
系列文章:
- Rust 原理丨聊一聊 Rust 的 Atomic 和内存顺序 👈 本篇
- Rust 原理丨从汇编角度看原子操作
- Rust 实战丨手写一个 SpinLock
- Rust 实战丨手写一个 oneshot channel
- Rust 实战丨手写一个 Arc
- Rust 原理丨操作系统并发原语
- Rust 实战丨手写一个 Mutex
- Rust 实战丨手写一个 Condvar
- Rust 实战丨手写一个 RwLock
Atomic
在 Rust 的 std::sync::atomic
模块中包含了无锁并发编程的原子化类型,与通常的算术运算符和逻辑运算符不同,原子化类型会暴露执行原子化操作的方法,单独的加载、存储、交换和算术运算都会作为一个单元安全地进行,哪怕其他线程也在执行操作同一内存的原子化操作也没问题。
Rust 提供了以下几种原子化类型:
AtomicIsize和AtomicUsize是与单线程isize类型和usize类型对应的共享整数类型。AtomicI8、AtomicI16、AtomicI32、AtomicI64及其无符号变体(如AtomicU8)是共享整数类型,对应于单线程中的类型i8、i16等。AtomicBool是一个共享的bool值。AtomicPtr是不安全指针类型*mut T的共享值。
这些类型都会以下几类核心功能:
Load、Store: 存取值Fetch-and-Modify: 获取并修改Compare-and-Exchange: 比较并交换
下面我们对上述提到的几种核心功能进行举例。
Load & Store
- load: 从原子化类型中获取起对应的基本数据类型的值。
- store: 将一个基本数据类型的值存储到其对应的原子化类型中。
在下面的例子中,我们使用 AtomicUsize::new(0)
初始化了一个原子类型,它对应的基本数据类型是 usize。
我们起了一个子线程,在 for 循环中不断地使用 store
函数修改 num_done 的值,然后在主线程中使用
load 获取起对应的值,当发现值为 100
时,就退出循环,进程结束。
得益于原子化类型的并发安全特性,所以这里两个线程对
num_done 进行并发读写都是安全的。
1 | fn main() { |
这里我们暂且忽略
std::sync::atomic::Ordering::Relaxed这个参数的含义,在后续的「内存顺序」章节会进行详细阐述。
Fetch-and-Modify
Fetch-and-Modify
操作用于在获取当前值的同时对其进行修改。这类操作包括
fetch_add、fetch_sub、fetch_and、fetch_or、fetch_xor
等。
我们将上面的例子修改一下,不再是直接 store
一个值,而是不断进行加 1 操作:
1 | fn main() { |
Compare-and-Exchange
Compare-and-Exchange 是一种条件更新操作,只有在当前值等于预期值时才会更新。
下面的例子中我们实现了一个函数
allocate_new_id,它支持在并发环境下分配新的
id,这里我们使用了 compare_exchange(id, id+1)
进行条件更新,只有当 id
没有发生变化的时候,才运行对其进行加
1,这就保证了在并发下,只有一个线程可以成功执行该语句,从而保证
id 的递增性和唯一性。
1 | fn allocate_new_id() -> u32 { |
在 Rust
中,原子化类型还提供了另外一个函数:compare_exchange_weak,它与
compare_exchange
的主要区别在于它们在失败时的行为:
compare_exchange_weak,它与
compare_exchange
的主要区别在于它们在失败时的行为:compare_exchange:
- 只会在实际值不等于期望值时失败。
- 提供更强的保证,但可能性能较低。
- 适用于不在循环中的单次比较交换操作。
compare_exchange_weak:
- 即使实际值等于期望值时也可能失败(称为“虚假失败”或“spuriousfailure”)。
- 性能可能更好,因为允许在某些架构上生成更高效的代码。
- 最适合在循环中使用,因为需要处理可能的虚假失败。
在实际应用中:
- 如果操作在循环中,使用
compare_exchange_weak通常更好。 - 如果是单次操作,使用
compare_exchange更合适。 - 在某些平台上,这两个操作可能没有性能差异,但
compare_exchange_weak的行为仍然可能不同。
这种区别的存在是因为在某些 CPU架构上,允许虚假失败可以生成更高效的机器码。比如在 ARM架构上,compare_exchange_weak 可以直接映射到单个LL/SC(Load-Link/Store-Conditional)指令。
硬件原理
