
系列文章:
- Rust 原理丨聊一聊 Rust 的 Atomic 和内存顺序
- Rust 原理丨从汇编角度看原子操作
- Rust 实战丨手写一个 SpinLock
- Rust 实战丨手写一个 oneshot channel
- Rust 实战丨手写一个 Arc
- Rust 原理丨操作系统并发原语 👈 本篇
- Rust 实战丨手写一个 Mutex
- Rust 实战丨手写一个 Condvar
- Rust 实战丨手写一个 RwLock
在本系列的前面所有篇章中,我们对非阻塞类的并发操作进行了详细的阐述和实践(除了 SpinLock,不过自旋锁是通过自旋来实现阻塞作用,本质上线程并没有陷入阻塞等待的状态)。
后面我们将继续参考 Rust Atomics and Locks 书中的后续篇章,继续手写几个阻塞类的并发工具,有 Mutex(互斥锁)、RwLock(读写锁)和 CondVar(条件变量)。它们都有一个共同的特点:线程会陷入阻塞,让出 CPU,在等待某个条件满足要求后,会被唤醒并重新调度执行。这就需要借助内核的能力了,我们需要内核支持:
- 记住那些陷入阻塞的线程;
- 在满足条件后,能够唤醒对应的正确的线程。
熟悉操作系统原理的读者应该清楚,我们编写的应用程序,一般是处于用户态,而想要跟内核进行交互,需要陷入内核态,而这种切换,很大程度需要依赖于操作系统提供的系统调用能力,即
syscall。
所以在进入手写 Mutex、RwLock 和 CondVar 篇章之前,我们需要先来学习一下,不同的操作系统,都为我们在并发操作中提供了什么样的能力和限制。
在 Rust
Atomics and Locks 第八章(Operating System
Primitives)中,作者介绍并比较了各平台提供的操作系统级并发原语,包括
POSIX 的 pthread 系列、Linux 的 futex、macOS
的 os_unfair_lock,以及 Windows
的重量级内核对象、轻量级对象和基于地址的等待机制。
在本篇,笔者将基于自己的理解,尝试对这章进行梳理和总结,以便为后面的手写实践篇章奠定一个良好的理论基础,这里还是建议读者去阅读原文,以便获得更多的细节,加深理解。
POSIX 线程原语 pthread
在 Unix 类操作系统中,比如 Linux,libc
就承担了跟内核进行交互的标准接口。在 libc
的基础之前,诞生了一个标准:Portable Operationg System
