
Claude Code 源码"开源"之后,相信很多人拿着各种 AI 工具对其源码进行了一顿操作,然而,相信大部分人,都是让 CC "重新认识了一遍自己",AI 学会了,但自己好像没学会。
笔者认为,带着问题去让 AI 进行主题性分析的话,或许会有更大的收获。
目前绝大部分 Agent 无非就是一个 ReAct 循环,只不过将这个几十行代码的 ReAct 扩展成了若干万行代码,以满足不同的场景需求。Claude Code 当然也不例外,那为什么 Claude Code 能在众多 Agent(尤其是 Coding CLI 中)脱颖而出呢?
笔者对以下几个问题其实是十分好奇的:
- Claude Code 每次 LLM API 调用的 Prompt 是怎样的?
- Prompt 的组成 部分是怎样的?为什么是选择这些而不是别的?
- Prompt 有哪些撰写原则?我们能学到什么?
- Prompt 过长时,压缩机制是怎样的?
- Claude Code 的 ReAct 循环是怎样的?在 Receive-Action-Observe这个循环中,它做了哪些不一样的东西?
- Claude Code内置了哪些工具,以支撑它如此灵活地完成各种各样的任务?工具体系又是如何搭建的?
- Claude Code 在"写代码(修改文件)"的时候,究竟发生了什么?
当然还有很多很多其他的问题,比如权限系统、sub-agent 体系、UI 优化等。不过贪多嚼不烂,笔者目前对上述问题是比较感兴趣的,所以就让 Claude Code 对着它自己的源码,通过对这些问题层层展开,最后由笔者整理成本文。
注:本文尽力避免"万字长文",怎奈为使行文连贯,有些地方难免啰嗦。好在每章自成主题,可单独阅读,按需食用即可。
1. Claude Code 每一个 Prompt 是如何组织的
如上图所示,发给 Claude API 的最终请求结构其实很简单:
1 | { |
但构建这个请求的过程远不简单。整个 Prompt 的构建可以分为三个核心区域:
- System Prompt(系统提示)—— 告诉 Claude "你是谁、你该怎么做"
- Messages(消息列表)—— 包含用户输入、历史对话和各种附加上下文
- Tools(工具定义)—— Claude 可以调用的工具列表
1.1 System Prompt:Claude Code 的"灵魂"
System Prompt
是整个架构中最精心设计的部分。它分为静态部分和动态部分,两者之间由一个关键的边界标记
SYSTEM_PROMPT_DYNAMIC_BOUNDARY 分隔。

静态部分定义在 constants/prompts.ts 中,包含 7 个
Section,如图所示不再赘述。
这部分无论固定不变的。 ← 所以可以命中 KV Cache,提高响应速度的同时,减少 token 费用。
在静态和动态部分之间,有一段至关重要的文字:
"Codebase and user instructions are shown below. Be sure to adhere tothese instructions. IMPORTANT: These instructions OVERRIDE any defaultbehavior."
这段话的意义深远——它告诉
Claude,接下来的动态指令(包括用户的自定义规则)优先级高于默认行为。这就是为什么我们在
CLAUDE.md 中写的规则能够生效。
动态部分由 utils/cloudend.ts 生成,包含多达 8
个组件,如图所示不再赘述。
这里值得特别展开的是 CLAUDE.md 的加载。Claude Code 会从多个位置按照优先级依次查找并合并配置。这个设计非常优雅,它允许从企业级的全局规范到个人项目的特定偏好,形成一个完整的配置层级。越靠近当前工作目录的规则,优先级越高。
1.2 Messages:上下文的大拼图(附件系统)
Messages 是整个 Prompt 中最复杂的部分。一条看似简单的用户消息,在发送给 API 之前,会被附加大量的上下文信息,具体分为以下 2 个部分:
- User Message(用户输入):你在终端里实际打的字,比如 "帮我修改这个文件"
- Attachment Messages(本轮附加注入):系统自动生成的上下文信息
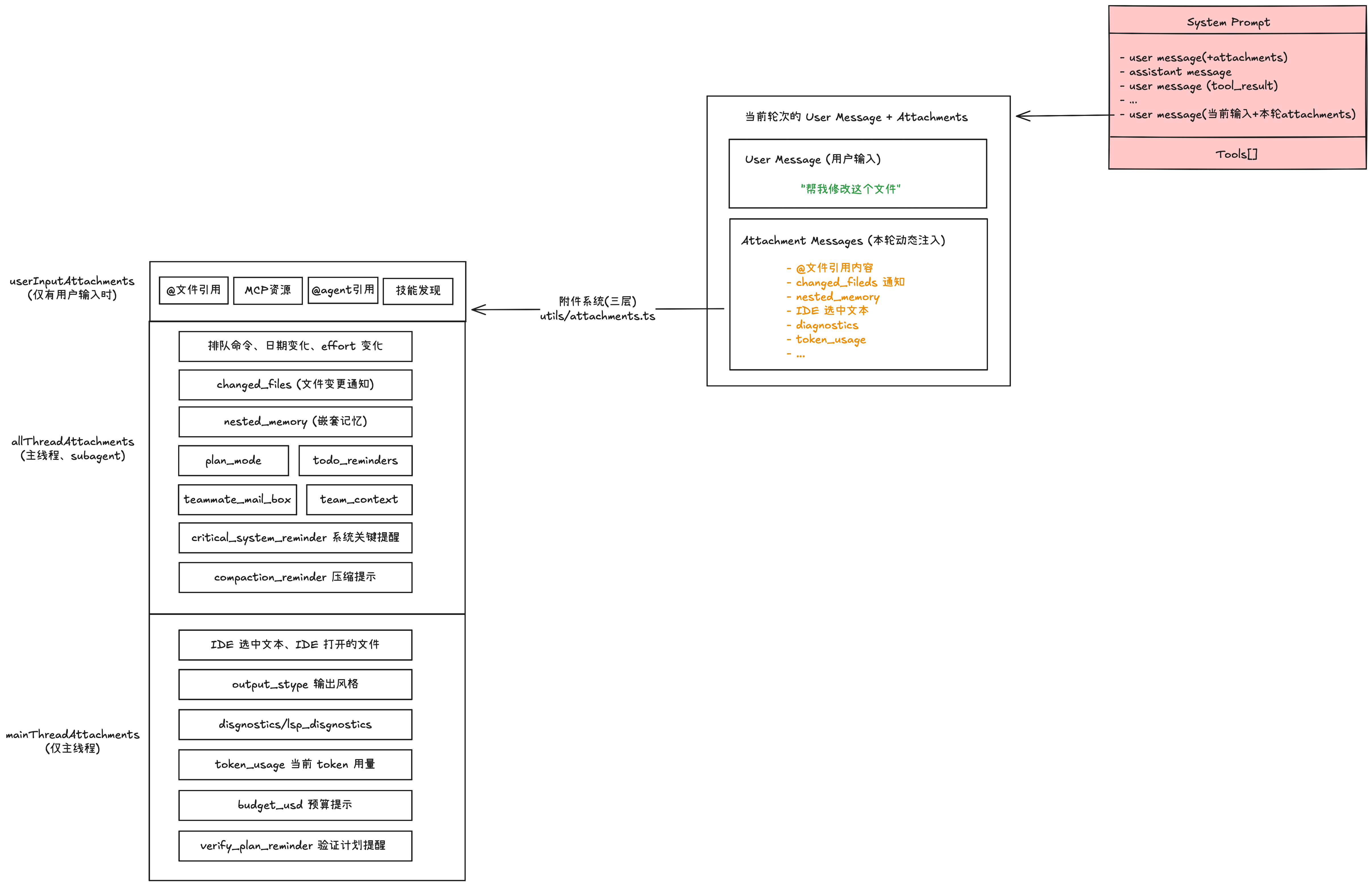
如上图所示,附件系统是 Claude Code 的核心设计之一,实现在
utils/attachments.ts 中(三层结构)。
这里要思考几个问题:
- 为什么需要附件系统?
- 附件为什么需要分层?
- 这么多的附件类型是一回事,关键是,为什么是它们?
- 这么多附件,每次注入的时候如何选择?
1.2.1 为什么需要附件系统?
先思考第 1 个问题,为什么需要附件系统?
模型不知道你刚在 IDE 里手动改了一行代码,不知道 linter自动格式化了文件,不知道长会话已经跨越了午夜。附件系统的工作,就是在每个turn 自动注入这些模型"应该知道但没法主动获取"的信息。
1.2.2 附件为什么要分层?
根据不同的触发条件,附件被分为三类:
| 层级 | 触发条件 | 包含什么 | 设计意图 |
|---|---|---|---|
| userInputAttachments | 仅用户有输入时 | @文件引用、@agent、MCP 资源、技能发现 | 响应用户的直接意图 |
| allThreadAttachments | 每轮都收集(含子 agent) | 文件变更、日期变化、记忆、plan、任务提醒 | 维护全局一致性 |
| mainThreadAttachments | 仅主线程 | IDE 选区、打开文件、诊断信息、token 用量 | 交互感知(子 agent 隔离) |
现在可以回答第 2 个问题:为什么要分层?
子 agent 被分配了"重构parser.ts"的子任务,它需要知道 parser.ts是否被外部修改了(changed_files,在 allThread层),但不需要知道用户在 IDE里选中了哪段代码(ide_selection,在 mainThread层)。信息按需分发,不是所有线程看到所有东西。
1.2.3 为什么是这些附件?
