯一索引能挡住,但业务层的校验逻辑彻底失效,引发大量报错。 | 方案
A:强制查主库(所有涉及状态决策的前置查询,必须走主库)。
方案 B:分布式锁(在查 DB 前,先在 Redis/ZK 上抢占一个 key,但这引入了新组件依赖)。 |
| 高并发库存扣减 (Inventory Deduction) | 悲观锁 SELECT FOR UPDATE 或 乐观锁
UPDATE ... WHERE count > 0 依赖数据库行锁或
MVCC 保证原子性扣减。 |
从库读取导致超卖 如果为了性能去从库查询“当前库存”,得到旧值(比如显示有货,实际主库已没货),然后发起扣减请求,导致判断失误。 | 铁律:涉及钱和库存的操作,读写必须全部在主库完成。 或者彻底升级架构,使用 Redis + Lua 脚本做库存扣减中心,数据库只做异步落库。 |
| 事务状态查询 (Transaction Status) | 直接查询订单表状态 支付回调后,查询订单表确认订单是否已变为“已支付”。 | 回调“未找到订单” 支付成功的回调非常快,可能在主从同步完成前就到达。此时去从库查订单状态,可能查到还是“未支付”,导致业务逻辑错误。 | 方案:强制查主库。 对于此类时效性极高的状态确认查询,绝不能走从库。 |
许可协议
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。
分享文章




