
系列文章:
- Rust 原理丨聊一聊 Rust 的 Atomic 和内存顺序
- Rust 原理丨从汇编角度看原子操作 👈 本篇
- Rust 实战丨手写一个 SpinLock
- Rust 实战丨手写一个 oneshot channel
- Rust 实战丨手写一个 Arc
- Rust 原理丨操作系统并发原语
- Rust 实战丨手写一个 Mutex
- Rust 实战丨手写一个 Condvar
- Rust 实战丨手写一个 RwLock
继上篇 Rust 原理丨聊一聊 Rust 的 Atomic 和内存顺序,我们详细介绍了 Rust 中的原子操作及内存顺序和内存屏障的诸多概念。我们知道,之所以要在硬件层面之上的编程语言中,抽象出这些顶层概念,是为屏蔽底层硬件的差异。那么本篇,我们就尝试从汇编代码和硬件层面来分析在不同的计算机架构下这些概念是如何被实现的,它们之间就有哪些具体的差异。
在展开之前,我们先来复习一下 Rust 中的内存顺序和内存屏障。
Rust 支持五种内存顺序(Ordering),从最松散到最严格依次为:
| 内存顺序 | 说明 | 保证 | 适用场景 | 示例 |
|---|---|---|---|---|
| Relaxed | 最宽松的内存顺序 | - 仅保证操作的原子性 - 不提供任何同步保证 - 不建立 happens-before 关系 |
- 简单计数器 - 性能要求极高且确定不需要同步 - 已通过其他方式确保同步 |
counter.fetch_add(1, Ordering::Relaxed) |
| Release | 用于存储操作 | - 之前的内存访问不会被重排到此操作之后 - 与 Acquire 配对使用可建立 happens-before 关系 |
- 生产者-消费者模式 - 发布共享数据 - 初始化完成标志 |
data.store(42, Ordering::Release) |
| Acquire | 用于加载操作 | - 之后的内存访问不会被重排到此操作之前 - 与 Release 配对使用可建立 happens-before 关系 |
- 生产者-消费者模式 - 获取共享数据 - 检查初始化标志 |
data.load(Ordering::Acquire) |
| AcqRel | 同时包含 Acquire 和 Release 语义 | - 结合了 Acquire 和 Release 的所有保证 - 用于读改写操作 |
- 需要双向同步的原子操作 - 锁的实现 - 复杂的同步原语 |
value.fetch_add(1, Ordering::AcqRel) |
| SeqCst | 最严格的内存顺序 | - 包含 AcqRel 的所有保证 - 所有线程看到的所有 SeqCst 操作顺序一致 - 提供全局的顺序一致性 |
- 需要严格的全局顺序 - 不确定使用哪种顺序时 - 对性能要求不高的场景 |
flag.store(true, Ordering::SeqCst) |
内存屏障主要分为以下几种类型:
Load Barrier(读屏障)
- 确保在屏障之前的所有读操作都执行完成
- 防止后续读操作被重排到屏障之前
- 对应 Acquire 语义
Store Barrier(写屏障)
- 确保在屏障之前的所有写操作都执行完成
- 防止后续写操作被重排到屏障之前
- 对应 Release 语义
