
本篇源于笔者一次使用 traceroute
遇到的疑难杂症的排查,在这个过程中,通过跟 Google Gemini 3Pro
的沟通,对计算机网络和平时使用的 VPN
工具又有了进一步的了解,特此梳理本文。
traceroute 回顾
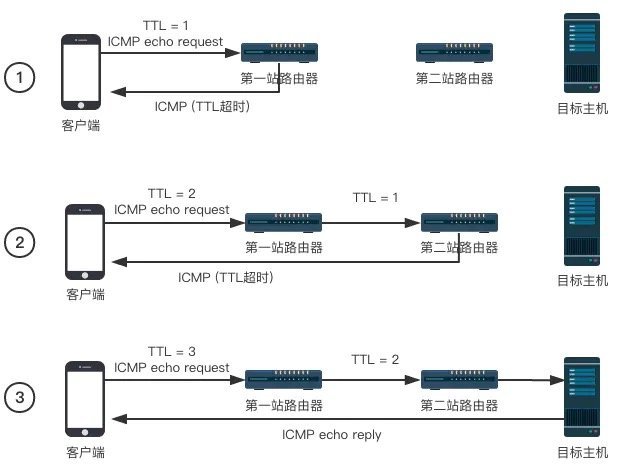
先回顾一下 traceroute 这个工具:
- 作用:用来跟踪一个 IP 数据包从源点到终点的路径。
- 原理:它利用 IP 数据报中的 TTL 字段和 ICMP 时间超时差错报告报文实现对从源点到终点的路径的跟踪。
- 过程:
- 客户端发送一个 TTL 为 1 的探测数据包(Linux/macOS 默认使用
UDP,Windows 使用 ICMP),在第一跳的时候超时并返回一个 ICMP
超时数据包,得到第一跳的地址。
- 客户端发送一个 TTL 为 2 的探测数据包,得到第二跳的地址。
- 依次递增 TTL,直到到达 目标主机,目标主机返回响应(UDP 端口不可达或 ICMP 回显应答),traceroute 结束。
- 客户端发送一个 TTL 为 1 的探测数据包(Linux/macOS 默认使用
UDP,Windows 使用 ICMP),在第一跳的时候超时并返回一个 ICMP
超时数据包,得到第一跳的地址。
问题再现
我在使用 traceroute 跟踪我本机到我的博客域名
hedon.top 的跳转路径时,发现很奇怪,返回的全是
* * *!
1 | ➜ ~ traceroute hedon.top |
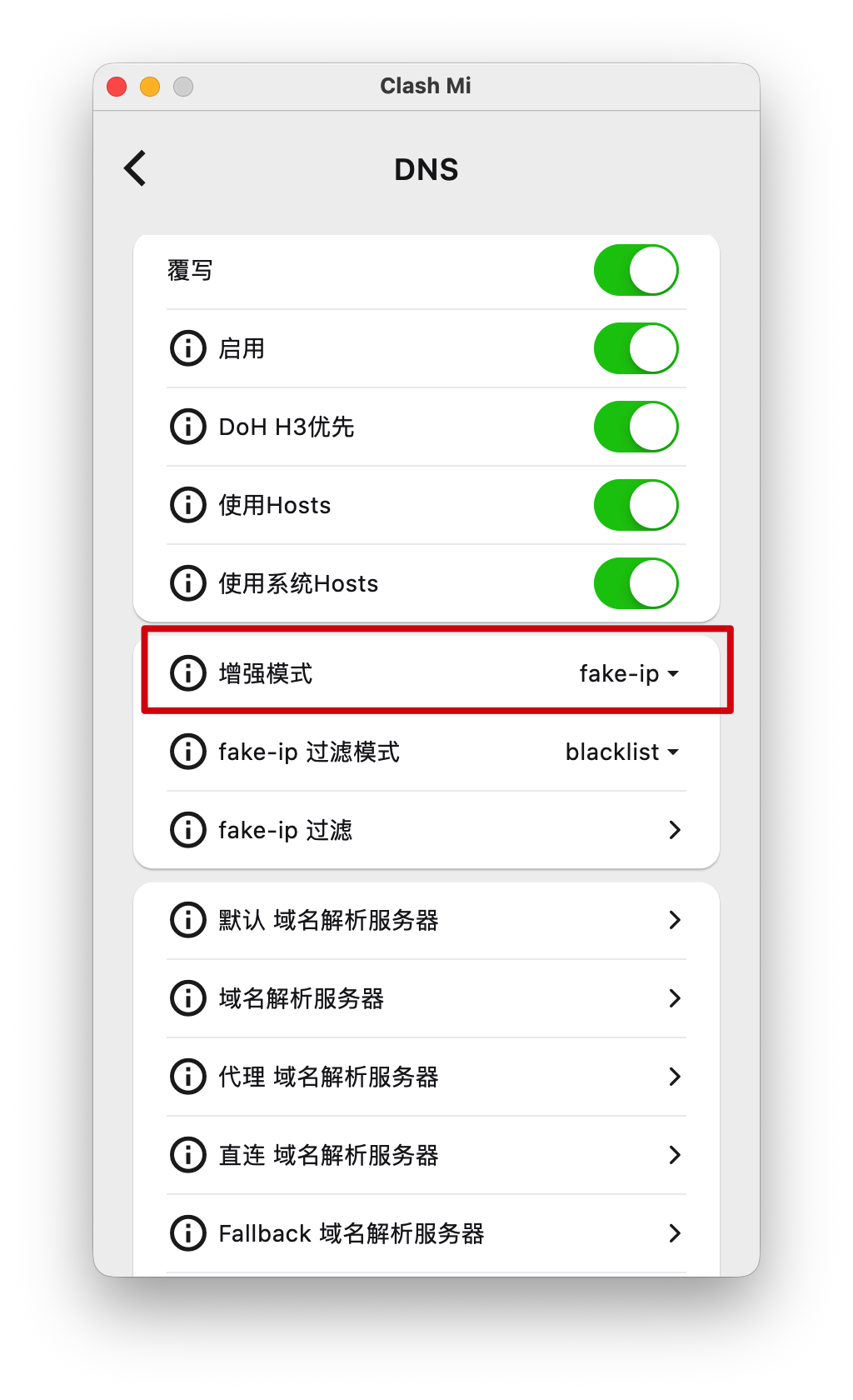
我就怀疑是不是因为我开启了 VPN,所以我就询问了一下 Google Gemini
3Pro,还真是!它说是因为 VPN 里面的 fake ip
导致了,我立马检查了我的 Clash Mi,发现果真如此,同时我关闭 Clash Mi
后,traceroute 就一切正常了。
原理分析
为什么会这样呢?
[!IMPORTANT]
很多代理软件开启 增强模式 (Fake IP) 时,会拦截所有 DNS 请求。为了加快速度,它不进行真正的 DNS 查询,而是直接扔给你一个“假的内部 IP”(通常是