在一些处理器架构中,当一个 CPU 执行需要原子性的操作时,它可以通过锁定内存总线来确保在操作完成之前,其他 CPU 无法访问相关的内存地址。
基本工作流程如下:
1 | CPU 发出 LOCK 信号 |
主流的有 2 种锁定机制:
总线锁定(Bus Locking):总线锁定是一种机制,它通过锁定内存总线来确保在执行原子操作时,其他处理器无法访问内存。这种方法虽然简单,但会导致总线的其他操作被阻塞,从而影响系统性能。
1
2
3
4
5
6
7
8
9优点:
- 绝对的原子性保证
- 适用于所有内存位置
缺点:
- 性能开销大
- 会阻塞其他 CPU 对内存的访问缓存锁定(Cache Locking):现代处理器通常使用缓存锁定来实现原子操作。缓存锁定通过锁定处理器的缓存行来实现,而不是锁定整个总线。这种方法可以减少对总线的影响,提高系统的并发性能。
1
2
3
4
5
6
7
8
9优点:
- 性能更好
- 不会完全阻塞内存访问
条件:
- 数据必须在缓存行中
- 缓存行必须是独占状态
缓存锁定通常依赖于缓存一致性协议(如 MESI 协议)来确保在多个处理器之间的数据一致性。通过这些协议,处理器可以在本地缓存中执行原子操作,并在必要时与其他处理器同步。
MESI 协议即:
1 | M (Modified):已修改 |
不同的架构有不同的锁定方式:
- x86/x64:使用 LOCK 前缀
- ARM:使用 exclusive load/store 指令
- PowerPC:使用 load-linked/store-conditional
以下是 x86 汇编的一个示例:
1 | ; 原子加法操作 |
为了充分利用缓存锁定的优势,我们在编写代码时,可以有以下的性能考虑:
缓存行对齐,避免伪共享
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15use std::sync::atomic::{AtomicI32, Ordering};
// 在 Rust 中,可以使用 #[repr(align(N))] 属性来确保结构体或变量的对齐方式,以避免伪共享。
// 伪共享是指多个线程访问不同的变量,但这些变量共享同一个缓存行,从而导致不必要的缓存一致性流量。
struct AlignedCounter {
counter: AtomicI32,
}
fn main() {
let counter = AlignedCounter {
counter: AtomicI32::new(0),
};
// 使用 counter.counter.fetch_add(...) 进行操作
}避免频繁的总线锁定
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17use std::sync::atomic::{AtomicI32, Ordering};
fn main() {
let counter = AtomicI32::new(0);
// 不好的做法:频繁的原子操作
for _ in 0..1000 {
counter.fetch_add(1, Ordering::SeqCst);
}
// 更好的做法:本地累加后一次性更新
let mut local_sum = 0;
for _ in 0..1000 {
local_sum += 1;
}
counter.fetch_add(local_sum, Ordering::SeqCst);
}
Rust 实战查看汇编
笔者使用的是 ARM64 架构的 macbook。
1 | use std::sync::atomic::{AtomicI64, Ordering}; |
使用 rustc 编译并输出汇编代码:
1 | rustc -O --emit asm src/main.rs |
代码中我特地设置了 10086
这个特殊的值,这是为了可以在输出的 main.s 文件中快速找到
store 对应的位置:
1 | __ZN3std3sys9backtrace28__rust_begin_short_backtrace17h750d7a3a9c81fc67E: |
在这个代码中,stlr 就是 Store Release
的意思,另外一个关键字是 ladpr,表示
Load Acquire 的意思,通过这个关键字,你可以找到
load 对应的汇编代码:
1 | Lloh11: |
Go 实战查看汇编
笔者使用的是 ARM64 架构的 macbook。
1 | package main |
使用如下命令,可以输出优化后的汇编代码:
1 | go build -gcflags=-S -ldflags=-w main.go 2> assembly.txt |
查看输出的文件,我们同样搜索 10086,可以快速找到
store 的位置:
1 | 0x0008 00008 (/Users/wangjiahan/go/go1.23.2/src/sync/atomic/type.go:109) MOVD $10086, R1 |