Full Barrier(全屏障)
- 同时包含读屏障和写屏障的功能
- 防止任何内存操作的重排序
- 对应 SeqCst 语义
读完本篇你能学到什么
汇编分析能力:掌握从 Rust 代码到汇编指令的完整分析链路,能够使用
cargo-show-asm或 Compiler Explorer 等工具深入理解代码的底层实现。跨平台差异洞察:深刻理解 x86-64(CISC)与 ARM64(RISC)两大主流架构在原子操作实现上的本质差异,为性能优化和平台适配提供理论基础。
内存顺序选择策略:不再需要死记硬背五种内存顺序,而是基于硬件特性和性能考量做出明智选择 —— 知道何时用
Relaxed追求极致性能,何时必须上SeqCst保证正确性。原子性保证机制:理解为什么同样的汇编代码,普通操作与原子操作在编译器层面有本质区别,以及对齐访问与跨缓存行访问的不同行为。
硬件协议原理:掌握 MESI 缓存一致性协议、x86 的
lock机制、ARM 的LL/SC机制等底层实现原理,能够解释多核环境下的数据同步过程。性能优化洞察:理解不同架构下内存屏障的开销差异,为高性能并发代码提供优化方向(如 ARM64 上
compare_exchange_weak的真实优势)。并发问题调试:当遇到并发 bug 时,能够从汇编层面分析问题根因,判断是内存顺序问题还是原子性问题。
架构适配能力:在跨平台开发中,能够针对不同架构的特性(如 x86-64 的强顺序 vs ARM64 的弱顺序)做出相应的代码调整。
锁与无锁数据结构设计:基于硬件原理设计高效的同步原语,理解何时选择基于 CAS 的无锁算法,何时选择传统锁机制。
在进入汇编代码的世界之前,我们先简单补充 2 个重要概念,分别是指令集和 CPU 缓存一致性协议 MESI。
指令集
两种指令集:
- CISC(Complex Instruction Set Computing,复杂指令集)
- RISC(Reduced Instruction Set Computing,精简指令集)
二者对比:
| 特征 | RISC | CISC |
|---|---|---|
| 指令集 | 精简,指令数目少 | 复杂,指令数目多 |
| 指令复杂性 | 指令简单,每条指令执行单一功能 | 指令复杂,可以执行多个功能 |
| 寻址方式 | 简单寻址方式 | 复杂寻址方式 |
| 硬件实现 | 易于实现 | 实现复杂 |
| 编译器 | 高效编译器 | 编译器效率相对较低 |
| 运算速度 | 快速 | 相对慢 |
具体可参考:risc vs. cisc。
两种指令集分别对应两种最典型的计算机架构:
- x86-64:基于 CISC(复杂指令集)的 64 位扩展架构,由 AMD 设计并主导,兼容 x86 32 位生态,通过硬件复杂性换取高性能与广泛兼容性,主导桌面与服务器领域。
- arm64:基于 RISC(精简指令集)的 64 位架构,由 ARM 设计,以精简指令、高能效为核心,原生支持低功耗场景,主导移动设备并逐步扩展至服务器与 PC 领域。
在本篇中,我们只涉及 2 个平台:
- x86_64-unknown-linux-musl(以下简称 x86-64)
- aarch64-unknown-linux-musl(以下简称 ARM64)
要将 Rust 代码编译为指定平台的可执行文件:
安装对应的目标平台
1