Interface,即熟知的 POSIX。在 Rust 中,对应了 libc crate。
Windows 系统并不遵循 POSIX 标准,而是一系列的系统库来提供内核交互能力,比如 kernel32.dll。
针对线程操作,POSIX 定义了一系列的数据类型和函数,即所谓的 pthreads。它提供了以下几个比较重要的并发原语,我将其归纳为一个表格,供你参考。

Linux:Futex 用户态等待与唤醒
在 Linux 中,所有 pthread 原语的实现,都是通过
futex 这个系统调用。它是全程是 fast user-space
mutex。它的实现核心是:通过操作一个 32
位的原子变量来实现等待和唤醒。等待操作会将一个线程陷入睡眠,而唤醒操作会唤醒那些操作同一个原子变量的睡眠中的线程。
这里我们简单进行一下展开,思考一下这个 futex
这个名字的含义,fast user-space mutex
翻译成中文就是快速用户空间互斥锁。我们知道,系统调用的代价是比较昂贵的,需要频繁地在用户态和内核态之间进行切换,对性能是很不友好的。
在 Linux 系统中,futex 机制并非独立存在,而是与互斥锁、条件变量等同步原语协同工作,形成 “用户态自旋 + 内核态等待” 的分层设计,以兼顾性能与功能。
比如在 Mutex 互斥锁场景下,采用 “两级等待” 策略:
- 用户态自旋阶段:尝试获取锁时先通过原子操作(如
atomic_compare_exchange)自旋尝试,避免内核调用。 - 内核态等待阶段:若自旋失败,通过 Futex 的
FUTEX_WAIT陷入内核,将线程挂起,直到其他线程通过FUTEX_WAKE唤醒。
这样多数短时间持锁场景可在用户态完成,仅在长时间竞争时陷入内核,相比纯内核互斥锁(如 spinlock)大幅降低系统调用开销。
这里有个很重要的点:判断和陷入等待,是原子的。也就是说,线程 A 在确定陷入等待时,如果关联的原子变量已经发生了变化,这个时候,不会陷入等待,而是会直接返回。这也就避免了唤醒信号的丢失。
这里我整理了 futex 的核心操作,供你参考:
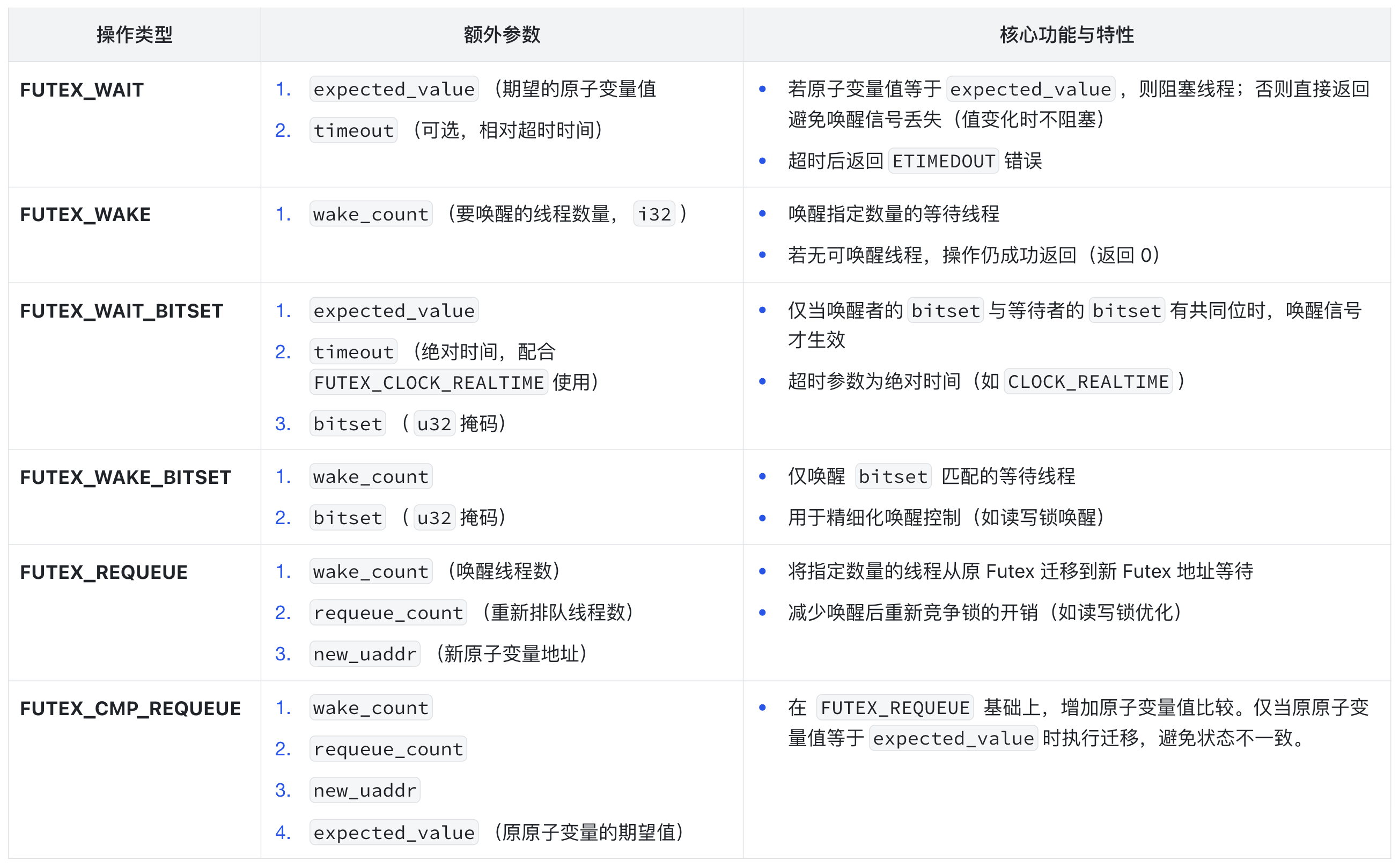
我们知道了 Linux 通过 Futex 实现等待与唤醒,内核究竟是如何实现这个等待与唤醒的能力的呢?我们需要解决三个核心问题:
- 寻址问题:内核怎么知道用户态传入的一个内存地址(虚拟地址),对应的是哪个物理锁?
