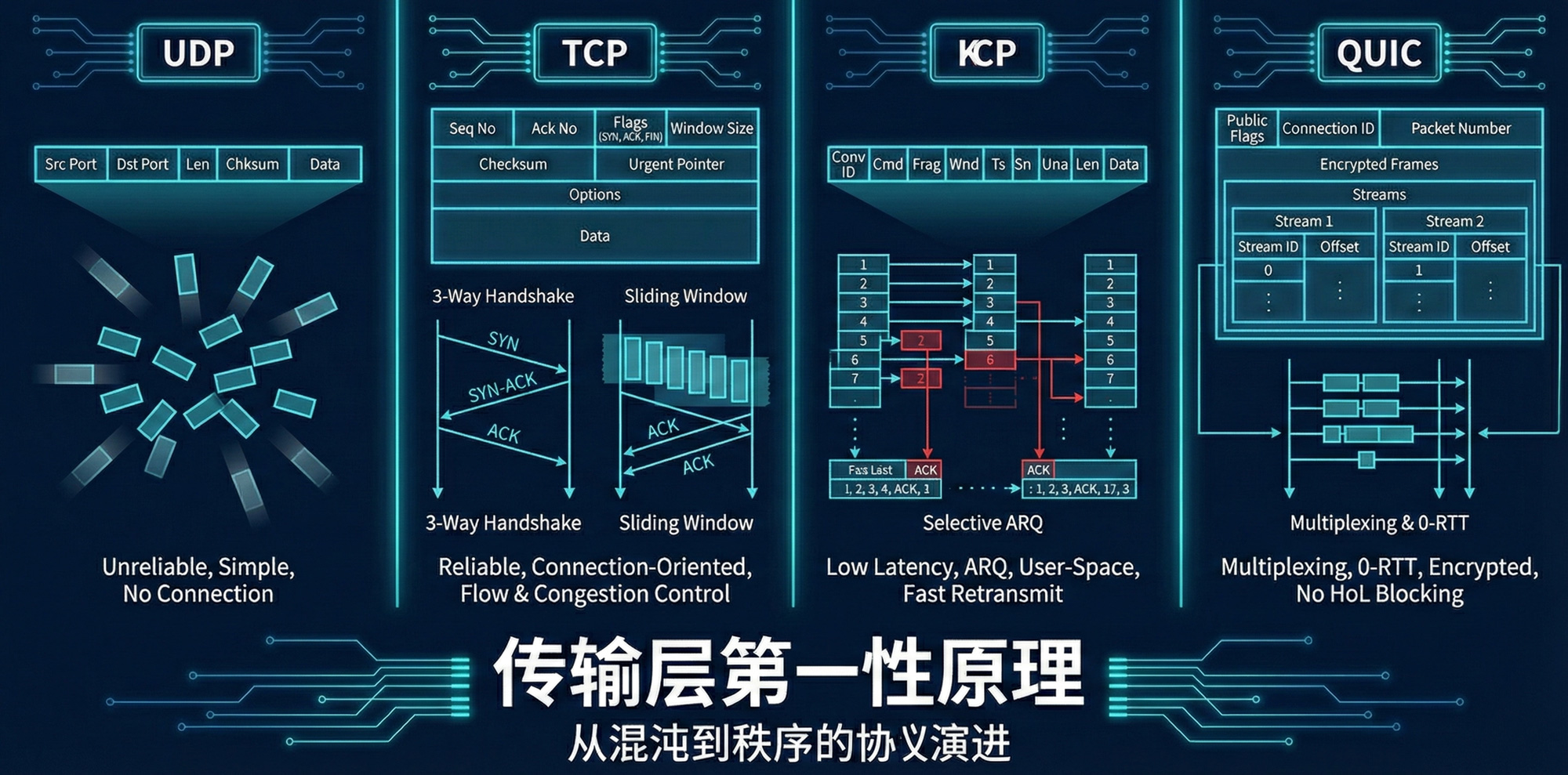
相信不少读者跟笔者一样,对计算机网络中传输层的各种协议背了又忘,忘了又背,背了还完。所以本篇想尝试从第一性原理出发,看看能否从根上去掌握传输层中的 UDP、TCP、KCP 和 QUIC 协议(尽管 KCP 和 QUIC 是在应用层进行实现的,不过因为其实现的功能属于传输层的范畴,所以笔者在本篇将将这二者归为传输层)。
特此声明,本篇是笔者与 Google Gemini 3Pro 共创所作,非常庆幸在当今 AI 时代下获取知识已是如此便利,且也为学习者从第一性原理理解所学知识大大降低了门槛。不过本篇的篇章安排和叙述逻辑,均由笔者把控和审阅,欢迎放心阅读。
1. 宏观理解
之所以背了又忘,通常是因为我们把传输层看作是一堆枯燥的字段(Flags、Window size)和死记硬背的流程(三次握手、四次挥手),而忽略了它存在的核心目的和演化逻辑。
要从根本上理解传输层(Transport Layer),我们需要剥离掉具体的协议细节,回归到第一性原理:传输层到底解决了什么网络层(IP)解决不了的问题?
1.2 三个层级
我们可以将其分解为三个层级来理解:复用与分用、不可靠基础上的可靠性、传输效率的权衡。
1.2.1 第一层级:复用与复用
👉🏻 核心逻辑
从主机到主机进化为进程到进程。
网络层(IP 层)的任务非常纯粹:通过 IP 地址,把数据包从地球的一端(主机 A)送到另一端(主机 B)。
但是,当数据包到达主机 B 时,IP 的任务就结束了。主机 B 此时正运行着微信、浏览器、Steam 和网易云音乐。这个数据包到底是给谁的?IP 协议不知道,也不管。
这就是传输层存在的第一个根本原因:
- 网络层只负责把快递送到大楼传达室(主机 IP)。
- 传输层负责把快递分发给大楼里的具体某个人(进程 Port)。
这个过程叫做复用(Multiplexing)和分用(Demultiplexing)。
不要把端口想象成物理插口,它只是一个逻辑地址。如果没有传输层,你的电脑同一时间只能运行一个网络程序,这显然是不可接受的。
1.2.2 第二层级:不可靠基础上的可靠性
👉🏻 核心逻辑
在不可靠的物理世界,构建一个完美的虚拟管道。
这是传输层最难理解、也最容易忘的部分。我们来看 TCP 为什么要搞得这么复杂。
第一性原理推导: 底层的网络环境(IP 层及更底层)本质上是不可靠的。
- 丢包: 路由器太忙,直接把包扔了。
- 乱序: 或者是前面的包走了远路,后面的包走了近路。
- 篡改/错误: 电信号干扰导致比特翻转。
如果你的应用是"银行转账"或"网页浏览",你无法容忍上述任何一种情况。你希望应用层感受到的是一条连续的、无差错的字节流。
TCP 的所有机制,都是为了填补"不可靠的现实"与"可靠的需求"之间的鸿沟。我们不需要死记硬背,而是通过问题来推导方案:
- 问题:我怎么知道数据包丢没丢?
- 方案(确认应答 ACK): 接收方收到数据必须回一个"收到了"。
- 衍生问题: 如果发送方一直收不到 ACK 怎么办?
- 方案(超时重传): 设个闹钟,时间到了没消息就重发。
- 问题:数据包乱了怎么办?重复了怎么办?