要解答第 3 个问题,我们可以将附件按照它们要解决的问题分类,这样能更好地理解设计意图。
类别 1:保持模型认知与现实世界同步
核心原则:模型的世界模型必须与真实状态保持同步。 每当外部状态变化,附件系统负责"通知"模型。注意这里的关键词是"delta"——很多附件名字里就带着"变化"的含义,因为它们只在状态改变时才注入。
| 附件 | 注入什么 | 解决什么问题 |
|---|---|---|
changed_files |
"foo.ts was modified. Here are the changes: ..." | 用户在 IDE 手动改了文件 / linter 自动格式化了文件 → 模型不知道 |
date_change |
"Today's date is now 2025-07-02. DO NOT mention this." | 长会话跨越午夜 → 模型的日期认知过期 |
nested_memory |
子目录的 CLAUDE.md 内容 | 模型进入新目录工作 → 不知道该目录的规则/约定 |
deferred_tools_delta |
"New tools available via ToolSearch: ..." | MCP server 连接/断开 → 工具集变了但模型不知道 |
agent_listing_delta |
"New agent types available: ..." | Agent 列表变化 → 模型可能调用已不存在的 agent |
mcp_instructions_delta |
MCP server 使用说明 | MCP server 连接后带来了使用说明 → 需要告知模型 |
类别 2:管理模型的"心理状态"
核心原则:LLM 不是无状态的——它会根据感知到的上下文压力改变行为。
compaction_reminder是一个典型案例。当对话历史很长时,模型会"感觉到"上下文窗口快满了,于是开始焦虑地赶进度——提前总结、跳过细节、催促用户做决定。这不是我们想要的行为。通过注入"你有无限上下文"这个安抚信息,Claude Code 在管理模型的"情绪"。
| 附件 | 注入什么 | 解决什么问题 |
|---|---|---|
compaction_reminder |
"Auto-compact is enabled. There is no need to stop or rush — you have unlimited context." | 长对话中模型"感知"到 context 快满 → 表现出焦虑行为(提前总结、催促用户) |
context_efficiency |
引导模型使用 SnipTool 清理历史 | 对话膨胀 → 但模型不知道可以主动剪枝 |
ultrathink_effort |
"The user has requested reasoning effort level: max" | 用户切换了推理力度 → 模型需要调整行为 |
output_style |
输出风格配置 | 用户设置了特定输出风格 → 模型需遵守 |
类别 3:IDE 上下文感知
核心原则:把 IDE 当作模型的"眼睛"。 没有附件系统,模型是"盲人编程"——不知道用户在看什么、IDE 报了什么错。
| 附件 | 注入什么 | 解决什么问题 |
|---|---|---|
ide_selection |
"The user selected lines 10-20 from foo.ts: [代码]" | 用户在 IDE 选了代码然后提问 → 模型不知道用户在看什么 |
ide_opened_file |
"The user opened foo.ts in the IDE." | 用户切换了文件 tab → 模型不知道用户的注意力在哪 |
diagnostics |
TypeScript/ESLint 错误列表 | IDE 报了新的编译错误 → 模型不知道自己的修改引入了问题 |
类别 4:行为习惯培养
核心原则:用周期性提醒替代一次性指令。 System prompt 只在对话开头出现一次,但在长达数十轮的对话中,模型很容易"遗忘"早期的指令。附件系统通过周期性地重复提醒来对抗这种遗忘。
| 附件 | 注入什么 | 解决什么问题 |
|---|---|---|
todo_reminder / task_reminder |
"The task tools haven't been used recently... This is just a gentle reminder" | 模型在长任务中忘记维护任务列表 |
plan_mode |
Plan mode 的完整指令 | 模型在 plan 模式中忘记自己在做计划、开始直接执行代码 |
plan_mode_exit |
"You have exited plan mode. You can now make edits." | 模型从 plan 模式退出但不知道自己已有权限执行操作 |
verify_plan_reminder |
"Please call VerifyPlanExecution tool" | 模型实施完计划后忘记验证 |
类别 5:资源感知与约束
核心原则:让模型具备"自我约束"的能力。 这里的设计选择非常有趣——Claude Code 不是在系统层面硬截断输出,而是让模型"知道"资源情况后自行调节行为。这是一种软约束,给了模型根据情况灵活应对的空间。
| 附件 | 注入什么 | 解决什么问题 |
|---|---|---|
token_usage |
"Token usage: 85000/200000; 115000 remaining" | 模型不知道自己用了多少 token,无法自我调节 |
budget_usd |
"USD budget: 2.50/2.50/5.00; $2.50 remaining" | 模型不知道花了多少钱,可能无节制调用工具 |
output_token_usage |
"Output tokens — turn: 2000/8000 · session: 15000" | 配合 token budget 功能,让模型知道输出进度 |
max_turns_reached |
"Maximum turns reached." | --max-turns 限制下通知模型该停止了 |
类别 6:知识注入
| 附件 | 注入什么 | 解决什么问题 |
|---|---|---|
relevant_memories |
从 auto-memory 目录中检索的相关记忆 | 模型不知道之前会话积累的经验/偏好 |
skill_listing |
当前可用的技能列表 | 模型不知道有哪些自定义技能可以调用 |
skill_discovery |
基于语义搜索的相关技能 | 模型可能不知道某个技能的存在 → 主动推荐 |
queued_command |
用户在工具执行中途输入的新消息 | Agent 循环中用户打了新消息 → 不能等到循环结束才看到 |
1.2.4 如何选择要注入的附件?
附件不是每轮都全量注入的——那样会快速耗尽上下文窗口。每种附件都有精心设计的触发条件、去重策略和生命周期管理:
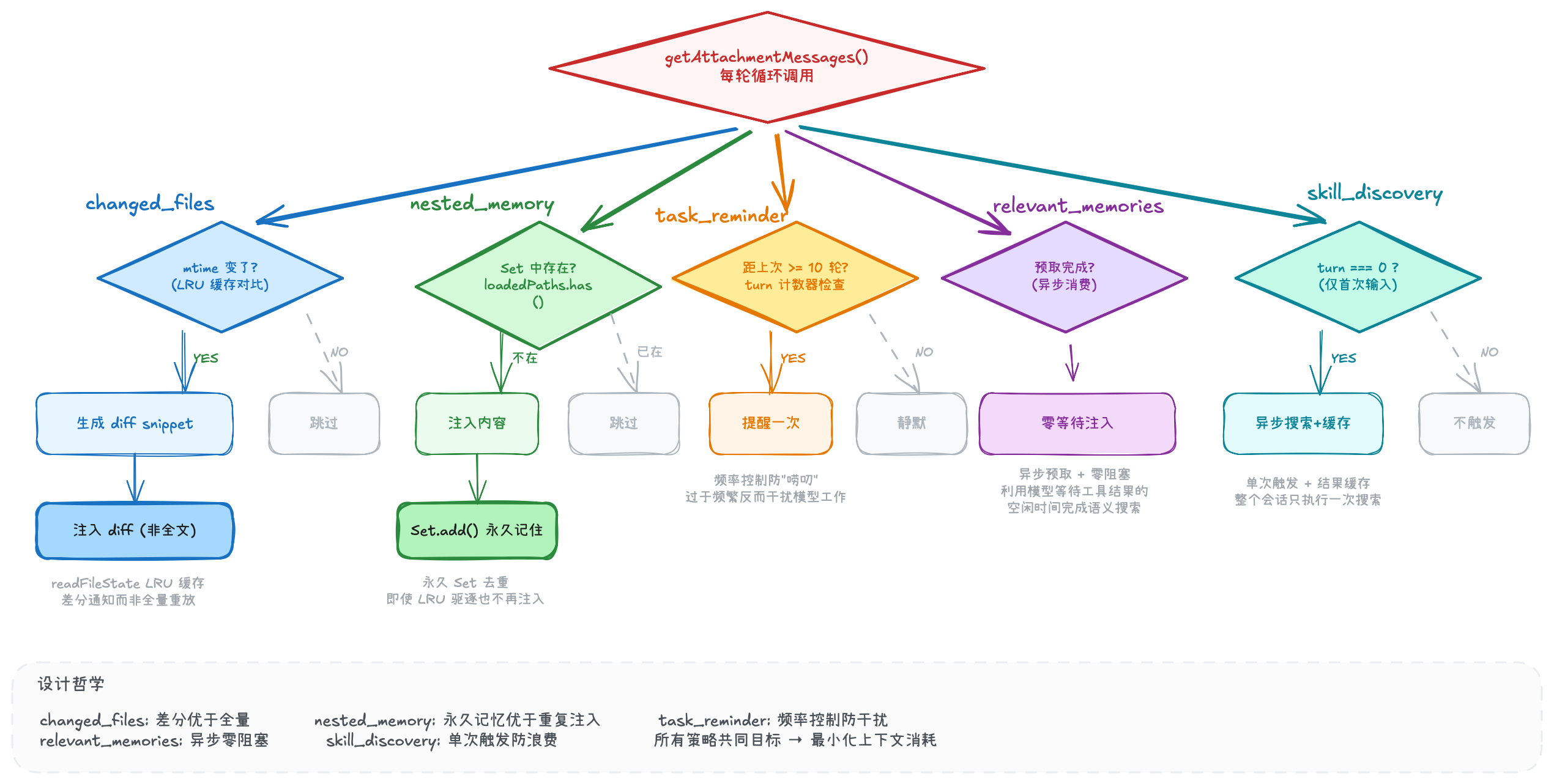
1.3 Tools:强大的工具体系
请见 🫱 4. Claude Code 的工具体系
2. Claude Code 的 Prompt 有哪些撰写原则
在知道了 Claude Code 每一个 Prompt 的组成部分之后,里面具体写了什么呢?有没有一些最佳实践是我们可以参考(抄)的呢?当然是有的,经对源码进行分析后,笔者(借助 AI)提取出了 Claude Code 在 Prompt Engineering 的 8 个最佳实践,可供参考。
一句话总结: Claude Code 的 prompt哲学是:不教模型"怎么做好",而是堵住模型"会做错"的所有口子;不用抽象规则,而用具体场景;不靠文字约束,而靠系统设计让错误行为无法发生。
2.1 行为塑造靠"反面清单",不靠"正面宣言"
传统做法是告诉 AI "你是一个优秀的程序员"。Claude Code 几乎不做正面描述,而是用大量具体的禁止行为来约束:
1 | "Don't add features, refactor code, or make 'improvements' beyond what was asked." |
LLM 天然倾向"过度工程化"和"讨好用户"。不写反面清单,模型会不断添加不必要的代码。这些禁令是从大量真实用户反馈中提炼出来的,每一条背后都是一个"模型做过头了"的真实场景。
写 prompt 时,先想"AI 最容易犯什么错",然后写对应的禁令。
2.2 用具体场景代替抽象规则
Claude Code 从不写"请谨慎操作"这样的空话,而是给出具体例子和边界条件:
1 | "Examples of the kind of risky actions that warrant user confirmation: |
又比如对 git 的操作:
1 | "A user approving an action (like a git push) once does NOT mean that they |
每条规则都用"例如..."或具体场景补充。让模型能类比推理到新场景。
2.3 面向失败模式设计,每条规则对治一个真实 BUG
读 prompts.ts 的注释能看到很多
@[MODEL LAUNCH]
标记,说明这些指令是针对特定模型版本的行为问题定制的:
1 | // @[MODEL LAUNCH]: capy v8 thoroughness counterweight (PR #24302) |
Prompt不是一次性写好的。应该持续监控模型行为,发现问题后添加对应的矫正指令。这是一个持续迭代的工程过程。
2.4 面向人类用户体验的输出控制
Claude Code 对输出格式的控制极其细致:
倒金字塔原则:
1
2
3
4
5
6
7"Lead with the answer or action, not the reasoning."