- 存储问题:成千上万个线程在休眠,内核把它们存在哪里?如何高效找到它们?
- 调度问题:线程是如何从"运行"变成"睡眠",又是如何被放回 CPU 的?
1. 寻址问题:从虚拟地址到 Futex Key
用户态调用 futex_wait(uaddr, val) 时,传入的是一个
虚拟地址(Virtual
Address)。但是,不同的进程可能将同一块物理内存映射到不同的虚拟地址(共享内存场景)。如果内核只看虚拟地址,就无法让不同进程的线程锁住同一个锁。
因此,内核的第一步是将 用户态的虚拟地址 转换为内核态唯一的 Futex Key。
内核根据锁的类型(进程内私有 vs 进程间共享)生成唯一的 Key:
- 私有锁(Private):
mm_struct(当前进程的内存描述符地址) +虚拟地址。 - 共享锁(Shared):
inode(物理文件索引节点) +page_offset(页内偏移量)。
本质:Futex Key 就像是给这一块内存打了一个身份证号。无论你在哪个进程、哪个虚拟地址,只要最终指向同一块物理内存,算出来的 Key 就是一样的。
2. 存储问题:全局哈希表(Futex Hash Bucket)
解决了身份识别,接下来是存储。内核不能给每个锁都分配一个独立的等待队列(太浪费内存),也不能把所有睡眠线程放在一个大链表里(查找太慢)。
Linux 采用了一个折中方案:全局哈希表
(futex_queues)。
内核维护了一个固定大小的哈希表,每个槽位(Slot)被称为一个 Bucket(桶)。每个 Bucket 内部维护:
- 自旋锁(Spinlock):保护这个桶的操作。
- 链表(Linked List):串联挂在这个桶上的所有睡眠线程。
不管系统里有多少个 futex 锁,所有的等待线程都会根据 Futex Key 的哈希值,散列到这些有限的 Bucket 中。这意味着,不同的锁(若哈希冲突)可能会落在同一个 Bucket 里,但这没关系,链表遍历时会再次比对 Key。
3. 休眠的底层实现(futex_wait)
当线程决定休眠时,内核执行以下步骤:
- 生成 Key:根据
uaddr计算futex_key。 - 查找 Bucket:计算哈希,找到对应的
hash_bucket。 - 加锁 Bucket:获取该 Bucket 的自旋锁(Spinlock)。这是为了防止你在检查的时候,别人把你唤醒了(竞态条件)。
- 原子检查(最后一道防线):
- 这是
futex极其关键的一步。内核读取用户态uaddr的值。 - 如果值 !=
expected:说明用户态判断错了(或者在进内核途中锁变了),立即释放
Bucket 锁,返回
EWOULDBLOCK。线程不会休眠。 - 如果值 == expected:准备休眠。
