
本篇将进入 Go 语言中关于锁的底层原理的探讨,笔者有幸阅读过 Mara Bos 的 《Rust Atomics and Locks》,该书对锁这一概念和底层原理进行了非常详尽的探讨,并且给出了 Rust 中 SpinLock、Mutex、RWMutex、Channel 和 Arc 等基础并发工具的手写实战案例,对于想更加深入理解并发编程尤其那些想手写并发工具的读者,非常推荐阅读该书。
特此声明,本篇是笔者基于 Go 1.25.3 版本源码、并与 Google Gemini 3Pro 共创所作,非常庆幸在当今 AI 时代下获取知识已是如此便利,且也为学习者从第一性原理理解所学知识大大降低了门槛。不过本篇的篇章安排和叙述逻辑,均由笔者把控和审阅,欢迎放心阅读。
结论先行
本篇我们将探讨 Go 语言中的各种"锁"的底层实现原理,包括
Mutex、RWMutex、WaitGroup 和
Once 。它们都离不开两个核心基础:atomic 和
sema:
atomic即原子变量,是一种硬件层面加锁的机制,可以保证基本类型在高并发下的并发安全性,实现原子操作。sema全称 semaphore,也叫信号锁 / 信号量锁,它的核心是一个uint32类型的值,含义是同时可并发的协程数量。在 Go 语言里面,每个seam背后都对应一个semaRoot结构体。
我们先给出上述几种并发工具的简要概述,后文再进行详细阐述:
Mutex:互斥锁,只能有一个持有者。- 正常模式:得到锁返回,得不到锁自旋,自旋多了就饥饿。
- 饥饿模式:不自选,直接入队等待。依次从队里唤醒协程并授予锁。
RWMutex:读写锁,只能一个写,可以同时多个读。WaitGroup:一组协程等待另外一组协程全部执行完毕再执行。Once:控制一段代码在并发中只执行一次。Cond:条件变量,允许多个 Goroutine 等待某个条件成立后被唤醒,常用于处理生产者-消费者模型。
1. Go 锁的两大基础
1.1 原子操作
Go 在 sync/atomic
包提供了一系列基本类型的原子操作,使用这些操作,可以保证基本类型在高并发下的并发安全性,实现原子操作。
- SwapInt32
- CompareAndSwapInt32
- AddInt32
- LoadInt32
- StoreInt32
1 | // AddInt32 atomically adds delta to *addr and returns the new value. |
查看 AMD64 的汇编时,我们会发现其中有一个 LOCK
指令:
1 | // uint32 Xadd(uint32 volatile *val, int32 delta) |
可以再看一下 ARM64
的汇编代码,我们会发现其中有:LDADDALW、LDAXRW
和 STLXRW 指令:
1 | TEXT ·Xadd(SB), NOSPLIT, $0-20 |
概括来说:
[!IMPORTANT]
原子操作的底层实现依赖于 86 的
lock前缀或 ARM 的LL/SC,而这二者又依赖于硬件级别的协同机制,其核心是通过 缓存一致性协议、总线仲裁 和 指令集层面的特殊支持 来保证多核环境下的原子性和内存顺序。