- 方案(序列号 Sequence Number): 给每个字节的数据编号。1, 2, 3... 这样接收方就可以重新排序,或者丢弃重复的号。
- 问题:接收方处理不过来怎么办?(比如服务器太慢,或者你发得太快)
- 方案(流量控制 Flow Control): 接收方在回信里告诉发送方:"我的缓冲区还剩 X 大小(Window Size)"。发送方根据这个 X 调整发送速度。这就是滑动窗口的本质——保护接收方。
- 问题:网线堵塞了怎么办?(中间的路由器处理不过来)
- 方案(拥塞控制 Congestion Control): 这是 TCP 最伟大的设计。发送方通过试探(慢启动、拥塞避免),感知网络的拥堵程度。一旦发现丢包(暗示堵车),立马减速。这是一个保护互联网基础设施的利他机制。
不要孤立地背诵"慢启动"、"快重传"。把 TCP 想象成一个强迫症晚期的快递员:他必须给每一个包裹编号(序列号),必须拿到客户的签字(ACK),发现客户家堆满了(流量控制)就暂停发货,发现路上堵车(拥塞控制)就换个时间发。
1.2.3 第三层级:速度与质量的权衡
👉🏻 核心逻辑
有时候,比起准确,我更需要实时。
并不是所有应用都需要 TCP 那样的强迫症。
- 场景: 视频通话、在线 FPS 游戏(如 CS:GO)。
- 思考: 在视频通话中,如果第 5 秒的画面丢了一帧,TCP 会怎么做?它会暂停后续播放,疯狂重传第 5 秒的那一帧,直到成功。等你看到那一帧时,已经是第 8 秒了,画面卡顿延迟。
- 实际需求: 丢了就丢了,赶紧把第 6 秒、第 7 秒的画面给我,我要的是实时性。
这就是 UDP(用户数据报协议) 的生存空间。
- 它几乎不加修饰,只做最基础的“复用/分用”(加个端口号)。
- 它不保证到达,不保证顺序,没有拥塞控制。
- 特点: 快、自由、无连接。
理论与实践结合:
- HTTP/3 (QUIC): 现在的互联网巨头发现 TCP 太重了(握手慢、队头阻塞),于是开始在 UDP 之上重新实现一套可靠传输协议(QUIC)。这说明传输层的本质功能(可靠性)可以上移到应用层实现,但底层的物理限制永远存在。
1.2.4 总结
| 特性 | TCP (Transmission Control Protocol) | UDP (User Datagram Protocol) |
|---|---|---|
| 角色人格 | 严谨的会计师 | 急躁的广播员 |
| 核心价值观 | 可靠性 > 实时性 | 实时性 > 可靠性 |
| 第一性原理 | 通过确认、重传、排序、流控,将不可靠的 IP 网络模拟成可靠的管道。 | 尽最大努力交付,保留 IP 网络的原始特性,只增加端口区分进程。 |
| 连接方式 | 面向连接 (三次握手确认双方都在线) | 无连接 (想发就发,不管你在不在) |
| 典型应用 | 网页 (HTTP)、邮件 (SMTP)、文件传输 (FTP) | 直播、视频会议、DNS、早期的 QUIC |
1.3 三个时代
要彻底理解这四个协议,我们不能平铺直叙地去背它们的定义。我们需要站在进化论的视角,看它们是如何为了解决特定时代的特定痛点而诞生的。
这不仅仅是协议的区别,更是思维模式(Mindset)的转变:从内核态的僵化走向用户态的灵活。
我们将这四个协议分为三个代际来理解:二元对立的世界 (TCP vs UDP)、暴力美学的补丁 (KCP) 和 颠覆架构的革命 (QUIC / HTTP3)。
1.3.1 第一代:二元对立的世界 (TCP vs UDP)
这是互联网早期的基础设定。设计者面临一个根本的取舍(Trade-off):你是要绝对准确,还是要绝对速度?
1. TCP (Transmission Control Protocol) —— 老好人
- 第一性原理: 公平与可靠。
- 痛点解决: 互联网早期网络极不稳定,必须保证数据不丢、不乱。
- 性格缺陷:
- 太守规矩(慢): 建立连接要三次握手,断开要四次挥手。
- 太顾大局(拥塞控制): 一旦发现丢包,TCP 默认认为是网络堵了,为了不给互联网添乱,它会立刻减速(慢启动、拥塞避免)。哪怕其实只是因为你家 WiFi 信号抖了一下,它也会大幅降低速度。
- 队头阻塞(Head-of-Line Blocking): 前面一个包没到,后面的包到了也不能用,必须排队等。
2. UDP (User Datagram Protocol) —— 甩手掌柜
- 第一性原理: 简单与直接。
- 痛点解决: 解决 TCP 头部太大、握手太慢的问题。
- 性格特征:
- 只管发,不管你收没收到。
- 没有任何"流控"或"拥塞控制",有多少发多少。
- 问题: 在复杂的互联网环境下,纯 UDP 几乎无法直接传输关键数据,因为丢包率不可控。
1.3.2 第二代:暴力美学的补丁 (KCP)
随着实时对战游戏(如王者荣耀、MMORPG)的兴起,开发者遇到了两难:
- 用 TCP?延迟太高,角色瞬移,因为 TCP 一丢包就降速等待。
- 用 UDP?包丢了技能放不出来。
于是,KCP 诞生了。它不是一个标准的网络协议,而是一个运行在 UDP 之上的算法库。
- 核心逻辑: 用带宽换延迟(流量换速度)。
- 第一性原理: TCP 的可靠性逻辑是对的(要确认、要重传),但 TCP 的策略太保守了。KCP 在 UDP 上重新实现了 TCP 的可靠机制,但把参数调得非常激进。
- KCP 怎么魔改 TCP 的?
- 死不退让(RTO 不翻倍): TCP 发现超时,下一次等待时间会翻倍(1s -> 2s -> 4s);KCP 说不,超时了我立马重传,等待时间只增加一点点(1s -> 1.5s),绝不让用户等。
- 选择性重传: 丢了哪个包,只重传那个包,不像早期 TCP 可能把后续的一起重传。
- 快速重传: 只要发现跳号(比如收到了 1, 3, 4,没收到 2),KCP 不等超时,立马重传 2。
- 代价: 会比 TCP 多消耗 10%-20% 的带宽。这是一种自私的协议,为了我的应用快,我不惜挤占网络资源。
- 总结: KCP = 激进版 TCP + UDP 的外壳。
1.3.3 颠覆架构的革命 (QUIC / HTTP3)
到了移动互联网时代,网页请求变得极其复杂(一个页面几百个资源),且用户经常切换网络(从 WiFi 切到 4G)。TCP 的底层架构(基于 IP 和端口)和队头阻塞成了瓶颈。KCP 这种小修小补已经不够了。
Google 站出来说:我们要重新发明轮子。这就是 QUIC (Quick UDP Internet Connections)。
- 核心逻辑: 移花接木,在用户态重构一切。
- 第一性原理: 既然操作系统的 TCP 协议栈(Kernel)更新太慢(你没法强迫全世界升级 Windows/Linux 内核),那我们就绕过内核,在应用层(用户态)基于 UDP 自己写一套完美的传输协议。
- QUIC 解决了什么 TCP 解决不了的问题?