可以看到,这里同样也是使用了 STLR 指令。接着我们看第 14
行代码的位置对应的汇编:可以发现这里使用的 LDAR
指令,也就是 Load Acuqire。
1 | 0x001c 00028 (/Users/wangjiahan/goStudy/go-atomic/main.go:14) HINT $0 |
内存顺序
在了解了 Rust Atomic
的基本用法和基本原理之后,我们回过头来谈一谈原子操作参数中的
std::sync::atomic::Ordering::Relaxed,这个就是本篇的主题:内存顺序。内存顺序要解决的核心问题是如何合理地限制单一线程中的代码执行顺序,使得在不使用锁的情况下,既能最大化利用
CPU 的计算能力,又能保证多线程环境下不会出现逻辑错误。
指令乱序
CPU 和编译器都会在保证程序运行结果不发生改变的前提下,尽一切可能让我们的程序运行得尽可能快。
1 | fn f(a: &mut i32, b: &mut i32) { |
像上述代码,编译器完全可以优化成下面的代码,从而提高程序的运行效率:
1 | fn f(a: &mut i32, b: &mut i32) { |
在这个过程中,就可能会出现指令重排,甚至是代码重写,不过这带来了指令乱序的问题,即程序的实际执行顺序跟我们的代码顺序是不一致的。
不过,编译器保证的是在单线程环境下,执行的结果最终一致,所以,指令乱序在单线程环境下完全是允许的。对于编译器来说,它只知道:在当前线程中,数据的读写以及数据之间的依赖关系。但是,编译器并不知道哪些数据是在线程间共享,而且是有可能会被修改的。而这些是需要开发人员去保证的。
内存模型
为了解决指令乱序带来的并发问题,Rust 采用了内存模型(Memory Model)这一概念。这个概念主要借鉴自 C++11 中引入的内存模型,它定义了在多线程环境下内存访问的行为规范。
内存模型的核心目标是在以下三方面之间取得平衡:
- 正确性保证:确保多线程程序的行为是可预测和一致的。
- 性能优化:允许编译器和 CPU 在不违反正确性的前提下进行优化。
- 跨平台兼容:提供一个统一的抽象层,使代码可以在不同的硬件架构上正确运行。
具体来说,内存模型:
- 为开发者提供了清晰的规则,说明在多线程环境下,什么样的内存访问行为是合法的,什么样的行为会导致未定义行为。
- 为编译器开发者提供了明确的标准,指导他们在不同平台上实现必要的内存同步原语。
- 通过定义不同的内存顺序级别(如 Relaxed、Release/Acquire、SeqCst 等),让开发者可以根据需要选择合适的同步强度。
这种抽象让开发者可以专注于并发逻辑本身,而不必过分关 注底层硬件的具体实现细节。
Sequenced-Before
在讨论内存顺序之前,我们需要先对 2 个重要关系术语进行简单阐述,分别是
Sequenced-Before 和 Happens-Before。
Sequenced-Before 描述的是单个线程内的操作顺序。它基于程序的源代码顺序,表示在同一线程中,一个操作在程序中出现在另一个操作之前。
具体来说,如果操作 A sequenced-before 操作 B,那么:
数据依赖关系:如果 B 依赖于 A 的结果,那么 A 一定会在 B 之前执行。例如:
1
2let x = 1; // 操作 A
let y = x + 1; // 操作 B - 依赖于 A 的结果原子操作的顺序:对同一个原子变量的操作会保持程序顺序。例如:
1
2X.fetch_add(5, Relaxed); // 一定先执行
X.fetch_add(10, Relaxed); // 一定后执行独立操作的可重排性:如果两个操作之间没有数据依赖关系,且操作的是不同的变量,那么它们可能会被重排序。例如:
1
2X.store(1, Relaxed); // 这两个操作可能会被重排序
Y.store(2, Relaxed); // 因为它们操作的是不同的变量
Happens-Before
Happens-Before 则描述了跨线程的操作顺序。它定义了不同线程中的操作之间的可见性和顺序关系。如果操作 A Happens-Before 操作 B,那么 A 的内存写入对 B 是可见的。
典型的 Happens-Before 有:
- 同一线程内,如果先调用
f(),再调佣g(),则f()happens-beforeg(),其实这就是sequenced-before。 spawinghappens-beforejoining。lockhappens-beforeunlock。
举个例子:
1 | static X: AtomicI32 = AtomicI32::new(0); |
上面这个例子的执行顺序如下图所示,因为 spawn
happens-before
join,所以我们可以确定的执行顺序是:“store 1 to
X”→“store 2 to X”→“store 3 to X”。而 load from
X 介于 spawn 和 join