198.18.x.x,但也可以配置成172.x.x.x),然后由代理软件接管流量。又因为大多数 VPN 软件的 Fake IP 逻辑只处理 TCP/UDP 数据流(用来浏览网页),它并不支持通过 Fake IP 来做 ICMP 路由探测。所以就导致了探测包发出去如泥牛入海,VPN 不回信,真实服务器更收不到(因为根本没发给真实 IP),所以看到的全是
* * *。
为什么需要 Fake IP 呢? —— 为了快!
在正常的 VPN/代理模式下,当你访问 hedon.top 时,采用的是
Redir-Host 模式:
- 本地 DNS 解析:电脑问 DNS 服务器 "hedon.top 是多少?"
- 等待:等待 DNS 返回 IP(比如 30ms)。
- 建立连接:电脑拿着 IP 去发起 TCP 连接。
- 代理软件:拦截连接,发现这个 IP 是国外的,于是走代理通道。
代理软件的设计者觉得步骤 2 是纯浪费时间。既然反正要走代理,我为什么要让本地 DNS 去查一个国外的 IP?而且万一 DNS 被污染了,给了一个错误的 IP,我还得想办法纠错。
开启 VPN (Fake IP 模式) 后的流程:
- 拦截:你发出的 DNS 请求,还没出电脑网卡,就被 VPN 软件截获了。
- 秒回:VPN
立刻、马上、随便编一个内网 IP(比如我看到的
172.19.0.13)扔给你的系统。- VPN 在心里记了个账:
172.19.0.13<==>hedon.top。
- VPN 在心里记了个账:
- 欺骗成功:浏览器(或 traceroute)拿到了这个 IP,以为是真的,于是向这个 IP 发起连接。
- 偷梁换柱:数据包发出来,又被 VPN 截获。VPN
查账本,发现目标是
172.19.0.13,于是它知道:"哦,这其实是要去访问hedon.top"。 - 远程解析:VPN 把"访问
hedon.top"这个指令发给远端的代理服务器,由远端服务器去解析真正的 IP 并传输数据。
sequenceDiagram
autonumber
participant App as 浏览器/App
participant OS as 操作系统/DNS栈
participant Clash as Clash (Fake IP)
participant Remote as 远端代理服务器
Note over App, Clash: 阶段一:DNS 欺骗 (极速响应)
App->>OS: 域名解析请求: hedon.top
OS->>Clash: 发送 UDP 53 包
Note right of Clash: Clash 拦截请求
根本不去查互联网!