2rustup target add x86_64-unknown-linux-musl # x86-64
rustup target add aarch64-unknown-linux-musl # ARM64编译时使用
--target标志1
2cargo build --release --target x86_64-unknown-linux-musl
cargo build --release --target aarch64-unknown-linux-musl
缓存一致性协议 MESI
在多核系统中,每个核心都有自己的缓存(L1/L2 Cache),而内存中的数据可能被多个核心同时读取或修改。如果不加控制,会导致以下问题:
- 缓存不一致(Cache Coherence Problem):不同核心的缓存可能持有同一内存地址的不同副本。
- 脏数据(Dirty Data):某个核心修改了数据,但其他核心仍使用旧值。
MESI(Modified, Exclusive, Shared, Invalid)是一种广泛使用的 缓存一致性协议(Cache Coherence Protocol),用于确保多核处理器系统中各个核心的缓存数据保持一致。它定义了缓存行的 4 种状态,并通过状态转换和消息传递机制来协调多核间的数据访问。
| 状态 | 含义 | 特点 |
|---|---|---|
| M (Modified) | 当前核心独占此数据,且已修改(与内存不一致) | 只有本核心有最新数据,必须写回内存后才能被其他核心读取。 |
| E (Exclusive) | 当前核心独占此数据,但未修改(与内存一致) | 可以安全读取或修改,无需通知其他核心。 |
| S (Shared) | 多个核心共享此数据(与内存一致) | 所有核心只能读取,不能直接修改(需先升级为
M 或 E)。 |
| I (Invalid) | 缓存行无效(数据已过期或未加载) | 必须从内存或其他核心重新加载最新数据。 |
更多细节可参考:维基百科 MESI。
查看 Rust 汇编代码
查看 Rust 汇编代码的常用方式有以下几种:
cargo rustc --lib --release --target x86_64-unknown-linux-musl -- --emit asm
cargo-show-asm(推荐 ✅)
1
cargo asm --release --target=x86_64-unknown-linux-musl --lib {module}::{func_name}
Compiler Explorer (推荐 ✅)
接下来我们来看下各种 Atomic 操作的汇编代码是什么样的。
Store
x86-64:
- 普通类型的赋值操作跟原子操作在
Relaxed顺序下生成的汇编的一模一样的! - 在强顺序一致性要求的
SeqCst下,使用了带有Lock语义的xchg指令保证内存顺序。
ARM64:
- 普通类型的赋值操作跟原子操作在
Relaxed顺序下生成的汇编的也是一模一样的! - 在强顺序一致性要求的
SeqCst下,使用了原子存储指令stlr保证内存顺序。
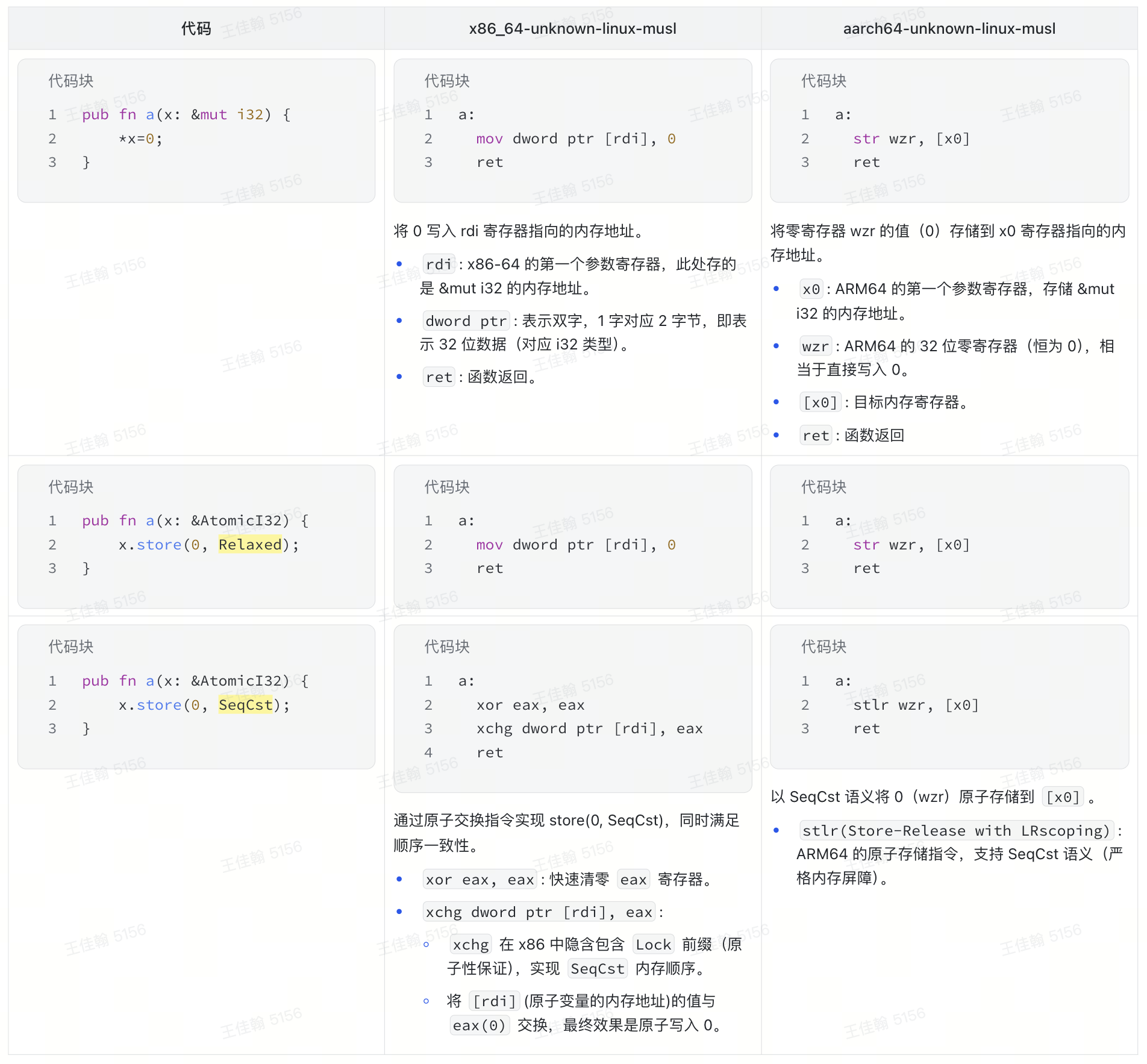
那么问题就来了:普通类型的赋值操作与 Relaxed 的原子操作生成的汇编一样,那凭什么后者就有原子性的保证呢?