之间,且没有进行任何其他的内存顺序限制,所以它和 store 2 to
X 之间的顺序是不确定的,但是可以肯定的是,它一定在
store 3 to X 之前,所以
assert!(x == 1 || x == 2); 是永远成立的。

到这里,相信不少读者已经能够理解为什么需要内存顺序这个东西了,核心问题就是在于 store 2 to X 和 load from X 的执行顺序是否会影响我们的业务逻辑,如果不会,那么我们可以指定最松散的内存顺序要求,如果会,那么我们就要利用指定合适的内存顺序来使得其按照我们的预期顺序进行执行,从而保证业务逻的正确。
Rust 内存顺序
Rust 支持五种内存顺序(Ordering),从最松散到最严格依次为:
| 内存顺序 | 说明 | 保证 | 适用场景 | 示例 |
|---|---|---|---|---|
| Relaxed | 最宽松的内存顺序 | - 仅保证操作的原子性 - 不提供任何同步保证 - 不建立 happens-before 关系 |
- 简单计数器 - 性能要求极高且确定不需要同步 - 已通过其他方式确保同步 |
counter.fetch_add(1, Ordering::Relaxed) |
| Release | 用于存储操作 | - 之前的内存访问不会被重排到此操作之后 - 与 Acquire 配对使用可建立 happens-before 关系 |
- 生产者-消费者模式 - 发布共享数据 - 初始化完成标志 |
data.store(42, Ordering::Release) |
| Acquire | 用于加载操作 | - 之后的内存访问不会被重排到此操作之前 - 与 Release 配对使用可建立 happens-before 关系 |
- 生产者-消费者模式 - 获取共享数据 - 检查初始化标志 |
data.load(Ordering::Acquire) |
| AcqRel | 同时包含 Acquire 和 Release 语义 | - 结合了 Acquire 和 Release 的所有保证 - 用于读改写操作 |
- 需要双向同步的原子操作 - 锁的实现 - 复杂的同步原语 |
value.fetch_add(1, Ordering::AcqRel) |
| SeqCst | 最严格的内存顺序 | - 包含 AcqRel 的所有保证 - 所有线程看到的所有 SeqCst 操作顺序一致 - 提供全局的顺序一致性 |
- 需要严格的全局顺序 - 不确定使用哪种顺序时 - 对性能要求不高的场景 |
flag.store(true, Ordering::SeqCst) |
在 C++ 中,其实还有另外一种内存顺序 Consume,它是
Acquire 的一个更弱的版本:
Acquire: 保证后续的所有读写操作不会重排到这个操作前面
Consume: 只保证后续与这个操作结果相关的读写操作不会重排到这个操作前面
理论上,Consume 在某些架构上可以提供比 Acquire 更好的性能,因为它只需要对数据依赖的操作进行同步。
然而,由于以下原因,Rust 选择不支持 Consume 顺序:
- 实现复杂性:很多编译器实现者发现正确实现 Consume 语义非常困难。
- 性能收益不确定:在实践中,大多数编译器都将 Consume 视为 Acquire 来处理。
- 标准困惑:C++ 标准委员会也承认当前的 Consume 语义定义存在问题,正在考虑重新设计。
选择建议:
- 不确定选择哪种顺序时:
- 使用 SeqCst(最安全但性能最低)
- 或咨询有经验的开发者
- 性能优化时:
- 先使用 SeqCst 开发
- 在性能测试后,根据需要降低到 Release/Acquire
- 只有在确实需要时才使用 Relaxed
- 常见组合:
- Release 写 + Acquire 读:最常见的生产者-消费者模式
- AcqRel:用于原子的读改写操作
- Relaxed:用于简单的计数器场景
下面我们来对每种内存顺序进行举例阐述。
Relaxed
Relaxed
是最宽松的内存顺序,它只保证了原子操作在并发下的安全性,但不保证执行顺序。
考虑如下代码:
1 | static X: AtomicI32 = AtomicI32::new(0); |
基于我们上面提到的 sequenced-before 规则,我们可以确定
a 和 b 两个线程内的
happens-before 规则,但是二者之间的
happens-before 是无法确定的,但是我们可以确定最后的结果是
15。下图展示了上述代码的执行顺序示意图:

虽然两个线程之间的 happens-before
是无法确定的,但是我们可以确定 X
的变化顺序:0→5→15。所以线程 b 输出
0 0 0 0、0 0 5 15 和 0 15 15 15
都是可能的,而永远不可能输出 0 5 0 15 或
0 0 10 15 类似的结果。
但是如果是这样子的话,就不一定了:
1 | static X: AtomicI32 = AtomicI32::new(0); |