"Use inverted pyramid when appropriate (leading with the action), and if
something about your reasoning is so important that it absolutely must be
in user-facing text, save it for the end."
“先给出答案或行动方案,而非先阐述理由。”
“在适当的情况下采用倒金字塔结构(先讲行动方案),如果您的理由中有某些内容非常重要,必须出现在面向用户的文本中,那么就将其放在最后。”结构格式的克制:
1
2
3
4
5
6
7"Match responses to the task: a simple question gets a direct answer in prose,
not headers and numbered sections."
"Only use tables when appropriate; for example to hold short enumerable facts.
Don't pack explanatory reasoning into table cells."
“将回答与任务内容相匹配:简单的问题应给出明确的散文式回答,而非使用标题和编号列表形式。”
“仅在适当的情况下使用表格;例如用于展示简短的可列举事实。切勿将解释性推理内容塞进表格单元格中。”用户注意力管理:
1
2
3
4
5
6
7
8
9
10
11
12"Focus text output on:
- Decisions that need the user's input
- High-level status updates at natural milestones
- Errors or blockers that change the plan"
"If you can say it in one sentence, don't use three."
“将文本输出的重点放在以下方面:
- 需要用户参与的决策事项
- 在自然的阶段性节点上呈现的高级状态更新
- 会改变计划的错误或阻碍因素”
“如果能用一句话表达清楚就不要用三句话。”防止语义回溯:
1
2
3
4"Avoid semantic backtracking: structure each sentence so a person can read it
linearly, building up meaning without having to re-parse what came before."
“避免语义回溯:将每个句子进行结构设计,以便读者能够按线性顺序阅读,从而逐步构建出意义,而无需反复解析之前的内容。”
不只管"模型说什么",还管"模型怎么说"。输出质量 = 信息量 /认知负荷。
2.5 用隐式约束
最巧妙的是通过工具系统设计而非 prompt 文字来约束行为:
工具描述中(getEditToolDescription):
1 | "You MUST use your Read tool at least once before editing." |
工具可用性控制:
1 | - Glob/Grep 存在 → prompt 告诉模型 "Use Glob instead of find" |
最好的 prompt 是让错误行为根本无法执行,而不是"请不要这样做"。
2.6 预设用户的"走开"场景
Claude Code 假设用户不会一直盯着屏幕:
1 | "When making updates, assume the person has stepped away and lost the thread. |
Agent的输出应该是自包含的进度报告,不是需要"回看上文"才能理解的日志。
2.7 精确的权限边界语言
安全相关的 prompt 使用了极其精确的法律式语言:
1 | "Authorization stands for the scope specified, not beyond." |
安全领域:
1 | "Assist with authorized security testing, defensive security, CTF challenges, |
安全指令要像法律条文——穷举允许项和禁止项,不留模糊地带。
2.8 优秀的工程管理
| 实践 | 做法 | 为什么 |
|---|---|---|
| 分节管理 | 每个 section 独立函数,条件加载 | 可缓存、可 A/B 测试 |
| 静态/动态分离 | SYSTEM_PROMPT_DYNAMIC_BOUNDARY | prompt cache 命中率 |
| 变量引用工具名 | ${FILE_EDIT_TOOL_NAME} 而非硬编码 |
工具重命名时 prompt 自动更新 |
| 条件裁剪 | enabledTools.has(...) 检查后才加入 |
不存在的工具不出现在 prompt 中 |
| 模型版本适配 | @[MODEL LAUNCH] 标记 |
不同模型有不同行为矫正 |
| 内外有别 | process.env.USER_TYPE === 'ant' |
内部版本有更详细的指令 |
| 迭代注释 | 每条规则旁标注 PR 编号 | 可追溯为什么加这条规则 |
3. Claude Code 的 ReAct 循环剖析
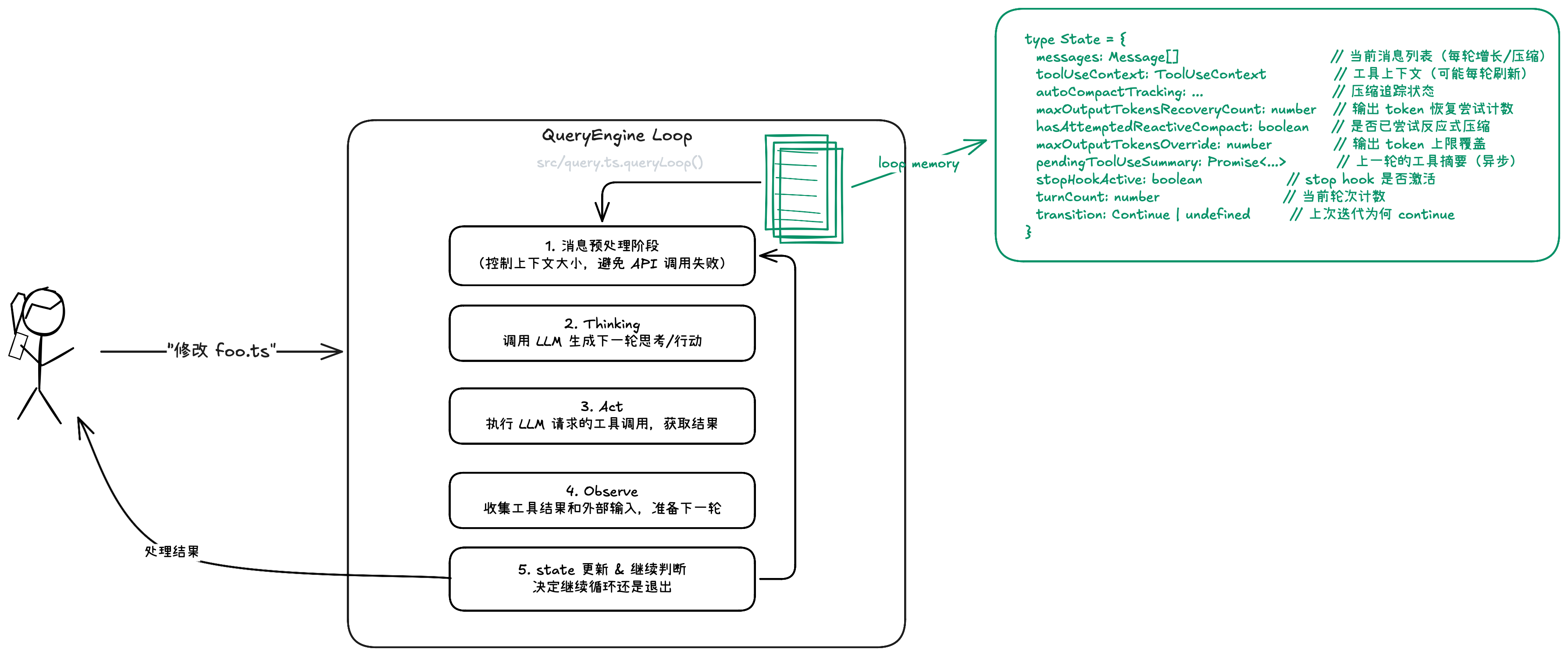
如上图所示,这是一个经典的 ReAct 循环,事实上绝大部分的 Agent 都是一个 ReAct 循环。关键在于,Claude Code 是如何把一个几十行代码的 ReAct 循环硬生生整出超过 51w 行代码的?或者说,为啥要这样?这可能就是最近比较火的 Harness Engineering 了吧。
接下来让我们从上图这 5 个阶段来一一拆解。
3.1 消息预处理阶段

这里 Claude Code 在压缩(compact)Prompt 的处理,是值的我们学习的。谈到压缩,我们一般能想到的就是滑动窗口,丢失掉旧的数据,这个时候我们会怕关键信息丢失,所以自然就想到了调另外一个 LLM 来做 summarize,一般也就到此为止了。
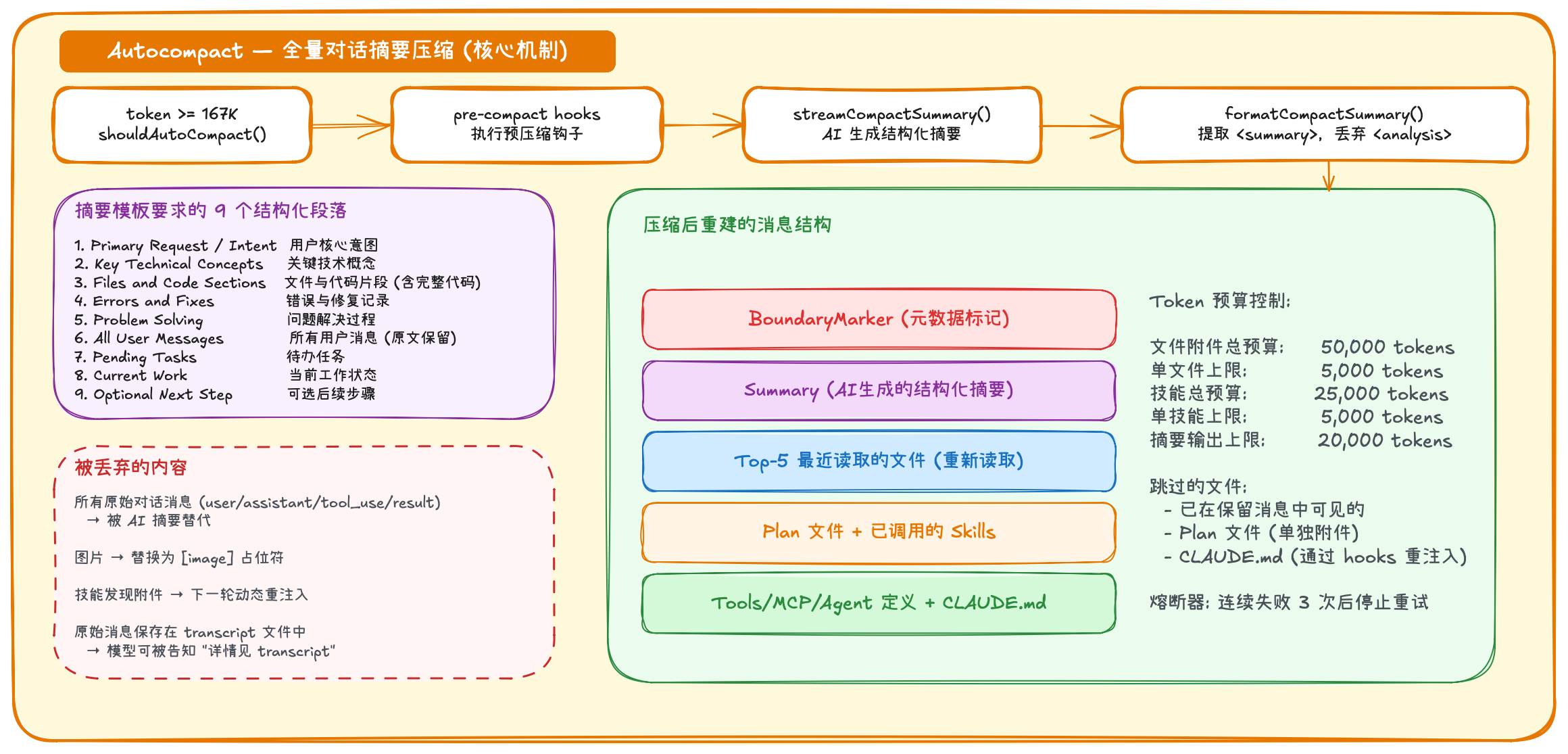
而 Claude Code 的压缩并不是一个简单的"满了就摘要"的操作,而是一套从轻到重的五级渐进式降级策略。这五级从轻到重依次执行,每一级解决一个特定的膨胀来源,设计思想是能不动就不动,能少压就少压。
| 级别 | 信息损失 | 计算成本 | 可逆性 |
|---|---|---|---|
| 1. 工具结果预算 | 极低(只截断超大输出) | 无 LLM 调用 | 否 |
| 2. 历史剪裁 | 低(丢弃远古对话) | 无 LLM 调用 | 否 |
| 3. 微压缩 | 低(标记跳过) | 无 LLM 调用 | 是 |
| 4. 上下文折叠 | 中(摘要但可展开) | 无 LLM 调用 | 是 |
| 5. Autocompact | 高(整段历史压成摘要) | 需要 LLM 调用 | 否 |
每一级都只在前一级不够用时才启动。大部分对话只会触发前三级,只有真正的超长会话才会走到 Autocompact。这既节省了 LLM 调用成本,也最大限度地保留了对话上下文的完整性。
当然,其中最具挑战、最容易造成信息损失的,还是 Autocompact。在让 LLM 进行 summarize 的时候,我们需要思考以下几个问题:
- 什么时候触发 Autocompact?
