

读书笔记丨《从零构建大语言模型》
通过 500 行代码实现,深入解析从零构建 GPT 风格大语言模型的完整流程:从数据处理、Transformer 架构核心、训练循环到文本生成策略,带你理解大模型背后的工程实现原理。
通过 500 行代码实现,深入解析从零构建 GPT 风格大语言模型的完整流程:从数据处理、Transformer 架构核心、训练循环到文本生成策略,带你理解大模型背后的工程实现原理。
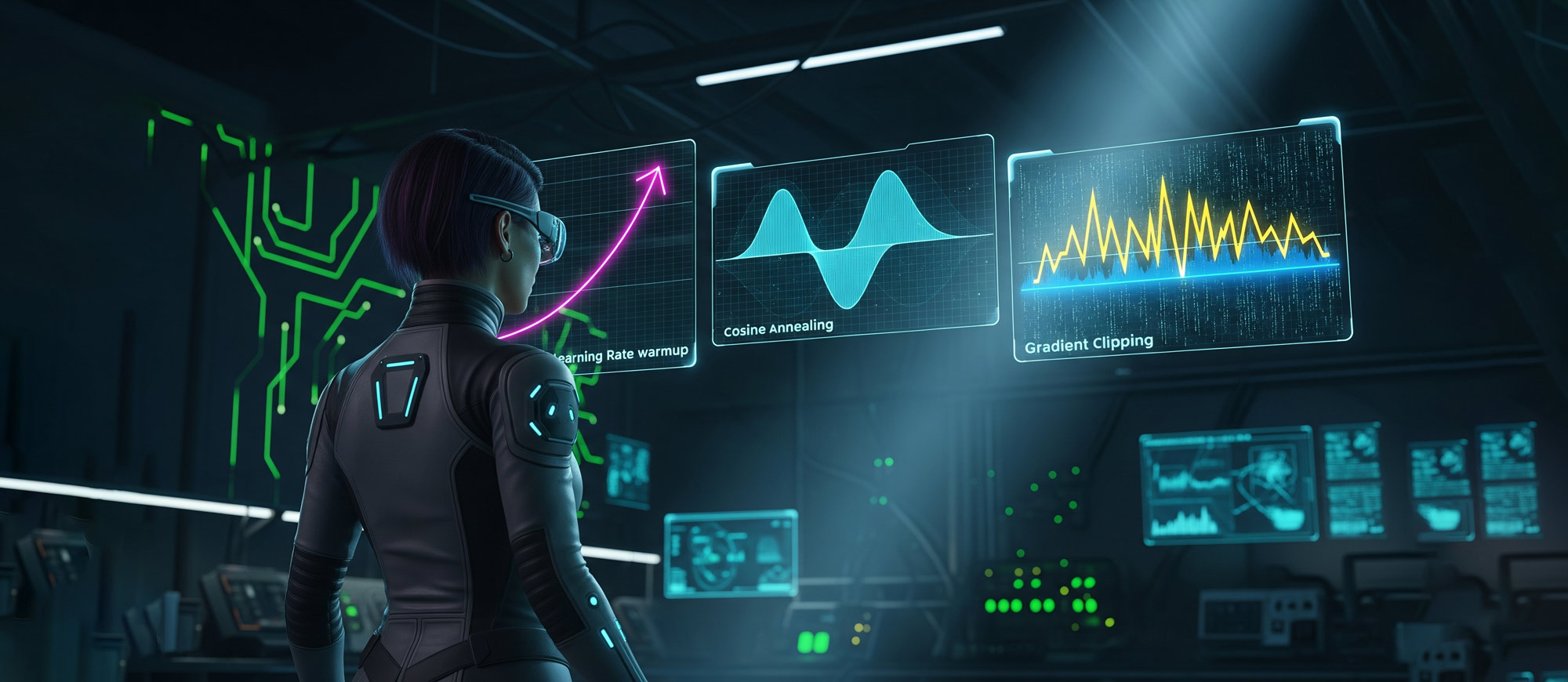
本篇深入探讨了深度学习训练中的三大核心优化技巧,学习率预热解决训练初期不稳定性,余弦衰减实现精细调整和平滑收敛,梯度裁剪防止梯度爆炸。从原理到实践,全面解析如何让模型在高维损失空间中更稳定、更高效地找到最优解。