上面这个例子,X 的变化顺序可以是 0→5→15,也可以是
0→10→15,这取决于哪个 fetch_add 先被执行。
再举个例子:
1 | static DATA: AtomicI32 = AtomicI32::new(0); |
上面这个例子中,线程 A 执行了:
1 | DATA.store(123, Ordering::Relaxed); // 准备数据 |
这是 2 个没有依赖关系的原子操作,且使用的是 Relaxed
内存顺序,所以对于线程 B 来说,这 2
个操作的顺序是不确定的。所以是很可能在
READY.load(Ordering::Relaxed) 返回 true
的时候,DATA.load(Ordering::Relaxed) 依旧还是
0。
那如何确保这个断言一定成功呢?那就需要“升级”一下了~ 这个时候就轮到
Release 和 Acquire 的出场了。
Release & Acquire
Release 和 Acquire
一般成对出现,它们共同建立了线程间的同步关系:
Release: 作用于写操作(store),确保该操作之前的所有内存访问不会被重排到这个 Release 操作之后。Acquire: 作用于读操作(load),确保该操作之后的所有内存访问不会被重排到这个 Acquire 操作之前。
当一个线程通过 Acquire 读取到另一个线程通过
Release 写入的值时,会建立一个 happens-before
关系:线程 A 中 Release
写入之前的所有内存写操作,对于线程 B 中 Acquire
读取之后的所有内存读操作都是可见的。
修改一下上面的例子:
1 | static DATA: AtomicI32 = AtomicI32::new(0); |

如上图所示,在这个例子中:
- Release-Acquire 同步确保了
READY的写入和读取之间建立了 happens-before 关系 - 由于
DATA的写入在READY的 Release 写入之前,而DATA的读取在READY的 Acquire 读取之后 - 因此可以保证线程 B 一定能看到线程 A 写入的值 123
更进一步,我们通过观察,可以发现 DATA 都没必要使用
Atomic 类型,因为由 READY 建议的
happens-before 规则已经能保证对 DATA
的读写不可能并发执行了。不过因为 Rust
的类型系统并不允许跨线程进行非原子类型的读写操作,所以这里我们需要使用
unsafe
才能使编译通过,但通过我们之前的分析,我们可以确保下面这段代码是安全的:
1 | static mut DATA: u64 = 0; |
释放序列(Release Sequence)
我们再来看一段代码示例:
1 | use std::{sync::atomic::AtomicU8, thread}; |
这段代码是参考 thread_2中我们使用的是 Relaxed, 这段代码中的assert_eq!(DATA[0], 42)也是一定成功的。为什么呢?这涉及到一个重要的概念——释放序列(ReleaseSequence):
对某个原子对象 M的一段连续修改序列的定义,用于保证acquire-加载 能够同步到对应的release-存储,形成 happens-before关系。具体来说:
起始于一次释放操作(release operation)
该释放操作是对原子对象 M 的一次写操作,且其内存语义为
release、acq_rel或seq_cst。这条操作在修改顺序(modificationorder)中作为释放序列的头部。
后续紧随其后的所有修改
自头部释放操作之后,凡是在 M的修改顺序中紧跟出现的原子操作,且满足以下之一,皆被纳入同一释放序列:
- 同一线程对 M 执行的任意原子写操作;
- 任意线程对 M 执行的“读-改-写”(RMW)原子操作(如
fetch_add、compare_exchange等)。
只要序列中没有出现其它线程的普通(非RMW)store,就形成一个最大连续子序列,这就是完整的释放序列。
序列中继发的这些写或 RMW 操作本身无需再指定memory_order_release(它们即便是relaxed),也都被“挂到”最初那次 release 操作上,从而被后续的 acquire加载所“看到”。
在这段代码中:当 thread_2 的 RMW操作成功的时候,说明 FLAG 是 1,即thread_1 已经执行了 release操作,这个时候:
thread_1的release操作建立了同步点thread_2的RMW操作自动成为释放序列的一部分- 当
thread_3通过acquire看到值 2时,它能看到整个释放序列的所有修改。 - 因此能保证看到
DATA中的 42。

所以在这种场景下使用 relaxed 既安全又高效,因为:
- 它是释放序列的一部分
- 不需要额外的同步开销
- 仍然能保证正确的内存顺序
为什么这样设计呢?