- 这是
- 入队:创建一个代表当前线程的等待对象
futex_q,填入 Key 和当前线程信息(task_struct),挂入 Bucket 的链表中。 - 切换状态:将当前线程的状态从
TASK_RUNNING修改为TASK_INTERRUPTIBLE(可中断睡眠)。 - 释放 Bucket 锁:入队完成,不再需要锁 Bucket。
- 让出 CPU(Schedule):调用核心调度函数
schedule()。CPU 保存当前线程的上下文,切换到下一个任务。当前线程停在代码的这一行,不再执行,直到被唤醒。
4. 唤醒的底层实现(futex_wake)
当另一个线程释放锁并调用 futex_wake(uaddr, count)
时:
- 生成 Key:同样计算出
futex_key。 - 查找 Bucket:找到对应的哈希桶。
- 加锁 Bucket:锁住整个桶。
- 遍历链表:遍历桶里的链表,逐个检查
futex_q对象的 Key 是否与当前uaddr的 Key 相同。 - 出队与唤醒:
- 找到匹配的线程(
futex_q)。 - 将其从链表中移除。
- 调用
wake_up_process(task)。- 这个函数会将线程的状态改回
TASK_RUNNING。 - 将线程加入 CPU 的 运行队列(Run Queue)。
- 这个函数会将线程的状态改回
- 如果唤醒数量达到了
count(比如唤醒 1 个),就停止遍历。
- 找到匹配的线程(
- 释放 Bucket 锁。
- 返回用户态。
如果我们要用一句话概括 futex
的底层休眠唤醒机制,那就是:
[!IMPORTANT]
利用物理内存地址(Key)作为唯一标识,通过全局哈希表(Hash Table)对等待线程进行分片管理,最终利用内核调度器(Scheduler)的
schedule()和wake_up()能力来实现 CPU 资源的让出与回收。
macOS:公平的 pthread 与非公平的 os_unfair_lock
在 macOS 上,线程/锁的内核 syscalls(__psynch_*
等)不是公开稳定 ABI,官方要求开发者只通过
LibSystem(libc + libpthread + Objective-C/Swift
runtime 等)来访问,它们都完全实现了 pthread。
不过值得注意的是,在 macOS 10.12 版本之前,macOS 的 pthread lock
默认都是公平锁(fair locks),不过在 macOS 10.12 (Sierra, 2016) 起新增了
os_unfair_lock,它是一个不公平、阻塞型、低开销的锁,取代了已弃用的
OSSpinLock。
需要注意,os_unfair_lock