本文从 PyTorch 的核心设计出发,通过一个简单的例子,帮助读者理解 PyTorch 的核心设计,包括张量、自动求导、神经网络等。
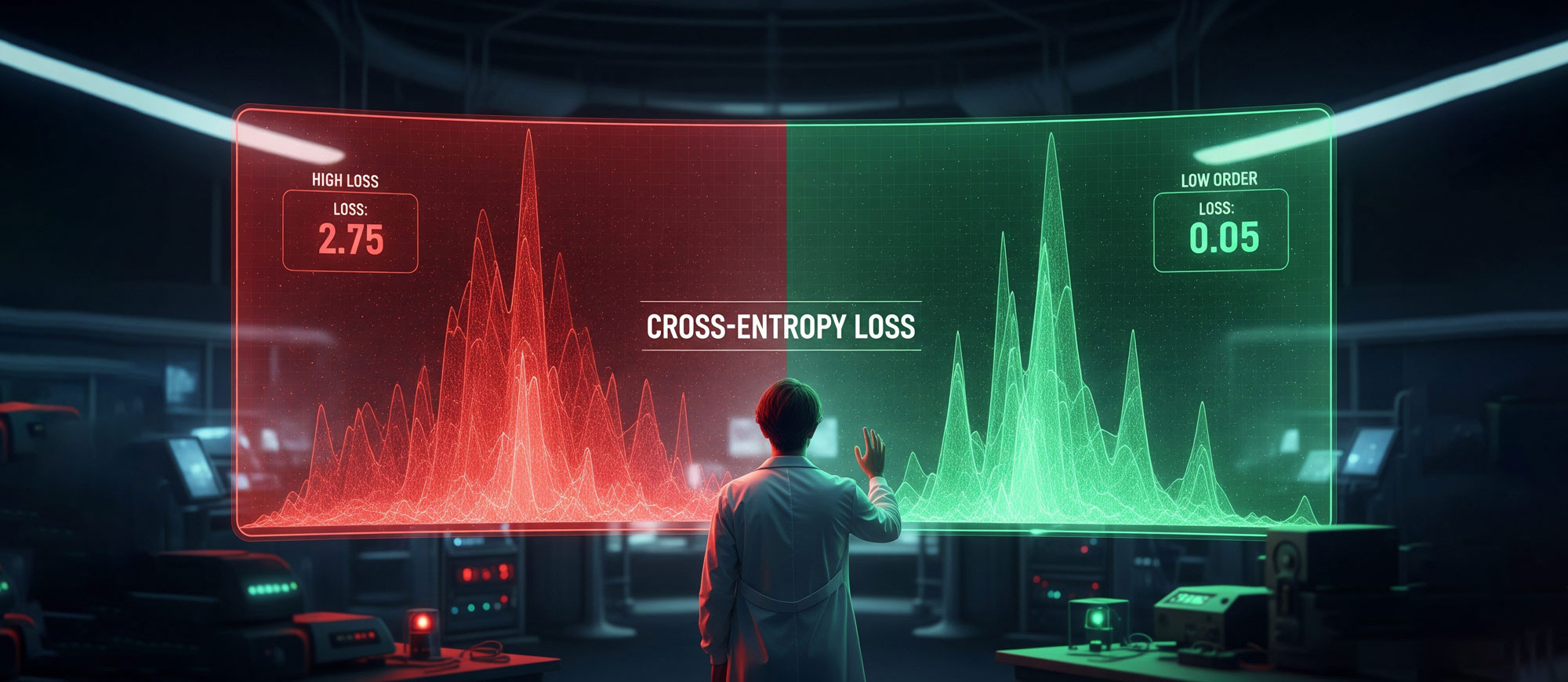
本篇从 LLM 训练过程概述开始,通过"教学徒写文章"的生动比喻,帮助读者理解交叉熵损失在机器学习中的核心作用,以及如何用它来评估和优化模型的预测能力。

本篇用外语学习的比喻,深入浅出地解释 GPT 架构中的权重共享技术,从听写记忆到表达记忆,帮助你理解这个提升大模型效率的核心优化策略

本篇用 CEO 追责分锅的比喻,深入浅出地解释反向传播算法的工作原理,从流水线管理到神经网络训练,帮助你理解这个深度学习的核心算法