- 原子性保证:RMW操作本身就是原子的,不会产生数据竞争
- 连续性:每个 RMW操作都直接或间接地基于前一个操作的结果
- 因果关系:形成了一个清晰的修改链条
- 性能考虑:中间的 RMW 操作不需要额外的同步开销
Sequentially Consistent
SeqCst 是最严格的内存顺序,它包括获取
release 和 acquire
的所有保证,还保证了全局一致的操作顺序。简单理解就是,你代码的顺序是怎么样,实际的执行顺序就是什么样。
我们来看一段代码:
1 | use std::sync::atomic::Ordering::SeqCst; |
在这段代码中,两个线程都是希望将自己的原子变量设置为
true,从而阻止另外一个线程对 S 进行
push 操作,其实就类似于锁。因为这里使用了
SeqCst,所以代码的执行顺序是跟代码编写顺序是一致的,那么就可能出现以下
3 种执行情况:

即:同一时刻,最多只可能有一个线程会对
S 进行操作。
内存屏障
除了内存顺序(Memory Order),还有另外一种方式可以控制程序的执行顺序,就是内存屏障(Memory Barrier)。内存屏障是一种底层的同步原语,它能强制处理器按照特定的顺序执行内存操作。内存屏障通过阻止或限制指令重排序,来确保内存操作的可见性和顺序性。
基本概念
内存屏障主要分为以下几种类型:
Load Barrier(读屏障)
- 确保在屏障之前的所有读操作都执行完成
- 防止后续读操作被重排到屏障之前
- 对应 Acquire 语义
Store Barrier(写屏障)
- 确保在屏障之前的所有写操作都执行完成
- 防止后续写操作被重排到屏障之前
- 对应 Release 语义
Full Barrier(全屏障)
- 同时包含读屏障和写屏障的功能
- 防止任何内存操作的重排序
- 对应 SeqCst 语义
即下面这 2 种实现方式是等价的:
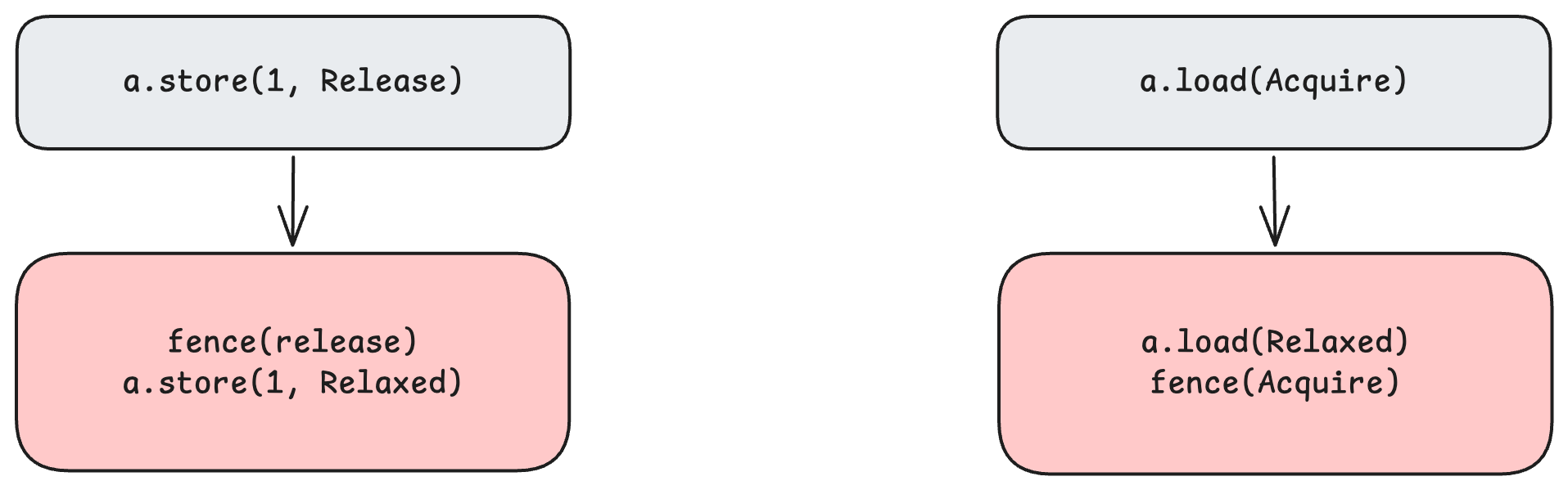
所以到这里,我们可以更好地理解为什么 release
是阻止其前面的内存访问越过它,而 acquire
是阻止其后面的内存访问越过它了。因为有个 fence
在前面或后面拦着!
但是一般来说,下面的写法相比上面的写法会有一丢丢的性能损失,因为这会增加一些额外的处理指令。那
fence 的用武之地是什么呢?
- 可以同时对多个原子操作进行
fench; - 可以根据条件判断,选择是否进行
fench。
举个例子:

这个例子的关键点是:
如果线程 2 中的任何一个 load 操作观察到了线程 1 中对应的 store 操作的值:
- 比如 A.load() 读到了值 1,或
- B.load() 读到了值 2,或
- C.load() 读到了值 3