- 彻底解决队头阻塞(多路复用):
- TCP: 一条高速公路,前面车坏了,后面全堵死。
- QUIC: 并不是单纯的一条路,而是并行的多车道(Stream)。图片 A 的包丢了,只影响图片 A,不影响旁边的 CSS 文件和文字加载。这是 QUIC 最核心的优势。
- 网络切换不断线(Connection Migration):
- TCP: 依靠 IP:Port 识别连接。你从 WiFi (IP: A) 切换到 4G (IP: B),IP 变了,TCP 连接必断,必须重新握手。
- QUIC: 发明了一个 Connection ID (UUID)。不管你的 IP 怎么变,只要 ID 没变,服务端就知道还是你,连接保持,无需重连。
- 0-RTT 建连:
- TCP + TLS 需要多次往返才能建立加密连接。QUIC 把传输层握手和加密层(TLS 1.3)握手合并了,最快可以做到 0 延迟发送数据。
- 彻底解决队头阻塞(多路复用):
1.3.4 总结
| 协议 | TCP | UDP | KCP | QUIC (HTTP/3) |
|---|---|---|---|---|
| 本质身份 | 正规军 (OS内核实现) | 传令兵 (OS内核实现) | 雇佣兵 (应用层算法库) | 特种部队 (应用层协议栈) |
| 底层载体 | IP | IP | UDP | UDP |
| 核心哲学 | 可靠性、公平性、顺序 | 简单、快、无状态 | 速度优先 (牺牲带宽换低延迟) | 效率优先 (解决队头阻塞、快速握手) |
| 丢包处理 | 减速、退让、重传 | 不管 | 激进重传、死不退让 | 独立流重传 (只重传丢的那一路) |
| 连接识别 | 五元组 (IP:Port...) | 无连接 | 会话 ID (Conv ID) | Connection ID (不怕切网络) |
| 典型场景 | 网页、文件下载、金融 | DNS、广播、简单的 IoT | MOBA 游戏、实时音视频 | 下一代 Web、YouTube、Gmail |
- TCP 和 UDP 是操作系统提供的原材料。TCP 也就是加了确认和流控的 UDP。
- KCP 是为了游戏和弱网环境,在 UDP 上模仿并魔改了 TCP,甚至不惜浪费流量也要快。
- QUIC 是为了现代 Web,在 UDP 上彻底重写了 TCP + TLS,解决了 TCP 几十年改不掉的"队头阻塞"和"僵化"毛病。
一句话总结: TCP 是老古董,UDP 是地基,KCP 是为了快而拼命的魔改插件,QUIC 是试图取代 TCP 的下一代互联网标准。
2. 底层剖析
要详细剖析这四个协议的底层原理,我们必须深入到数据包(Packet)的结构和状态机(State Machine)的控制逻辑中去。
我们要抓住一个核心矛盾:如何在不可靠的物理线路(丢包、乱序、延迟)上,构建出符合应用层需求的逻辑管道。
2.1 UDP:裸奔的传输层
UDP 是理解其他所有协议的基准。它的底层原理非常简单,几乎就是 IP 协议的“影分身”。
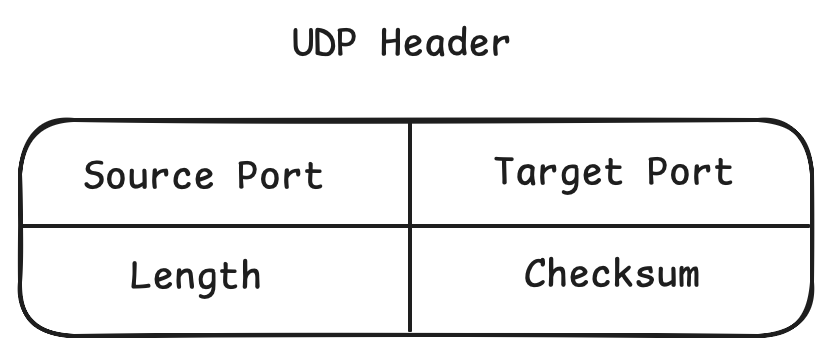
2.1.1 头部结构
UDP 的头部只有 8 个字节。
- Source Port & Destination Port: 也就是前面提到的"复用/分用"。
- Length & Checksum: 告诉你包有多长,校验一下数据有没有坏(比特翻转)。
2.1.2 核心机制
- 无状态(Stateless): 操作系统内核不会为 UDP 维护任何表格。来一个包,查一下端口,扔给应用程序。发一个包,直接扔给网卡。
- MTU 限制: UDP 不负责切分数据。如果你应用层给 UDP 一个 2000 字节的数据包,而底层以太网 MTU 只有 1500,IP 层会进行分片(Fragmentation)。一旦其中一个分片丢了,整个 UDP 包就废了。