对于原子操作的底层原理和硬件层面的细节,感兴趣的读者可以阅读我这两篇笔记:
1.2 sema 锁
1.2.1 概述
- sema 锁全称 semaphore,也叫信号锁 / 信号量锁。
- sema 的核心是一个
uint32类型的值,含义是同时可并发的协程数量。 - 每一个 sema 锁都对应一个
semaRoot结构体。 semaRoot中有一个平衡二叉树用于协程排队。
1.2.2 数据结构
在 internal/sync/mutex.go#L20
定义了 Mutex 的数据结构,如下:
1 | // A Mutex is a mutual exclusion lock. |
其中第二个元素 sema,便是一个 sema 锁,它本质上是一个
semaRoot 结构体的值。
semaRoot 定义在 runtime/sema.go#L40:
1 | // Asynchronous semaphore for sync.Mutex. |
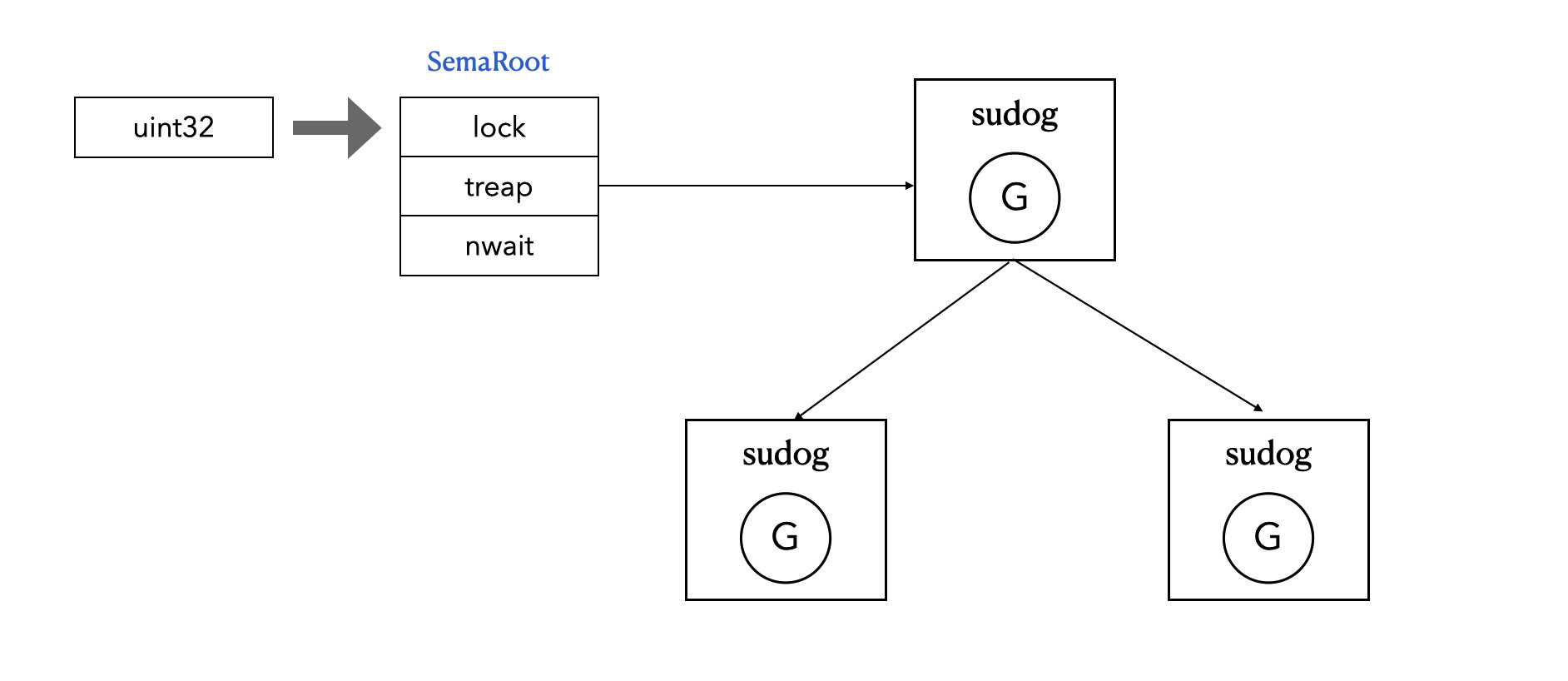
1.2.3 操作
当 unit32 > 0 时,表示可以并发的协程个数
- 获取锁:sema - 1, 获得锁成功
- 释放锁:sema + 1,释放锁成功
当 unit32 = 0 时,表示没锁了,sema 锁退化成一个专用的休眠队列
- 获取锁:进入堆树等待,协程休眠;
- 释放锁:从堆树中取出一个协程并唤醒
1.2.4 semeacquire()
semaacuqire()
尝试递减计数器,失败则创建 sudog
加入等待队列并休眠,等待被唤醒。
- sema > 0:sema --
- sema = 0:将协程放入堆树中等待,并休眠
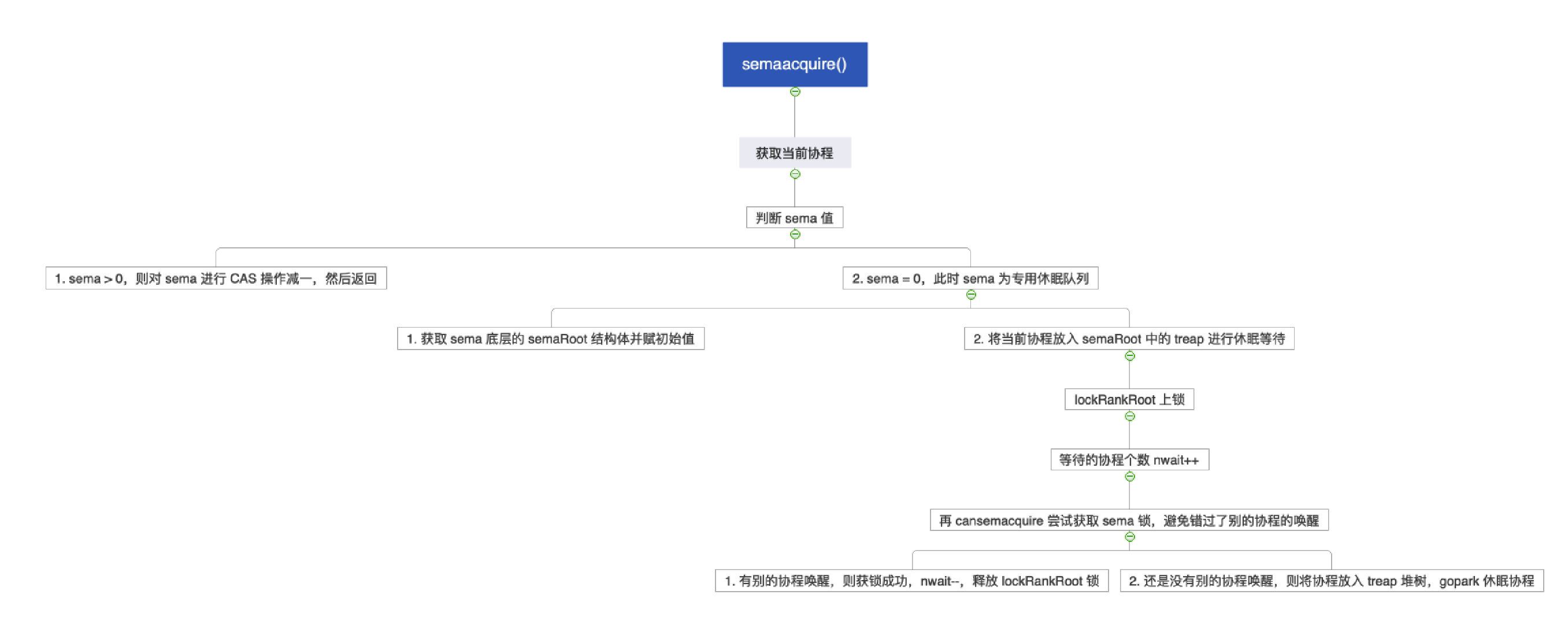
1 | func semacquire1(addr *uint32, lifo bool, profile semaProfileFlags, skipframes int, reason waitReason) { |
1.2.5 semarelease()
semarelease()
递增计数器,如果有等待者则从队列中取出一个 sudog
并唤醒对应的 goroutine,handoff 模式下直接移交锁并让出
CPU。
- 无等待中的协程:直接返回
- 有等待中的协程:从堆树中出队一个协程,唤醒,并调度到当前 P 的 runq 中
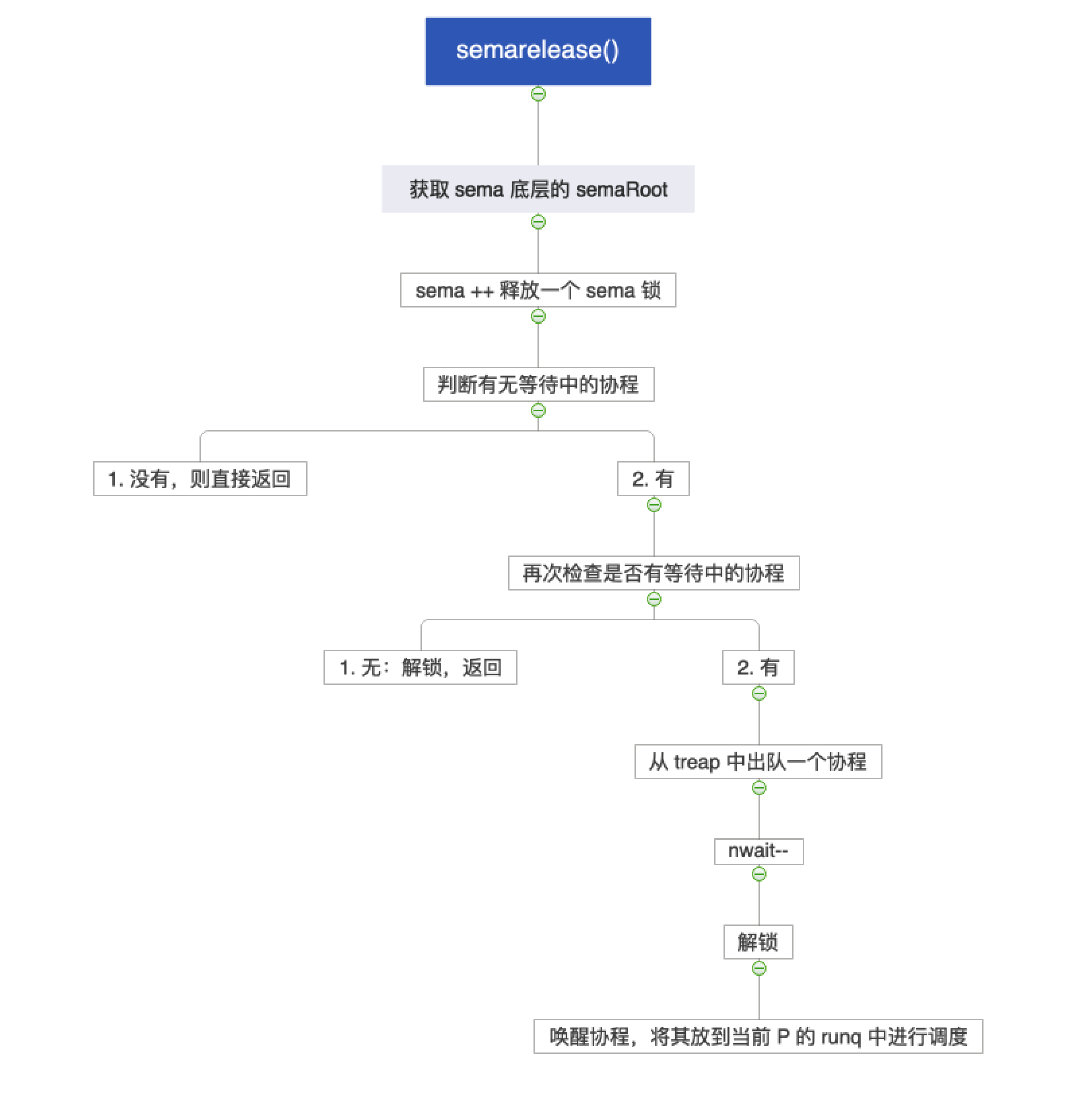
1 | // semrelease1 释放一个信号量,如果有等待者则唤醒一个 goroutine |
1.2.6 深度理解
sema 是 Go sync.Mutex 连接 Go
运行时 (Runtime) 和 操作系统 (OS) 的关键枢纽。
sema 就是用来解决"拿不到锁的 Goroutine
到底去了哪里、怎么睡、怎么醒"的关键问题。
我们要从以下三个层次由浅入深地理解 sema:
- 数据结构层:它是怎么存储等待者的?