- 提示词是怎样的?(要留哪些东西?舍弃哪些东西?)
- summarize 后仍然超长怎么办?
3.1.1 什么时候触发压缩?

3.1.2 压缩的提示词是什么?
获取压缩 prompt 的代码如下:
1 | export function getCompactPrompt(customInstructions?: string): string { |
说白了,就是三个部分:
- NO_TOOLS_PREAMBLE:告诉模型不要调用工具,直接输出文本
- BASE_COMPACT_PROMPT:告诉模型压缩的时候要保留什么东西
- NO_TOOLS_TRAILER:再次强调模型不要调用工具,直接输出文本
1 | const NO_TOOLS_PREAMBLE = `CRITICAL: Respond with TEXT ONLY. Do NOT call any tools. |
3.1.3 压缩后还超长怎么办?
摘要不够短就砍掉更多历史再摘要,直到低于阈值。渐进式截断而非一次性丢弃,尽可能多保留信息。
1 | export async function compactConversation(...) ... { |
3.1.4 Autocompact 总结
3.2 Thinking 阶段:调用 LLM 生成下一轮思考/行动
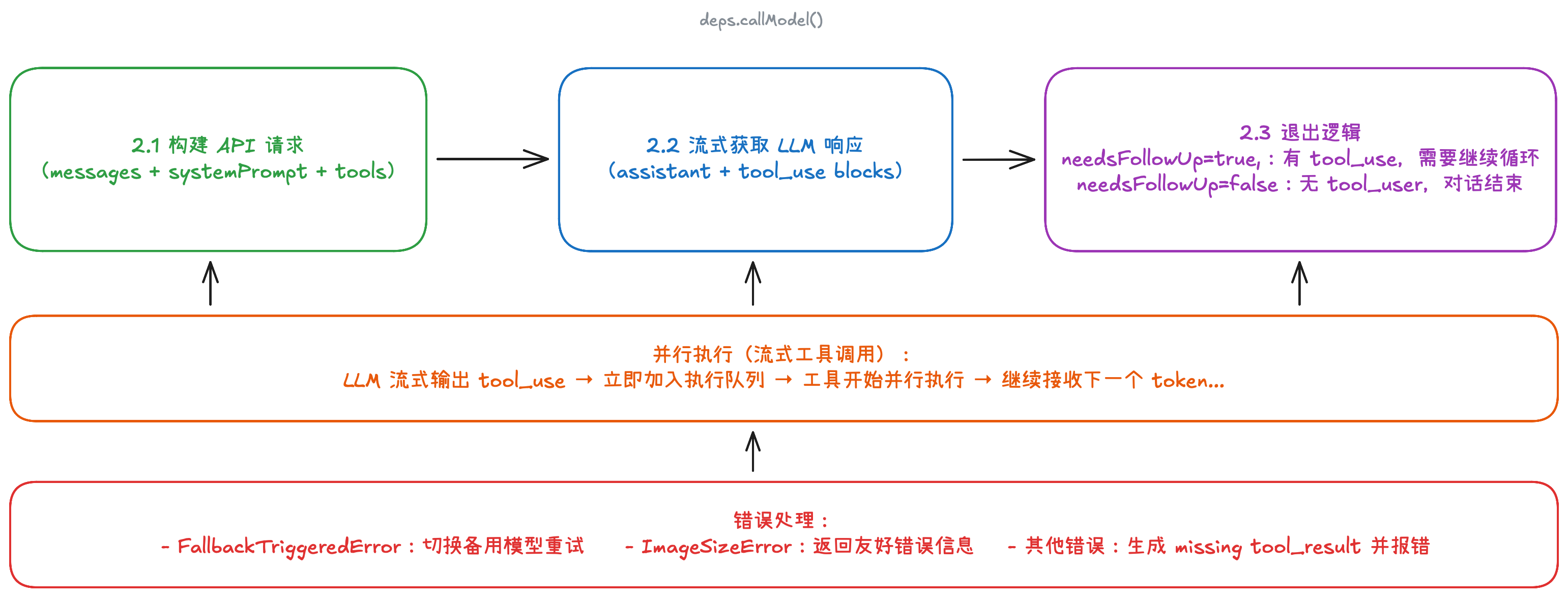
3.3 Act 阶段:执行 LLM 请求的工具调用,获取结果

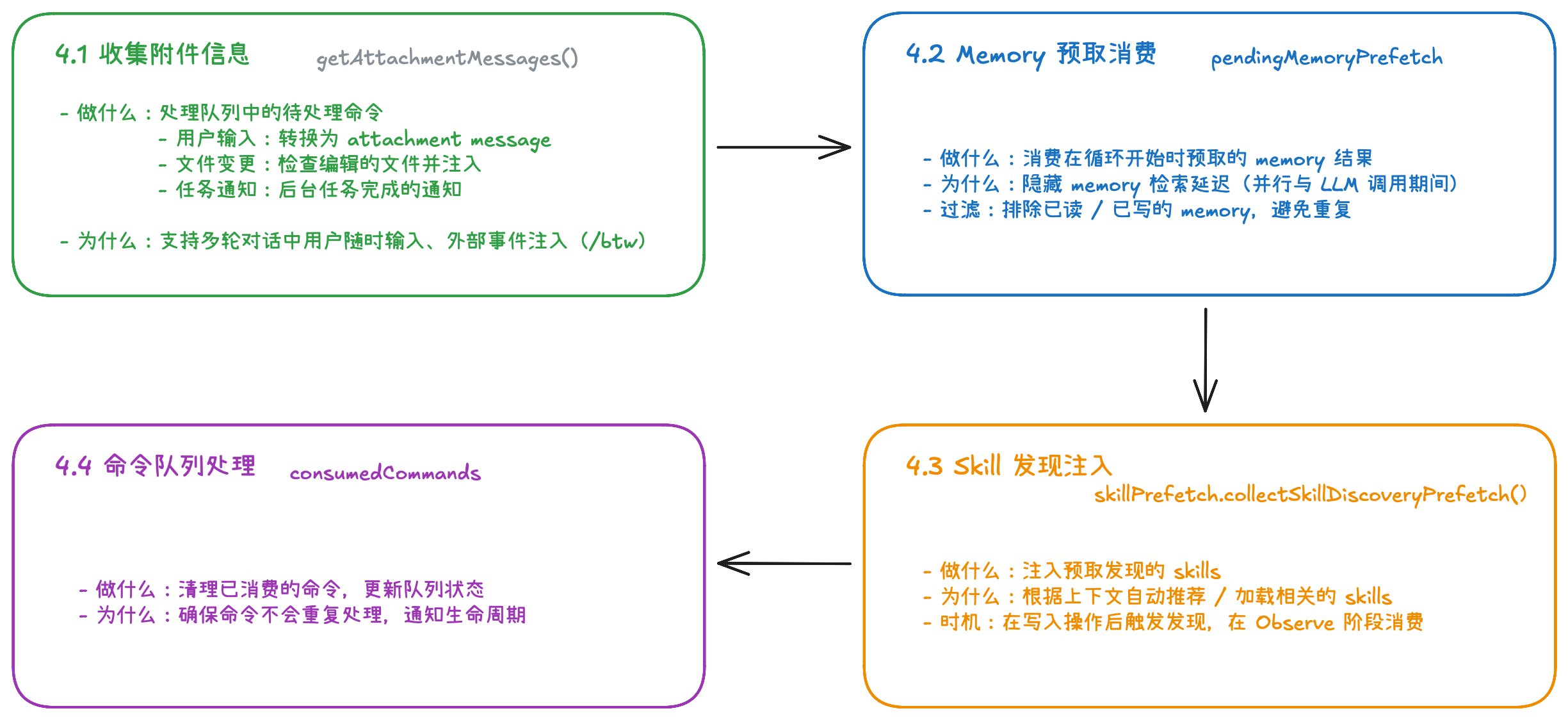
3.4 Observe 阶段:收集工具结果和外部输入,准备下一轮
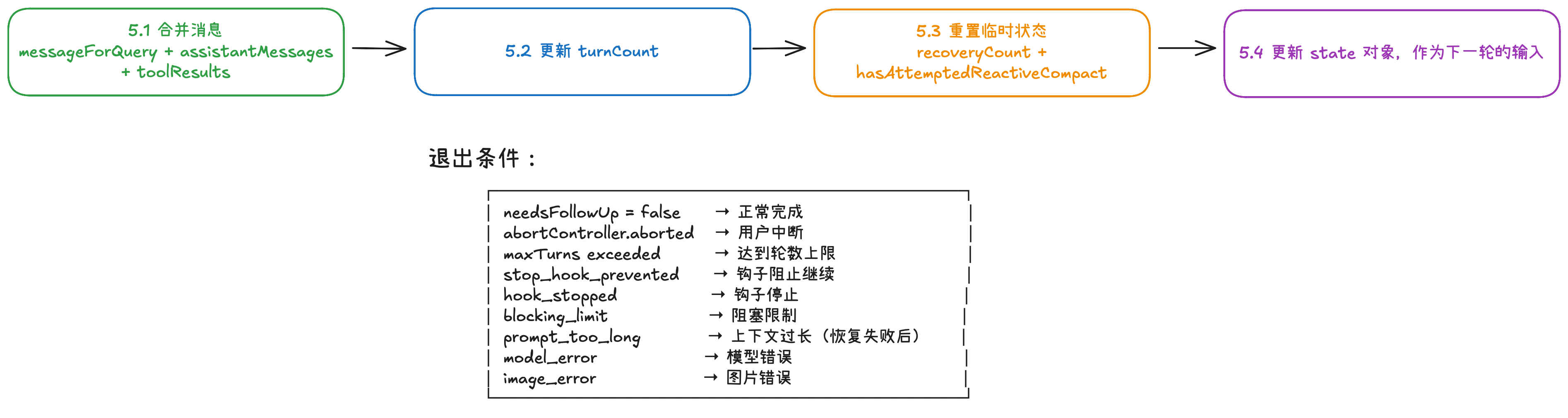
3.5 状态更新 & 继续判断:决定是继续循环还是退出
3.6 我们能学到什么?