Clash->>Clash: 1. 从 Fake IP 池选一个空闲 IP
比如 172.19.0.13
Clash->>Clash: 2. 记账 (Mapping)
"172.19.0.13" = "hedon.top"
Clash-->>App: 秒回: IP 是 172.19.0.13
Note over App, Clash: 阶段二:建立连接 (偷梁换柱)
App->>App: 以为拿到了真 IP
向 172.19.0.13 发起 TCP 连接
App->>Clash: TCP SYN (Dst: 172.19.0.13)
Note right of Clash: Clash 拦截 TCP 包
查账本:172.19.0.13 是谁?
Clash->>Clash: 哦,原来是 hedon.top
Clash->>Remote: 把"域名 hedon.top"发给远端
由远端服务器去解析真实 IP
Remote->>Remote: 在海外解析并连接真实服务器
关键点:
- 省时:DNS 响应是毫秒级的,因为根本不需要网络请求,Clash 直接从内存里扔一个 IP 给你。
- 防污染:因为本地根本不进行真实的 DNS 解析,GFW 的 DNS 污染攻击直接无效。
- 远端解析:真实的 IP 解析发生在远端代理服务器(比如在日本或美国的机房),那里解析出来的 IP 一定是离目标最近、最准确的(比如 Google 的 CDN 节点)。
为什么返回是全是 * * * 呢?
再看那个全是 * * * 的现象,就很容易理解了:
- 执行:
traceroute hedon.top。 - Clash Mi 欺骗:给了
172.19.0.13。 - 发包:
traceroute向172.19.0.13发送 UDP/ICMP 探测包。 - 死胡同:
- 这个 IP 在公网上是不存在的。
- Clash 通常只代理浏览器的 TCP/UDP 数据流,它并没有义务去模拟路由器的 ICMP TTL 回显功能。
- 所以探测包发给 Clash Mi 的虚拟网卡后,就像掉进了黑洞,没有任何设备回信"超时"。
注意事项
Fake IP 虽然爽,但对于写代码的人来说,有两个巨大的坑:
坑一:Docker/局域网冲突
如果 Clash Mi 用的 Fake IP 网段(如
172.19.0.0/16)恰好和你的 Docker 容器网段重叠。
- 现象:你要连本地的 Docker 数据库,结果流量被 Clash 吸走了,报"连接被拒绝"。
- 解法:始终确保 Fake IP 网段设置为
198.18.0.1/16。这是一个专门用于性能测试的保留网段,世界上没有公网机器用它,Docker 默认也不用它。
坑二:IP 缓存中毒 (DNS Cache Poisoning)
有些笨拙的软件(比如旧版的 Java 客户端、某些物联网设备 SDK)会缓存 DNS 结果。
- 你开了 VPN,程序解析
hedon.top拿到172.19.0.13。 - 程序把这个 IP 存到自己的内存缓存里,有效期 1 小时。
- 你关了 VPN。
- 程序再次发起请求,它不去解析 DNS 了,直接连
172.19.0.13。 - 报错:因为 VPN 关了,操作系统不知道这个 IP 是谁,网络直接不可达。
解法:关 VPN 后,往往需要重启应用,甚至执行
ipconfig /flushdns (Windows) 或
sudo killall -HUP mDNSResponder (macOS)。
其他原因
除了 Fake IP
这种本地欺骗导致的全是星星外,在真实的互联网环境中,traceroute
出现 * * * 是非常普遍的现象。
从第一性原理来看,* * *
的本质含义只有一个:我发出了探测包,但在规定时间内(通常是 5
秒),我没有收到任何回信。
造成没有回信通常有以下四大类原因,我们按照出现的概率从高到低排列:
1. 中间路由器的高冷 (ICMP 限速或禁发)
表现:中间几行是星星,但最后能到达终点。