- 运行时层 (Runtime):Go 如何高效管理成千上万个锁?
- 操作系统层 (OS):底层的
futex到底在做什么?
1.2.6.1 第一层:它在内存中是什么?
在 sync.Mutex 的定义中:
1 | type Mutex struct { |
前面我们讨论过,sema
本质上只是一个内存地址(Address)。
- 作为 Key:Go 运行时并不关心
sema变量里存的具体数值是多少(虽然它确实会变),运行时真正关心的是&sema(这个变量在内存中的地址)。 - 全局哈希表:Go
运行时维护了一个全局的哈希表(
semTable),在这个表中:- Key
&sema(Mutex 中 sema 字段的内存地址)。 - Value 一个等待队列(平衡二叉树),里面躺着一个个正在睡觉的 Goroutine。
- Key
1 | var semtable semTable |
为什么这么设计? 如果每个 Mutex 都向操作系统申请一个专门的内核信号量对象,开销太大了。Go 程序中可能有数百万个 Mutex,通过把它们映射到一个固定大小的全局哈希表中,Go 实现了极高的扩展性。
1.2.6.2 第二层:运行时调度 (GMP)
当 state 字段判断需要阻塞时,Go 会调用
runtime_SemacquireMutex(&m.sema, ...)(其实背后就是上面提到的
semacuqire())。这背后发生了什么?这是与 GMP
模型 交互的核心。
当 state 字段判断需要阻塞时,Go 会调用
runtime_SemacquireMutex(&m.sema, ...)。这背后发生了什么?这是与
GMP 模型 交互的核心。
1. 包装:从 G 到 Sudog
Goroutine (G) 是不能直接挂在链表上的。Go
使用了一个中间结构体叫 sudog。
- 当一个 G 需要阻塞时,运行时会创建一个
sudog,把这个 G 包装进去。 - 这个
sudog代表了"一个在特定信号量上等待的 G"。
2. 入队与休眠
- 计算哈希:根据
&sema的地址,算出它在全局semTable中的位置。 - 挂载:把包装好的
sudog挂到该位置的 Treap 尾部。 - 切出 (Park):
- 调用
goparkunlock。 - 关键点:当前的 M (系统线程) 会断开与当前 G 的关系。
- G 的状态从
Running变为Waiting。 - M 并没有睡觉,它会去 P (处理器) 的本地队列里找下一个可运行的 G 来执行。
- 这就是 Go 高并发的精髓:用户层面的阻塞锁,并没有阻塞底层的系统线程(除非没有其他工作可做)。
- 调用
3. 唤醒 (Handoff)
当 Unlock 调用
runtime_Semrelease(&m.sema) (即
semarelease())时:
- 查找:再次根据
&sema地址去全局哈希表里找。 - 出队:取出链表头部的
sudog。 - 调度:
- 把
sudog里的 G 取出来。 - 将 G 的状态从
Waiting改为Runnable。 - 把它扔到当前 P 的运行队列或者全局运行队列中,等待被 M 执行。
- 把
1.2.6.3 第三层:操作系统原语
这就到了物理实现的底座了。如果 M 发现没有别的 G 可以执行了,或者 Go 运行时本身的某些同步需要,它最终必须依赖操作系统的能力来让 CPU 停下来。
在 Linux 平台上,sema 的底层实现依赖于 Futex
(Fast Userspace Mutex)。
Futex 是 Linux
内核提供的一种机制,它的核心理念是:即使需要内核介入,也要尽量减少陷入内核的次数。
它包含两个操作:
- User Space Check
(用户态检查):先检查内存中的一个整数(就是
sema的值)。如果条件满足(比如有信号),直接走人,完全不涉及内核。 - Kernel Wait (内核态等待):只有当条件不满足时,才发起系统调用(System Call),让内核把线程挂起。
在 runtime/os_linux.go
中,你会看到类似这样的汇编或封装调用:
- 休眠 (