了解了上述 5 个阶段后,我们能学习什么?这里笔者像转变一下视角:
不是 Claude Code 设计了什么,而是工业级 Agent 必须具备什么?ClaudeCode 又是怎么满足的?
笔者认为可以考虑以下几个硬性需求:
| 硬性需求 | 主要矛盾 |
|---|---|
| 状态清晰可管理 | 状态必然复杂 vs 复杂产生 bug |
| 长时间运行 | 无限任务 vs 有限上下文窗口 |
| 高响应性 | 多步操作的串行延迟 vs 用户的耐心 |
| 容错性高 | 错误必然发生 vs Agent 不能轻易死掉 |
| 可扩展 | 循环逻辑要稳定 vs 行为要不断变化 |
| 可观测 | Agent 思考过程是盲盒 vs 调试和改进的需要 |
4. Claude Code 的工具体系
4.1 架构全景
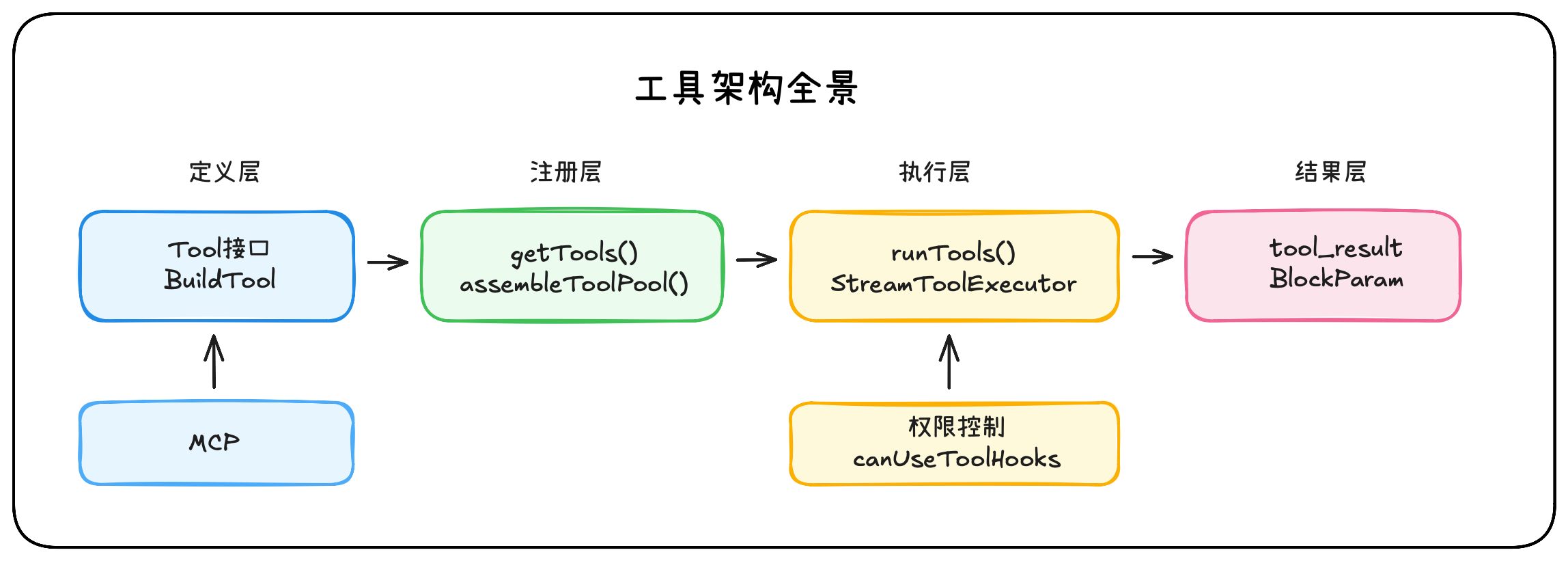
4.2 工具总览

4.3 工具接口
1 | type Tool<Input, Output, P> = { |
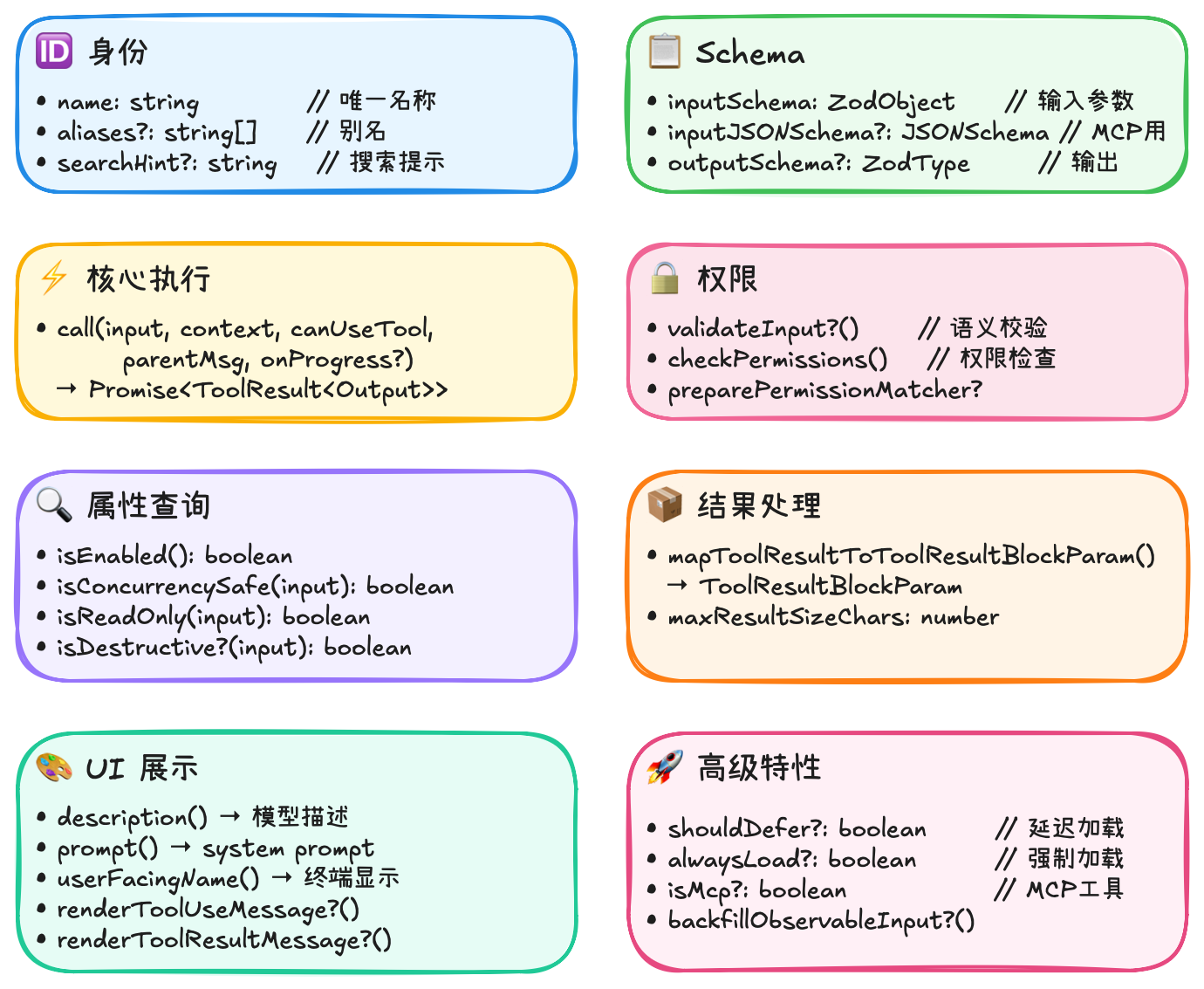
提供安全的默认值(fail-closed 原则):
| 默认 | 值 | 理由 |
|---|---|---|
| isEnabled | true | 默认启用 |
| isConcurrencySafe | false | 假设不安全(保守) |
| isReadOnly | false | 假设有写操作 |
| isDestructive | false | 默认不破坏性 |
| checkPermissions | allow | 交给通用权限系统 |
4.4 工具工厂
1 | buildTool() —— 工具工厂 (Tool.ts:783) |
4.5 GlobTool 为例
1 | src/tools/GlobTool/ |
完整实现如下:
1 | export const GlobTool = buildTool({ |
4.6 工具注册
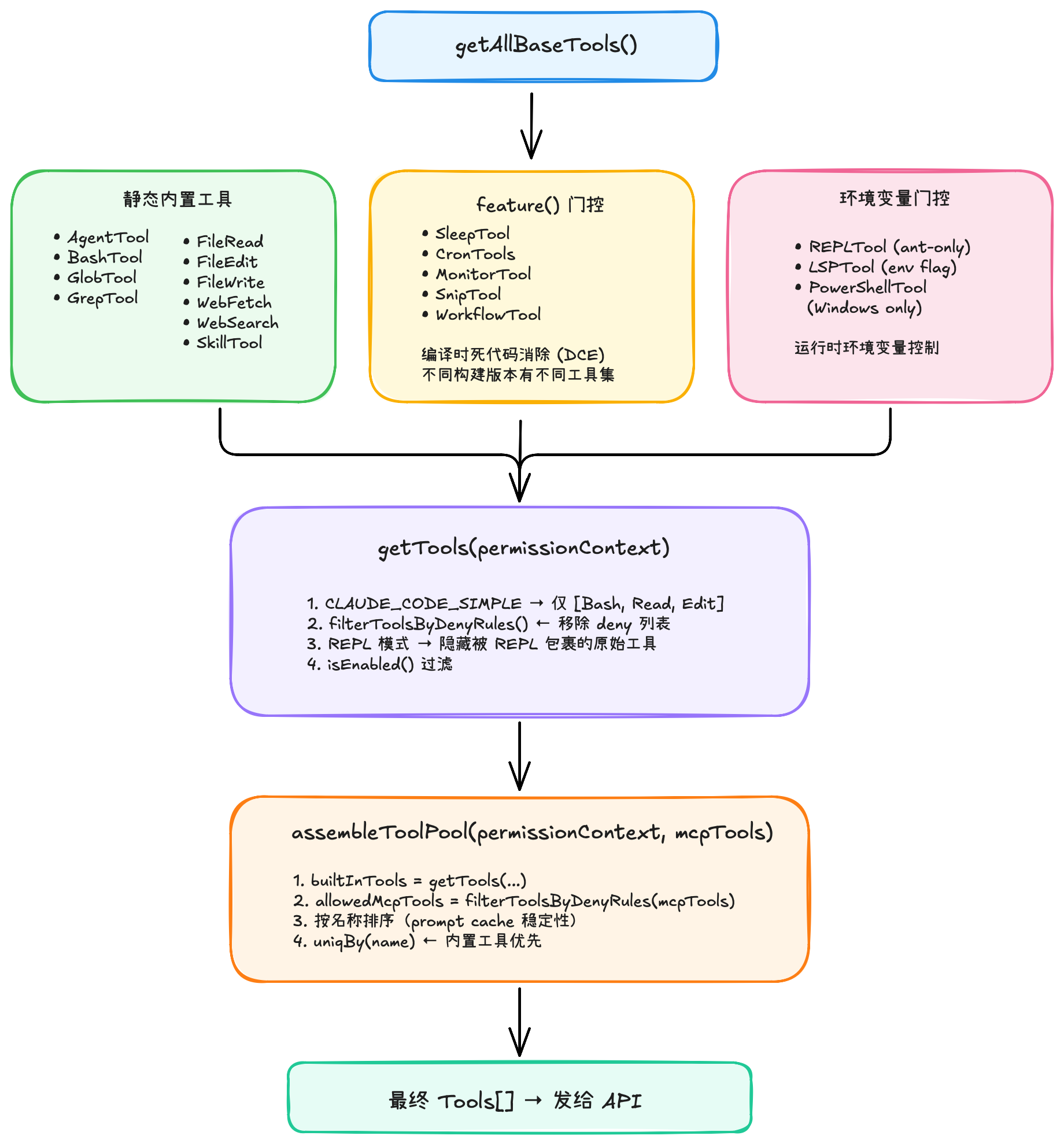
💡 关键设计原则:
feature()门控在编译时做死代码消除(DCE),不同构建版本有不同工具集。- 工具排序保证 prompt cache 命中率——内置工具始终是
contiguous prefix。 uniqBy('name')确保内置工具与 MCP 同名工具不冲突。
4.7 MCP 集成

MCP 工具的特殊之处:
- 使用
inputJSONSchema而非 Zod schema(直接传递 JSON Schema 给 API) - 命名格式
mcp__<server>__<tool>,支持 anthropic/alwaysLoad 元标记 checkPermissions返回passthrough,交给通用权限系统处理- 支持
URL elicitation重试(OAuth 等认证流)
4.8 工具执行
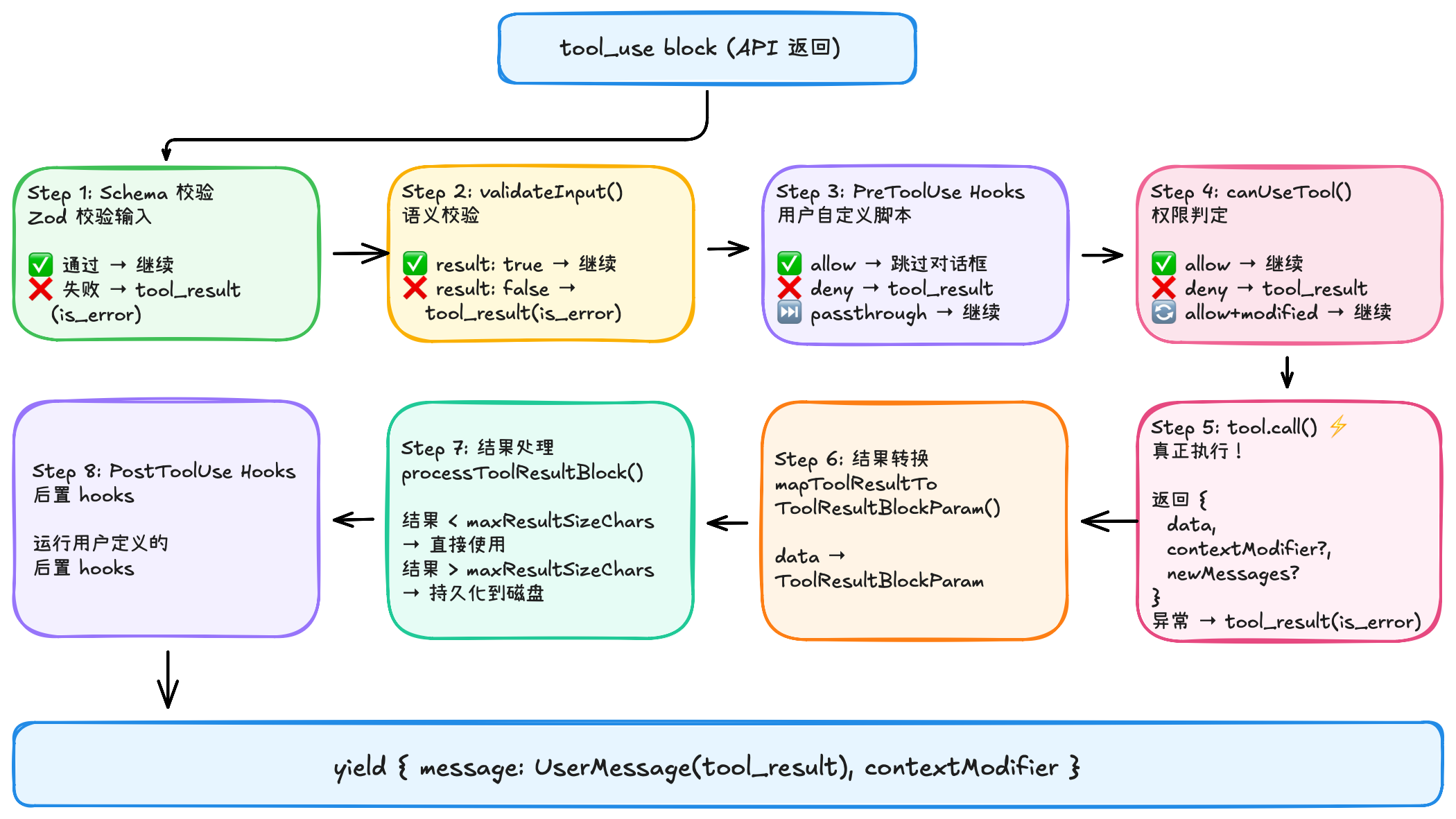
4.9 权限控制
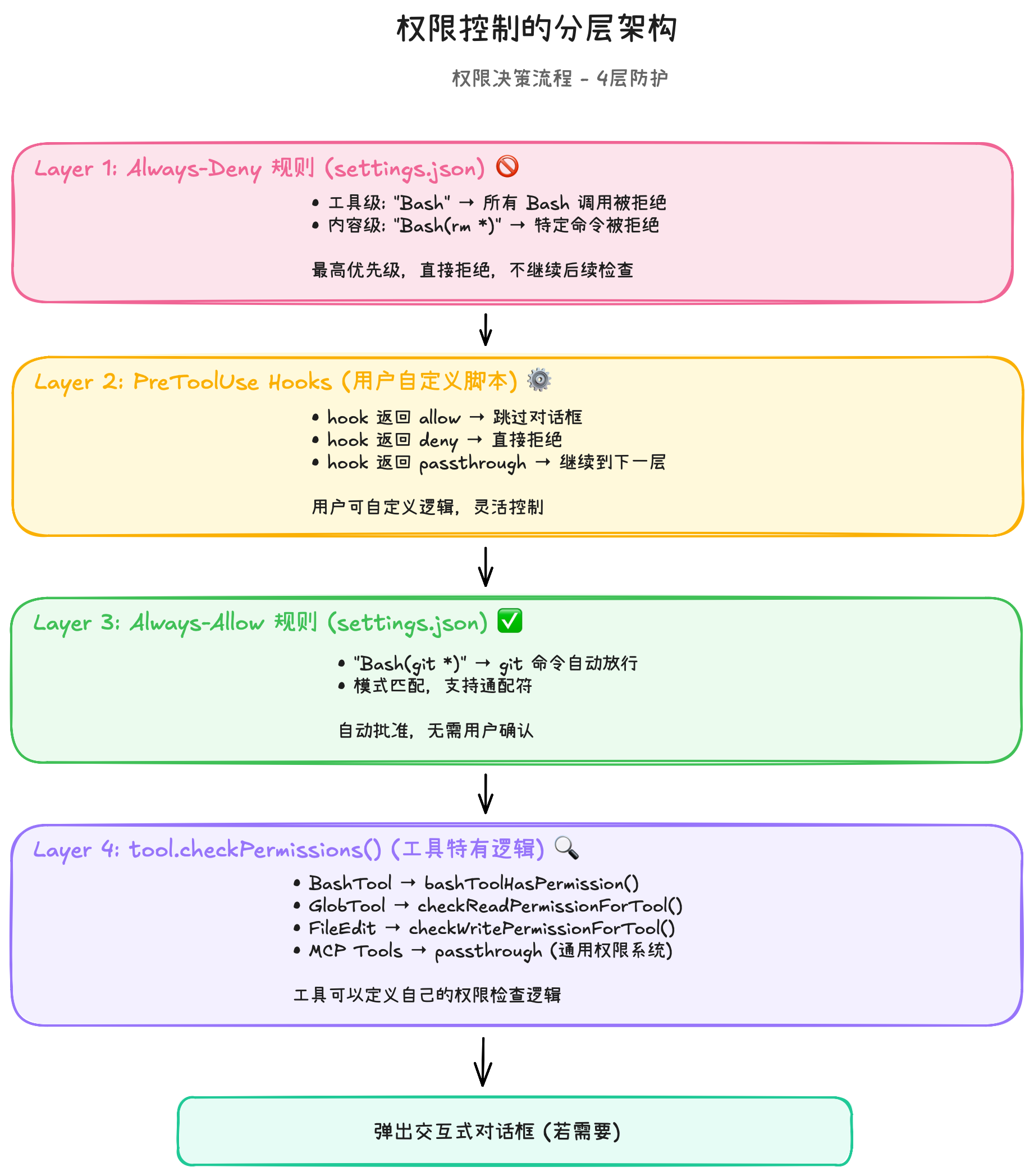
5. Claude Code 是如何修改代码的
在对 Claude Code 的上下文管理、ReAct 循环、Harness Engineering 和工具体系有了一个基本的了解之后,笔者身为程序员,自然最关心的就是"修改代码"这件事情了,所以本节我们就落到这个具体的需求点上,来探讨一下 Claude Code 在做修改代码这件事情的时候,到底做了什么。
当面对这个问题的时候,笔者心中又衍生了几个小问题:
- 修改代码这个行为是怎么完成的?
- 如何确保修改的精确性?
- 如何确保修改的全面性?
- 如何确保修改的安全性?(并发冲突...)
- 如何确保修改的语法正确性?
- 如何确保修改的功能正确性?
- 修改后整个上下文管理发生了什么?
好的,让我们一一解答。(废了,我不想要"万字长文"的 🤷🏻♀️🤡😷)
5.1 修改代码这个行为是怎么完成的?
Claude Code 修改文件有两个工具:
| 工具 | 用途 | 输入 | 何时使用 |
|---|---|---|---|
| FileEditTool | 精确替换文件中的一段文本 | file_path, old_string,