- 在上述 2 个架构中,这仅能说明
mov和str在(当前选择的)硬件层面是原子的,无论是否使用 Atomic 类型。这因为 CPU 的缓存一致性协议(MESI)和总线锁定机制确保对齐操作不会撕裂(tearing)。 - 但是对于未对齐或跨缓存行访问,普通操作不保证原子性,可能被拆分为多次访问(如未对齐的 i64 可能拆为 2 个 32 位写入)。
所以在 Rust 编译器上:
- 普通操作(*x=0):Rust
不将其视为原子操作,即使生成的汇编与
Relaxed原子操作相同。编译器可能优化或重排普通操作,破坏原子性假设。- 如:循环中的多次普通写入可能被合并为一次(优化后仅保留最后一次写入)。
- 原子操作(x.store(0, Relaxed)):Rust
强制保证原子性,无论硬件是否隐式支持:
- 对齐访问:直接生成
mov(利用硬件原子性)。 - 未对齐访问:插入额外指令(如
lock cmpxchg)确保原子性。 - 禁止编译器优化重排或消除操作。
- 对齐访问:直接生成
Load
x86-64:
- 三段代码生成的汇编代码一模一样!这是因为 x86-64 的强顺序策略默认保证
mov具有顺序一致性(类似 SeqCst),因此无需显示内存屏障。
ARM64:
- 对于普通类型的加载操作和 load Relaxed 生成的汇编代码是一样的。
- 对于 load SeqCst,使用了专门的原子加载指令
ldar,它会隐式插入内存屏障,保证该操作之前的所有内存访问对其他线程可见。
虽然 x86-64 对于上面的 3 段代码生成的汇编是一样的,但这只是 x86-64 硬件层面上的保证,且跟之前一样,仅在对齐时是原子的,如果未对齐或跨缓存行访问,是可能被撕裂成 2 个操作的。
在 ARM64 中,不依靠硬件层面的复杂性,而通过 ldar