futexsleep): 调用futex(addr, FUTEX_WAIT, val, ...)。 意思就是:“内核老兄,请你看看addr这个内存地址的值是不是val?如果是,就把我(当前线程 M)挂起;如果不是,说明中间有人改过(可能有信号了),那我就不睡了,直接返回。” - 唤醒 (
futexwakeup): 调用futex(addr, FUTEX_WAKE, count, ...)。 意思就是:“内核老兄,在这个地址上睡觉的线程,请帮我叫醒count个。”
关于 Futex 的更多细节,推荐阅读笔者整理的:Rust 原理丨操作系统并发原语。
1.3 总结
atomic 和 sema 是 Go 并发的"阴阳二元":
| atomic | sema | |
|---|---|---|
| 哲学 | 乐观(假设无竞争) | 悲观(接受竞争) |
| 机制 | 硬件指令 | OS/Runtime 调度 |
| 速度 | 极快(纳秒) | 较慢(微秒) |
| 能力 | 状态变更 | 休眠/唤醒 |
| 使用 | 所有路径 | 慢速路径 |
| 目标 | 性能 | 正确性 + 公平性 |
所有 Go 的同步原语都是这两者的不同组合方式,遵循 "Fast Path with Atomic, Slow Path with Semaphore" 的设计模式!🎯
用一句话总结就是:
[!IMPORTANT]
Atomic 提供无锁的快速状态管理(CAS、加减),sema 提供有竞争时的 goroutine 休眠/唤醒机制,两者组合实现"乐观尝试 + 悲观等待"的高效并发模型。
graph LR
subgraph "性能层级"
A[atomic
纳秒级
99% 场景]
B[sema
微秒级
1% 竞争]
end
A -->|无竞争| Fast[Fast Path]
A -->|低竞争
自旋| Spin[Spin]
B -->|高竞争| Slow[Slow Path
休眠/唤醒]
style A fill:#ccffcc
style B fill:#e1f5ff
style Fast fill:#90EE90
style Slow fill:#FFB6C1
2. sync.Mutex
2.1 概述
Go 语言的 sync.Mutex
是一种并发原语,旨在保证同一时间只有一个 Goroutine
可以访问共享资源,从而实现互斥(Mutual
Exclusion)。它的底层实现是基于两个核心字段和一套复杂的自旋、排队和唤醒逻辑,以在性能和公平性之间取得平衡。
sync.Mutex
类型只有两个公开的指针方法:Lock() 和
Unlock()。
m.Lock():锁定当前的共享资源m.Unlock():进行解锁
2.2 数据结构
前面我们已经展示过 sync.Mutex 的数据结构了:
1 | type Mutex struct { |
Go 语言的 sync.Mutex 结构体非常精简,仅包含两个字段:
state (int32):这是一个 32 位整数,用于原子地表示互斥锁的当前状态。通过不同的位(Bit)来编码多种信息,实现了极高的效率。sema (uint32):这是我们前面提到的 sema 锁,用于实现 Goroutine 的阻塞和唤醒机制。当 Goroutine 无法立即获取锁时,它会在该信号量上阻塞休眠,等待锁的持有者释放信号量将其唤醒。
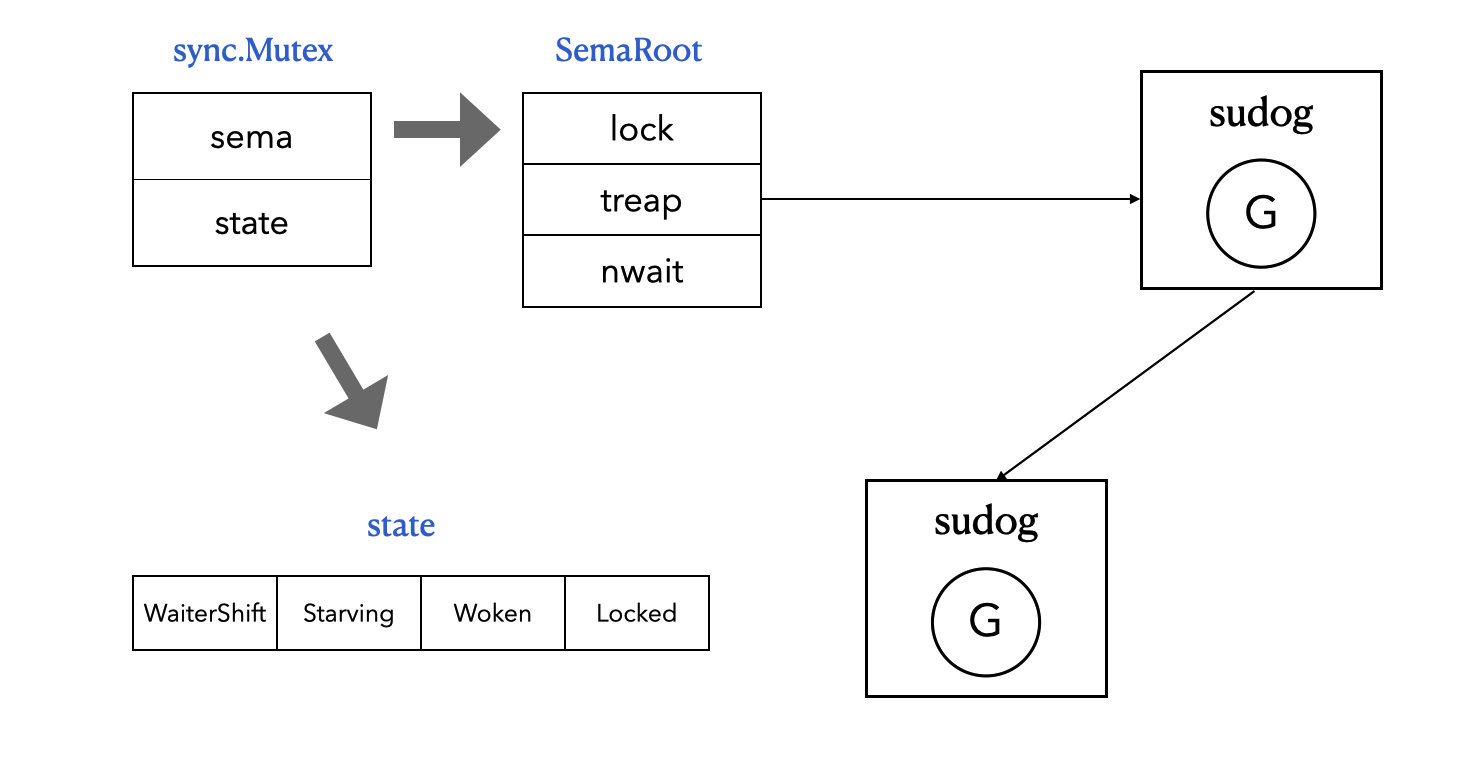
如何理解这 2 个字段呢?在我看来:
state字段是在用户态(User Space)解决"谁拿到锁"的逻辑。sema字段是用来解决"拿不到锁的 Goroutine 到底去了哪里、怎么睡、怎么醒"的物理问题。
2.3 state 字段
sema 前面已经介绍得非常清楚了,下面我们重点来分析一下
state 字段。
为了最大化性能,state
字段通过位运算存储了四个关键信息,这些信息共同决定了锁的运行模式和竞争程度:
| 位 (Bit) | 含义 | 解释 |
|---|---|---|
| 0 | Locked |
1 表示已加锁,0 表示未加锁。 |
| 1 | Woken |
1 表示已有 Goroutine 被唤醒(正在尝试获取锁),此时不需要再唤醒其他人。 |
| 2 | Starvation |