new_string, replace_all |
修改现有文件(首选) |
| FileWriteTool | 全量写入文件 | file_path, content |
创建新文件 / 完全重写 |
System prompt 引导模型优先使用 Edit——修改 500 行文件中的 1 行,Edit 只需发送 ~10 行 token,Write 则需发送全部 500 行。
1 | "ALWAYS prefer editing existing files. NEVER write new files unless explicitly required." |
举个例子:
1 | 输入: |
为什么选这个方案? —— 因为它匹配 LLM 的能力特征:
| 方案 | LLM 需要做什么 | 容易出错的点 |
|---|---|---|
| 行号定位 | 记住精确行号 | 行号幻觉(第 15 行记成第 13 行) |
| Unified diff | 生成 @@ -15,3 +15,4 @@ |
格式/行号双重出错 |
| AST 操作 | 理解语法树节点 | 每种语言不同,复杂度高 |
| 全文重写 | 输出整个文件 | 不出错,但 500 行改 1 行 = 浪费 499 行 token |
| 字符串替换 | 复制原文 + 输出修改后的版本 | LLM 最擅长这个 |
5.2 如何确保修改的精确性?
核心问题:模型给出的old_string,能不能准确定位到文件中的正确位置?
5.2.1 唯一性校验 - 不允许歧义
默认 replace_all = false,要求 old_string
在文件中只出现一次:
1 | // 匹配 3 次 → 拒绝 |
这个设计迫使模型提供足够的上下文行来唯一定位修改点。模型不能只写
return false(可能出现多次),必须包含上下行直到唯一。
5.2.2 先读后写 - 禁止盲改
1 | const readTimestamp = toolUseContext.readFileState.get(fullFilePath) |
模型必须先用 FileReadTool 读过文件。这确保
old_string
是基于当前真实内容构造的,而不是基于训练数据中的"记忆"。
5.2.3 编码和换行符保留 - 不引入格式噪音
1 | 读取时: 检测编码(UTF-8/UTF-16LE) + 换行符(LF/CRLF) → 记录 |
不保留的后果:Windows 项目 CRLF 文件被转成 LF → git diff 爆炸,每行都显示被修改。
5.3 如何确保修改的全面性?
核心问题:如果需要改多处,怎么保证不遗漏?
5.3.1 replace_all 模式
一个 Edit 调用 + replace_all: true
可以一次替换文件中所有匹配——适用于变量重命名等场景。
5.3.2 对话循环驱动多文件修改
Claude Code 的修改不是一次性的,而是对话循环驱动的多轮工具调用:
1 | 模型: "我需要修改 3 个文件" |
模型可以在一轮中发出多个 Edit 调用,并行执行(Glob/Grep/Read 是
concurrency_safe,可并行;Edit 是非 safe,串行执行)。
5.3.3 Agent 并行修改
主线程可以 spawn 子 Agent 并行处理不同文件/模块:
1 | 主 Agent: "重构 auth 模块" |
5.3.4 附件系统的"变更感知"
每轮工具执行完成后,changed_files
附件会检测哪些文件被外部修改(linter、format-on-save
等),注入 diff snippet 告知模型:
1 | "Note: auth.ts was modified, either by the user or by a linter. |
模型看到这些变更后可以决定是否需要追加修改——确保不遗漏 linter 引入的变化。
5.4 如何确保修改的安全性?
核心问题:并发冲突、外部修改、误操作如何防范?
| 防线 | 机制 | 一句话 |
|---|---|---|
| Staleness 双重检查 | validateInput + call 各检查一次 mtime | 被别人改过的文件不准覆盖 |