原子加载指令来保证原子性。

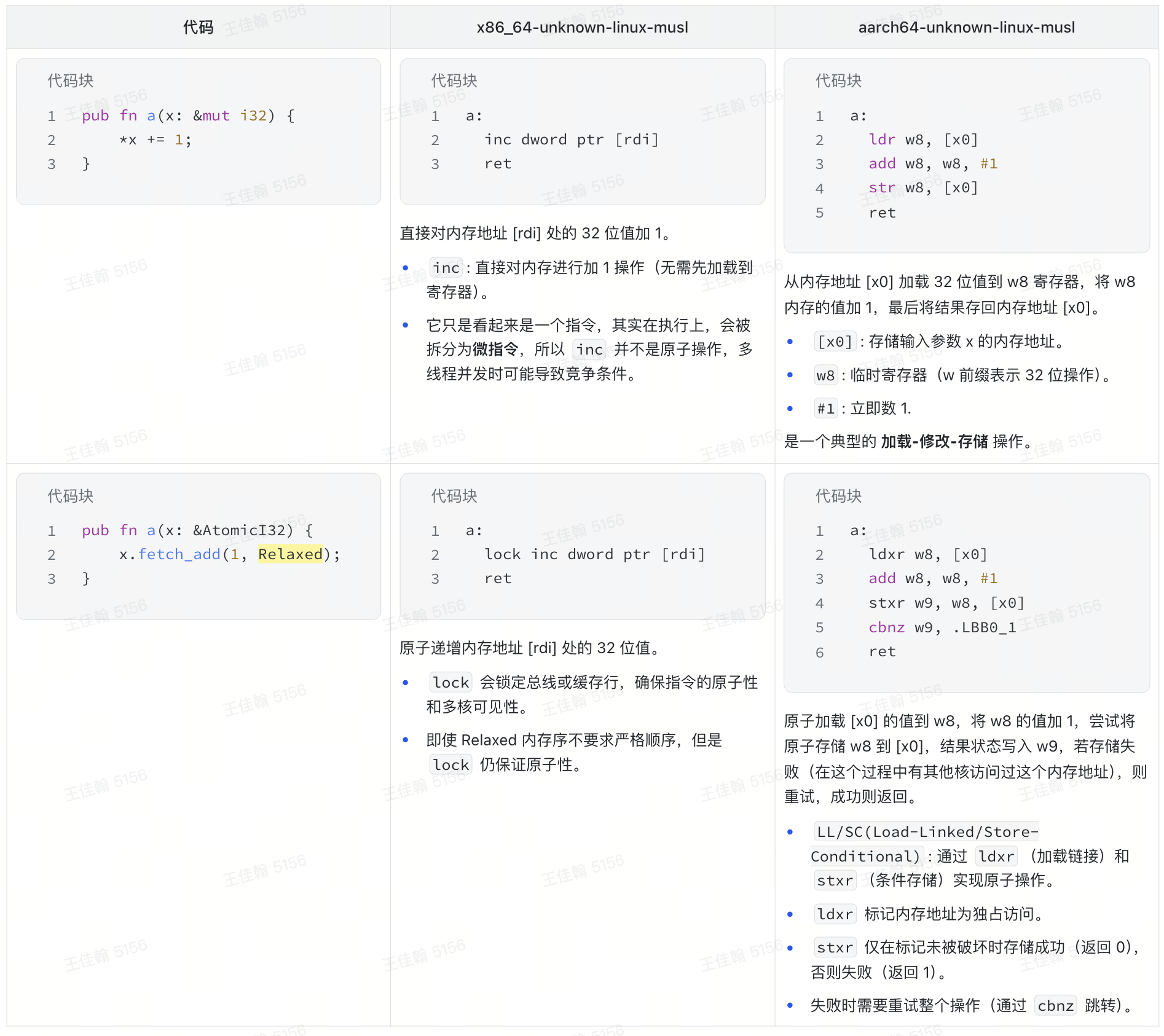
Read-Modify-Write
x86-64:
- 使用
lock指令来锁定总线或缓存行,从而实现原子性。
ARM64:
- 使用
LL/SC机制来实现原子操作(有点类似与乐观锁的味道)。
Compare-and-Exchange
x86-64:
- 二者没有任何区别,或者可以理解为,x86-64 就没有专门实现
compare_exchange_weak。
ARM64:
- 二者实现是不同的,在 ARM64 上,
compare_exchange_weak是真的具备weak的特性。所以如果在特定场景下想用compare_exchange_weak来进一步提升性能,在上层也一定要用循环来主动重试,避免虚假失败。

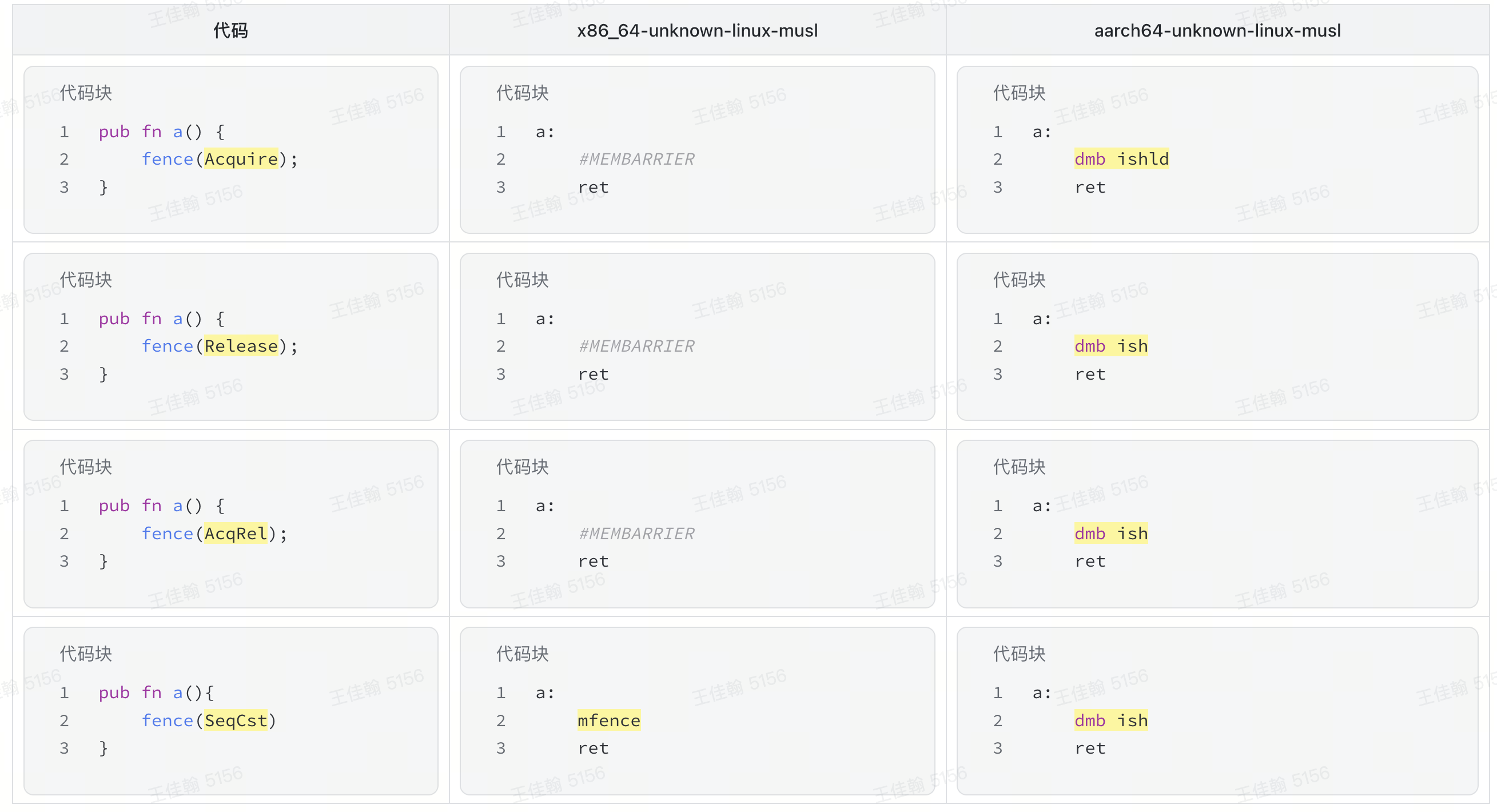
Fence
x86-64:
- Release 和 Acquire 并没有额外使用的指令。只有使用 SeqCst
内存屏障的时候,会插入一条
mfence(memory fence) 指令,这条指令会保证在越过它之前,前面所有的内存操作都已经完成。
ARM64:
- Release、AcqRel 和 SeqCst 都插入了一条
dmb ish(data memory barrier, inner shared domain)。而 Acquire 则插入了一条dmb ishld,它只会等待 load 操作的完成,但是允许 store 操作重排序到它后面。
总结对比

到这里我们可以得到以下结论:
- x86-64 保证原子性的关键是
lock机制,ARM64 保证原子性的关键是LL/SC机制。 - x86-64 保证内存顺序的关键是