1 表示进入饥饿模式(Go 1.9+ 引入的关键优化)。 |
| 3-31 | WaiterCount |
记录当前有多少个 Goroutine 在排队等待。 |
如下图所示:
1 | 31 3 2 1 0 |
使用一个 int32 来存储这么多信息有三大好处:
满足多个状态修改的原子性:所有状态必须在一个原子操作中一起更新,避免状态不一致。
1
2
3
4
5
6// 错误的设计(如果分开存储)
mutex.locked = true // ← 这里可能被中断
mutex.waiterCount++ // ← 状态不一致的窗口期
// 正确的设计(单个原子操作)
atomic.CompareAndSwapInt32(&m.state, old, new) // 一次性更新所有状态CPU Cache Line 效率:一个 int32 只占 4 字节,极度缓存友好,所有状态信息在同一个 cache line 中,读取/修改只需要一次内存访问,避免 false sharing。
Fast Path 快速路径优化:在无竞争情况下,即 state == 0 表示完全空闲(无锁、无等待、无标志),一次 CAS 就能完成加锁,编译器可以内联这段代码,这是 99% 无竞争场景的关键优化。
1
2
3
4
5
6
7
8
9
10func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
// Slow path (outlined so that the fast path can be inlined)
m.lockSlow()
state 的状态转换示例:
1 | // 初始状态 |
2.4 上锁
- 正常模式:获得锁直接返回,得不到锁就自旋,自旋多次后进入 sema 队列中休眠,超过 1ms 就转为饥饿模式;
- 饥饿模式:
- 新来的协程不自旋,直接今年入 sema 队列中;
- 依次从 sema 队列中唤醒协程,并直接获得锁,当 sema 队列为空时,跳回正常模式
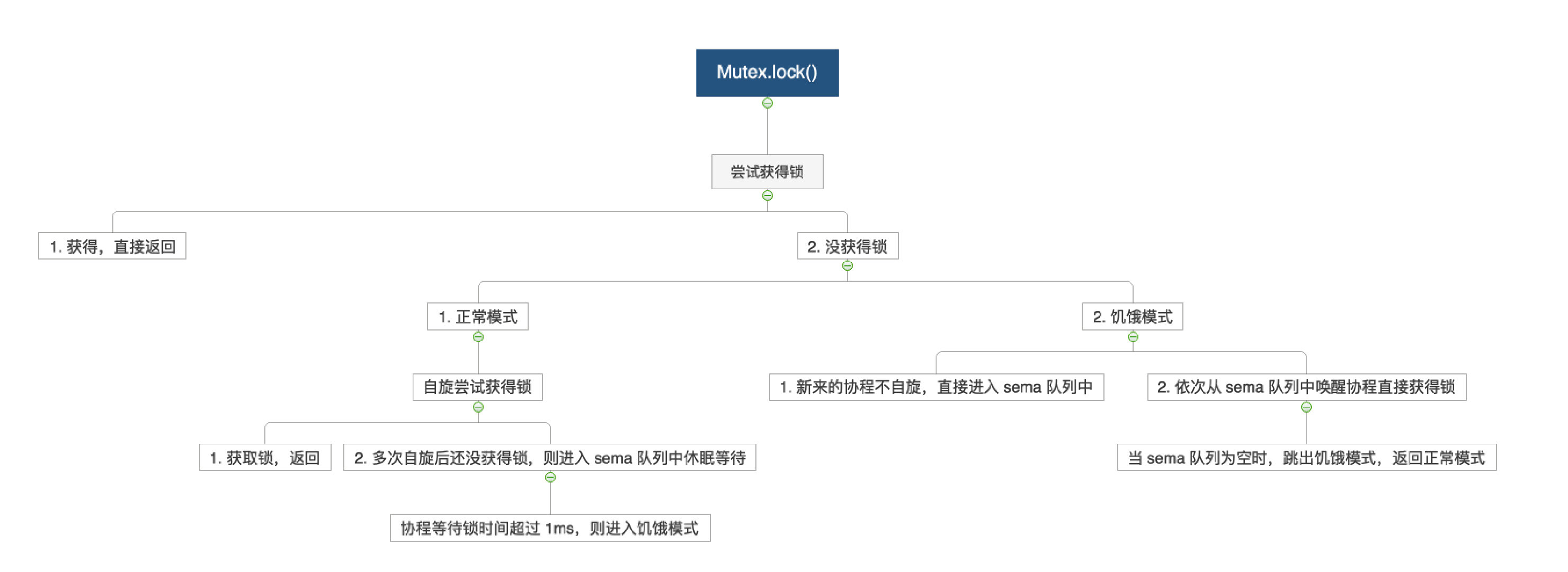
上锁的源码位于 sync/mutex.go#L61,代码如下所示:
1 | func (m *Mutex) lockSlow() { |
关键步骤:
- 自旋(Spinning):在正常模式且满足条件时自旋等待
- 设置 mutexWoken:告诉 Unlock 不要唤醒其他 goroutine
- 更新等待者计数:增加 waiter 数量
- 进入信号量等待:调用 runtime_SemacquireMutex
- 饥饿模式切换:等待时间超过 1ms 切换到饥饿模式
自旋条件:
1 | const ( |
2.5 解锁
- 正常模式:解锁后新来的协程和 sema 队列中的协程一起竞争;
- 饥饿模式:新来的协程直接入 sema 队列,依次从 sema 队列中唤醒协程并直接交付锁;
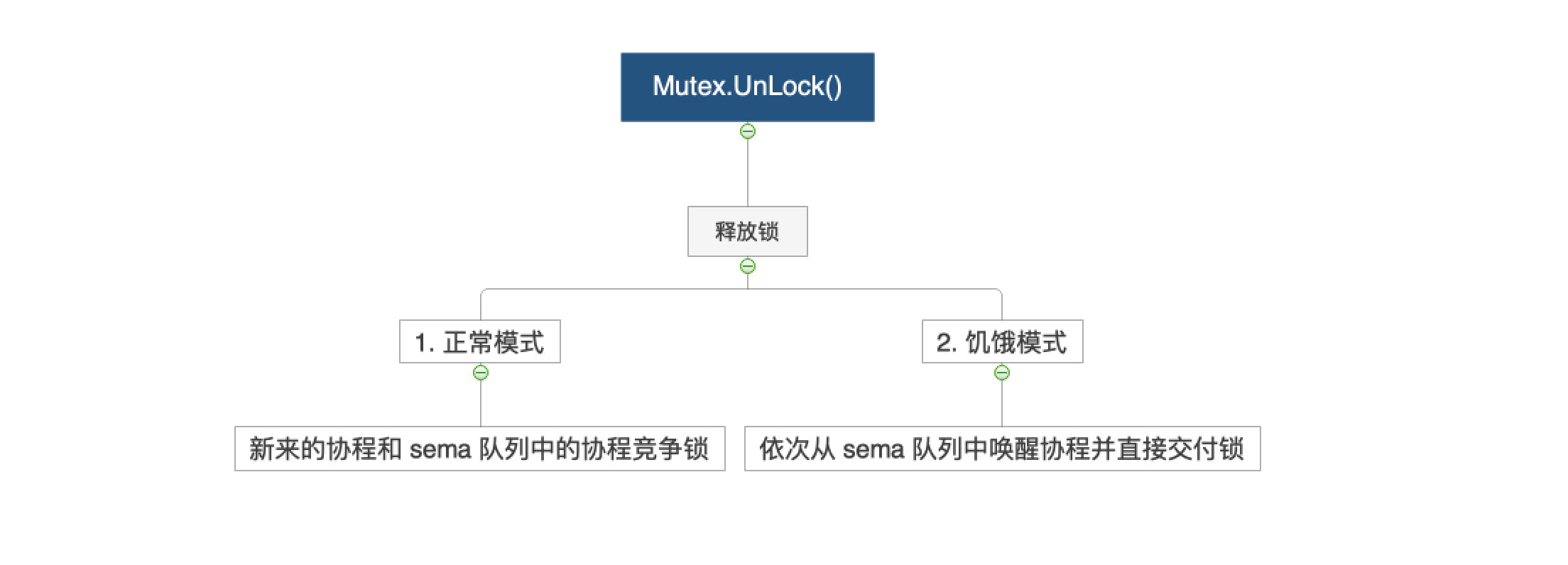
上锁的源码位于 sync/mutex.go#L202,代码如下所示:
1 | func (m *Mutex) Unlock() { |
关键步骤:
- 原子清除锁定位:atomic.AddInt32(&state, -mutexLocked),结果为 0 则直接返回
- 检查是否需要唤醒:无等待者/已有锁持有者/已有被唤醒者则跳过
- 正常模式:设置 mutexWoken 标志 + 减少等待者计数 + semrelease(handoff=false) 唤醒但需重新竞争
- 饥饿模式:semrelease(handoff=true) 直接移交所有权 + goyield() 让出 CPU
2.6 总结
到这里,我们已经深入探析了 sync.Mutex
的核心机制和底层数据结构。归纳下来,Go 的 Mutex
实现,本质上是通过 atomic 乐观抢占为主、sema
信号量排队休眠为辅,辅以饥饿/公平模式动态切换,来最大化锁的性能与公平性。
精髓:抢得快靠 "atomic",等得稳靠 "sema"。
- 快速路径(Fast Path): 绝大多数情况下,goroutine
利用