| 原子性写入 | 同步读 + 同步写,无 await 间隙 | 并发竞争不能破坏文件 |
| 权限控制 | deny 规则 → hooks → allow 规则 → 交互确认 | 用户不同意不准改 |
| UNC 路径防护 | 跳过 \\server\share 的文件系统操作 |
防止 NTLM credential 泄露 |
| 文件备份 | Edit 前按 content hash 创建 v1 备份 | 可撤销 AI 的修改 |
5.5 如何确保修改的语法正确性?
核心问题:替换完成后,文件的语法是否仍然合法?
5.5.1 Claude Code 当前策略:事后检测而非事前校验
FileEditTool 本身不做任何语法检查——它是语言无关的纯文本替换。语法正确性由两个机制保障:
- LSP
实时诊断(事后检测):如果编辑引入了语法错误,LSP
会产生诊断信息(error/warning),通过
diagnostics附件在下一轮注入到模型上下文,模型看到诊断后会自行修复。 - 模型自身的代码理解能力:模型在生成
new_string时已经考虑了语法——它不是随机替换,而是理解代码结构后生成的。先读后写强制确保模型看过完整文件,有足够的上下文生成语法正确的代码。
5.5.2 工程建议:借鉴强类型语言的编译时保障
当前的"事后检测"模式存在缺陷:先写入错误代码 → LSP 报错 → 模型再修 → 又一轮 API 调用。每次修复循环至少浪费一轮 token。更好的思路是写入前校验。
这个时候,静态强类型语言的编译器(如 TypeScript 和 Rust),就可以发挥巨大的作用。
5.6 如何确保修改的功能正确性?
核心问题:语法对了,但逻辑是否正确?功能是否如预期?
这不是单个工具能解决的问题。我们可以通过三道防线构建功能正确性保障:
- Prompt 引导自验证
- TDD 驱动的验证循环
- 独立于执行者的外部校验
5.6.1 第一道防线:Prompt 引导自验证
Claude Code 的 System prompt 中存在以下关键指令:
1 | "Before reporting a task complete, verify it actually works: |
这些不是建议,而是行为纠偏指令——专门针对模型"虚报成功"的倾向。
5.6.2 第二道防线:TDD 驱动的验证循环
Claude Code 的对话循环天然支持 红-绿-重构 的 TDD 工作流:
1 | 理想流程(TDD 先行): |
即使模型不主动做 TDD,现有测试也充当安全网:
1 | 实际常见流程: |
TDD 思维对 AI Coding 的特殊价值:
| 传统 TDD 价值 | 在 AI Coding 中的放大效果 |
|---|---|
| 测试即需求文档 | 模型从测试中理解预期行为比读注释更精确 |
| 红绿循环提供反馈 | 模型的自验证有了客观标准,不靠自我评估 |
| 防止回归 | 模型改了 A 功能,测试发现 B 功能被破坏 → 立即修复 |
| 增量确信 | 每个小修改都有测试兜底,模型可以大胆重构 |
当没有测试时——这是最危险的场景。Claude Code 的
prompt 要求模型明确说 "I can't verify"
而不是假装成功。但更好的做法是:模型主动为修改的代码补充测试。这可以通过
CLAUDE.md 中的项目级指令强化:
1 | # CLAUDE.md |
5.6.3 第三道防线:独立于执行者的外部校验
- 权限对话框——写入前的代码审查窗口:每次写操作前弹出确认对话框(未明确授权时)。
- 极简返回值——迫使模型主动自验证:Edit 成功只返回
"file updated successfully",不附带修改后的文件内容。这与前面的 LSP 诊断形成配合——LSP 诊断是异步注入的(下一轮才能看到),在此之前模型没有任何"修改是否正确"的直接信号。极简返回值切断了"看到结果就以为改对了"的捷径:模型必须主动Read重新检查,或Bash运行测试来确认修改生效,而不是假设成功。 - 独立 Agent 的异步复查:内置的 Verification Agent 在后台异步运行,专门负责复查代码变更。它被刻意限制为只读模式——只能使用 Read、Glob、Grep、Bash,不能调用任何写工具。
5.7 修改后整个上下文管理发生了什么?