既然 UDP 什么都不管,那么所有的高级功能(KCP 的重传、QUIC 的流控)都必须由应用层代码自己来实现。
2.2 TCP:流量与拥塞的博弈
传输控制协议(TCP)是互联网的基石,其设计目标是在不可靠的 IP 网络上提供可靠(Reliable)、有序(Ordered)且错误检查(Error-Checked)的字节流服务。从第一性原理来看,TCP 是一个复杂的控制论系统,通过负反馈机制(ACK)来调节系统的输入(发送速率),以维持系统的稳定性(避免拥塞崩溃)。
2.2.1 字节流抽象与序列号管理
TCP 的核心抽象是字节流。不同于 UDP 的报文,TCP 将应用层数据视为无边界的水流。
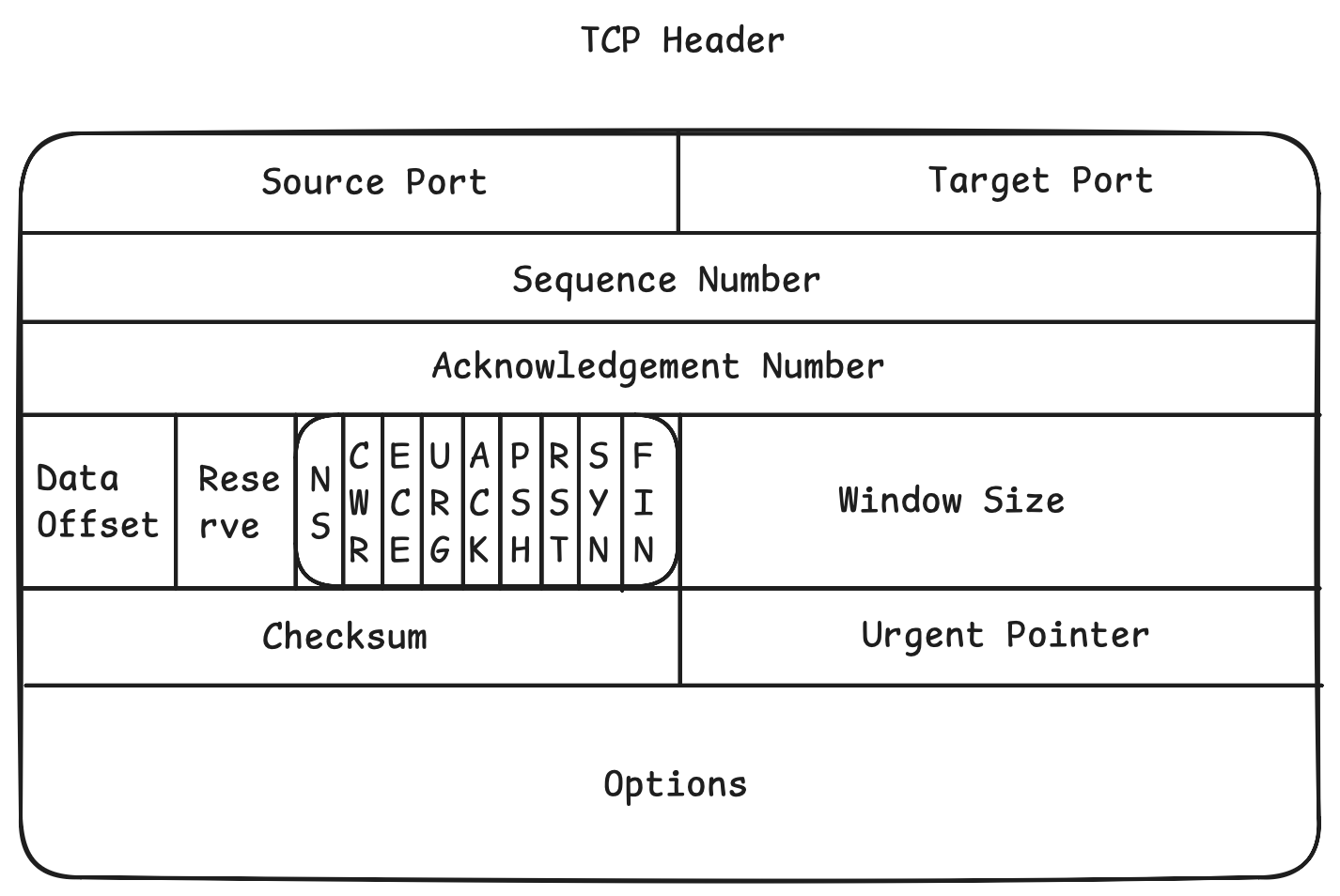
为了实现有序重组,TCP 为发送的每一个字节(Octet)分配一个 32 位的序列号。
- 语义:TCP 段头部的
Sequence Number字段表示该段数据载荷中第一个字节在整个数据流中的偏移量。 - ACK 机制:TCP 使用累积确认(Cumulative
ACK)。
Acknowledgment Number表示接收端期望收到的下一个字节的序列号。例如,ACK=1001 意味着 1000 及以前的所有字节均已正确接收。
内核为每个 TCP 连接维护一个接收缓冲区(Receive Buffer)。
- 当数据包乱序到达(例如,先收到 SEQ 2000,后收到 SEQ 1000),内核会将 SEQ 2000 的数据暂存在缓冲区中的对应位置(SACK 机制辅助记录这一空洞)。
- 只有当 SEQ 1000 到达填补空洞后,内核才会更新 ACK 指针,并唤醒用户进程读取数据。
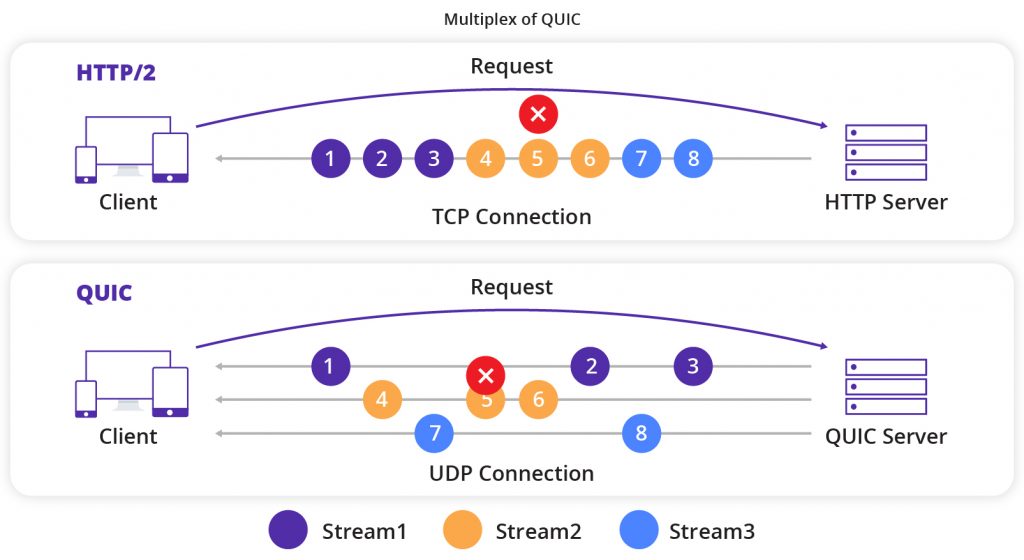
- 队头阻塞(Head-of-Line Blocking, HOL):这是 TCP 在低延迟场景下的致命弱点。如果 SEQ 1000 的包丢失,即使 SEQ 2000-5000 的数据已经完整到达,应用层也无法读取这 3000 字节。内核必须等待 SEQ 1000 重传成功,才能交付后续数据。在丢包率为 1%-2% 的网络中,HOL 会导致巨大的延迟抖动。
2.2.2 可靠传输:RTO 与 ARQ
TCP 的可靠性依赖于自动重传请求(ARQ)。核心问题在于:发送端发出数据后,应该等待多久才认为数据丢失?这个时间被称为重传超时(RTO)。
RTO 的计算必须基于对往返时间(RTT)的动态估算。
SRTT(Smoothed RTT):采用指数加权移动平均(EWMA)算法平滑采样值。 \[ SRTT_{new} = (1 - \alpha) \cdot SRTT_{old} + \alpha \cdot RTT_{sample} \] 其中 \(\alpha\) 通常取 0.125。
RTTVAR(RTT Variation):Van Jacobson 引入了对 RTT 抖动(方差)的估算,以适应网络波动 17。
\[ RTTVAR_{new} = (1 - \beta) \cdot RTTVAR_{old} + \beta \cdot |SRTT_{old} - RTT_{sample}| \] 最终 RTO 计算公式为: \[ RTO = SRTT + 4 \cdot RTTVAR \] 系数 4 的选择基于切比雪夫不等式,旨在覆盖 99% 以上的 RTT 分布。
Karn 算法:解决重传二义性问题。如果一个包发生了重传,收到 ACK 时无法确定是回应原包还是重传包,因此 Karn 算法规定:发生重传时,不更新 RTT 估算值,并将 RTO 指数退避(Exponential Backoff) 。