atomic硬件指令快速抢占锁,纳秒级切换,无需操作内核。 - 慢速路径(Slow Path): 发生竞争时,goroutine 通过
sema跳入排队睡眠,只有唤醒才参与下一轮抢占。这部分涉及用户/内核态切换,耗时微秒级,但能极大减少资源消耗与 CPU 干扰。 - 三层状态编码: 利用一个
int32整数位操作,节省空间同时高效追踪锁的"持有""等待""唤醒""饥饿"等复杂状态。 - 饥饿模式保障公平性: 当长时间得不到锁时,自动切换到饥饿模式,保证队列排头的人下一次必定抢到锁,杜绝饥饿和“惊群”。
3. sync.RWMutex
3.1 概述
- 同时只能有一个 Goroutine 能够获得写锁
- 同时可以有任意多个 Gorouinte 获得读锁
- 同时只能存在写锁或读锁(读和写互斥)
sync.RWMutex 提供了 4 个方法:
rwm.RLock():上读锁rwm.RUnlock():解读锁rwm.Lock():上写锁rwm.Unlock():解读锁
3.2 数据结构
sync.RWMutex 定义在 sync/rwmutex.go#L39,如下所示:
1 | type RWMutex struct { |
w:写锁,拿到它直接有了上写锁的资格,有可能还需要等待读锁全部释放writerSem:写协程等待队列readerSem:读协程等待队列readerCount:正值表示正值读的协程个数,负值表示加了写锁;readerWait:上写锁应该等待读协程的个数
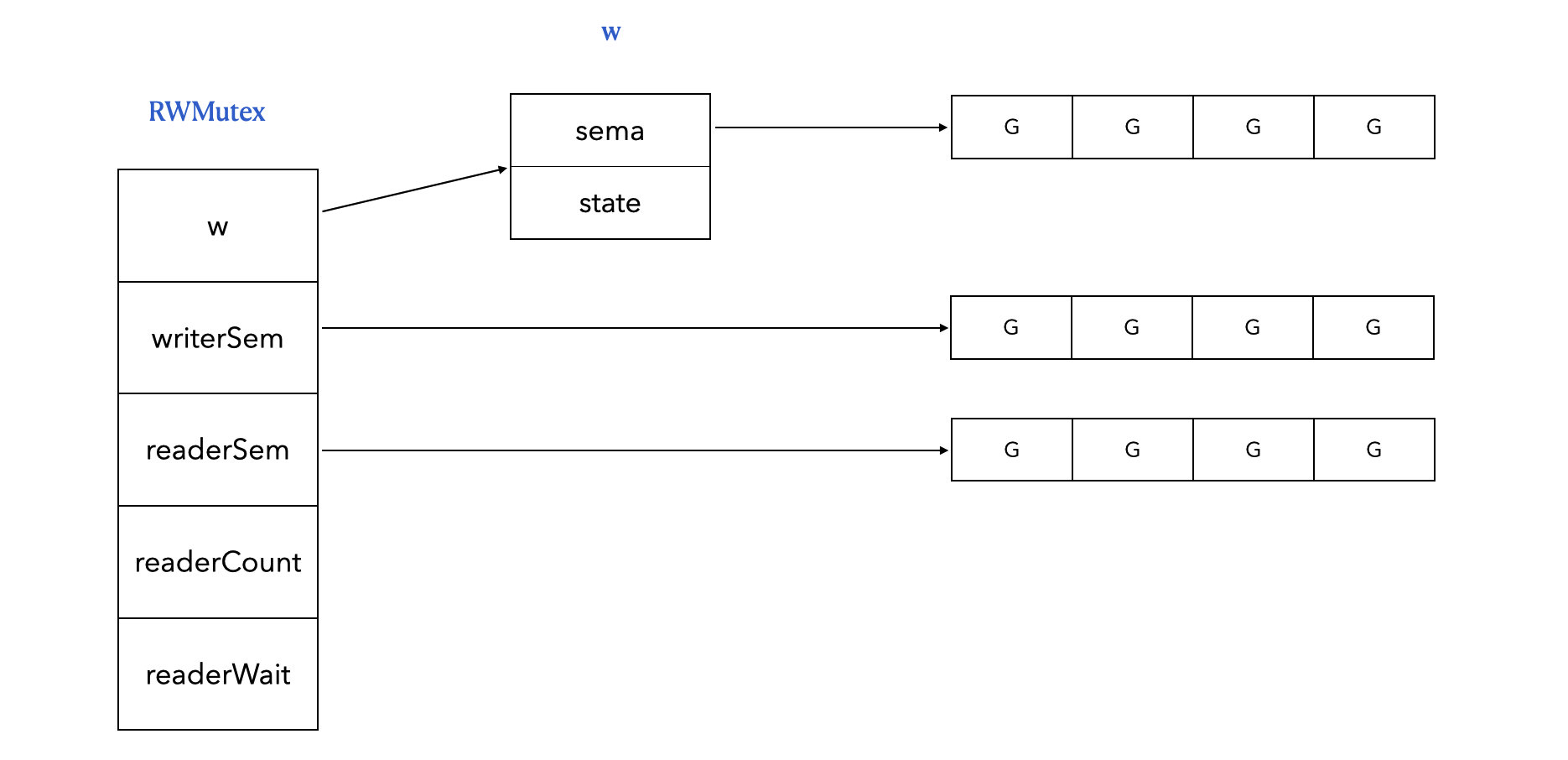
3.3 上写锁

1 | const rwmutexMaxReaders = 1 << 30 // 最多的读者个数,是一个非常大的值 |
3.4 解写锁

1 | func (rw *RWMutex) Unlock() { |
3.5 上读锁

1 | func (rw *RWMutex) RLock() { |
3.6 解读锁
1 | func (rw *RWMutex) RUnlock() { |
3.7 总结
总的来说,Go 的 RWMutex 遵循的是写者优先(Writer
Priority) 原则,防止写者饥饿。四个核心方法的要点总结如下:
上写锁:竞争写锁,看看有无读协程:
没有读协程的话直接获得写锁;
有读协程的话,阻塞后来的读协程,等待当前读协程释放;
解写锁:解写锁,唤醒 readerSem;
上读锁:readerCount++,并检查是否有写锁:
没有写锁,则上锁完毕;
有写锁,则陷入 readerSem,等待写锁释放;
解读锁:readerCount --,并检测是否有写协程被阻塞:
无,则返回;
有,则 readerWait --;判断是否是最后一个释放读锁的协程:
- 不是,则返回;
- 是,则唤醒 writerSem,解锁完毕;
4. sync.WaitGroup
4.1 概述
WaitGroup 等待一组 Goroutine 完成。主 Goroutine 调用 Add 来设置要等待的 Goroutine 的数量。然后每个 Goroutine 运行并在完成时调用 Done。同时,主 Goroutine 可以使用 Wait 来阻塞,直到所有 Goroutine 完成。
wg.Add(delta int):Add 将 delta(可能为负)添加到 WaitGroup 计数器。如果计数器变为 0,所有在 Wait 时阻塞的 Goroutine 将被释放。如果计数器变成负值,Add 会 panic。wg.Done():当 WaitGroup 同步等待组中的某个 Goroutine 执行完毕后,设置这个 WaitGroup 的 counter 数值减 1。wg.Wait():表示让当前的 Goroutine 等待,进入阻塞状态。一直到 WaitGroup 的计数器为 0,才能解除阻塞,这个 Goroutine 才能继续执行。
4.2 数据结构
sync.WaitGroup 源码位于 sync/waitgroup.go#L48:
1 | type WaitGroup struct { |
重点是看 state 字段:
1 | 63 33 32 31 0 |
为什么要用一个字段?