没有提供对应的条件变量或读写锁功能
。也就是说,如果需要使用条件等待或读写锁语义,仍需使用
pthread_cond_t 或 pthread_rwlock_t 等 POSIX
原语,或者使用更高层的 GCD(Grand Central Dispatch)并发模型。Apple
将os_unfair_lock 定位为替代早期的 OSSpinLock
的低级锁,以解决 OSSpinLock
存在的优先级反转问题,同时提供比 pthread_mutex
更快的性能。os_unfair_lock 内部会在必要时让出 CPU
而非自旋等待,从而避免高优先级线程饥饿,但调度上又不像
pthread_mutex 那样严格 FIFO。
Windows
Windows 提供了一系列独特的并发原语,可分为重量级内核对象、轻量级对象(如 Critical Section、SRW 锁、Condition Variable 条件变量等)和基于地址的等待机制三大类。它们在 API 设计、用法和实现上各不相同,体现了 Windows 从早期到现代的演进。
重量级内核对象:基于 HANDLE 的 wait 与 notify
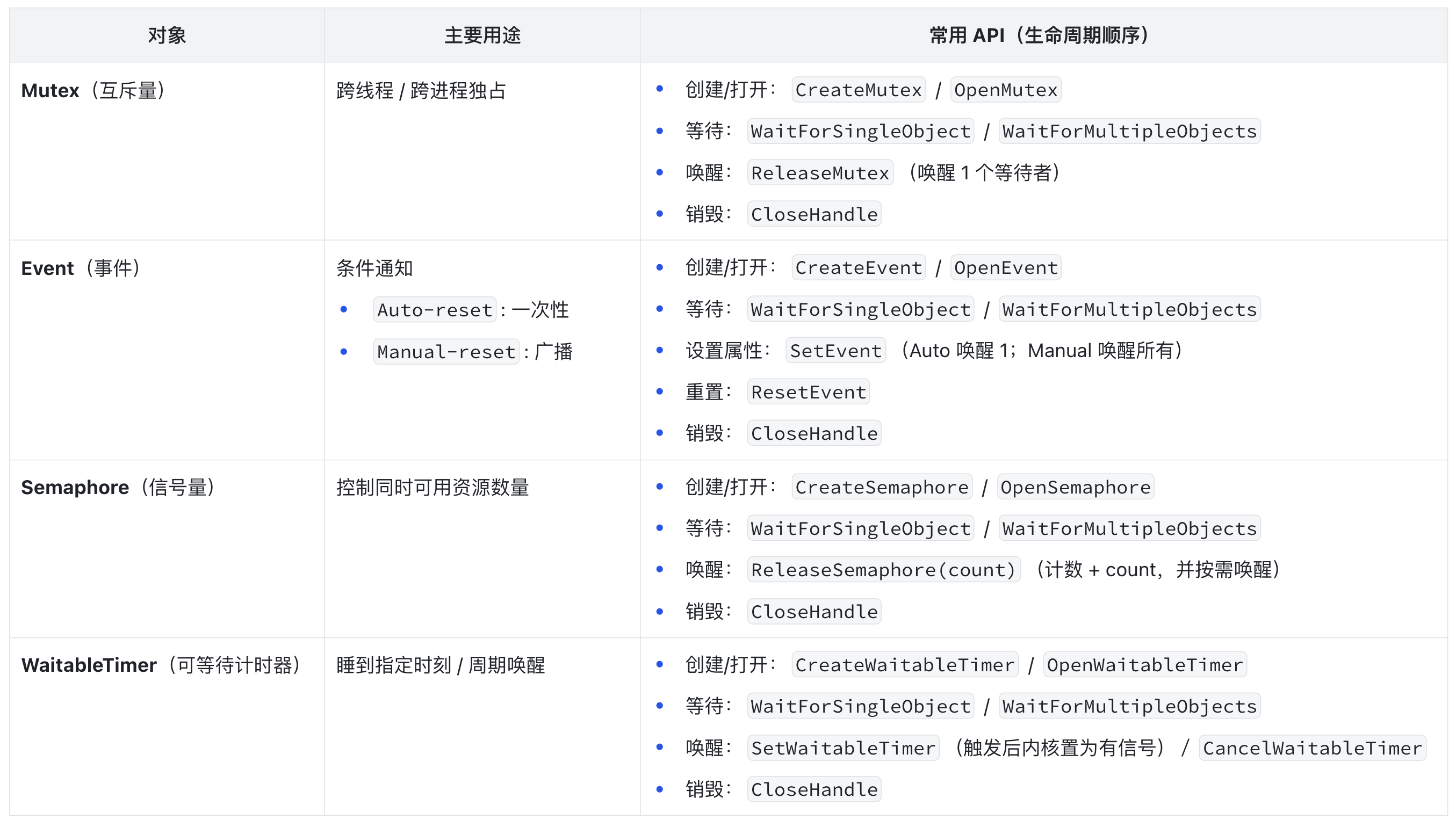
Windows 的重量级同步原语是由内核完全管理的对象,典型代表包括:Mutex(互斥量)、Event(事件)、Semaphore(信号量)、WaitableTimer(可等待计时器)等 。这些对象通过 Windows API 创建,相当于创建了一个内核对象句柄(HANDLE),类似打开文件会得到文件句柄一样 。每个对象在内核有对应的数据结构,操作系统维护其状态和等待队列。具体可以参考: 重量级内核对象。
我整理了它们的基本使用方式,供你参考:
轻量级对象:CriticalSection、SRWLock 与 ConditionVariable
"轻量级"同步原语是指不以独立内核对象形式存在、主要在用户态运作、仅在必要时调用内核的机制。
是不是已经开始有点 futex 的感觉了?🤭

CRITICAL_SECTION
它并非通过 Create 函数得到句柄,而是定义为结构体
CRITICAL_SECTION,需调用
InitializeCriticalSection()
初始化,之后直接用地址操作。本质上是一个递归互斥锁,同一个线程可以多次
Enter,内部有一个递归计数,必须对应次数的
Leave 才能完全释放。
Critical Section 在未争用情况下尝试通过用户态 Atomic 操作获取,比如 CAS 交换为当前线程,成功则进入,失败则可能先自旋尝试,依旧失败再进入内核等待。
SRW Locks