等待 RTO 超时过于缓慢。TCP 引入了快速重传机制:当发送端收到 3 个重复的 ACK(Duplicate ACK) 时,推断该 ACK 指示的下一个报文段已丢失,立即重传,而不必等待定时器溢出。这一机制利用了"重复 ACK"作为网络丢包的隐式信号,显著降低了恢复延迟。
2.2.3 拥塞控制:从 AIMD 到 BBR
TCP 认为丢包是网络拥塞的信号(这一假设在无线网络中往往不成立,却是 TCP 设计的基石)。
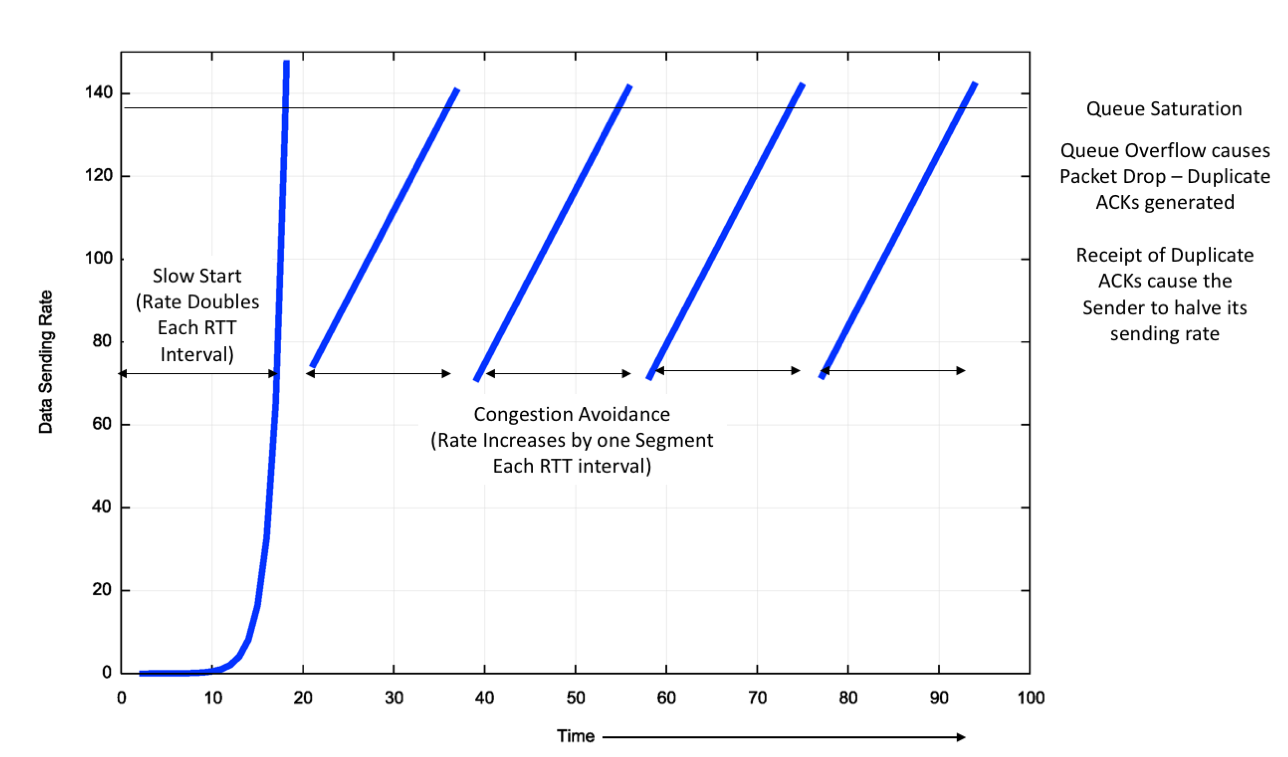
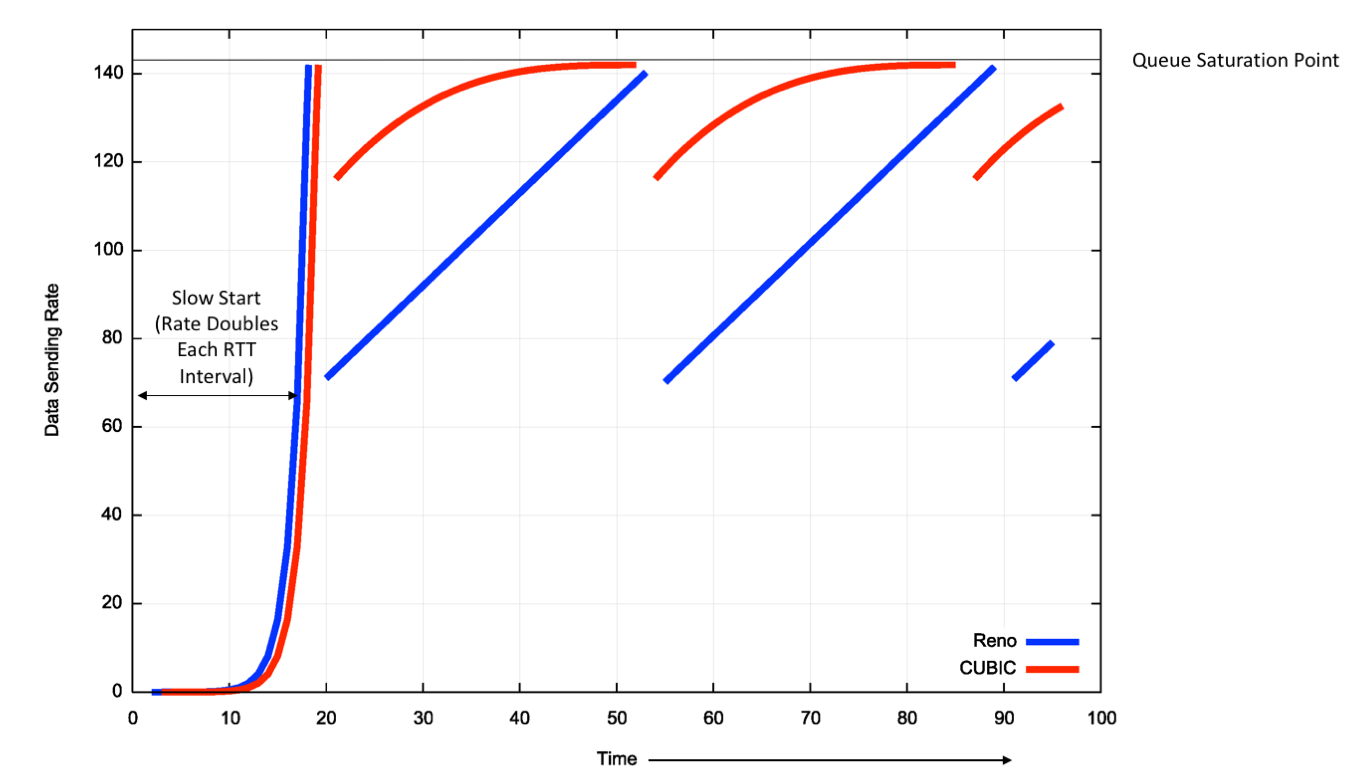
- 慢启动(Slow Start):连接建立初期,拥塞窗口(cwnd)呈指数增长,每收到一个 ACK,cwnd 加 1 MSS(最大报文段长度)。这实际上是倍增过程,用于快速探测可用带宽。
- 拥塞避免(Congestion Avoidance):当 cwnd 达到慢启动阈值(ssthresh)后,进入线性增长阶段(AIMD:加法增,乘法减)。每经过一个 RTT,cwnd 增加 1 MSS。
- 拥塞发生:一旦检测到丢包(超时或 3 个重复 ACK),TCP 立即大幅削减 cwnd(通常减半或降为 1),以释放网络压力。
2.2.3.1 CUBIC 算法
Linux 默认使用的 CUBIC 算法,将窗口增长函数设计为一个三次函数。 \[ W(t) = C(t - K)^3 + W_{max} \] 其曲线在接近上次丢包窗口 \(W_{max}\) 时变得平缓(稳定探测),而在远离饱和点时快速增长。这种凹凸性使得 CUBIC 在高带宽延迟积(BDP)网络中比线性增长的 Reno 算法更高效。
2.2.3.2 BBR(Bottleneck Bandwidth and RTT)
Google 提出的 BBR 算法颠覆了“基于丢包”的传统逻辑。BBR 基于模型(Model-based),试图实时测量网络的两个物理边界:
RTprop(物理链路的最小往返传播时延)。
BtlBw(瓶颈链路带宽)。
BBR 试图将发送速率控制在 BtlBw,同时保持 inflight 数据量等于 BDP(带宽×延迟),从而在不填满路由器缓冲区(Bufferbloat)的情况下跑满带宽。这种机制使得 BBR 在高丢包率环境下依然能保持高吞吐,因为它不会因为非拥塞性丢包而错误地降低速度。
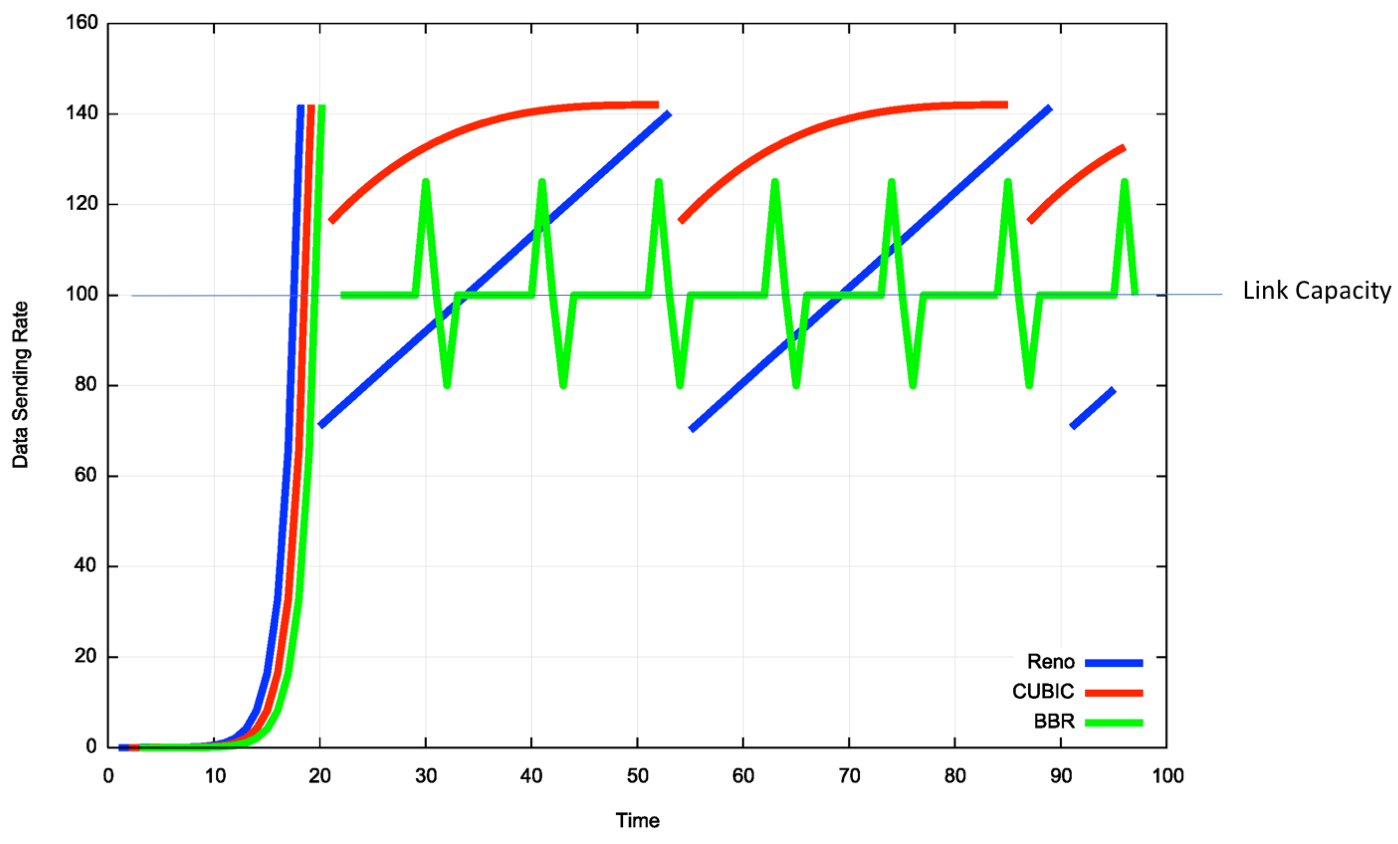
TCP 的丢包判断机制(通常是 3 次重复 ACK 或超时)在现代高丢包率或高延迟网络(如跨海传输)下显得反应太慢,且一旦退让就退让太多。
2.3 KCP:用带宽换时延
KCP 是一个纯算法层面的 ARQ 协议,其设计者 skywind3000 明确指出,KCP 的第一性原理是用带宽换延迟。如果说 TCP 是为了最大化全网的带宽利用率和公平性,那么 KCP 就是为了在单点连接上压榨出物理极限的响应速度,不惜牺牲带宽资源。
2.3.1 头部结构
KCP 的核心在于其精巧的数据段结构 IKCPSEG,其头部占据 24
字节(TCP 通常为 20 字节),字段定义直接服务于激进的重传逻辑。
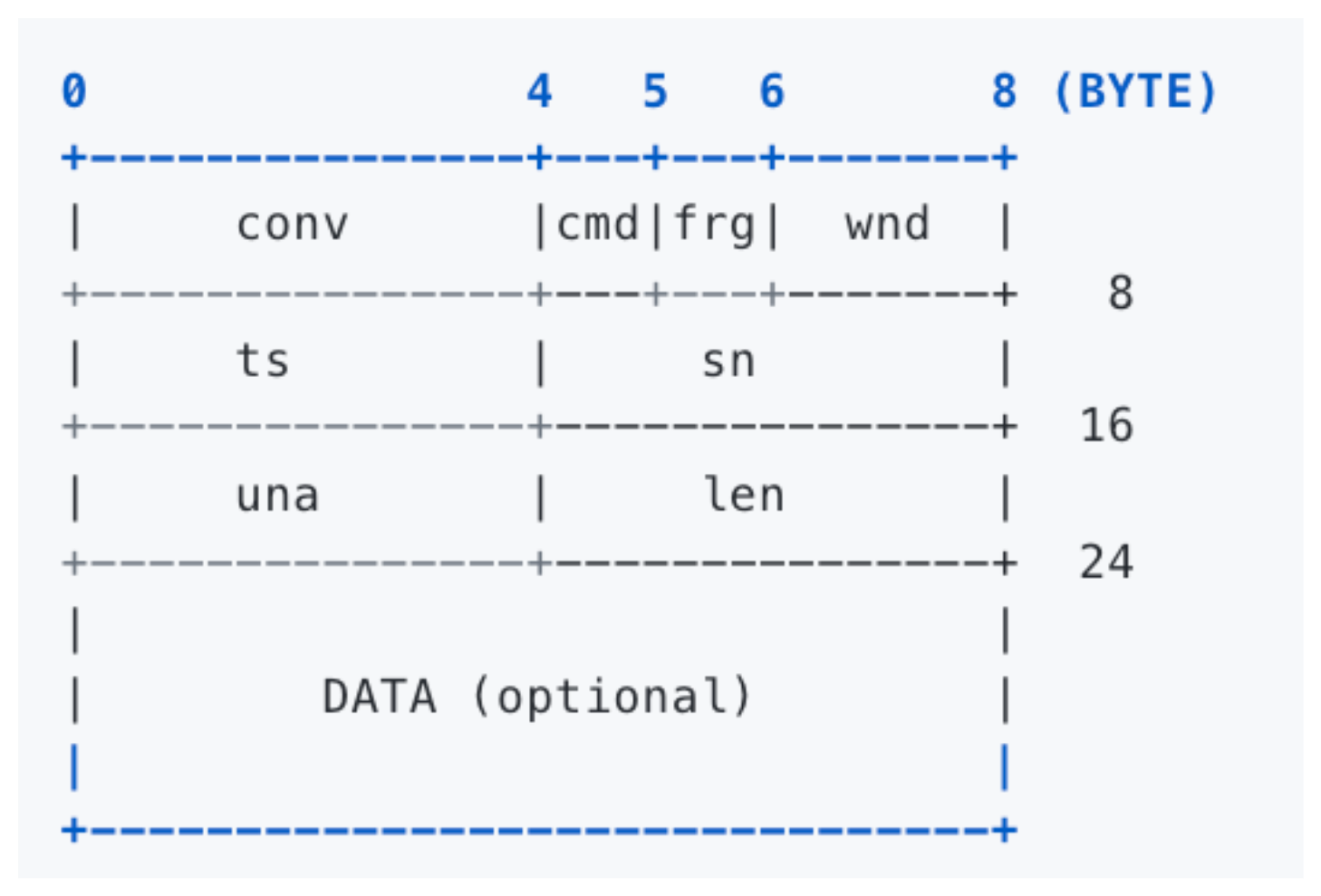
| 字段 | 类型 | 描述 | 设计意图 |
|---|---|---|---|
conv |
32-bit | 会话 ID | 区分不同的逻辑连接,类似于 TCP 的四元组但仅由 ID 标识。 |
cmd |
8-bit | 指令类型 | IKCP_CMD_PUSH (数据), ACK (确认), WASK (窗口探测), WINS (窗口通告)。 |
frg |
8-bit | 分片序号 | 支持应用层大数据包的自动分片与重组(倒序编号,0 为最后一片)。 |
wnd |
16-bit | 接收窗口 | 类似于 TCP 的 rwnd,用于流量控制。 |
ts |