mfence指令,ARM64 保证内存顺序的关键是dmb ish和dmb ishld指令。 - x86-64 没有实现真实的
compare_exchange_weak,ARM64 实现了compare_exchange_weak。 - x86-64 使用的是强顺序策略,具体来说:
- Load→ 后续操作:禁止重排序(如
Load A→Store B必须保持顺序)。 - Store→ 前序操作:禁止重排序(如
Load A→Store B中Store B不能提前到Load A前)。 - Store→ 后续 Load:允许重排序(如
Store A→Load B可能实际执行为Load B→Store A
- Load→ 后续操作:禁止重排序(如
- ARM 使用的是弱顺序策略,即所有的原子操作都可能被重排序。
- x86-64 中,Relaxed、Acquire、Release 和 AcqRel 的内存顺序效果是一致的。ARM64 中,Relaxed 没有任何内存顺序的保证,而 Release、AcqRel 和 SeqCst 是一样昂贵的,Acquire 稍微轻量一点,只保证了前面的 load 不会重排到后面。
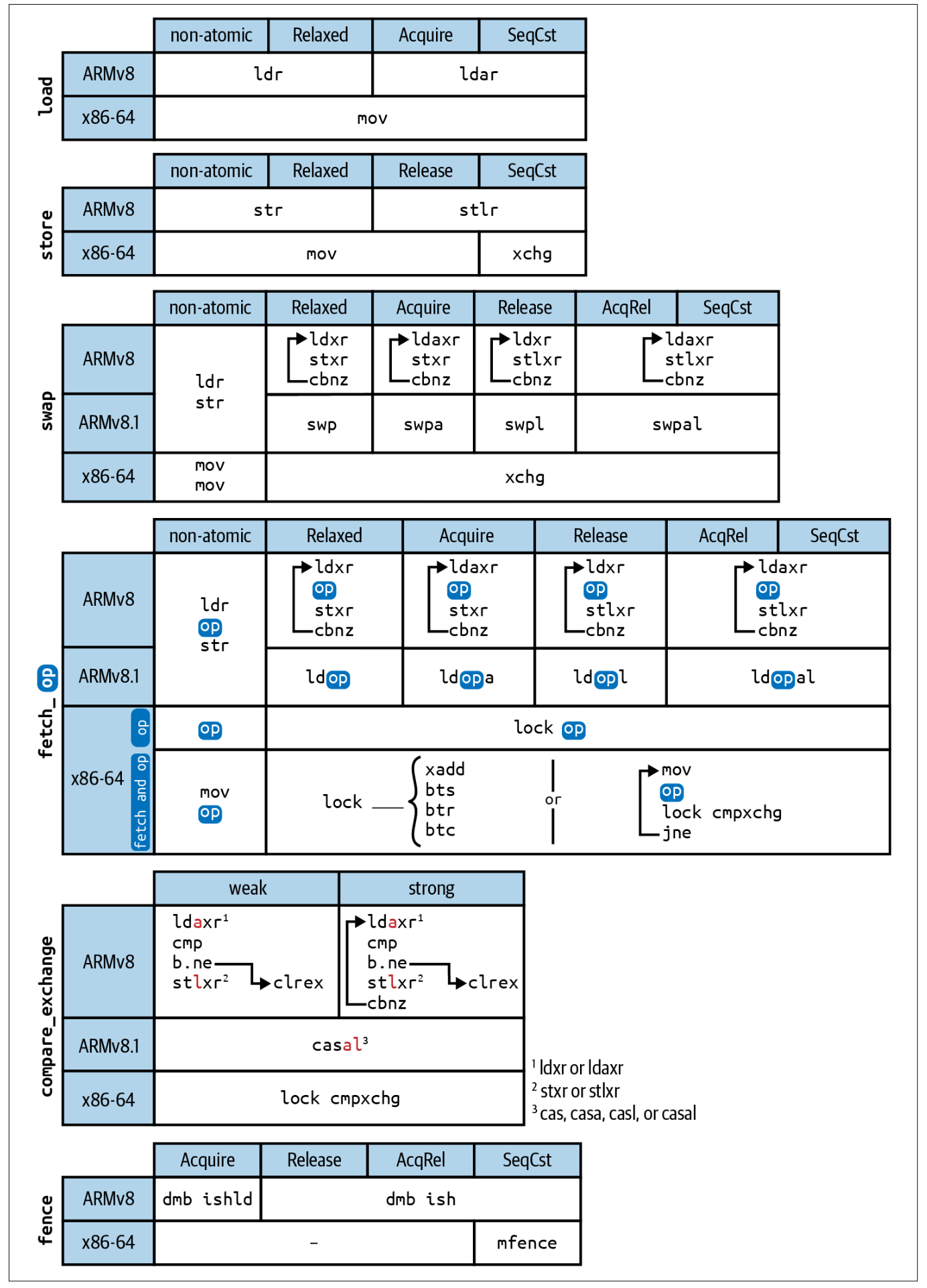
Rust Atomics and Locks 书中给出了一张更细节的图,感兴趣的读者可以研究一下。
硬件原理
最后我们尝试从硬件层面来进一步理解原子操作的底层实现。这块笔者并不专业,更多的是尝试通过 ChatGPT 等 LLM 查阅资料,进行梳理总结。
原子操作的底层实现(如 x86 的 lock 前缀或 ARM 的
LL/SC)依赖于硬件级别的协同机制,其核心是通过
缓存一致性协议、总线仲裁 和
指令集层面的特殊支持
来保证多核环境下的原子性和内存顺序。