- 原子操作:可以用一次原子操作同时读写两个值
- 避免竞态:counter 和 waiter 总是一致的快照
- 零分配:整个 WaitGroup 只需 16 字节(8+4+padding)
1 | state := wg.state.Load() |
4.3 wg.Wait()

1 | func (wg *WaitGroup) Wait() { |
4.4 wg.Add()

1 | func (wg *WaitGroup) Add(delta int) { |
4.5 wg.Done()
1 | func (wg *WaitGroup) Done() { |
5. sync.Once
5.1 概述
sync.Once 可以让并发中的一段代码只执行一次;
- once.Do(func):执行某一函数,该函数在多个协程中,只会被执行一次。
5.2 数据结构
sync.Once 的源码位于 sync/once.go#L20:
1 | type Once struct { |
done:表示当前 once 是否已经执行过了;m:锁
5.3 once.Do()
其实就一个简单的双重检测逻辑。

1 | func (o *Once) Do(f func()) { |
6. sync.Cond
6.1 概述
从第一性原理来看,sync.Cond
解决的是轮询(Polling) vs 事件通知(Event
Notification)的问题。
当你需要等待某个特定条件(比如"队列不为空"或"缓冲区有空位")满足时,你只有两种选择:
- 轮询 (Spinning):在一个死循环里不断加锁检查。
- 通知 (Cond):我去睡觉,等条件满足了,你把我叫醒。
Go 的 sync.Cond
实现非常独特,它没有直接使用操作系统层面的 Condition Variable(如
Pthread Cond),而是自己在 Runtime
层面实现了一套基于票号(Ticket)的通知队列。
sync.Cond 提供了 3 个核心方法:
c.Wait():阻塞,等待条件发生c.Signal():唤醒一个等待的协程c.Broadcast():唤醒所有等待的协程
使用方式:
1 | c.L.Lock() // 1. 先加锁(保护条件 condition) |
6.2 数据结构
sync.Cond 源码位于 sync/cond.go#L37:
1 | type Cond struct { |
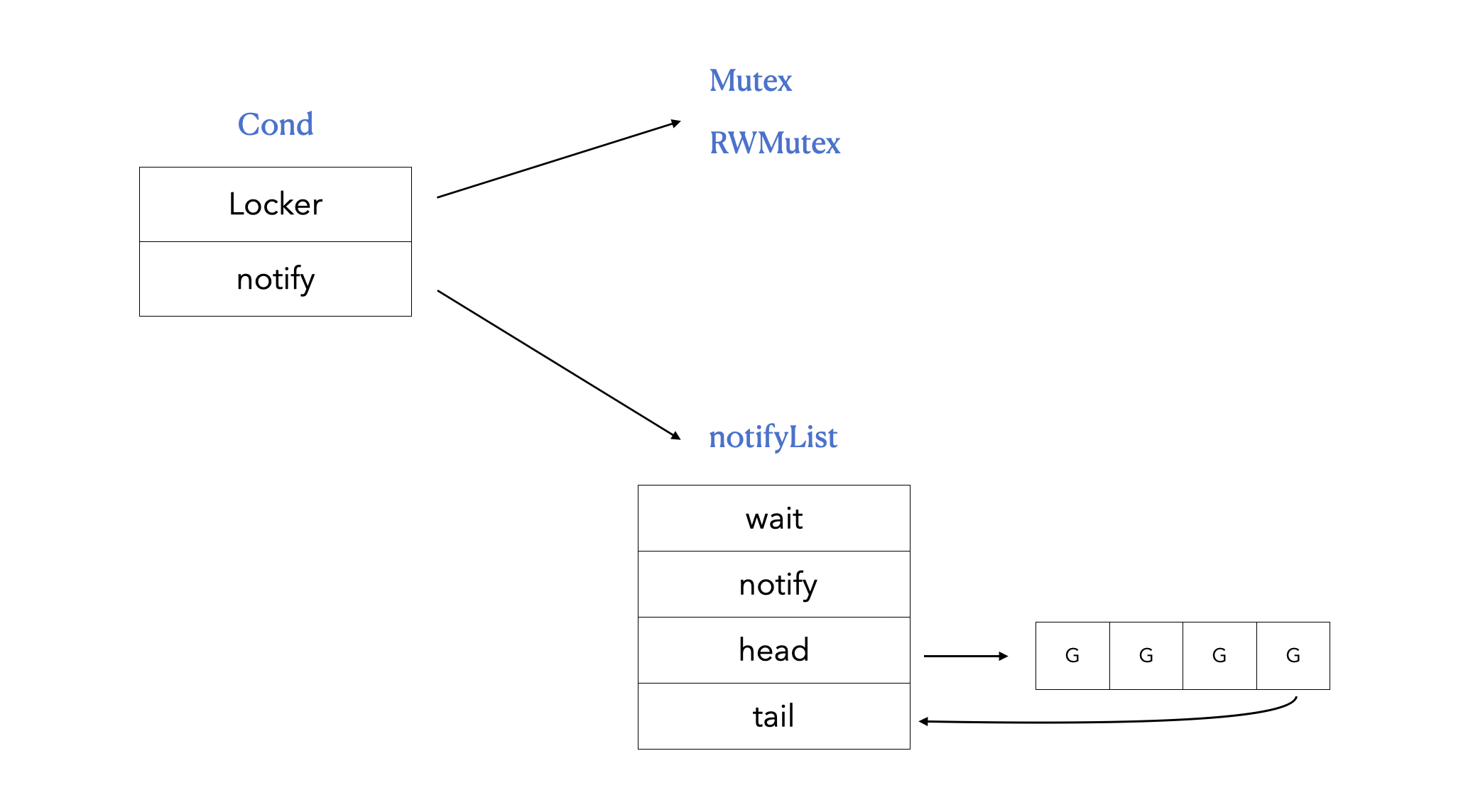
理解 sync.Cond
的关键,在于理解它如何解决虚假唤醒和消息丢失的问题。Go
使用了一种类似银行排号系统的逻辑。
1 | wait = 5, notify = 2 |
6.3 c.Wait()
当一个 Goroutine 调用 Wait()
时,发生了以下严密的步骤:
- 拿号 (Ticket Allocation): 调用
runtime_notifyListAdd。这本质上是一个原子操作,将notifyList中的wait计数器加 1,并返回当前的序列号(Ticket)。 - 解锁 (Unlock): 调用
c.L.Unlock()。必须先拿号,再解锁。这保证了即使你在解锁后、睡觉前,有人发送了信号,你的号也已经排进去了,不会错过通知。 - 睡觉 (Block): 调用
runtime_notifyListWait(Ticket),把自己挂起,等待有人喊"第 100 号"或者"所有人"醒来。 - 重新加锁 (Lock): 当被唤醒后,
Wait函数返回前,会自动调用c.L.Lock()。
1 | func (c *Cond) Wait() { |
6.4 c.Signal()
当调用 Signal() 时:
- 调用
runtime_notifyListNotifyOne。 - 它会查找
notifyList中最早那个还没被唤醒的 Ticket(比如第 99 号已醒,现在叫第 100 号)。 - 通过
sema(信号量)精确唤醒持有该 Ticket 的那个 Goroutine。
1 | func (c *Cond) Signal() { |
6.5 c.Broadcast()
当调用 Broadcast() 时:
- 调用
runtime_notifyListNotifyAll。 - 它不需一个一个叫,而是直接记下当前的
wait计数器值(比如当前排到了 150 号)。 - 它会唤醒从"当前已唤醒号"到"150 号"之间的所有 Goroutine。
1 | func (c *Cond) Broadcast() { |
6.6 总结
graph TB
A[sync.Cond 核心机制]
A --> B[Ticket 系统
wait & notify]
A --> C[三步原子操作
Add→Unlock→Wait]
A --> D[按序唤醒
FIFO]
B --> E[防止丢失唤醒]
C --> F[保证 happens-before]
D --> G[公平性]
style A fill:#ffcccc
style B fill:#e1f5ff
style C fill:#fff4e1
style D fill:#ccffcc