那么:线程 1 中的 release fence 就会 happens-before 线程 2 中的 acquire fence。这意味着线程 1 中 release fence 之前的所有内存操作对线程 2 中 acquire fence 之后的操作都是可见的。
这展示了内存屏障的一个重要优势:一个屏障可以同时为多个原子操作建立同步关系,而不需要在每个原子操作上都使用 Release/Acquire 内存序。这在某些场景下可能会更高效。
用更通俗的话说:这就像在线程 1 设置了一个"检查点"(release fence),在线程 2 也设置了一个"检查点"(acquire fence),只要线程 2 看到了线程 1 在其检查点之后做的任何一个改动,那么线程 1 检查点之前的所有操作对线程 2 的检查点之后都是可见的。
硬件实现
不同的处理器架构实现内存屏障的方式不同:
1 | ; x86/x64 |
与内存顺序的关系
Rust 的内存顺序实际上是通过内存屏障来实现的:
1 | // Release 写入会插入 Store Barrier |
注意:直接使用内存屏障是非常底层的操作,通常我们应该使用 Rust提供的高级抽象(如原子类型和它们的内存顺序)来实现同步。内存屏障的知识主要用于理解这些高级抽象的工作原理。
Go Atomic
熟悉 Go 语言的读者应该会意识到在使用 Go 语言的原子类型的时候,好像都没见过 Memory Order 这个东西,如下:
1 | package main |
在 atomic/doc.go 源码中我们可以看到这段话:
1 | // The load and store operations, implemented by the LoadT and StoreT |
Go
语言设计者认为让程序员选择内存序会增加复杂性和出错的可能,所以为了程序的简单性和可预测性,直接就使用了最安全的
Seq-Cst 内存顺序了。
the Go memory model 中还提了一句:
1 | If you must read the rest of this document to understand the behavior of your program, you are being too clever. |
这也呼应了 Go 的设计理念:
1 | Share memory by communicating; don't communicate by sharing memory. |
所以总结一下:
- Go 的原子操作采用了最强的顺序一致性内存序;
- 这是一个有意识的设计选择,为了简单性和可预测性;
- 如果你需要更细粒度的内存序控制,那么 Go 可能不是最佳选择;
- Go 更推荐使用 channels 和其他同步原语来进行并发控制。
参考
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。

的概念、分类及其在并发编程中的应用。通过大...)