x86 的 lock
前缀:总线锁定与缓存一致性
总线锁定(Bus Locking)
当 CPU 执行
lock cmpxchg时,lock前缀会向总线(或缓存一致性协议)发送信号,临时独占内存地址的访问权,阻止其他核心的干扰。- 锁定范围:现代 CPU 通常锁定缓存行(通常 64 字节),而非整个总线。
- 硬件支持:通过处理器的 原子操作单元 和 缓存控制器 协同实现。
MESI 缓存一致性协议
缓存一致性协议(如 MESI)会在硬件层面上确保所有核心对内存修改的观察一致:任何核心的修改会立即(或按协议约定)传播到其他核心的缓存。
lock操作会强制目标缓存行进入 Modified(独占修改) 状态,并通知其他核心的缓存行失效(Invalid)。 如:核心 A 执行
lock inc [x],缓存行x变为 Modified。核心 B 尝试读取
x,触发缓存一致性协议:核心 A 将修改后的值写回主存或核心 B 的缓存(取决于协议变种如 MESIF/MOESI)。
核心 B 的缓存行
x变为 Shared 或 Exclusive。
内存屏障的隐含保证
即使代码使用
Relaxed内存序,lock会隐式插入 StoreLoad 屏障,确保:- 该指令前的所有写操作对其他核心可见。
- 该指令后的读操作不会重排到指令前。
现代优化:缓存锁定(Cache Locking)
新式 CPU(如 Intel Skylake+)优先在缓存层面实现原子性,仅当跨缓存行或未对齐时才降级为总线锁定,减少性能损耗。
ARM 的 LL/SC(Load-Linked/Store-Conditional):轻量级独占标记
独占访问标记(Exclusive Monitor)
硬件状态机:每个 CPU 核心维护一个 独占访问标记,记录最近通过
ldxr加载的内存地址。标记触发:
ldxr [x]会标记地址x为当前核心的独占访问区域。标记清除条件:
其他核心修改了
x的缓存行(通过缓存一致性协议)。当前核心执行
clrex或上下文切换。
条件存储(**
stxr**)的原子性校验校验独占标记:
stxr执行时,硬件会检查目标地址的独占标记是否仍属于当前核心:- 若标记有效:存储成功,返回 0。
- 若标记失效:存储失败,返回 1(需重试)。
与缓存一致性协议的交互
ARM 的 ACE 协议:LL/SC 依赖缓存一致性协议(如 CHI 或 ACE)监听其他核心的修改:
- 核心 A 执行
ldxr [x],缓存行x进入 Exclusive 状态。 - 若核心 B 写入
x,缓存行在核心 A 中变为 Invalid,独占标记被清除。 - 核心 A 的后续
stxr会因标记失效而失败。
- 核心 A 执行
内存顺序的灵活控制
ARM 的内存序(如
Relaxed/SeqCst)通过显式屏障指令实现:ldapr(Load-Acquire):确保后续操作不重排到加载前。stlr(Store-Release):确保前序操作不重排到存储后。
总结
本篇文章通过查看 x86_64-unknown-linux-musl 和
aarch64-unknown-linux-musl 两大平台下的汇编代码
,深入剖析了 Rust 原子操作的底层实现机制,揭示了同一行 Rust
代码在不同平台上截然不同的机器级行为。
到目前为止,我们学习的都是无锁(non-blocking)操作,下篇,我们将继续学习 Rust Atomics and Locks 中的第八章《Operating System Primitives》,为手写阻塞类组件(Mutex、RwLock、CondVar)做理论准备,咱们下篇见!
Happy Coding! Peace~