32-bit | 时间戳 | 发送时刻的本地时间,用于接收端回显以计算 RTT。 |
sn |
32-bit | 序列号 | 数据包的编号。 |
una |
32-bit | 未确认序号 | 告知对方:此编号之前的所有包已收到(累计确认)。 |
len |
32-bit | 数据长度 | 载荷长度。 |
resendts |
(内部) | 重传时间 | 下一次需要重传的时刻,由 ikcp_update 检查。 |
rto |
(内部) | 超时时间 | 该包当前的重传超时设定。 |
fastack |
(内部) | 跳过次数 | 记录该包被多少个后续包的 ACK 跳过(SACK 机制),用于触发快速重传。 |
2.3.2 激进 ARQ
KCP 的激进性体现在它对传统 TCP 策略的全面修正。
2.3.2.1 混合确认机制:UNA + ACK List
TCP 主要依赖累计确认(UNA)。KCP 则采用了 UNA + ACK List 的混合模式。
- 头部中的
una字段提供累计确认,保证基础的滑动窗口推进。 - 同时,KCP 会单独发送 ACK 包(或者在数据包后追加 ACK
信息),显式告知收到了哪些特定的
sn。这种机制类似于 TCP 的 SACK,但在 KCP 中是原生且强制的。它允许发送端精确知道哪些包丢失,从而只重传丢失的包(选择性重传,Selective Repeat),避免了 Go-Back-N 的带宽浪费。
2.3.2.2 快速重传
TCP 需要 3 个重复 ACK 触发快重传。KCP 引入了 fastack
计数器:
- 当发送端收到一个 ACK,确认了
sn=100和sn=102,但没有确认sn=101时,sn=101的fastack计数器加 1。 - 一旦
fastack达到设定阈值(resend参数,通常设为 2 甚至 1),KCP 不等待rto超时,立即重传sn=101。 - 这使得 KCP 在跨越长肥管道(Long Fat Network)时,能比 TCP 快数倍地感知并恢复丢包。
2.3.2.3 非退让的流控
TCP 检测到丢包会减半窗口(拥塞避免)。KCP 提供了 nc(No
Congestion Control)配置开关。
- 当
nc=1时,KCP 完全关闭拥塞窗口(cwnd)逻辑,只受限于接收端的接收窗口(rwnd)和发送端的发送缓冲区大小。 - 这意味着即使网络极度拥塞,丢包率极高,KCP 依然会按照最大速度发送数据和重传包。这种“自私”的行为在公共互联网上可能加剧拥塞,但对于实时游戏等对延迟极度敏感的应用,它是保证流畅体验的关键手段。
2.3.2.4 RTO 策略优化
- 不翻倍:TCP 超时后 RTO 翻倍(x2, x4, x8)。KCP 默认仅 x1.5,这意味着它会更频繁地重试。
- RTO 最小值:TCP 的 RTO 最小值通常受限于内核 tick(例如 200ms),虽然现代 Linux 已优化,但 KCP 允许在用户态设置极低的 RTO 最小值(如 10ms-30ms),这对于局域网或高质量光纤网的微小抖动反应极快。
2.3.3 算力代价:用户态时钟与轮询
KCP 的高性能是有代价的——CPU 利用率。
- User-space Scheduling:KCP
没有内核的中断驱动机制。用户程序必须在一个循环中不断调用
ikcp_update(current_time)。 - Tick 频率:为了获得低延迟,
ikcp_update通常每 10ms 甚至 1ms 调用一次。这导致 CPU 即使在空闲时也难以进入深度睡眠状态,产生了大量的空轮询开销。
KCP 的本质是在应用层实现了一个高频轮询的调度器(通常
update间隔为 10ms)。它比 TCP 多耗费 20%-30% 的流量,换取了低延迟。关于 KCP 更多的底层细节可参阅 KCP 源码分析与原理总结。
2.4 QUIC:用户态的 TCP+TLS