- 原理:路由器的核心 KPI 是转发数据包,而不是陪聊。当你发送 TTL 超时的探测包时,路由器需要暂停手头的工作,调用 CPU 生成一个 ICMP Time Exceeded 消息发回给你。这会消耗路由器的 CPU 资源。
- 策略:为了防止被 DDoS 攻击或节省性能,运营商(ISP)和骨干网路由器通常配置了 ICMP Rate Limiting (限速) 甚至 ICMP Silently Drop (静默丢弃)。
- 结论:如果中间全是星,但最后一行通了,完全不用担心,这是正常的网络现象。
2. 防火墙的黑洞策略 (DROP vs REJECT)
表现:从某一行开始全是星星,直到结束都连不上。
- 原理:当探测包撞上防火墙(可能是企业边缘防火墙、GFW、或者目标机器的
iptables)时,防火墙有两种处理方式:
- REJECT:明确告诉你"滚"。你会收到
Destination Unreachable。 - DROP (丢弃):直接把包扔垃圾桶,不给任何回信。
- REJECT:明确告诉你"滚"。你会收到
- 为什么:出于安全考虑,管理员通常配置 DROP。因为回复错误信息会暴露防火墙的存在和 IP 地址,给黑客留下线索。
- Linux 的痛点:Linux traceroute 默认用 UDP 高端口探测。很多企业的防火墙策略是:只允许 Web (80/443) 流量进入,封禁所有未知 UDP 端口。这会导致你还没到终点就被拦截了。
- 解决方法:使用
traceroute -I(改用 ICMP) 或traceroute -T(改用 TCP 80 端口) 通常能穿透更多层。
3. 进出路径不一致 (非对称路由 Asymmetric Routing)
表现:忽通忽断,或者全是星星。
- 原理:互联网非常复杂,"去程"和"回程"走的路往往是不一样的。
- 去程:你 -> 路由器 A -> 路由器 B -> 目标。
- 回程:目标 -> 路由器 C -> 路由器 D -> 你。
- 问题:
- 如果你发出的探测包经过了路由器 B(它是有状态防火墙),它记录了"我发出了一个包"。
- 但回信是路由器 C 试图发回来的。路由器 B(或者你这边的防火墙)一看:"我没见过你 C 发过来的连接请求啊?你是谁?"
- 于是回信被状态防火墙 (Stateful Firewall) 拦截了。
- 结论:虽然数据包可能真的到达了,但回音被杀死了。
4. 真的断网了 (路由黑洞 / 环路)
表现:到某一跳后中断,或者在两个 IP 之间死循环。
路由黑洞 (Blackhole):路由器 A 的路由表说"去往目标找 B",但路由器 B 说"我不认识目标,也没有默认网关"。数据包到了 B 就被丢弃了(且 B 如果配置了不回显 ICMP,就是星星)。
路由环路 (Loop):A 说"找 B",B 说"找 A"。
traceroute 会显示:
1
2
3
45 10.0.0.1
6 10.0.0.2
7 10.0.0.1
8 10.0.0.2直到 TTL 耗尽。
总结
看到 * * *
时,需要通过上下文来判断:
| 现象 | 含义 | 后端应对 |
|---|---|---|
| 全星 (第 1 跳就开始) | 连门都没出去 | 查 VPN Fake IP、本地防火墙、网关配置 |
| 中间有星,最后通了 | 中间路由器高冷/忙碌 | 忽略,网络是通的 |
| 最后几行全是星 | 目标主机开了防火墙/禁 Ping | 尝试 telnet 端口验证业务层连通性 |
| 从第 X 跳开始全星 | 链路中断 或 强力防火墙(GFW) | 检查路由表,联系网管 |
星星夹杂 IP (如 \* 1.1.1.1 \*) |
丢包率高 / 负载均衡 | 网络质量差,存在抖动 |
新工具推荐
一个实用的命令:
如果你在排查服务器连通性,建议使用 mtr (My Traceroute)。它结合了 ping 和 traceroute,会实时刷新每一跳的丢包率。
1 | # 能够清晰看到是哪一跳开始丢包的 |
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