SRW Locks 不支持递归获取,同一线程如果持有写锁,再请求写锁会死锁。SRW 之所以被称为 "slim" 锁,是因为其实现相当高效,无锁时获取和释放都是用户态的 Atomic 操作,发生争用时,内核用一个优化的等待机制管理等待队列。
Condition Variable
是 Vista 时代引入的新原语,它必须搭配 Critical Section 或 SWR Lock 使用。
基于地址的等待机制:WaitOnAddress
Windows 在 8 版(2012)引入了全新的底层同步机制,与 Linux futex 非常相似,主要函数有:
WaitOnAddress(address, compare_address, _,_): 让当前线程在 address 指向的内存值满足特定条件前进入睡眠,函数会将 address 处提供的值和 compare_address 提高的值逐字节比较,如果全等,则线程睡眠,等待后续唤醒,如果不等,函数立即返回。与 futex_wait 相同,比较与睡眠是一个原子操作:在检查内存值与期望值决定休眠的过程中,若有其他线程改变了 address 或发起唤醒,系统会保证不漏掉信号。WakeByAddressSingle(address): 唤醒在指定地址上等待的一个线程。WakeByAddressAll(address): 唤醒在指定地址上等待的所有线程。
在实现上,WaitOnAddress 非常轻量,没有显式的内存对象或句柄。当线程等待时,内核只是将线程放入与那块内存地址相关联的等待队列中,唤醒时根据地址找到等待线程列表进行唤醒。
总结
通过对 3 个不同的操作系统的分析,从大的角度来讲,我们会发现它们的并发原语最重要的就是要利用原子变量,在用户态实现 3 个操作,以减少系统调用的出现,进一步提升性能。这 3 个操作可以归纳为:
- wait(&AtomicU32): 在原子变量等于期望值的时候陷入等待,否则直接返回。
- wake_one(&AtomicU32): 唤醒某个
wait()在当前变量的线程。 - wake_all(&AtomicU32): 唤醒所有
wait()在当前变量的线程。
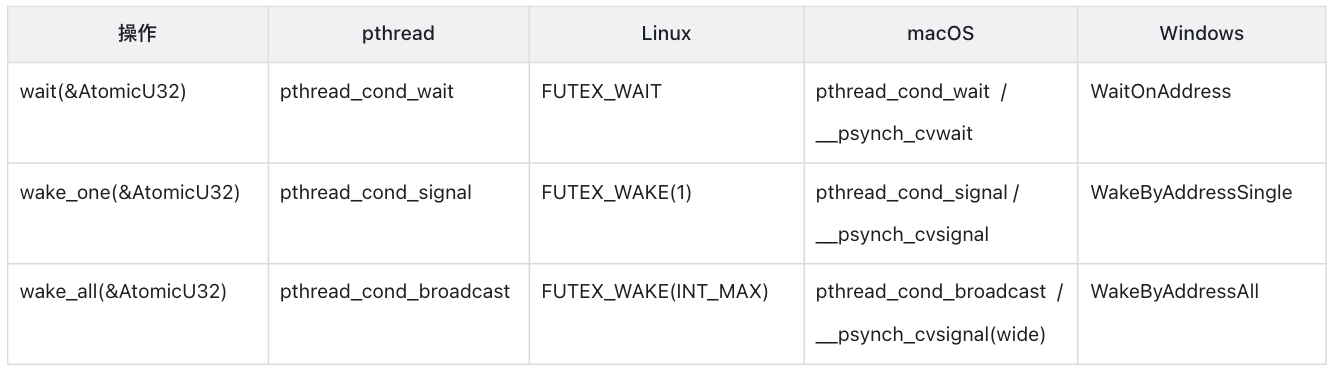
所以下一步如果我们想在编程语言的层面上(Rust)实现自己的
Mutex、REMutex 和
CondVar,第一步就是需要针对不同的操作系统实现一套
wait/wake_one/wake_all
以屏蔽不同操作系统的实现差异,幸运的是 Rust Atomics and Locks 的作者 Mara Bos 已经帮我们实现好了:atomic-wait。下篇,我们就利用这个
crate,来一步步手写一个自己的 Mutex!
Happy Coding! Peace~