QUIC(Quick UDP Internet Connections),现已标准化为 RFC 9000,代表了网络传输协议的最新演进方向。它不仅仅是一个传输协议,更是一个将传输层(Transport)、安全层(TLS)和部分应用层(HTTP/2)功能融合的垂直整合架构。
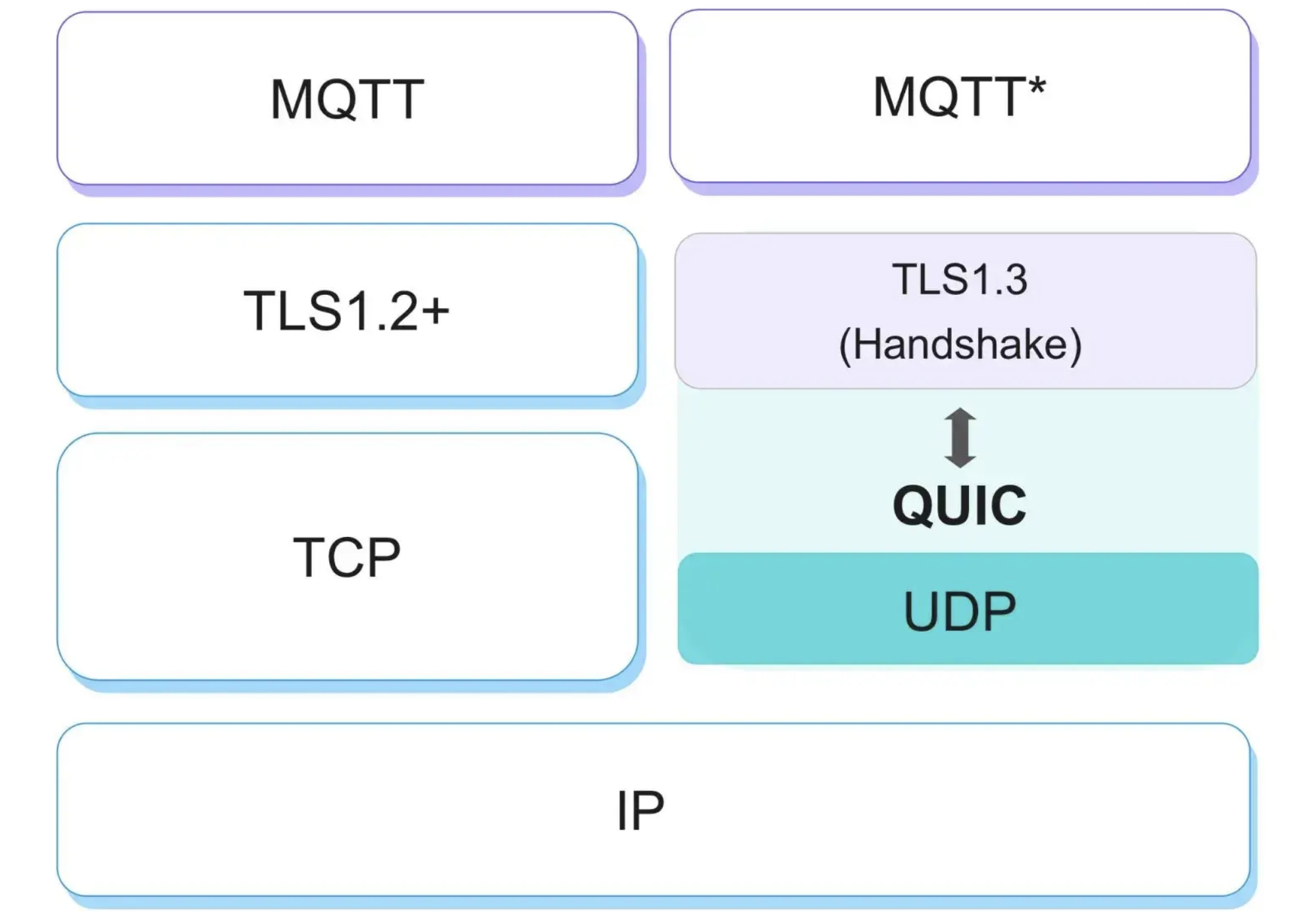
关键点:
- 低连接延迟
- 无队头阻塞
- 灵活拥塞控制
- 连接迁移
2.4.1 报文结构
QUIC 设计了两种头部格式,以适应握手和数据传输的不同需求。
长首部(Long Header):用于连接建立阶段(Initial, Handshake, Retry, 0-RTT)。第一字节最高位为 1。包含完整的 Source CID 和 Destination CID,以及版本号。

短首部(Short Header):用于连接建立后的数据传输(1-RTT)。第一字节最高位为 0。仅包含 Destination CID(可选)和 Packet Number。这极大地减少了头部开销。

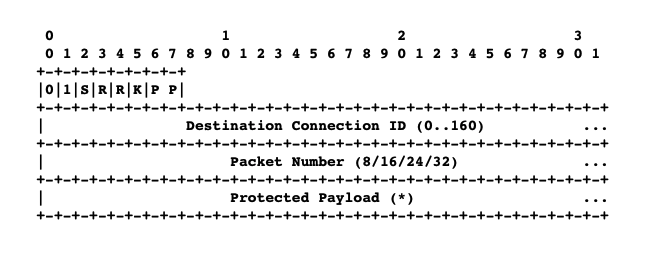
QUIC 的一个关键安全特性是对 Packet Number 进行加密。
- 机制:利用 Header Protection Key(从 TLS 协商导出),对 Packet Number 字段进行异或掩码操作。
- 目的:防止中间设备(Middleboxes)窥探连接的 RTT 或丢包率,也防止中间设备基于明文头部做深度包检测(DPI)从而干扰连接。这强化了协议的抗僵化能力(Ossification Resistance)。
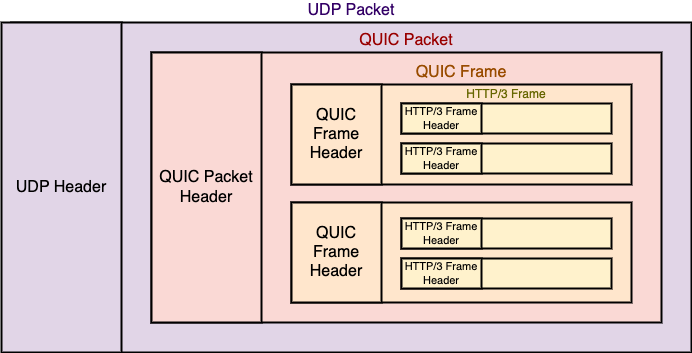
2.4.2 核心结构:Frame 与 Stream(解决队头阻塞)
TCP 的队头阻塞源于其单一的字节流抽象。QUIC 引入了Stream作为一等公民。
- 独立性:一个 QUIC 连接可以包含多个 Stream。每个 Stream 有独立的 ID 和 Offset。
- 底层实现:QUIC 数据包(Packet)是传输单元,Frame 是逻辑单元。一个 Packet 可以承载属于 Stream A 的 Frame 和属于 Stream B 的 Frame。
- 抗阻塞:如果承载 Stream A 数据的 Packet 丢失,接收端只需等待该 Packet 重传即可恢复 Stream A;而 Stream B 的数据如果在后续 Packet 中到达,接收端可以立即提交给应用层,无需等待 Stream A 的恢复。这彻底消除了传输层的队头阻塞。
2.4.3 连接迁移与 CID
移动互联网时代,设备的 IP 地址经常变动(Wi-Fi 切 5G)。TCP 依赖四元组(SrcIP, SrcPort, DstIP, DstPort)标识连接,IP 变动会导致连接中断。
- Connection ID (CID):QUIC 使用 CID 唯一标识连接。
- 迁移机制:当客户端 IP 变化时,它在新的 IP 上发送包含原有 Destination CID 的数据包。服务器收到后,通过哈希表查找 CID 对应的连接上下文,验证数据包的真实性(防欺均),然后更新路径信息。连接保持不断,应用层无感知 22。
- 隐私保护:为了防止路径关联攻击(通过追踪 CID 关联用户的物理位置),QUIC 允许在连接期间协商一组新的 CID。客户端在切换网络时主动更换使用新的 CID,使得监听者无法关联前后两条路径。
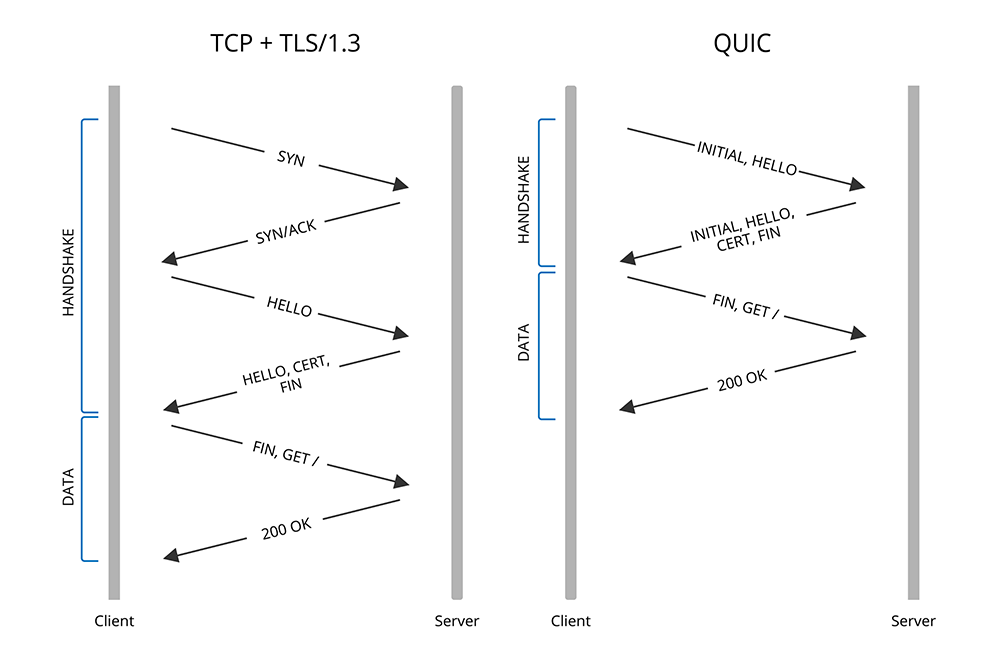
2.4.4 低延迟连接
QUIC 深度集成了 TLS 1.3,将传输层握手与加密握手合并。