核心目标:让模型在每一轮都拥有与真实世界一致的认知。
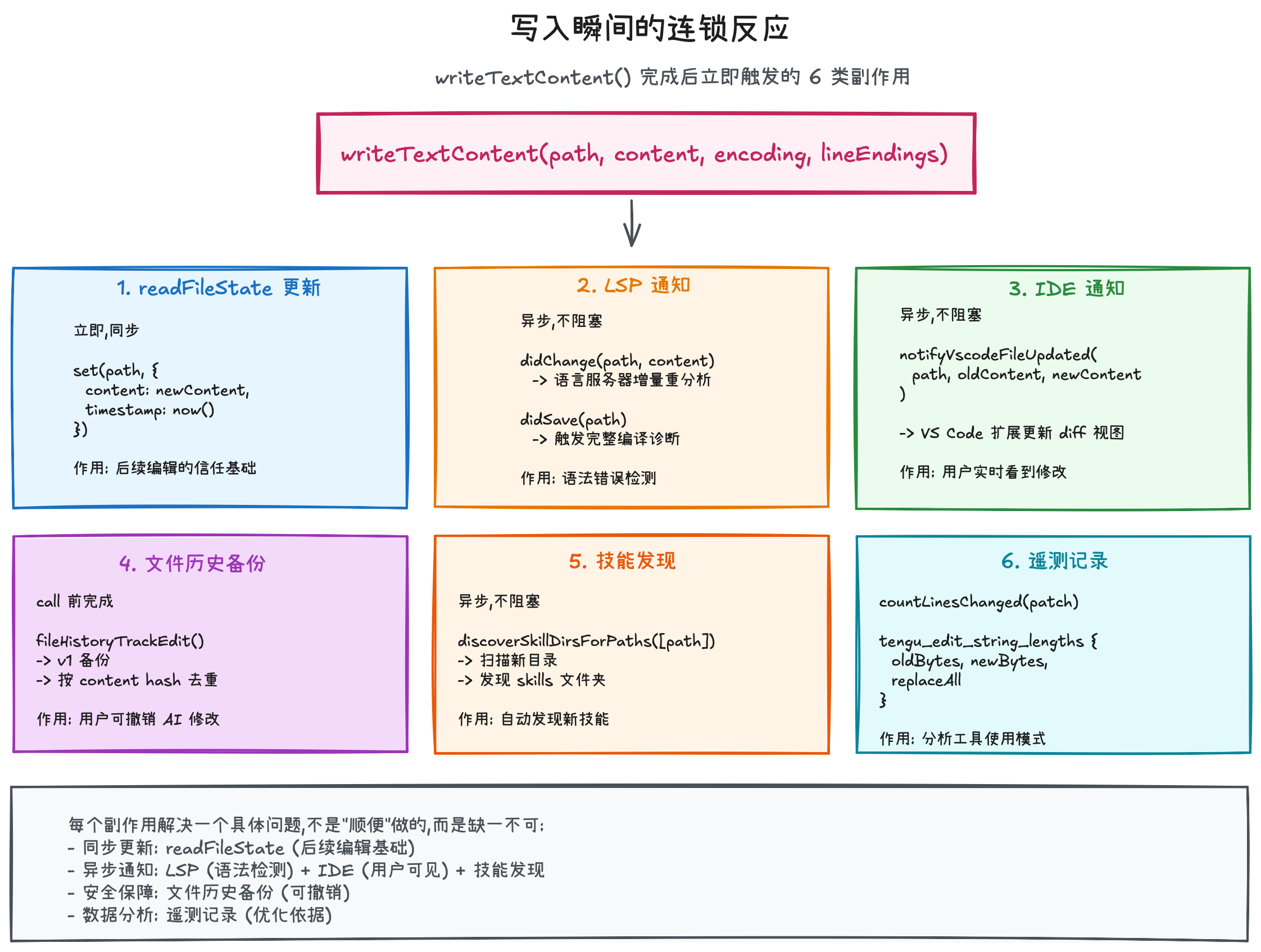
整体状态(state)的迁移图如下:
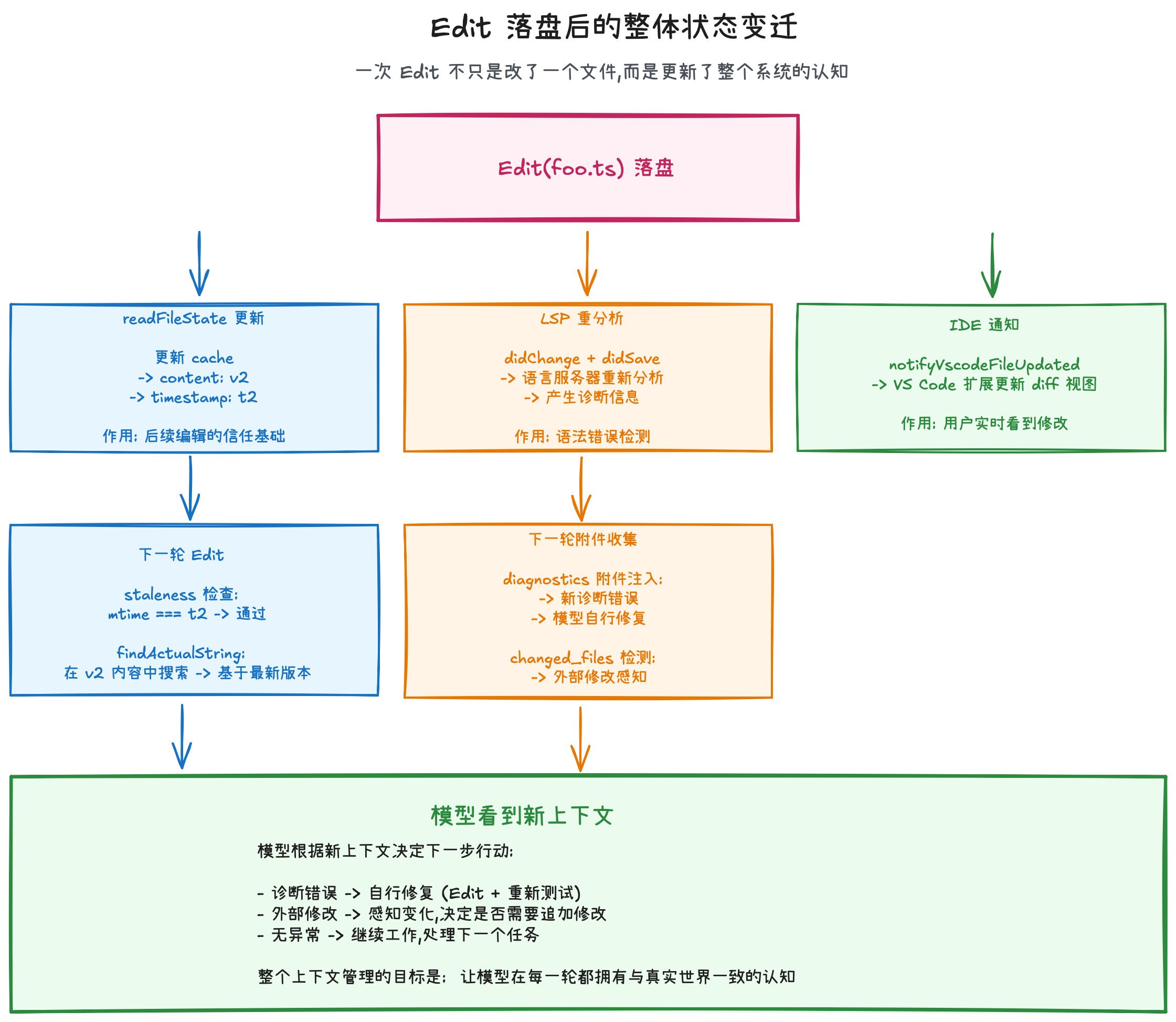
一次 Edit 不只是"改了一个文件"——它更新了系统的文件认知(readFileState)、触发了语言服务器重分析(LSP)、通知了用户的 IDE(VSCode)、创建了可撤销的备份(fileHistory),并在下一轮对话中通过附件系统将所有变化反馈给模型。整个上下文管理的目标是:让模型在每一轮都拥有与真实世界一致的认知。
5.8 串一下整个流程
一个完整的代码修改流程如下所示:
1 | 模型发出 Edit tool_use |
6. 写在最后
Claude Code 的"开源",给了我们一个难得的机会,去理解一个工业级 AI Agent 的真实复杂度。它不是一个"更大的 demo",而是一个充分考虑了边界情况、失败模式、用户体验的工程系统。
但更重要的是,这些设计原则是可迁移的。无论你在构建 Coding Agent、数据分析 Agent,还是任何其他领域的 Agent:
- 附件系统的"分层注入、差分通知、频率控制"思想适用于任何需要上下文管理的场景
- "反面清单"式的 Prompt 写法适用于任何需要约束模型行为的场景
- "先校验再执行、先读再写"的工具设计适用于任何有副作用的操作
- "事后检测 + 反馈闭环"的质量保障模式适用于任何无法事前完全验证的场景
希望本文的分析能帮助读者不只是"知道 Claude Code 做了什么",而是理解为什么这样做,并将这些思想应用到自己的实践中。
毕竟,AI 学会了没用——你学会了才有用。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