sync.Cond 的核心设计:
- Ticket 系统:基于票号的通知机制,防止丢失唤醒
- 三步原子操作:Add→Unlock→Wait,顺序不能错
- 必须循环 Wait:防止虚假唤醒和竞态条件
- 关联 Locker:Wait 自动释放和重新获取锁
7. 排查锁异常问题
7.1 锁拷贝 go vet
1 | m := sync.Mutex{} |
这个时候,可以用 Go 提供的 go vet
工具来检查是否存在锁拷贝问题:
1 | ➜ go vet main.go |
go vet还能检测可能的 bug 和可疑的构造。
7.2 数据竞争问题 - go build -race
1 | // 此处 i 有并发问题 |
这个时候,可以用 Go 提供的 go build -race
工具来检查是否存在数据竞争问题:
1 | ➜ go build -race main.go |
7.3 死锁 go-deadlock
- https://github.com/sasha-s/go-deadlock
8. 再次看 Go 锁的两大基础
在分析完 Go 的各种并发工具之后,相信不少读者都能理解为什么 atomic 和 sema 是 Go 锁的两大基础了。
graph TB
subgraph "用户层并发工具"
Mutex[sync.Mutex]
RWMutex[sync.RWMutex]
WaitGroup[sync.WaitGroup]
Cond[sync.Cond]
Once[sync.Once]
Pool[sync.Pool]
Chan[Channel]
end
subgraph "Runtime 基础原语"
Atomic[Atomic 原子操作]
Sema[Semaphore
sleep/wakeup]
end
Mutex --> Atomic
Mutex --> Sema
RWMutex --> Atomic
RWMutex --> Sema
WaitGroup --> Atomic
WaitGroup --> Sema
Cond --> Sema
Once --> Atomic
Pool --> Atomic
Chan --> Atomic
Chan --> Sema
style Atomic fill:#ffcccc
style Sema fill:#e1f5ff
还是前面那句话:
[!IMPORTANT]
atomic 提供无锁的快速状态管理(CAS、加减),sema 提供有竞争时的 goroutine 休眠/唤醒机制,两者组合实现"乐观尝试 + 悲观等待"的高效并发模型。
graph LR
subgraph "性能层级"
A[atomic
纳秒级
99% 场景]
B[sema
微秒级
1% 竞争]
end
A -->|无竞争| Fast[Fast Path]
A -->|低竞争
自旋| Spin[Spin]
B -->|高竞争| Slow[Slow Path
休眠/唤醒]
style A fill:#ccffcc
style B fill:#e1f5ff
style Fast fill:#90EE90
style Slow fill:#FFB6C1
这里笔者再次梳理下各个并发工具的如何运用 atomic 和 sema 的:
sync.Mutex1
2
3
4
5
6
7
8
9
10
11
12
13type Mutex struct {
state int32 // ← Atomic 操作的目标
sema uint32 // ← Semaphore 使用的地址
}
// Lock 流程:
// 1. atomic.CAS(state, 0, 1) ← Atomic 快速路径
// 2. 失败 → 自旋 + atomic 操作 ← Atomic 重试
// 3. 还失败 → semacquire(&sema) ← Semaphore 休眠
// Unlock 流程:
// 1. atomic.Add(state, -1) ← Atomic 快速路径
// 2. 有等待者 → semrelease(&sema) ← Semaphore 唤醒sync.RWMutex1
2Atomic: 管理 state(锁定/唤醒/饥饿/等待者)
Sema: 竞争时休眠/唤醒sync.WaitGroup1
2Atomic: 管理 reader 计数和 writer 等待标志
Sema: writer 等待、reader 等待(两个独立的 sema)sync.Once1
2Atomic: 管理缓冲区索引、状态标志
Sema: 发送/接收阻塞时休眠/唤醒sync.Cond1
2Atomic: 管理计数器(Add/Done)
Sema: Wait() 时如果计数 > 0 则休眠Channel1
2Atomic: (底层 Mutex 用)
Sema: Wait() 休眠,Signal/Broadcast 唤醒
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。

的底层实现原理,结合 atomic 原子操作与 sema 信号量机制,揭示锁的本质和并发安全保障机制,帮助读者以第一性原理理解 Go...)