- 1-RTT:首次连接,客户端发送 Initial 包包含 TLS ClientHello,服务器回复 ServerHello 和 EncryptedExtensions。1 个 RTT 后即可发送应用数据。
- 0-RTT:对于曾经连接过的服务器,客户端缓存了 ServerConfig 或 Session Ticket。在重连时,客户端利用预共享密钥(PSK)加密应用数据,随第一个 Initial 包(ClientHello)一起发送。服务器收到后立即解密处理。
- 反重放(Anti-Replay):0-RTT 数据不具备前向安全性,且容易被重放。RFC 9000 要求服务器对 0-RTT 数据的使用极其谨慎,通常只允许幂等请求(如 GET),并通过时间窗和 Ticket 唯一性检查来限制重放窗口。
2.4.5 更精确的恢复
QUIC 改进了 TCP 的 ACK 机制:
- ACK Ranges:TCP SACK 只有 3-4 个块。QUIC 的 ACK Frame 可以携带大量的 ACK Ranges(交替的 Ack 和 Gap 块),能精确描述极度碎片化的接收状态。
- Packet Number 单调递增:TCP 重传时使用相同的
SEQ。QUIC 重传一个 Frame 时,会将其封装在一个新的 Packet
中,使用新的 Packet Number。
- 消除二义性:接收端收到 ACK 时,根据 ACK 中的 Packet Number 就能明确知道是确认了原始包还是重传包。这彻底解决了 TCP 的重传二义性问题,使得 RTT 计算极其精准,不再需要 Karn 算法的退避策略。
2.5 总结
为了更直观地理解,我们对比一下它们处理"数据发送"这个动作的底层逻辑:
| 动作 | TCP (Kernel) | UDP (Kernel) | KCP (User Space) | QUIC (User Space) |
|---|---|---|---|---|
| 封装 | 这里是数据 -> 加 TCP 头 -> 存入发送缓冲区 -> 睡觉等 ACK | 这里是数据 -> 加 UDP 头 -> 扔给网卡 -> 结束 | 这里是数据 -> 加 KCP 头 -> 放入 UDP Payload -> 扔给网卡 | 这里是数据 -> 拆分 Frame -> 加密 -> 放入 UDP Payload -> 扔给网卡 |
| 重传触发 | 1. 超时 (RTO 很长) 2. 收到 3 个重复 ACK |
无 | 1. 超时 (RTO 很短) 2. 收到 n 个跨越包 (n可配) |
1. 超时 (基于精确 RTT) 2. 独立 Stream 触发 |
| 拥塞响应 | 丢包 = 网络堵塞 -> 降速 | 无 | 丢包 = 信号不好 -> 加速重传 (可选关闭流控) | 丢包 = 根据算法 (如 BBR) 智能判断 -> 动态调整 |
| 内存拷贝 | 用户态 -> 内核态 (Context Switch) | 用户态 -> 内核态 | 用户态处理 -> 此时还在用户态 -> 只有最后发 UDP 时进内核 | 完全在用户态处理 -> 只有最后发 UDP 时进内核 |
从原理出发,我们可以得出工程实践的指导原则:
- 内网微服务 (RPC): 依然首选 TCP。因为内网环境极其稳定,带宽大,丢包率几乎为 0。TCP 的内核态实现效率极高,CPU 消耗比 QUIC 低得多(QUIC 需要在用户态频繁解密和计算,非常吃 CPU)。
- 公网实时游戏/音视频: 首选 KCP(或类 KCP 的私有协议)。因为你要的是低延迟,且你可以容忍多跑一点流量。
- 弱网环境下的 App/Web: 首选 QUIC。比如跨国访问、移动端环境。它解决了 TCP 的队头阻塞和连接迁移问题,能显著提高用户的加载体验。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。



